ADS03:倒排文件索引
Inverted File Index
倒排文件索引
一、定义
索引Index:在文本中 定位 给定术语term 的一种机制
倒排文件Inverted File:包含一个指针列表(如页码),指向文本中出现该术语的所有位置
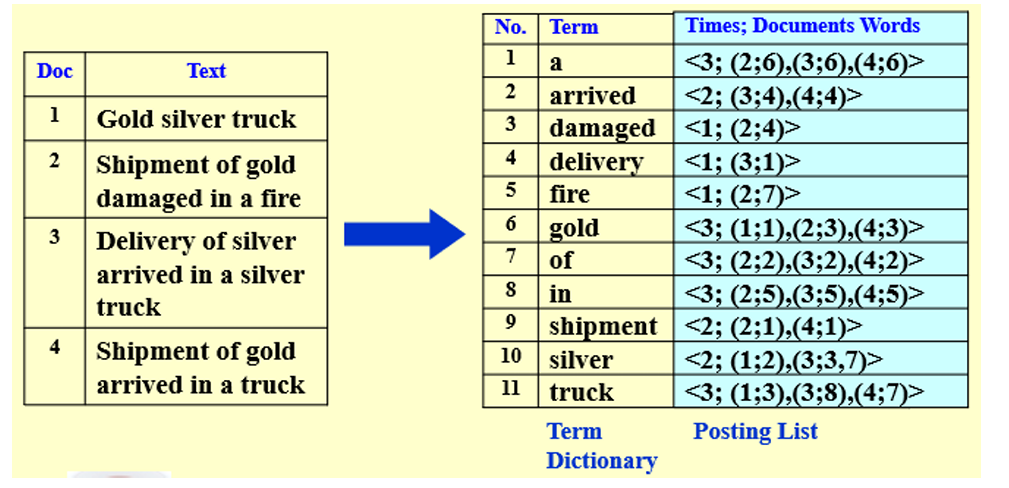
记录:出现频率Times、出现的位置
搜索:从最小频率的term开始求交
while(read a document D){ |
二、Read a term
2.1 word stemming词干
对一个单词进行加工,使之只包含它的骨干

2.2 stop words停用词
对于非常常用的词语,直接过滤掉
例如:a, the, it
注意:to be or not to be
三、Accessing a term
方法一:Search trees
方法二:Hashing
四、Index
4.1 当空间不足时
BlockCnt = 0; |
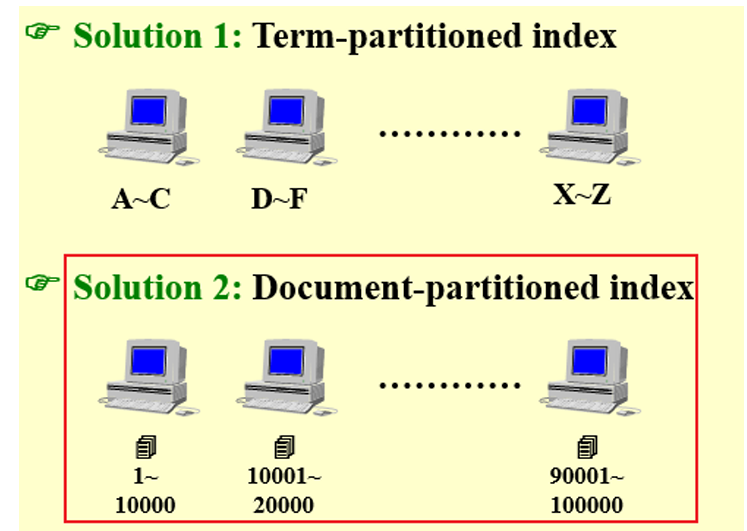
5.2 Distributed indexing分布式索引
所有的节点保存集合的子集
- 先将所有的文档随机分配
- 然后再建立索引
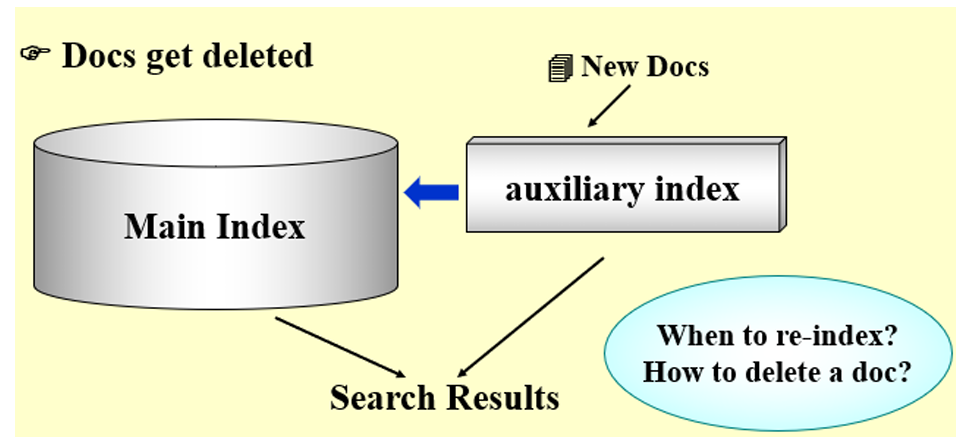
5.3 Dynamic indexing 动态索引
- 文档更新
- 更新字典中已经存在的术语
- 向字典中加入新键值
- 删除文档
5.4 Compression 压缩索引
保存每个索引与上一个索引位置的差值

5.5 Thresholding阈值
- 文档:只保存通过键值排序的前x个文档
- 询问:根据查询词的频率升序排序,只根据原始查询条件的一部分
五、搜索引擎的评价
- 编辑索引的速度
- 查询的速度
- 查询语句的复杂程度
- 数据检索性能评估(在正确建立之后)
- 相应时间
- 索引空间
- 信息检索性能评估
- 结果与查询语句的相关性
5.1 相关性衡量
相关性与搜索的人有关,而非与搜索的词语有关
- 例如,有的人查“苹果”是为了吃,有的人是为了用
相关性测量需要3个元素:
- 一个测试的文档集benchmark document
- 一个测试的查询集benchmark suite of queries
- 对每隔查询文档进行相关/不相关的二进制评估binary assessment
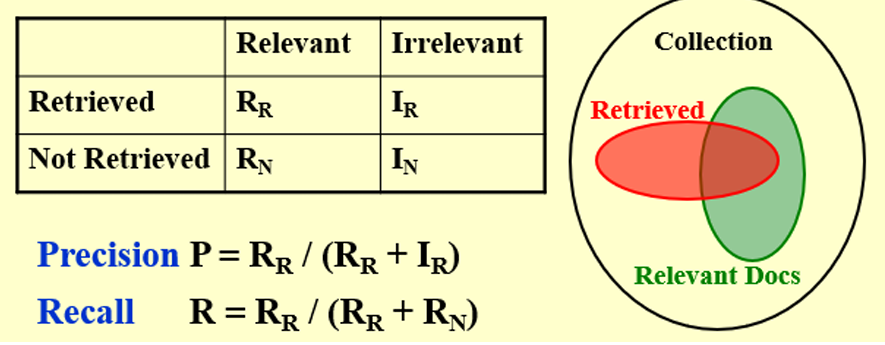
5.2 Precision and Recall
\[ \begin{aligned} &精准度Precision:P=\frac{R_R}{R_R+I_R},查询的准确度越多越好\\ &召回率Recall:R=\frac{R_R}{R_R+R_N},查询的正确结果越多越好 \end{aligned} \]
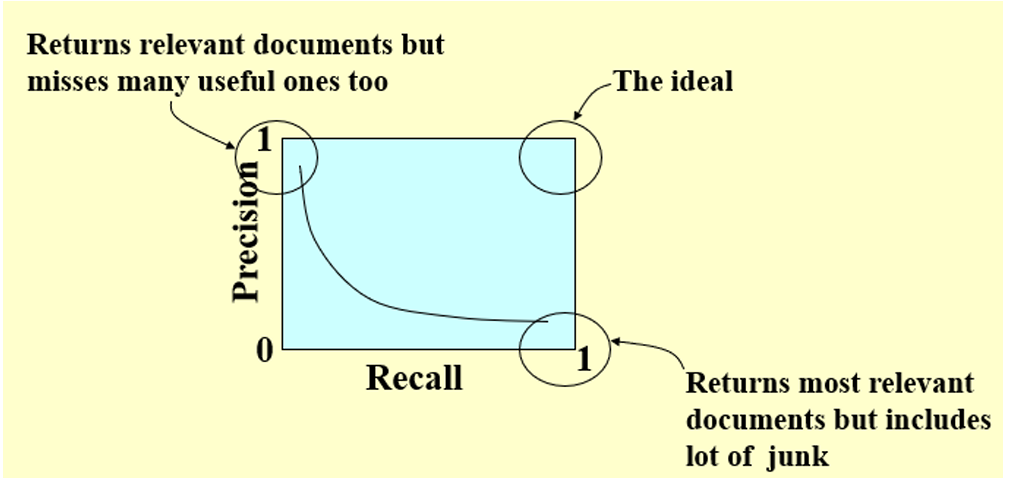
有的时候,精准度与召回率可能会同时满足
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 华风夏韵!
评论