操作系统
Chapter 1:Introduction
1.1 操作系统在做什么
1.1.1 操作系统的作用
Operating System的作用:
- 作为用户与计算机硬件交互的中间层
Operating System的目标:
- 更加容易的执行/实现用户的程序
- 更加方便的使用计算机:交互
- 更有效率的使用硬件

Computer System的结构:
- 硬件Hardware:提供基础的计算资源
- CPU、memory、I/O devices
- 操作系统Operating System:控制在不同程序、不同用户间的硬件的使用
- 应用程序Application
Programs:定义如何使用系统资源来解决问题
- Word processors、compilers、web browsers、database systems、video games
- 用户Users:
- People、machines、other computers
1.1.2 什么是操作系统
1.1.2.1 计算机系统组成角度:操作系统是系统软件
- 计算机系统组成:
- 软件:应用软件、系统软件(操作系统等)
- 硬件:输入/输出(I/O)设备、存储器(内存) 、中央处理器(CPU)
1.1.2.2 用户角度:操作系统是用户与计算机硬件之间接口
- Computer计算机硬件
- PC
- mainframe, or minicomputer
- mobile computers
- 操作系统提供的接口有:
- 命令级接口
- 键盘或鼠标等命令。
- Mobile user interfaces such as touch screens, voice recognition
- 程序级接口
- 它提供一组系统调用System calls ,即操作系统服务,供用户程序和其它程序调用
- 命令级接口
1.1.2.3 系统角度:操作系统是计算机系统资源的管理者
- OS是资源的分配者
- 管理所有资源
- 处理冲突的需求,有效而公平
- OS是一个控制程序
- 控制程序的执行,阻止错误、不正确的使用
1.1.2.4 软件分层、扩充机器的角度:操作系统是扩充裸机的第一层系统软件
1.1.2.5 综合考虑
操作系统是一组:有效控制和管理计算机各种硬件和软件资源,合理的组织计算机的工作流程 ,以及方便用户的程序的集合
- 有效(efficient):系统效率高,资源利用率高(如:CPU使用率,内存、外部设备是否忙)
- 合理:公平,如果不公平则会产生“死锁”或“饥饿”
- 方便(convenience):用户界面,编程接口
1.2 Computer System Organization
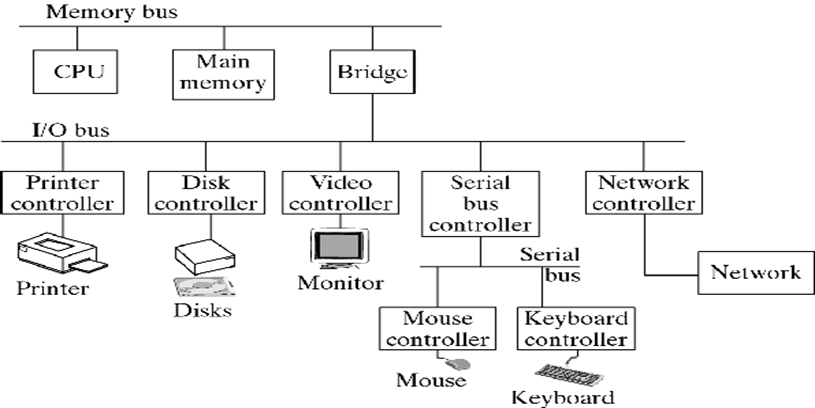
1.2.1 总线结构
总线结构:微型计算机是以总线为纽带来构成计算机系统,中央处理机(CPU)、存储器、 I/O设备(包括外存磁盘、磁带)都挂接在总线
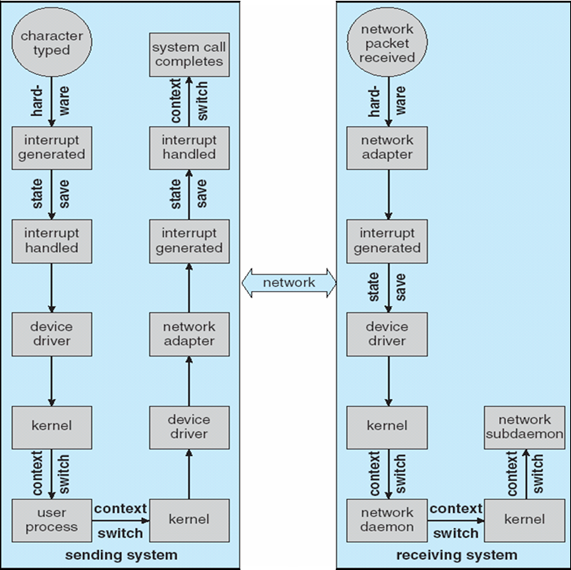
- I/O设备和CPU可以并行运行execute concurrently
- 每一个设备控制器控制一个特定的设备
- 每一个设备控制器均有一个存储单元local buffer
- 每一个设备控制器均有一个操作系统的驱动器device driver,让操作系统管理它
- CPU在内存main memory和buffer之间进行数据的移动
- I/O本质上是device到local buffer之间的数据交互
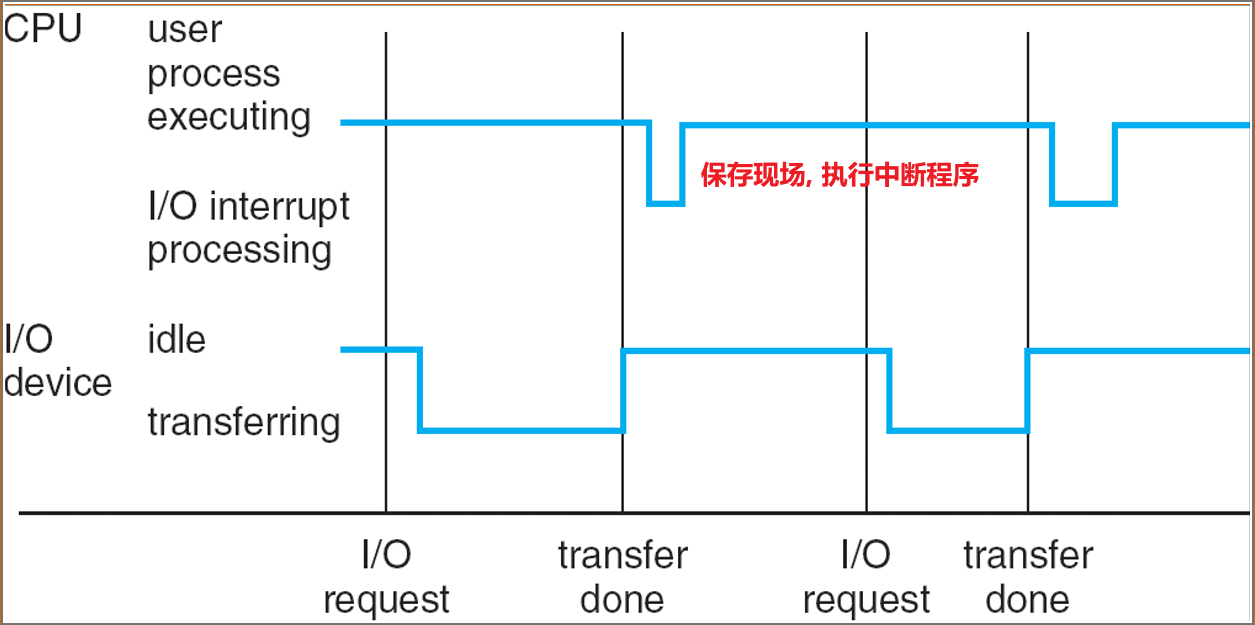
- 设备通过提出中断interrupt的方式,告诉CPU它已经完成了操作
1.2.2 计算机启动 Startup
bootstrap program
- 存放在ROM/EEPROM中,也被称为firmware
- 在电源启动/重启的时候,这个程序被加载到内存中
- 会初始化操作系统的必须部分
- 然后将操作系统加载到内存中,开始执行
1.2.3 中断
中断(Interrupt):指系统发生某个异步/同步事件后,处理器暂停正在执行的程序,转去执行处理该事件程序的过程
- 硬件中断
- 软件中断:陷入(trap)
操作系统是中断驱动的interrupt driven
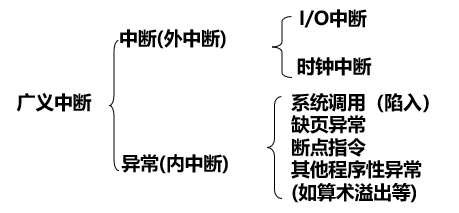
外部中断(interrupt),异步中断:
- 外部设备所发出的I/O请求
- 分为可屏蔽的和不可屏蔽的两类,由一些硬件设备产生,可以在指令执行的任意时刻产生
异常(exception),内部中断,同步中断:
- 由正在执行的进程产生,一条指令终止执行后才会发出中断
- 常见的异常有除零、溢出及页面异常(fault出错)等。另一种情况是使用int指令(trap陷入),Linux使用该指令来实现系统调用。 fault与trap区别
中断处理
- 操作系统保存当前CPU状态:存储register、PC(program counter)
- 判断发生了哪一种中断:
- Polling:轮询
- Vectored interrupt system:向量化中断系统
- 单独的代码段决定了每种类型的中断应采取的操作(中断服务程序)
Interrupt Time line
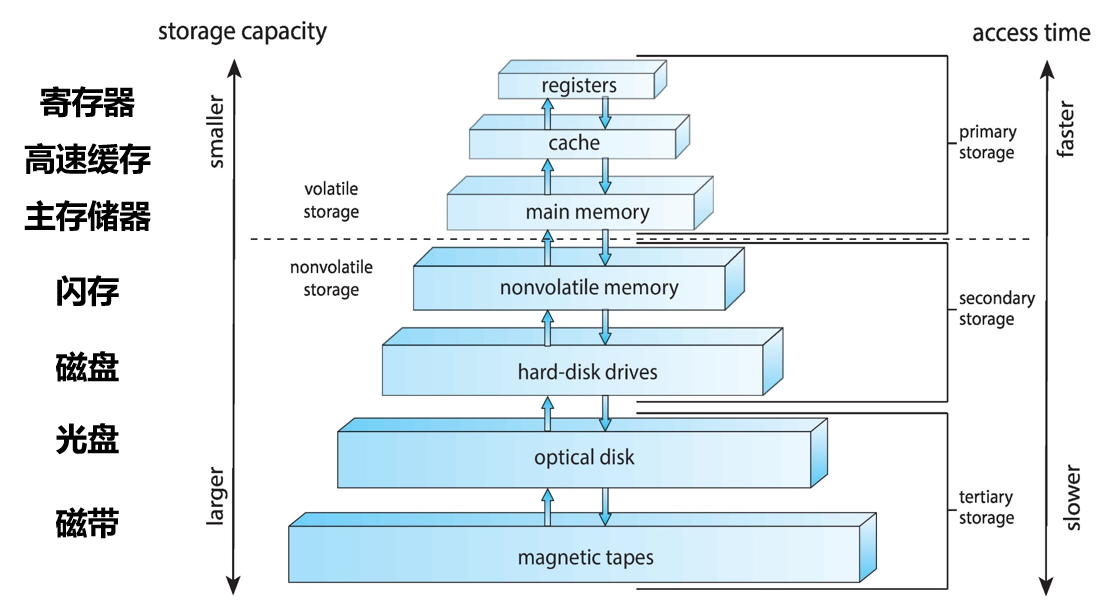
1.2.4 存储结构
Main Memory(主存)
- CPU能够直接访问的最大存储空间
Secondary Storage(赋存)
- 主存的拓展,提供大量非易失型的存储空间
Hard Disk Drives(HDD, 硬盘):
- 覆盖有磁记录材料的刚性金属或玻璃盘
- 磁盘表面按逻辑划分为磁道,磁道又细分为扇区
- 磁盘控制器确定设备和计算机之间的逻辑交互
Caching(高速缓存技术):将信息复制到更快的存储系统中
- Main Memory可以被视为Secondary Storage的一个缓存(cache)
- 重要原理:在计算机(硬件、操作系统、软件)的多个级别执行
- 正在使用的信息临时从较慢的存储复制到较快的存储
- 更快的存储(缓存)首先检查,判断信息是否存在
- 如果是,则直接从缓存中使用信息(fast)
- 如果不是,则将数据复制到缓存并在其中使用
- 缓存小于正在缓存的存储
- 缓存管理是一个重要的设计问题
- 缓存大小和替换策略
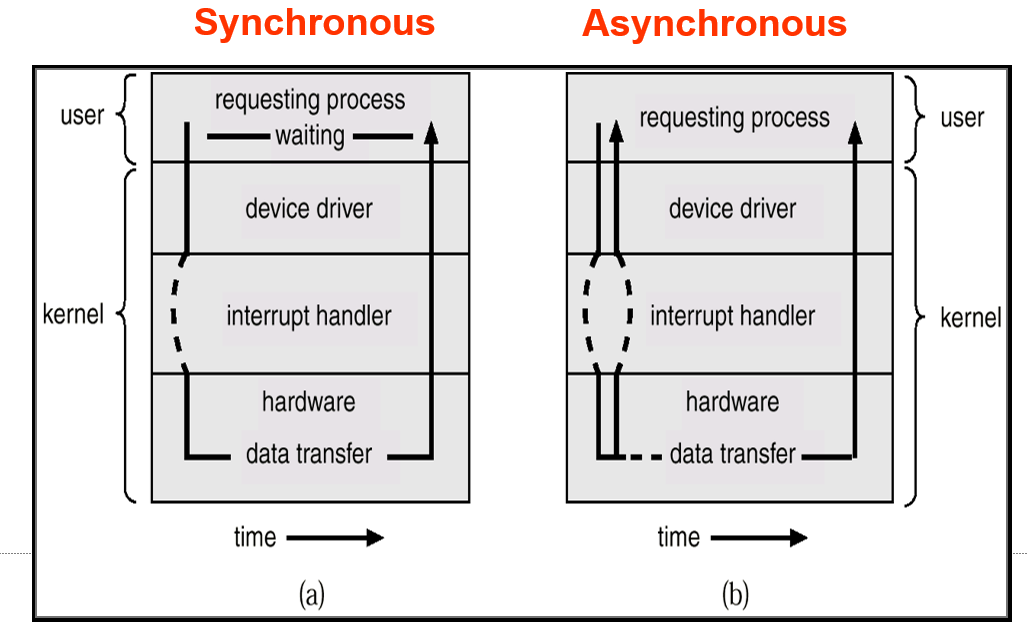
1.2.5 IO结构
I/O方式:
程序I/O (Programmed I/O)
中断 I/O (Interrupt I/O)
- 同步I/O:IO开始后,控制权只有当IO结束才会返回给程序
- 异步I/O:IO开始后,控制权立即返回给程序
- 设备状态表Device-status table:包含每个I/O设备的条目,指示其类型、地址和状态
- 操作系统索引到I/O设备表中,以确定设备状态并修改表条目以包括中断
DMA方式:Direct Memory Access Structure直接内存访问
- 用于能够以接近内存速度传输信息的高速I/O设备
- 设备控制器将数据块从缓冲存储器直接传输到主存储器,无需CPU干预
- 每个块只生成一个中断,而不是每个字节一个中断
通道方式
1.3 Computer System Architecture
1.3.1 单处理器系统
- 只有一个CPU和一个计算单元
1.3.2 多处理器系统
- Multiprocessor Systems多处理器系统:也称为并行系统parallel systems、紧密耦合系统tightly-coupled systems
- 优点:
- 增加吞吐量
- 规模经济
- 提高可靠性——性能下降或容错
- 两种类型:
- 非对称多重处理
- 对称多重处理
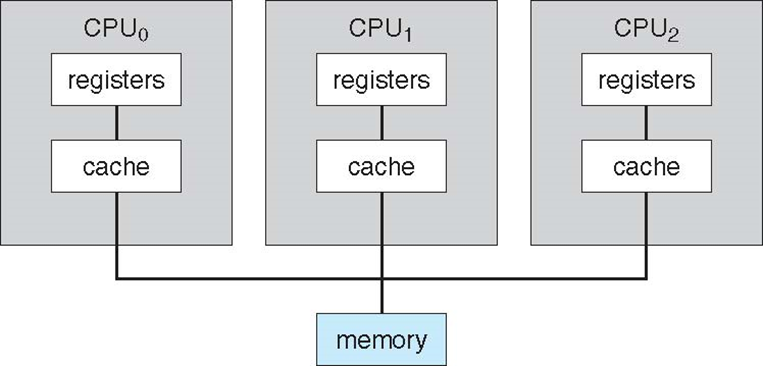
Multi-processor(多个芯片) and multicore(多核)
- System(系统)包含所有的芯片
- Chassis(主板)包含多个独立的处理器
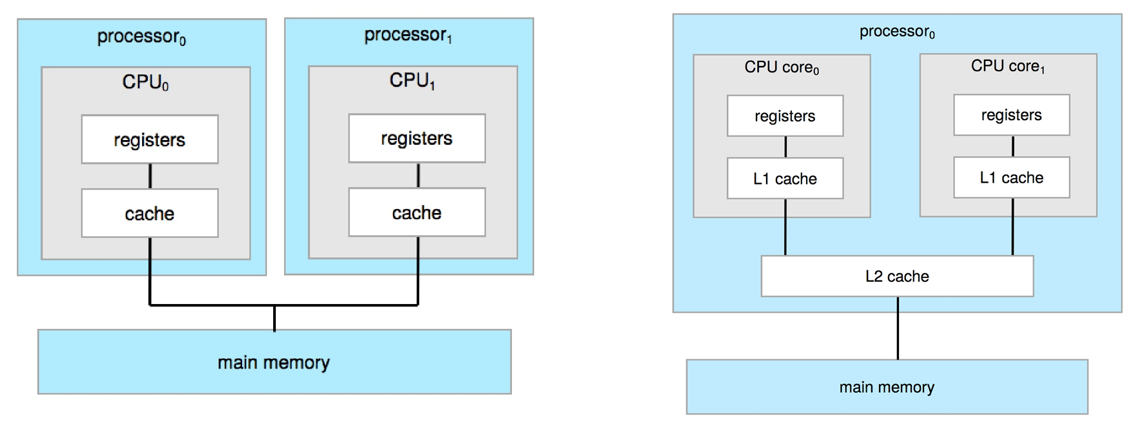
1.3.3 计算机系统组件的定义
- CPU:执行指令的硬件
- Processor处理器:包含一个或多个CPU的物理芯片
- Core核:CPU里面最基本的计算单元
- Multicore多核:在一块CPU里面有多个计算单元
- Multiprocessor多处理器:包含多个处理器
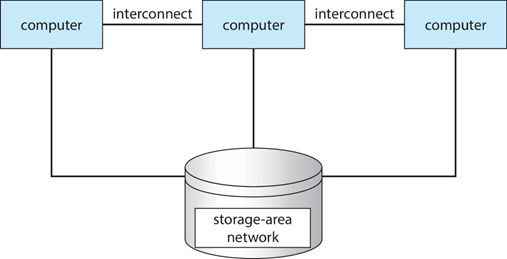
1.3.4 Clustered Systems集群系统
集群系统(Cluster) :是由一组互联的主机(节点)构成统一的计算机资源,通过相应软件协调工作的计算机机群,给人以一台机器的感觉
通常通过存储区域网络(storage-area network,SAN)共享存储
提供高可用性(high-availability)服务,可在故障中生存
- Asymmetric clustering(非对称集群):有一台机器处于热备用模式
- Symmetric clustering (对称集群): 有多个运行应用程序的节点,相互监视
一些集群用于高性能计算(HPC,high-performance computing)
- 必须编写应用程序以使用并行化(parallelization)
一些具有分布式锁管理器(DLM分布式锁管理器) 避免冲突操作
其他形式的集群:并行集群、WAN上的集群
集群技术正在迅速变化
- 一些集群产品支持集群中的数千个系统,以及相隔数英里的集群节点
- Storage-Area Network,SAN,存储区域网
1.4 Operating System Operations操作系统的执行
- 硬件驱动的中断
- 软件错误或请求创建exception(异常) 或trap(陷入)
- 除以零,请求操作系统服务
- 其他进程问题包括无限循环、进程相互修改或操作系统
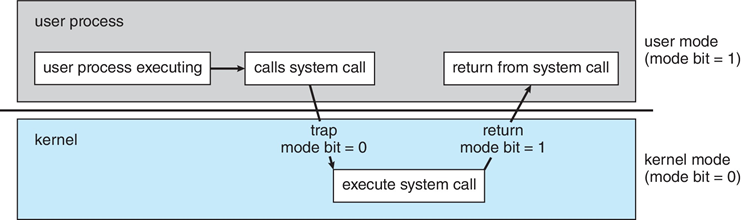
1.4.1 两种操作模式:
- User mode(用户态):执行用户程序时
- 只能访问属于它的存储空间和普通寄存器,只能执行普通指令
- 用户程序以及操作系统核外服务程序运行在用户态下
- 使用用户栈
- 非特权指令:用户程序中所使用的指令
- Kernel mode(内核态):执行操作系统程序时
- 也称为:monitor mode管态、system mode系统态、supervisor mode管态 、privileged mode特权模式
- 能够访问所有系统资源,可以执行特权指令,可以直接操作和管理硬件设备
- 操作系统内核程序运行在内核态下
- 使用内核栈
- 特权指令:不允许用户程序中直接使用的指令。例如:I/O指令、设置时钟、设置控制寄存器等指令都是特权指令
1.4.2 Timer(定时器):防止无限循环/进程占用资源
- 在特定时间段后设置中断
- 操作系统递减计数器
- 当计数器为零时,生成中断
- 在调度进程之前设置,以重新控制或终止超过分配时间的程序
1.5 Resource Management资源管理
- 进程管理 Process Management
- 主存管理 Main Memory Management
- 文件系统管理 File-System Management
- 大容量储存管理 Mass-Storage Management
- 高速缓存管理机制 Caching
- I/O系统管理 I/O System Management
1.5.1 进程管理
- 进程Process:所有处于执行中的程序
- 进程是一个最基本的单元
- 不同进程之间可以共享一些数据,但不会相互依赖
- 程序是passive entity(静态实体),进程是active entity(活动实体)
- 进程需要获得一些资源以完成任务
- CPU、内存、IO、文件、初始化数据
- 进程终止需要回收任何可重用资源
- 单线程进程(Single-threaded process)
- 有一个程序计数器(PC,program counter),指定要执行的下一条指令的位置
- 进程按顺序执行指令,一次一个,直到完成
- 多线程进程(Multi-threaded process)
- 每个线程有一个程序计数器(PC)
- 通常,系统有许多进程,一些用户,一些操作系统在一个或多个CPU上并发运行
- 通过在进程/线程之间复用CPU(multiplexing)实现并发(concurrency)
- 时间片:多个时钟周期的组合
- 轮转的调度方法:每一个进程执行一段时间后,暂停当前进程,执行下一个进程
- 每一次切换时,由于需要将当前进程的相关信息保存下来,所有会造成浪费
- Process Management的任务:
- 创建和删除用户和系统进程
- 暂停和恢复进程
- 提供进程同步机制
- 提供过程通信机制
- 提供死锁处理机制
1.5.2 内存管理
- 要执行程序,所有(或部分)指令必须在内存中
- 程序所需的所有(或部分)数据必须在内存中
- 内存管理确定内存中的内容和时间
- 优化CPU利用率和计算机对用户的响应
- Memory Management的任务:
- 跟踪当前正在使用内存的哪些部分以及由谁使用
- 决定哪些进程(或其部分)和数据要移入和移出内存
- 根据需要分配和释放内存空间
1.5.3 文件系统管理
- 操作系统提供信息存储的统一逻辑视图
- 将物理属性抽象为逻辑存储单元文件file
- 每个介质由设备(如磁盘驱动器、磁带驱动器)控制
- 不同的属性包括访问速度、容量、数据传输速率、访问方法(顺序或随机)
- 文件系统管理
- 文件通常被组织到目录中
- 大多数系统上的访问控制,以确定谁可以访问什么
- File-system Management的任务:
- 创建和删除文件和目录
- 用于操作文件和目录的原语primitives
- 将文件映射到辅助存储
- 将文件备份到稳定(非易失性)存储介质上
1.5.4 大容量储存管理
- 通常,磁盘用于存储不适合主内存的数据或必须保存“长”一段时间的数据
- 适当的管理至关重要
- 计算机操作的整体速度取决于磁盘子系统及其算法
- Mass-Storage Management的任务
- 安装mounting和拆卸unmounting
- 空闲空间管理
- 存储分配
- 磁盘调度
- 分区Partition
- 保护Protection
- 有些存储不需要很快
- 三级存储包括光盘、磁带
- 仍然必须由操作系统或应用程序进行管理
1.5.5 高速缓存机制Caching
重要原理,在计算机(硬件、操作系统、软件)的多个级别执行
将正在使用的信息临时从较慢的存储复制到较快的存储
Faster Storage(cache)首先检查,判断信息是否存在
- 如果存在,则直接从缓存中使用信息(fast)
- 如果不存在,则将数据复制到缓存并在其中使用
缓存小于正在缓存的存储
- 缓存管理是一个重要的设计问题
- 缓存大小和替换策略
多任务环境必须小心使用最新的值,无论它存储在存储层次结构中的何处

多处理器环境必须在硬件中提供缓存一致性,以便所有CPU在其缓存中都具有最新的值
分布式环境情况更加复杂
- 一个基准可以有多个副本
- 第19章涵盖的各种解决方案
1.5.6 I/O子系统
- 操作系统的一个目的是向用户隐藏硬件设备的特性
- I/O Subsystem的任务:
- I/O的内存管理,包括缓冲(在传输数据时临时存储数据)、缓存(将部分数据存储在更快的存储中以提高性能)、假脱机(一个作业的输出与其他作业的输入重叠)
- 通用设备驱动程序接口
- 特定硬件设备的驱动程序
1.6 Security and Protection安全和保护
- 保护Protection:控制进程或用户 访问操作系统定义的资源 的机制
- 安全性Security:防御系统内部和外部攻击
- 范围广泛,包括拒绝服务(denial-of-service)、蠕虫(worms)、病毒(viruses)、身份盗窃(identity theft)、服务盗窃(theft of service)
- 系统通常首先区分用户,以确定谁可以做什么
- 用户身份(user IDs、security IDs):包括姓名和相关号码,每个用户一个
- user ID与该用户的所有文件、进程关联,以确定访问控制
- 组标识符(group ID):允许定义和管理用户集,然后还可以与每个进程、文件关联
- 权限提升Privilege escalation:允许用户更改为具有更多权限的有效ID
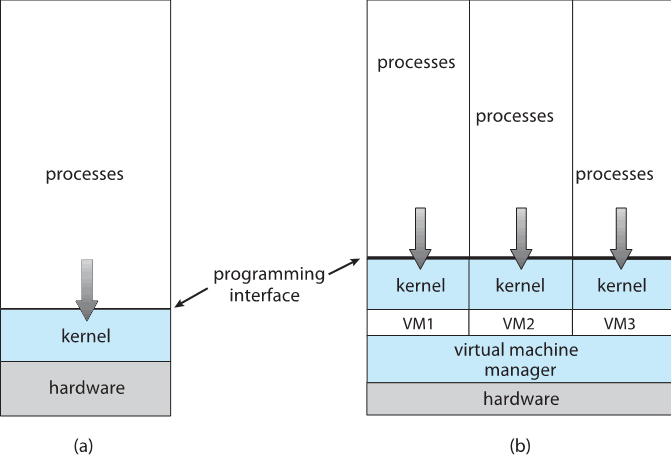
1.7 Virtualization虚拟化
- 允许操作系统在其他操作系统中运行应用程序
- 仿真Emulation:当源CPU类型与目标CPU类型不一样时使用该技术
- 通常是最慢的方法
- 当计算机语言未编译为本机代码时:Interpretation翻译
- 虚拟化Virtualization:为CPU本机编译的OS,运行本机也编译过的guest
OS
- 考虑运行WinXP客户机的VMware,每个客户机都运行本机WinXP主机操作系统上的应用程序
- VMM(虚拟机管理器 virtual machine Manager)提供虚拟化服务
- VMM可以本地化运行,在这种情况下,它们也是主机
- 因此,没有通用主机(VMware ESX和Citrix XenServer)
1.8 Distribute System分布式系统
- 分布式计算
- 独立的、可能异构的、联网在一起的系统的集合
- 网络(Network)是通信路径,TCP/IP最常见
- 局域网(LAN)
- 广域网(WAN)
- 城域网(MAN)
- 个人局域网(PAN)
- 网络操作系统(Network Operating
System):提供跨网络的系统之间的功能
- 通信方案允许系统交换消息
- 看起来是单一系统
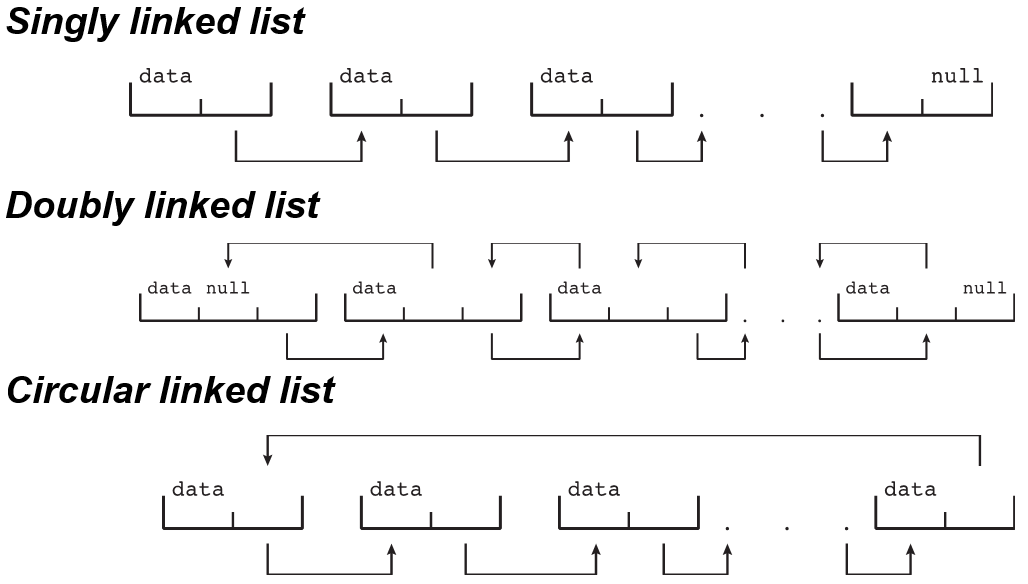
1.9 Kernel Data Structures内核数据结构
Linked List
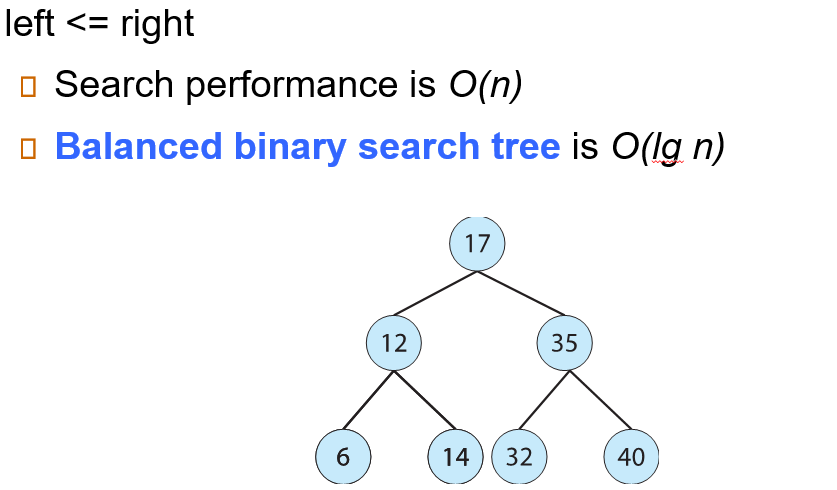
Binary Search Tree
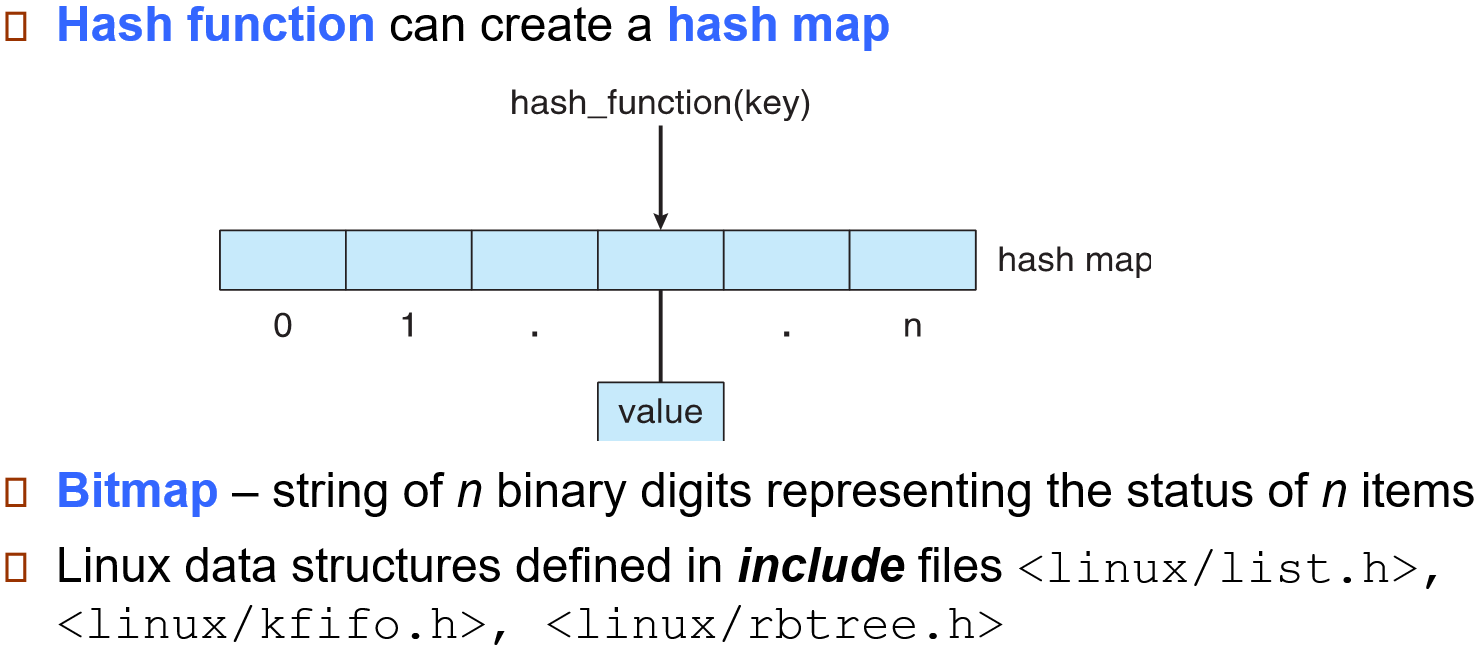
Hash Map
1.10 Computing Environments计算环境
1.10.1 传统计算 Traditional
- 独立通用机器
- 但由于大多数系统与其他系统(即互联网)互连,因此变得模糊
- 门户Portals提供对内部系统的web访问
- 网络计算机(thin clients)就像Web终端
- 移动计算机通过无线网络互连
- 网络无处不在,甚至家庭系统也使用防火墙保护家庭计算机免受互联网攻击
Mainfram Systems大型机系统:
Batch System:批处理系统
Multiprogramming:多道程序,多个作业同时保存在主存中,CPU在其中多路复用

Time-Sharing Systems:分时系统
- 分时:多个用户分时共享使用同一台计算机
- 也就是说把计算机的系统资源(尤其是CPU时间)进行时间上分割,即将整个工作时间分成一个个的时间片,每个时间片分给一个用户使用
- 这样将CPU工作时间分别提供给多个用户使用,每个用户依次地轮流且使用一个时间片
- 响应时间:是分时系统的重要指标,它是用户发出终端命令到系统作出响应的时间间隔。
- 系统的响应时间主要是根据用户所能接受的等待时间确定的。
- 假设分时系统中进程数(用户数)为n,每个进程的运行时间片为q,则系统的最大响应时间为:\(S=(n-1)×q\)
- 响应时间仅计算第一次被运行的时间点
- 分时:多个用户分时共享使用同一台计算机
Desktop Systems:桌面系统
- 个人计算机:专用于单个用户的计算机系统
- I/O设备:键盘、鼠标、显示屏、小型打印机
- 重点:用户的便利性和响应能力
- 可以采用为大型操作系统开发的技术,通常个人只使用计算机,不需要高级CPU利用率的保护功能
- 可以运行多种不同类型的操作系统
1.10.2 移动计算 Mobile
- 手持智能手机、平板电脑等
- 它们与“传统”笔记本电脑的功能区别是什么?
- 附加功能–更多操作系统功能(GPS、gyroscope陀螺仪)
- 允许新类型的应用程序,如增强现实
- 使用IEEE 802.11无线或蜂窝数据网络进行连接
计算应用领域:
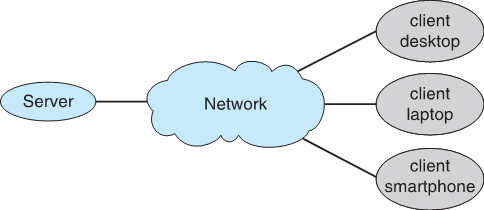
1.10.3 客户机Client-服务器Server计算
智能PC取代了无人机终端
现在许多系统都是服务器,响应客户端生成的请求
- 计算服务器系统compute-server system:为客户端提供请求服务(即数据库)的接口
- 文件服务器系统file-server system:为客户端提供存储和检索文件的接口
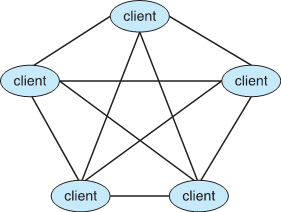
1.10.4 点对点计算 Peer-to-Peer
分布式系统的另一种模型
P2P无法区分客户端和服务器
- 相反,所有节点都被视为对等节点
- 可以分别充当客户端、服务器或两者
- 节点必须加入P2P网络
- 在网络上向中央查找服务注册其服务,或
- 广播服务请求并通过发现协议响应服务请求
示例包括Napster和Gnutella、Voice over IP(VoIP),如Skype
Blockchain technology 区块链技术
1.10.5 虚拟化计算 Virtualization
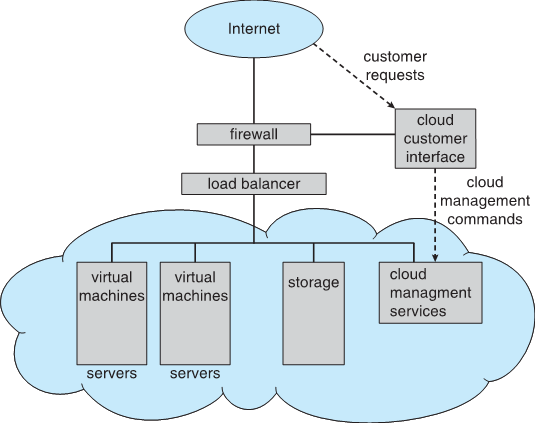
1.10.6 云计算 Cloud Computing
- 通过网络将计算、存储甚至应用程序作为服务提供
- 基于虚拟化的虚拟化逻辑扩展
- Amazon EC2拥有数千台服务器、数百万台虚拟机、PB存储空间,可在互联网上使用,根据使用情况付费
- Many types
- Public cloud(公有云):任何愿意付费的人都可以通过互联网获得
- Private cloud(私有云):由公司运营供公司自用
- Hybrid cloud(混合云):包括公共云组件和私有云组件
- Software as a Service (SaaS,软件即服务) :通过互联网提供的一个或多个应用程序(即文字处理器)
- Platform as a Service (PaaS,平台即服务) :软件堆栈可通过Internet(即数据库服务器)供应用程序使用
- Infrastructure as a Service (IaaS,基础设施即服务) :通过Internet可用的服务器或存储(即可用于备份的存储)
1.10.7 实时嵌入式系统 Real-Time Embedded Systems
- 实时嵌入式系统——最流行的计算机形式
- 各种相当大的、特殊用途的、有限用途的操作系统、实时操作系统
- 使用扩展
- 还有许多其他特殊的计算环境
- 有些有操作系统,有些在没有操作系统的情况下执行任务
- 实时操作系统具有明确定义的固定时间限制,运行顺序与要求的顺序一定相同
- 处理必须在约束内完成
- 只有在满足约束条件时才能正确操作
- 嵌入式系统:是以应用为中心,以计算机技术为基础,采用可剪裁软硬件,适用于对功能、可靠性、成本、体积、功耗等有严格要求的专用计算机系统,用于实现对其他设备的控制、监视或管理等功能
- 嵌入式操作系统:运行在嵌入式系统环境中,对整个嵌入式系统以及它所操作、控制的各种部件装置等资源进行统一协调、调度和控制的系统软件
1.10 总结

Chapter 2:Operating-System Structures
2.1 操作系统提供的服务
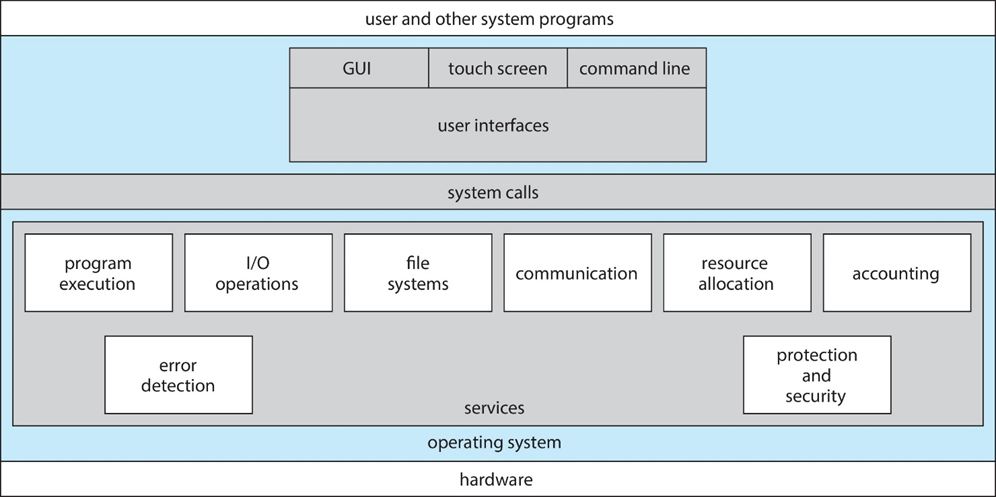
- 用户界面User Interface:
- 几乎所有操作系统都有用户界面(UI)
- 在命令行界面(CLI)、图形用户界面(GUI)和批处理之间有所不同
- 程序执行Program Execution:
- 系统必须能够将程序加载到内存并运行该程序,正常或异常结束执行(指示错误)
- I/O操作I/O operations:
- 正在运行的程序可能需要I/O,这可能涉及文件或I/O设备
- 文件系统操作File-System Manipulation:
- 程序需要读取和写入文件和目录,创建和删除它们,搜索它们,列出文件信息,权限管理
- 通信Communication:
- 进程可以在同一台计算机上或在网络上的计算机之间交换信息
- 通信可以通过共享内存或消息传递(数据包由操作系统移动)
- 错误检测Error Detection:
- 操作系统需要不断意识到可能的错误
- 错误可能出现在CPU和内存硬件、I/O设备、用户程序中
- 对于每种类型的错误,操作系统都应该采取适当的措施来确保正确和一致的计算
- 调试设施可以大大提高用户和程序员有效使用系统的能力
- 资源分配Resource allocation:
- 当多个用户或多个作业同时运行时,必须将资源分配给每个用户或作业
- 许多类型的资源(如CPU周期、主内存和文件存储)可能有特殊的分配代码,其他(如I/O设备)可能有一般的请求和发布代码。
- Accounting:
- 跟踪哪些用户使用了多少和什么类型的计算机资源
- 保护和安全Protection and Security:
- 存储在多用户或联网计算机系统中的信息的所有者可能希望控制该信息的使用,并发进程不应相互干扰
- 保护包括确保控制对系统资源的所有访问
- 来自外部的系统安全需要用户身份验证,扩展到保护外部I/O设备免受无效访问尝试
- 如果要保护系统,必须在整个系统中采取预防措施。链条的坚固程度取决于它最薄弱的环节
2.2 User Operating System Interface
- Operating System Interface操作系统的接口:
- User Interface (用户接口)
- Program Interface (程序接口,system call)
- User interface:用户接口,Almost all operating
systems have a user interface (UI)
- Command-Line Interface (CLI):命令行用户接口,文本界面
- Graphics User Interface (GUI):图形用户接口
- Touch-Screen Interface:触摸屏接口
- Choice of Interface:语音接口
2.3 System Calls
系统调用System Call:操作系统提供的服务的编程接口
- 系统调用:进程和操作系统内核之间的编程接口
- 通常用高级语言(C或C++)编写
- 通常由程序通过高级应用程序接口(API)访问,而不是直接使用系统调用
- 系统调用过于复杂,不适于编程
- 通过API将系统调用封装起来,便于编程
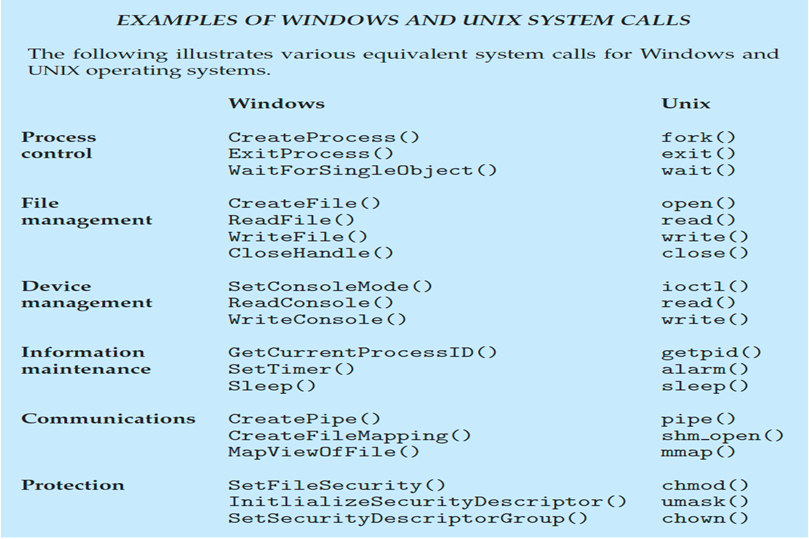
- 三种最常见的API:
- 用于Windows的Win32 API
- 用于基于POSIX的系统的POSIX API(包括几乎所有版本的UNIX、Linux和Mac OS X)
- 用于Java虚拟机(JVM)的Java API
API与系统调用的区别
应用编程接口(API):其实是一组函数定义,这些函数说明了如何获得一个给定的服务
系统调用:是通过软中断向内核发出一个明确的请求,每个系统调用对应一个封装例程(wrapper routine,唯一目的就是发布系统调用),一些API应用了封装例程
API还包含各种编程接口,如:C库函数、OpenGL编程接口等
系统调用的实现是在内核完成的,而用户态的函数是在函数库中实现的

参数的传递:
放到register
放到内存中,用register传递指针
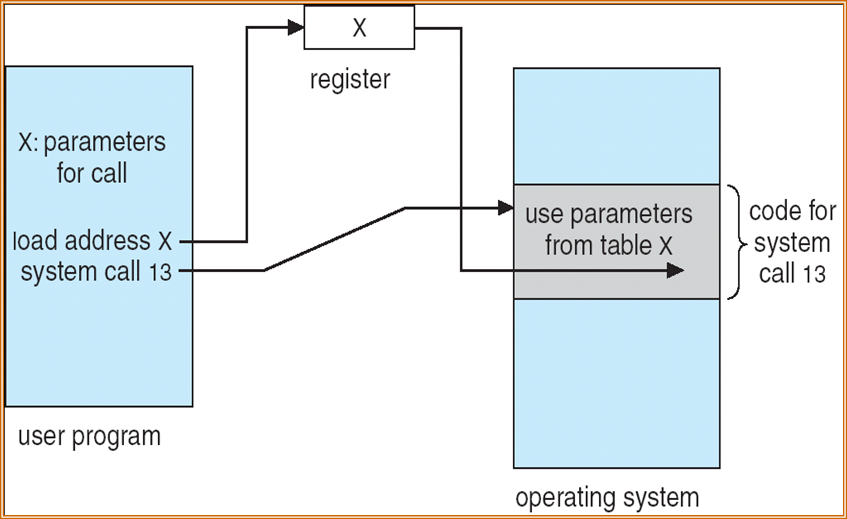
放到栈中,使用时从栈中pop出来
系统调用的种类
- Process control:进程控制
- 创建/终止/结束/中止/加载/执行 进程
- 获取/设置 进程属性
- 等待 一段时间/某个事件的发生
- 分配/释放/出错时转储 内存
- 用于确定错误的调试器Debugger,单步执行
- 用于管理进程之间共享数据访问的锁Locks
- File management:文件管理
- 创建/删除/打开/关闭/读/写/重定位 文件
- 获取/设置 文件属性
- Device management:设备管理
- 访问/释放/读/写/重定位 设备
- 获取/设置 设备属性
- 逻辑挂载/逻辑接触挂载 设备
- Information maintenance:信息维护
- 获取/设置 时间/日期/系统数据/进程属性/文件属性/设备属性
- Communications:通信
- 创建/删除 通信联系
- 如果是message passing model,则需要发送/接受信息
- 如果是shared-memory model,则需要创建/访问共享空间
- 传递状态信息
- 远程连接
- Protection:安全保护
- 对资源/文件的访问权限
- 用户的权限
- Process control:进程控制
2.4 System Services
系统程序System programs为程序开发和执行提供了方便的环境。它们可以分为:
- 文件操作:创建、删除、复制、重命名、打印、转储、列出并通常操作文件和目录
- 状态信息
- 文件修改:文本编辑器
- 编程语言支持:编译器、汇编器、调试器、解释器
- 程序加载和执行:加载/重新加载
- 通信:创建进程之间的连接,允许用户对另外一个用户进行传输文件/发送信息/远程控制
- 后台服务:启动时启动某些程序,打印错误日志,用户文本操作
- 应用程序
大多数用户对操作系统的认知是由系统程序System programs定义的,而不是实际的系统调用System calls
2.5 Linkers and Loaders
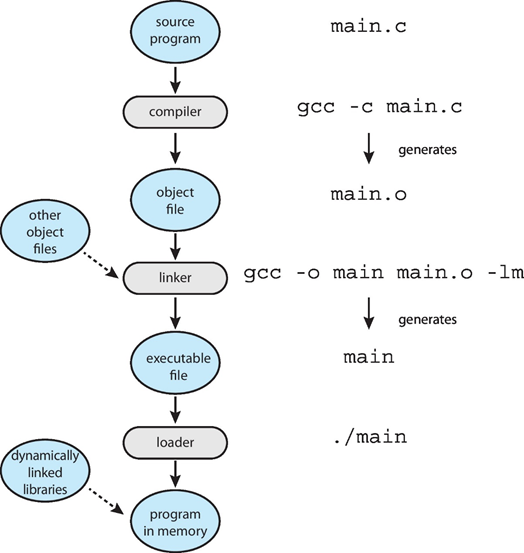
编译成目标文件的源代码,可加载到任何物理内存位置:可重定位的目标文件relocatable object file
链接器Linker将这些obj文件,合并为单个二进制可执行文件executable file
- 引入了库
程序作为二进制可执行文件加载load在辅助存储上
必须由要执行的加载程序带入内存
- 重新定位Relocation将最终地址分配给程序部件,并调整程序中的代码和数据以匹配这些地址
现代操作系统不会将库链接到可执行文件中
- 相反,动态链接库(DLL)是根据需要加载的,由所有使用同一版本库的用户共享
- 在程序运行时,按照需要加载一次
对象,可执行文件具有标准格式,因此操作系统知道如何加载和启动它们
2.6 为什么应用程序只运行在特定的操作系统上
- 在一个系统上编译的应用程序通常不能在其他操作系统上执行
- 每个操作系统都提供自己独特的系统调用、自己的文件格式等
- 应用程序可以是多操作系统
- 用解释语言编写,如Python、Ruby和多个操作系统上可用的解释器
- 以包含包含运行应用程序的VM的语言编写的应用程序(如Java)
- 使用标准语言(如C),在每个操作系统上分别编译,以便在每个系统上运行
- 应用程序二进制接口(Application Binary
Interface,ABI):是API的体系结构等价物
- 定义了二进制代码的不同组件如何在给定的体系结构、CPU等上与给定的操作系统交互
2.7 Operating-System Design and Implementation
- 操作系统的设计和实现不是“可解决的”,但一些方法已经证明是成功的
- 不同操作系统的内部结构可能有很大差异
- 从定义目标和规范开始
- 受硬件选择、系统类型的影响
- 用户目标和系统目标
- 用户目标:操作系统应便于使用、易于学习、可靠、安全和快速
- 系统目标:操作系统应易于设计、实施和维护,并且灵活、可靠、无错误和高效
操作系统的设计考虑
- 功能设计:操作系统应具备哪些功能
- 算法设计:选择和设计满足系统功能的算法和策略,并分析和估算其效能
- 结构设计:选择合适的操作系统结构
- 按照系统的功能和特性要求,选择合适的结构,使用相应的结构设计方法将系统逐步地分解、抽象和综合,使操作系统结构清晰、简单、可靠、易读、易修改,而且使用方便,适应性强
具体实现
- 变化很大
- 早期操作系统:汇编语言
- 然后:系统编程语言,如Algol、PL/1
- 现在:C,C++
- 实际上通常是多种语言的混合
- 组件中的最低级别
- 主体用C表示
- 用C、C++、脚本语言(如PERL、Python、shell脚本)编写的系统程序
- 更高级的语言更容易移植到其他硬件,但速度较慢
- 仿真可以允许操作系统在非本机硬件上运行
2.8 Operating-System Structure
Simple Structure:简单结构
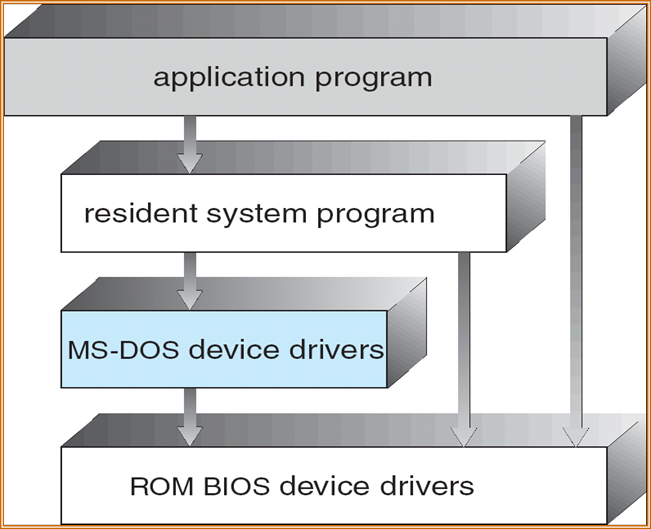
- MS-DOS:以最少的空间提供最多的功能
- 未划分为模块
- 虽然MS-DOS有一些结构,但其接口和功能级别没有很好地分离
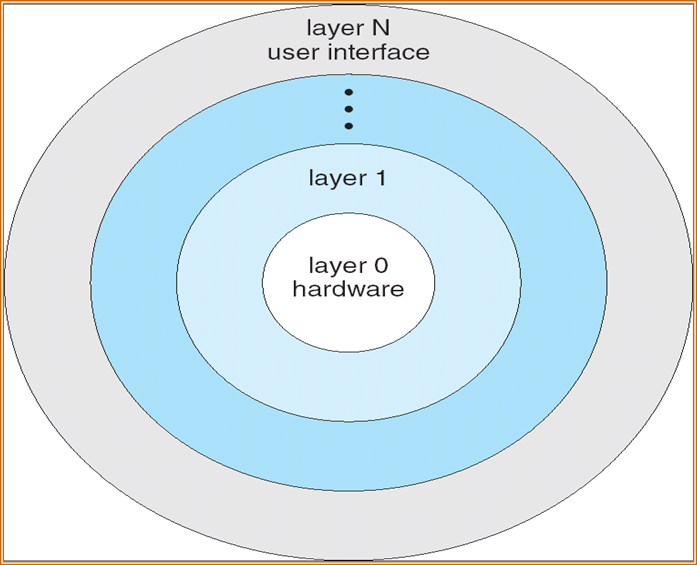
Layered Approach:层次化结构
- 操作系统被划分为若干层(级别),每一层都构建在较低层之上
- 底层(第0层)是硬件;最高的(N层)是用户界面
- 通过模块化,层的选择使得每个层只使用较低层的功能(操作)和服务
- 上一层只能使用下一层的功能
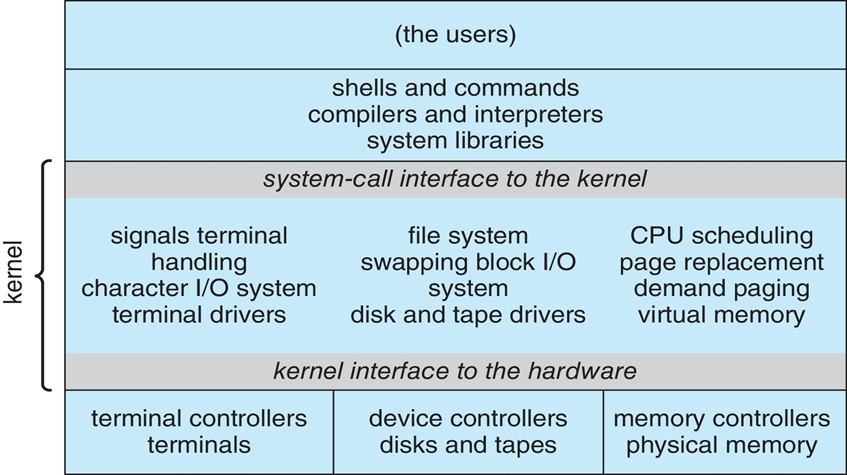
Monolithic Kernels Structure:单/宏内核结构

- 内核的整个代码都打包到一个文件中
- 每个函数都可以访问内核的所有其他部分
- 最早和最常见的操作系统体系结构(UNIX)
- 操作系统的每个组件都包含在内核中
- 示例:OS/360、VMS和Linux
- 优点:高效
- 缺点:很难定位问题,很难修改和维护,内核会变得越来越大
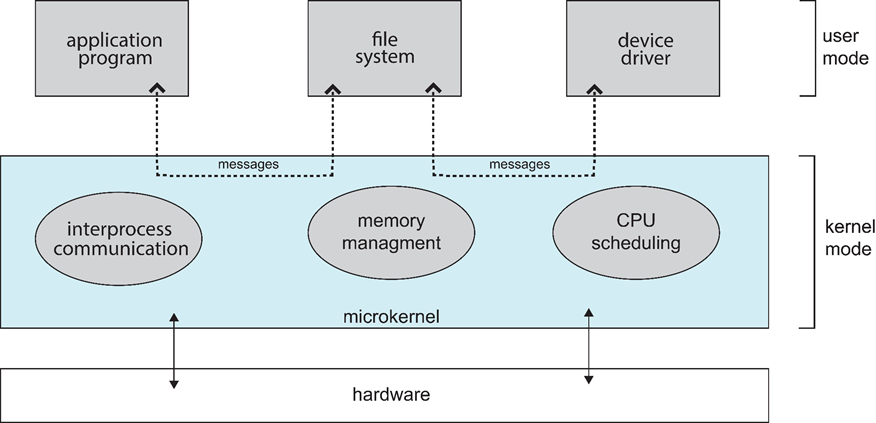
Microkernel:微内核,只保留必要的程序,在内核模式中运行的程序
只有最基本的功能由内核实现
所有其它功能委托给一些独立进程实现,这些进程通过明确定义的通信接口与中心内核通信
系统的各个部分彼此都很清楚的划分开来,同时也迫使程序员使用“清洁的”程序设计技术
优点:动态可扩展性、在运行时切换重要组件
缺点:在各个组件之间支持复杂通信需要额外的CPU时间
现有的系统多使用微内核结构
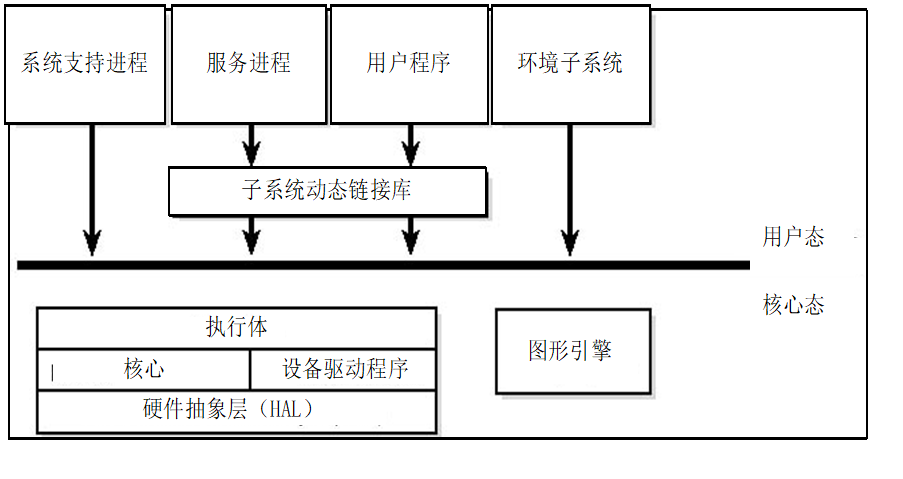
Modules:模块
- 大多数现代操作系统实现kernel modules(内核模块)
- 使用面向对象的方法
- 每个核心组件都是独立的
- 每个人都通过已知接口与其他人交谈
- 每个都可以根据需要在内核中加载
- 总体而言,与层相似,但更灵活
- 大多数现代操作系统实现kernel modules(内核模块)
Hybrid Systems:混合结构
- 大多数现代操作系统实际上不是一个纯模型
- Hybrid System结合了多种方法来满足性能、安全性和可用性需求
Virtual Machines:虚拟机
- 虚拟机采用分层方法得出其逻辑结论。它将硬件和操作系统内核视为硬件
- 虚拟机提供与底层裸硬件相同的接口
- 操作系统主机会产生一种错觉,认为进程有自己的处理器和(虚拟内存)
- 为每位host提供一份底层计算机的(虚拟)副本
- 虚拟机软件:VMWARE、VirtualBox、Microsoft virtual PC
- 开放堆栈云计算平台
Chapter 3:Processes
3.1 进程的概念
3.1.1 进程
进程:一个正在执行的程序,独立的,有权获取资源的
- 计算机的基本工作单位
- jobs作业=user programs用户程序=tasks任务=process进程
- 包含一些资源的指令容器:例如CPU时间(CPU执行指令)、内存、文件、完成其任务的I/O设备
- 示例:
- 编译进程
- 字处理进程
- 调度程序进程(scheduler processes):sched、swapper
- 守护进程(daemon process):ftpd、httpd
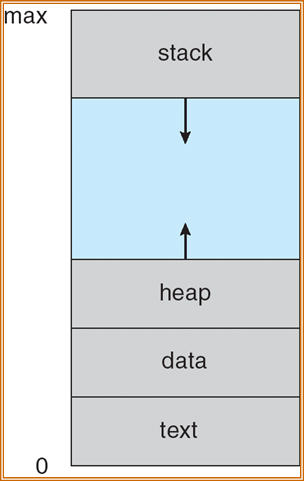
3.1.2 内存中的进程
- 程序代码,也被称为text section
- PC:Program Counter
- Register
- Data section:全局变量
- Stack:临时变量
- Heap:动态开辟的内存
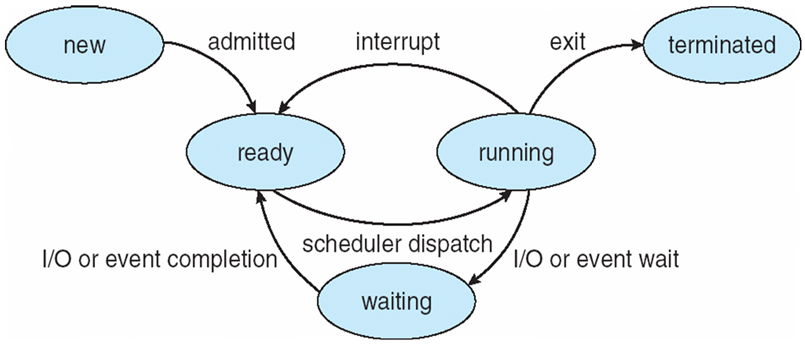
3.1.3 进程状态
- New(新):创建进程,在内存中开辟一段空间给进程
- Running(运行、执行): 进程正在使用CPU
- Ready(就绪):进程可以使用CPU
- Waiting(等待、blocked阻塞):进程等待一些事件的发生
- Terminated(终止):进程停止执行
3.1.4 进程状态的切换
- 程序:系统调用
- 操作系统:调度
- 外部程序:中断
- 只有ready状态才能转换到running状态
- 三个基本状态之间可能转换和转换原因如下:
- ready→running:当处理器空闲时,进程调度程序必将处理机分配给一个处于ready状态的进程 ,该进程便由ready状态转换为running状态
- running→waiting:处于running状态的进程在运行过程中需要等待某一事件发生后(例如因I/O请求等待I/O完成后),才能继续运行,则该进程放弃处理器,从running状态转换为waiting状态
- waiting→ready:处于waiting状态的进程,若其等待的事件已经发生,于是进程由waiting状态转换为ready状态。
- running→ready:处于running状态的进程在其运行过程中,因分给它的处理器时间片已用完,而不得不让出(被抢占)处理器,于是进程由running态转换为ready态。
- waiting→running,ready→waiting这二种状态转换一般不可能发生
- 处于running状态进程:如系统有一个处理器,则在任何一时刻,最多只有一个进程处于运行状态。
- 处于ready状态进程:一般处于就绪状态的进程按照一定的算法(如先来的进程排在前面,或采用优先权高的进程排在前面)排成一个就绪队列。
- 处于waiting状态进程:处于等待状态的进程排在等待队列中。由于等待事件原因不同,等待队列也可以按事件分成几个队列。
例:

3.1.5 进程与程序的区别
- 进程是动态的,程序是静态的:程序是有序代码的集合;进程是程序的执行
- 进程是暂时的,程序是永久的:进程是一个状态变化的过程,程序可长久保存
- 进程与程序的组成不同:进程的组成包括程序、数据和进程控制块(即进程状态信息)
- 进程与程序的对应关系:通过多次执行,一个程序可对应多个进程;通过调用关系,一个进程可包括多个程序
3.1.6 PCB 进程控制块
- 每个进程在操作系统内用进程控制块(Process Control
Block)来表示,它包含与特定进程相关的许多信息:
- Process state:进程状态
- Program counter:当前进程执行到的位置
- CPU registers:CPU中的寄存器
- CPU scheduling information:CPU的调度信息
- Memory-management information:内存管理信息
- Accounting information:统计信息
- File management :文件管理信息
- I/O status information:输入/输出状态信息

3.2 Process Scheduling 进程调度
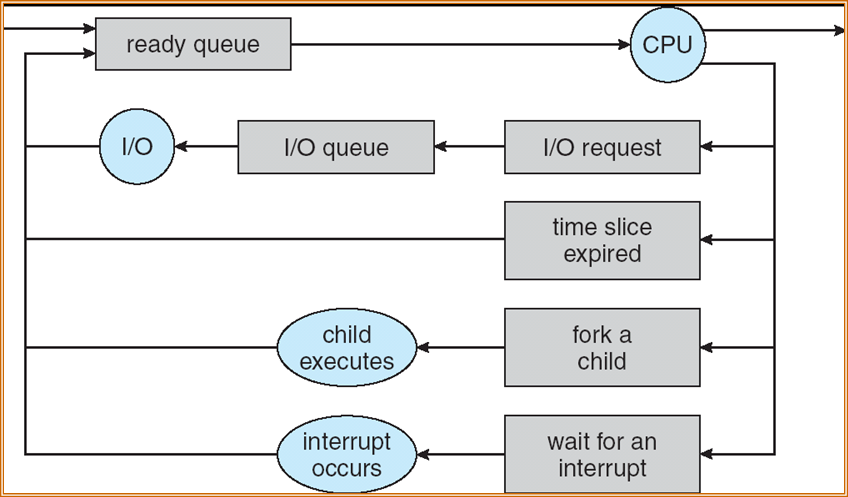
3.2.1 Scheduling Queue 调度队列
- Job queue作业队列:系统中所有进程的集合
- Ready queue就绪队列:驻留在主存中、就绪并等待执行的所有进程的集合
- Device queue设备队列:等待I/O设备的一组进程
进程会在不同队列之间迁移
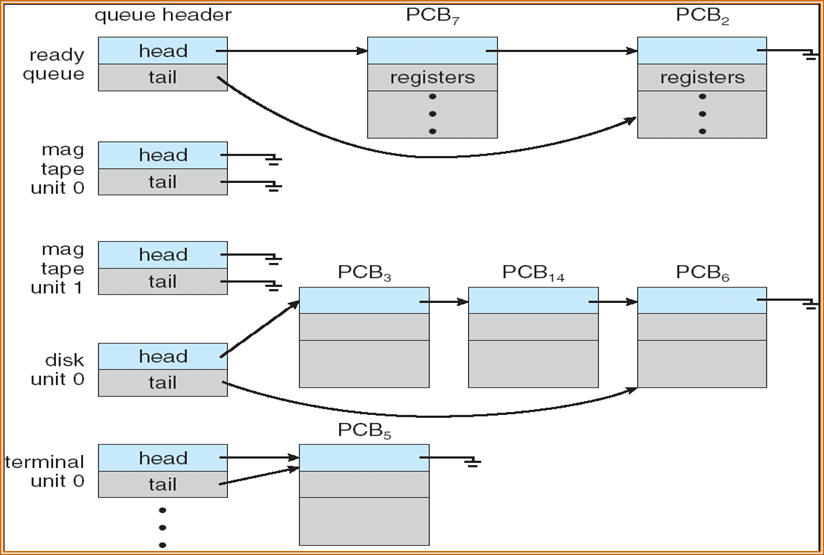
进程调度的表示
3.2.2 Schedulers 调度器
- Long-term scheduler / job scheduler:长程调度 /
作业调度
- 控制ready queue的长度:选择应加入ready queue的进程
- 调用的频率很低,基本上以秒/分钟为单位
- 控制多道程序设计multiprogramming的程度
- 大多数现代操作系统没有长期调度程序(如Windows、UNIX、Linux)
- Short-term scheduler / CPU scheduler:短程调度 /
CPU调度
- 选择ready queue中的哪一个进程能够进入CPU
- 调用的频率很好高,基本上以毫秒为单位
- Medium-Term Scheduler:中程调度
- 将一些进程从内存中临时移出,从而减少调度器须要处理进程的数目
- 这样将进程移出内存的机制叫做换出(Swapping)
- 按需调用,可以关闭中程调度
- 进程可以被分为:
- I/O-bound process:I/O型进程,需要做很多的I/O操作,有很多的CPU中断
- CPU-bound process:CPU型进程,需要很多的计算
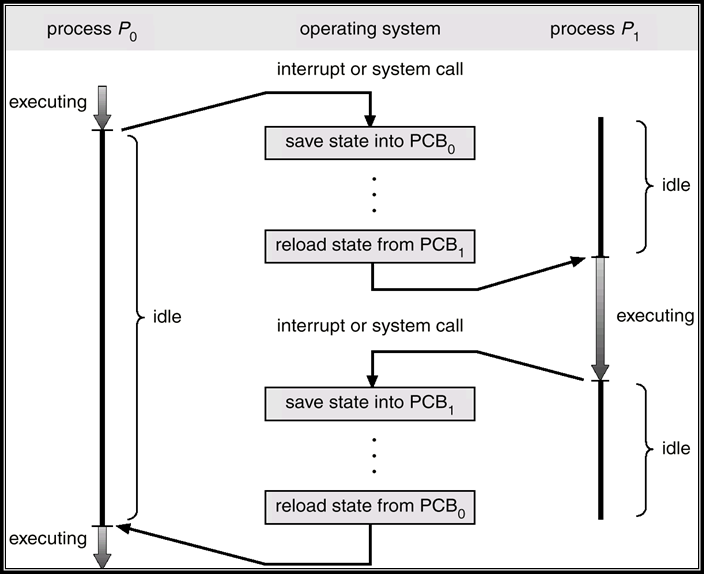
3.2.3 Context Switch 上下文切换
- 当CPU切换到另一个进程时,系统必须保存旧进程的状态,并通过上下文切换(Context Switch)加载新进程的保存状态
- 上下文切换时间开销大;系统在切换时没有任何有用的工作
- 时间取决于硬件支持
3.2.4 移动端的多任务
- 由于屏幕的实际情况,iOS的用户界面限制了
- 单个前台进程:通过用户界面控制
- 多个后台进程:内存中、正在运行,但不在显示器上,并且有限制
- 限制包括单个、短任务、接收事件通知、特定的长时间运行任务,如音频播放
- Android运行前台和后台,限制更少
- 后台进程使用服务执行任务
- 即使后台进程挂起,服务也可以继续运行
- 服务没有用户界面,占用内存少
3.3 Operations on Process 进程的操作
3.3.1 Process Creation 进程创建
父进程创建子进程,子进程又创建其他进程,形成进程树
通常,通过进程标识符(process identifier,pid)识别和管理进程
资源共享:
- 父进程和子进程共享所有资源
- 子进程共享父进程资源的子集
- 父进程和子进程不共享资源
执行:
- 父进程和子进程同时执行
- 父进程一直等到子进程结束
地址空间:
- 子进程是父进程的副本
- 子进程已经加载进了一段程序
例:UNIX
- fork():系统调用,用于创建一个新的进程
- int pid1 = fork();
- 父进程使用fork创建子进程时,子进程会生成一份父进程的备份,除了返回值之外,两者完全一样
- 从系统调用fork中返回时,两个进程除了返回值pid1不同外,具有完全一样的用户级上下文
- 在子进程中,pid1的值为0
- 在父进程中, pid1的值为子进程的进程号
- exec():系统调用,用于在fork之后调用新程序,替换进程的内存空间
- exit():系统调用,终止子进程,并给父进程返回参数
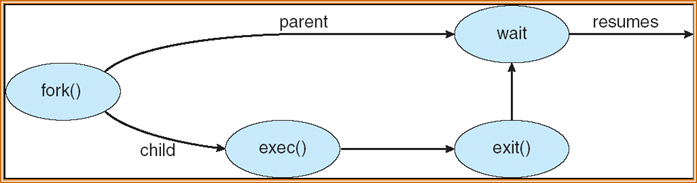
- fork():系统调用,用于创建一个新的进程
C语言代码示例:进程的创建过程
|
3.3.2 Process Termination 进程终止
- 引起进程终止的事件
- 正常结束
- 异常结束
- 外界干预
- 进程执行完最后一条指令后,会询问操作系统如何终止它
- 从子进程向父进程输出数据
- 操作系统释放该进程的数据
- 如果父进程被终止,那么子进程会发生:
- 有些操作系统不会让子进程继续运行
- 子进程通过cascading termination终止运行
- 子进程被过继到另一个父进程
- 移动端操作系统
- 会因为系统资源不够,而终止一些进程
- 此时要有一个进程的优先级排序,从重要到不重要,排序如下:
- 前端进程
- 可见进程
- 服务进程
- 后台进程
- 空进程
- Android会优先终止最不重的进程
3.4 IPC:Interprocess Communication 进程通信
Independent Process:独立进程,不被其它进程的执行影响,也不能影响其它进程的执行
Cooperating Process:合作进程,可以其它进程的执行影响,也可以影响其它进程的执行
- 优点:
- 信息共享
- 加速计算
- 模块化
- 更加便捷
- 需要IPC:Interprocess Communication,进程通信
- 优点:
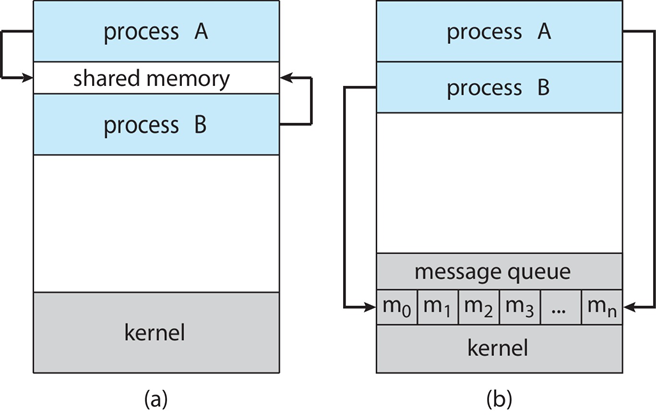
IPC的两种模式
- 共享内存
- 消息传递
通信类型:
- 直接通信
- send(P, message):直接发消息给进程P
- receive(Q, message):直接接收来自进程Q的消息
- 间接通信
- send(A, message):发送消息给邮件服务器A
- receive(A, message):从邮件服务器A接收消息
- 直接通信
常用通信机制:
- 信号(signal):进程发送信号
- 共享存储区(shared memory):不同进程共享一段空间,进行通信
- 管道(pipe):进程间通过一种操作将结果传输过去
- 消息(message)
- 套接字(socket)
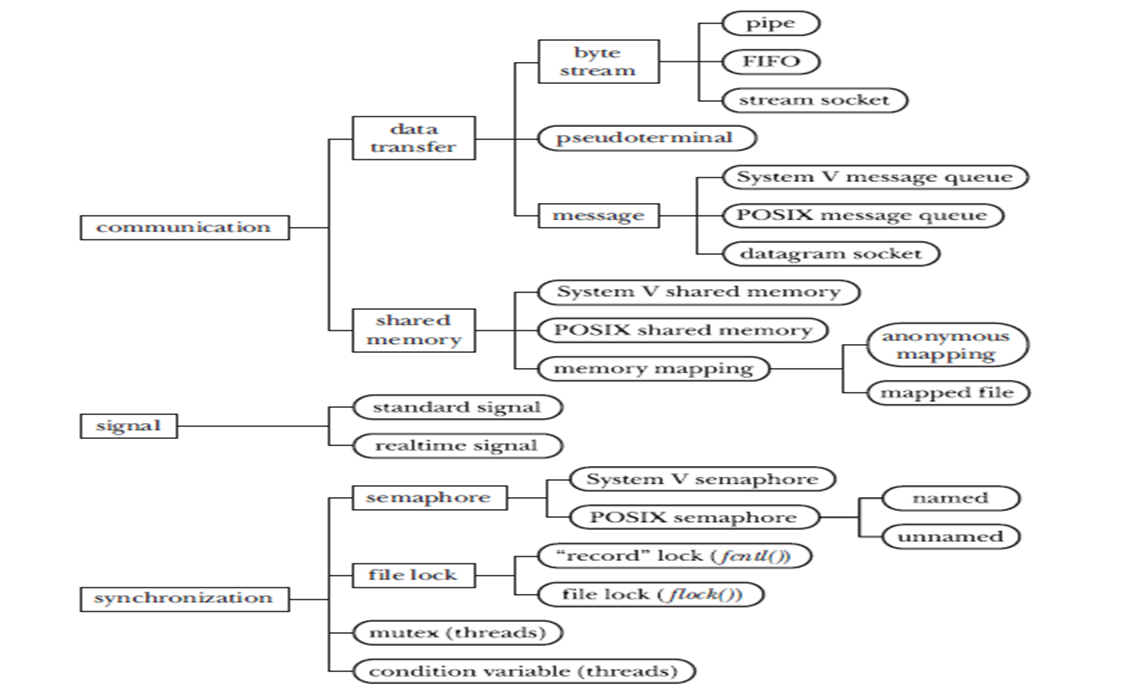
3.4.1 Linux进程通信机制
Linux实现进程间通信(IPC Inter Process Communication):
- System V IPC机制:
- 信号量:保证不同进程得到的信息是一样的
- 消息队列、
- 共享内存
- 管道(pipe)、命名管道
- 套接字(socket)
- 信号( signal )
- 文件锁(file lock)
- POSIX线程:
- 互斥锁(互斥体、互斥量)(mutex)、条件变量(condition variables)
- POSIX:
- 消息队列、信号、共享内存
3.4.2 Windows 进程线程通信机制
- 基于文件映射的共享存储区
- 无名管道和命名管道
- server32pipe.c、client32pipe.c
- 启动多个client进程进行通信
- 邮件槽
- 套接字
- 剪帖板(Clipboard)
- 信号
- 其他同步机制
3.5 IPC:in Shared-Memory Systems
- 希望通信的进程之间共享的内存区域
- 通信受用户进程的控制,而不是操作系统的控制
- 主要问题是:提供允许用户进程在访问共享内存时同步其操作的机制
- 在第6、7章会讨论同步
- 协同进程的并发执行需要允许进程相互通信并同步其操作的机制(第6章)。
- 合作过程的共同范式:Producer-Consumer Problem(生产者-消费者问题)
- 生产者进程生成消费者进程使用的信息
- unbounded-buffer(无限缓冲区):对缓冲区的大小没有实际限制。
- bounded-buffer(有限缓冲区):假设存在固定的缓冲区大小。
3.5.1 Bounded-Buffer:Shared-Memory Solution
Shared data
typedef struct {
...
}item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;为了保证进程对共享空间的正确操作,只能使用BUFFER_SIZE-1的空间
- 空间是一个循环队列
Producer:生产者,生成数据
item nextProduced;
while (1) {
produce an item in nextProduced;
// buffer中没有空位, 什么都不做
while ((in + 1) % BUFFER_SIZE == out);
// 向buffer中添加一个item
buffer[in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
}Consumer:消费者,使用数据
item nextConsumed;
while (1) {
// buffer中没有item, 什么都不做
while (in == out);
// 从buffer中拿走一个item
nextConsumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
consume the item in nextConsumed ;
}
3.6 IPC:in Message-Passing Systems
- 进程通信和同步其操作的机制
- 消息系统:流程之间无需借助共享变量即可进行通信
- IPC设施提供两种操作:
- send(message)
- receive(message)
- message的大小是固定的或可变的
- 如果进程P和Q想要沟通,他们需要:
- 在他们之间建立通信联系
- 通过发送/接收交换message
- 实现的任务:
- 如何建立链接?
- 一个链接可以与两个以上的进程关联吗?
- 每对通信进程之间可以有多少个链接?
- 链路的容量是多少?
- 链接可以容纳的消息大小是固定的还是可变的?
- 链路是单向的还是双向的?
- 通信链路的实现
- 物理:
- 共享内存
- 硬件总线
- 网络
- 逻辑:
- 直接或间接
- 同步或异步
- 自动或显式缓冲
- 物理:
3.6.1 Direct Communication(直接通信)
- 进程必须明确命名:
- send(P, message):向进程P发送消息
- receive(Q, message):从进程Q接收消息
- 通信链路的属性
- 自动建立链接
- 链接只与一对通信进程相关联
- 每对之间只有一条链路
- 链接可能是单向的,但通常是双向的
3.6.2 Indirect Communication(间接通信)
- message从mailbox(也称为port)定向和接收
- 每个mailbox都有唯一的id
- 进程只有在共享mailbox时才能通信
- 通信链路的属性
- 仅当进程共享common mailbox时才建立链接
- 链接可能与许多进程关联
- 每对进程可以共享多个通信链路
- 链接可以是单向的或双向的
- 操作
- 创建新的mailbox(port)
- 通过mailbox发送和接收message
- 销毁mailbox
- 基本操作:
- send(A, message):将消息发送到邮箱A
- receive(A, message):从邮箱A接收消息
3.6.3 Synchronization同步
- 消息传递可以是阻塞的或非阻塞的
- Blocking(阻塞)被认为是同步的
- Blocking send:发送方被阻止,直到确认消息被收到
- Blocking receive:在消息可用之前,接收器被阻止
- Non-blocking(非阻塞)被认为是异步的
- Non-blocking send:发送方不断发送消息
- Non-blocking receive:接收器不断接收消息,可能是有效消息,也可能是Null消息
- 可能的不同组合
- 如果发送和接收都被是Blocking,称为完整性过程have a rendezvous
3.6.4 Buffering
- 附加到链接的消息队列,以三种方式之一实施
- 零容量
- 链路上没有消息排队
- 发送方必须等待接收方接收完成后,才能再次发送消息
- 容量有限
- n条消息的有限长度
- 如果链接已满,发送方必须等待
- 无限容量
- 无限长度
- 发送程序从不等待
- 零容量
3.6.5 实例
- 例: 设计一个程序,要求
- 用函数msgget创建消息队列
- 从键盘输入的字符串添加到消息队列
- 创建一个进程,使用函数msgrcv读取队列中的消息并在计算机屏幕上输出
- 分析 :
- 程序先调用msgget函数创建、打开消息队列
- 接着调用msgsnd函数,把输入的字符串添加到消息队列中
- 子进程调用msgrcv函数,读取消息队列中的消息并打印输出
- 最后调用msgctl函数,删除系统内核中的消息队列
//msgfork.c |
分成两个独立的程序:msgsnd.c,msgrcv.c。分别编译和运行


3.7 IPC:example
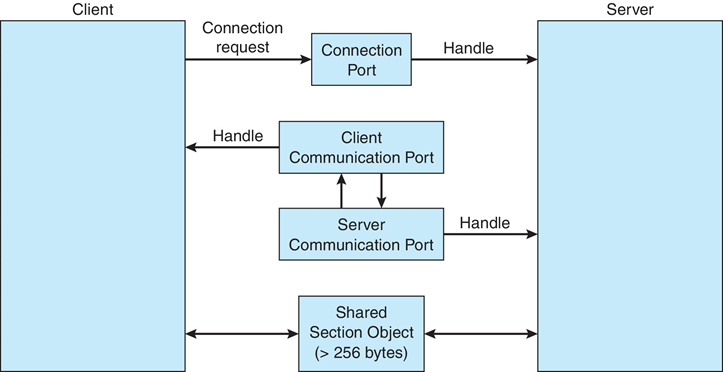
3.7.1 Windows
- 通过高级本地过程调用(LPC)功能以消息传递为中心
- 仅在同一系统上的进程之间工作
- 使用端口(如邮箱)建立和维护通信通道
- 通信工作如下:
- 客户端打开子系统连接端口对象的句柄
- 客户端发送连接请求
- 服务器创建两个专用通信端口,并将其中一个端口的句柄返回客户端
- 客户端和服务器使用相应的端口句柄发送消息或回调,并侦听回复
3.7.2 Pipe 管道通信
- 充当允许两个进程通信的管道
- 问题:
- 通信是单向的还是双向的?
- 在双向通信的情况下,是半双工还是全双工?(在工作时是否有一端读或写?)
- 沟通过程之间必须存在关系(即父子关系)吗?
- 管道可以通过网络使用吗?
- Ordinary pipes普通管道:无法从创建它的流程外部访问。通常,父进程创建个管道,并使用它与它创建的子进程通信。
- Named pipes命名管道:可以在没有父子关系的情况下访问。
3.7.2.1 Ordinary pipes
- 普通管道允许以标准 生产者-消费者 的形式进行通信
- 生产者写入一端(管道的写入端write-end)
- 消费者从另一端(管道的读取端read-end)读取
- 因此,普通管道是单向的
- 需要沟通流程之间的父子关系
- Windows调用这些匿名管道anoymous pipes
3.7.2.2 Named pipes
- 命名管道比普通管道更强大
- 通信是双向的
- 沟通过程之间不需要父子关系
- 多个进程可以使用命名管道进行通信
- 在UNIX和Windows系统上提供
3.8 Communication in Client–Server Systems
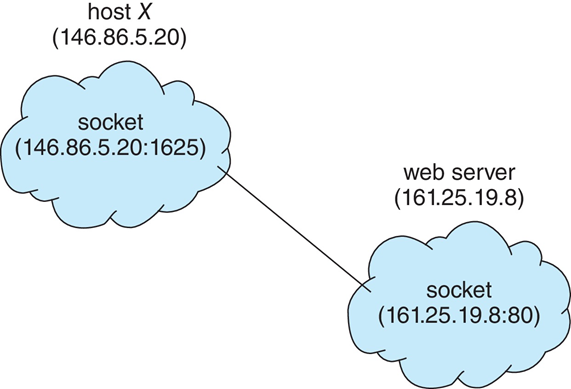
3.8.1 Socket 套接字
- Socket被定义为通信的端点
- IP地址和端口串联:消息包开头包含的数字,用于区分主机上的网络服务
- socket 161.25.19.8:1625指:主机161.25.119.8上的端口1625
- 通信由一对socket组成
- 1024以下的所有端口都是众所周知的,用于标准服务
- 特殊IP地址127.0.0.1(loopback),用于指运行进程的系统
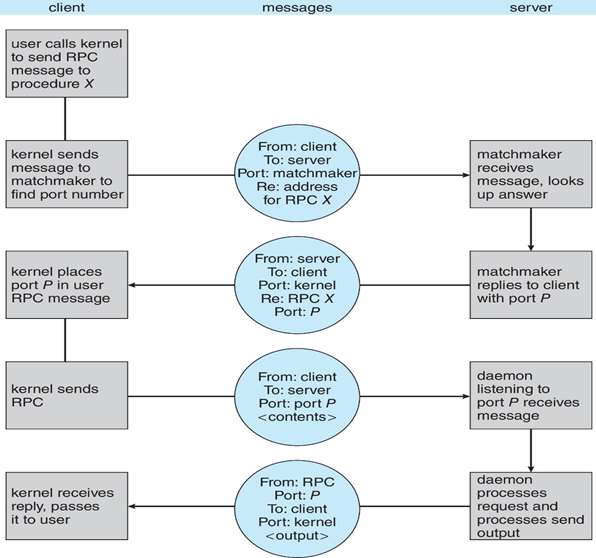
3.8.2 Remote Procedure Calls 远过程调用
- Remote Procedure
Calls(RPC,远过程调用):抽象网络系统上进程之间的过程调用
- 再次使用端口来区分服务
- 存根stubs:服务器上实际过程的客户端代理
- 客户端存根The client-side stub:定位服务器并整理(marshalls)参数
- 服务器端存根The server-side stub:接收此消息,解压缩编组参数,并在服务器上执行过程
- 在Windows上,stub代码根据用Microsoft接口定义语言(MIDL)编写的规范编译
- 通过外部数据表示(XDL,External Data
Representation)格式处理数据表示,以考虑不同的体系结构
- 大端和小端
- 远程通信比本地通信有更多的故障情况
- 消息只能传递确定的一次,而不能最多传递一次
- 操作系统通常提供rendezvous / matchmaker服务来连接客户端和服务器
- Android RPC的执行过程:
Chapter 4:Threads & Concurrency
4.1 Overview
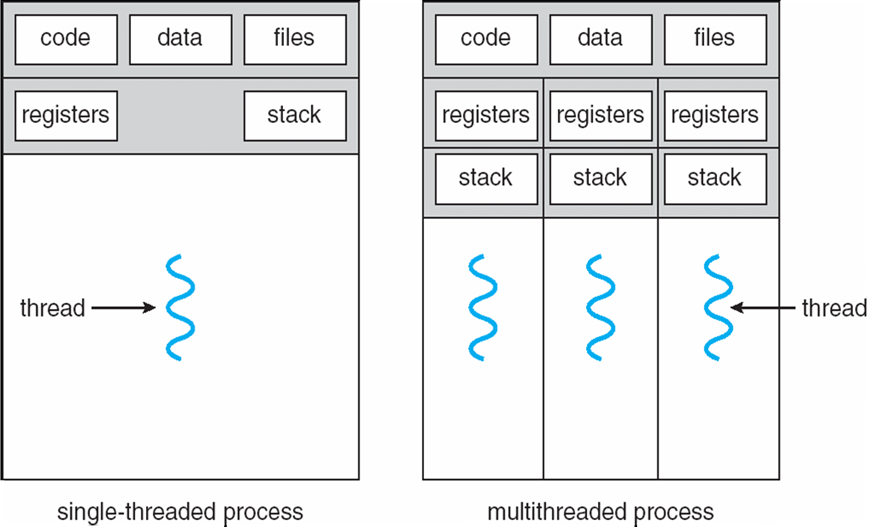
进程:
- 资源拥有单位:
- 给每个进程分配一虚拟地址空间
- 保存进程映像
- 控制一些资源(文件,I/O设备)
- 有状态、优先级、调度
- 调度单位:
- 进程是由一个或多个程序的一次执行
- 可能会与其他进程交替执行
4.1.1 线程Thread的概念
- 进程:资源的拥有单元称为进程 / 任务
- 线程:资源的调度单位称为线程 /
轻型进程(light weight process)
- 线程只拥有在运行中必不可省的资源(PC、register、stack)
- 但它可与同属一个进程的其它线程共享进程拥有的全部资源
线程定义为:进程内一个执行单元或一个可调度实体
- 有执行状态(状态转换)
- 不运行时保存上下文
- 有一个执行栈
- 有一些局部变量的静态存储
- 可存取所在进程的内存和其他资源
- 可以创建、撤消另一个线程
4.1.2 线程的特点
- 不拥有系统资源(只拥有少量的资源,资源是分配给进程)
- 一个进程中的多个线程可并发执行(进程可创建线程执行同一程序的不同部分)
- 系统开销小、切换快。(进程的多个线程都在进程的地址空间活动)
4.1.3 线程的优点
- 创建一个新线程花费时间少(结束亦如此)
- 两个线程的切换花费时间少
- 如果机器设有 “存储[恢复]所有寄存器” 指令,则整个切换过程用几条指令即可完成
- 因为同一进程内的线程共享内存和文件,因此它们之间相互通信无须调用内核
- 适合多处理机系统
4.1.4 线程的使用案例
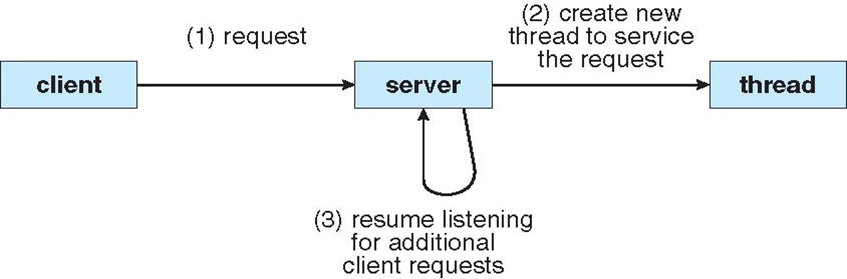
- LAN中的一个文件服务器,在一段时间内需要处理几个文件请求
- 有效的方法是:为每一个请求创建一个线程
- 在一个SMP机器上:多个线程可以同时在不同的处理器上运行
- 一个线程显示菜单,并读入用户输入;另一个线程执行用户命令
- 考虑一个应用:由几个独立部分组成,这几个部分不需要顺序执行,则每个部分可以以线程方式实现
- 当一个线程因I/O阻塞时,可以切换到同一应用的另一个线程
4.2 多核编程
多核系统给程序员带来新的挑战:
- 划分活动
- 负载均衡:保证任务的计算量尽量均衡
- 数据拆分
- 数据依赖性
- 测试和调试
多线程服务端结构
- 服务端、客户端各自是一个进程
- 当有请求时,服务端创建一个线程,处理请求
多核系统的并行执行:
4.3 Multithreading Models
线程的实现机制:
- 用户级线程 user-level thread
- 内核级线程 kernel-level thread
- 两者结合方法
4.3.1 User Threads 用户级线程
- 用户级线程:
- 不依赖于OS核心(内核不了解用户线程的存在)
- 应用进程利用线程库提供创建、同步、调度和管理线程的函数来控制用户线程
- 如:数据库系统informix、图形处理Aldus PageMaker
- 调度由应用软件内部进行,通常采用非抢先式和更简单的规则,也无需用户态/核心态切换,所以速度特别快
- 一个线程发起系统调用而阻塞,则整个进程在等待。
- 特点:
- 用户线程的维护由应用进程完成
- 内核不了解用户线程的存在
- 用户线程切换不需要内核特权
- 用户线程调度算法可针对应用优化
- 一个线程发起系统调用而阻塞,则整个进程在等待(多对一模型中)
- 三个主要的线程库(创建用户级线程)
- POSIX Pthreads 、 Win32 threads、 Java threads
4.3.2 Kernel Threads 内核级线程
- 内核级线程:
- 依赖于OS内核,由内核的内部需求进行创建和撤销,用来执行一个指定的函数
- 一个线程发起系统调用而阻塞,不会影响其他线程
- 时间片分配给线程,所以多线程的进程获得更多CPU时间
- 特点:
- 内核维护进程和线程的上下文信息
- 线程切换由内核完成
- 时间片分配给线程,所以多线程的进程获得更多CPU时间
- 如1个进程拥有10个线程,4个进程各自拥有1个线程,则CPU会对这14个线程进行分配资源
- 一个线程发起系统调用而阻塞,不会影响其他线程的运行
- Examples
- Windows XP/2000 及以后
- Solaris
- Linux
- Mac OS X
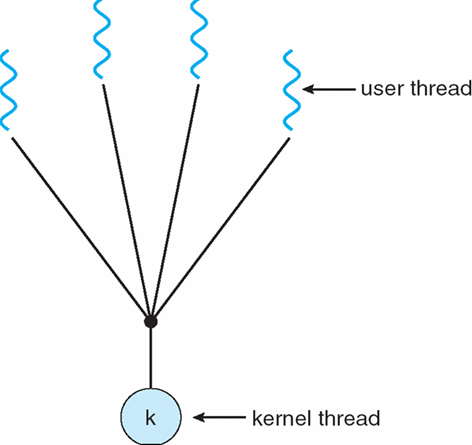
4.3.3 Many-to-One 多个用户线程, 一个内核线程
多个用户级线程 映射到 单个内核线程
由用户级运行库实现
- 在用户级别创建、调度和同步线程
操作系统不知道用户级线程
- 操作系统认为每个进程只包含一个控制线程
示例:
- Solaris Green Threads
- GNU Portable Threads
优点:
- 不需要操作系统支持,全部在用户态模式进行
- 可以由用户自己设定调整调度策略,以满足应用程序需求
- 由于没有系统调用,因此降低了线程操作的开销
缺点:
- 无法利用多处理器,不是没有真正并行,而是在多个用户级线程之间进行轮转
- 当一个线程阻塞时,整个进程块也会阻塞
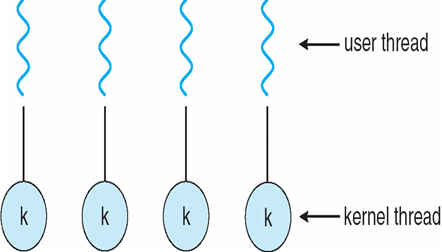
4.3.4 One-to-One 一个用户线程, 一个内核线程
每个用户级线程 都映射到 内核线程
- 操作系统为每个用户级线程提供一个内核线程
- 每个内核线程独立调度
- 操作系统执行的线程操作(创建、调度、同步)
- 示例
- Windows NT/XP/2000操作系统
- Linux操作系统
- Solaris 9及更高版本
- 优点:
- 每个内核线程在多处理器中,均可平行执行
- 当一个线程阻塞时,其它线程还能被正常调度
- 缺点:
- 线程间的操作消耗过大
- 操作系统会随着线程数目的增加而变大
4.3.5 Many-to-Many 多个用户线程, 多个内核线程
将多个用户级线程 映射到 多个内核线程
- 允许操作系统创建足够数量的内核线程
- 示例:
- Solaris版本9之前的版本
- 带有ThreadFiber软件包的Windows NT/2000
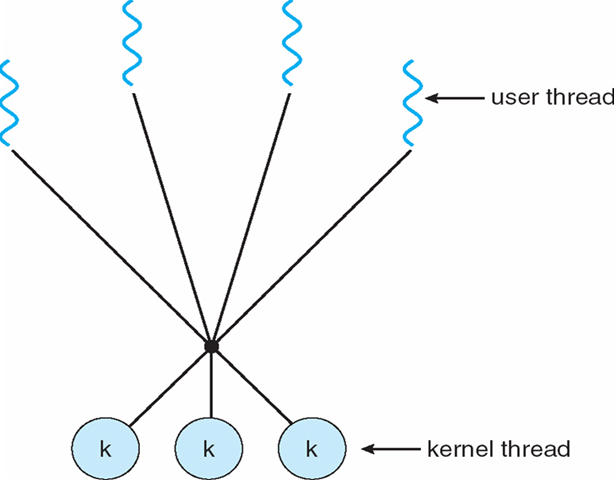
4.3.6 Two-level Model 两级模型
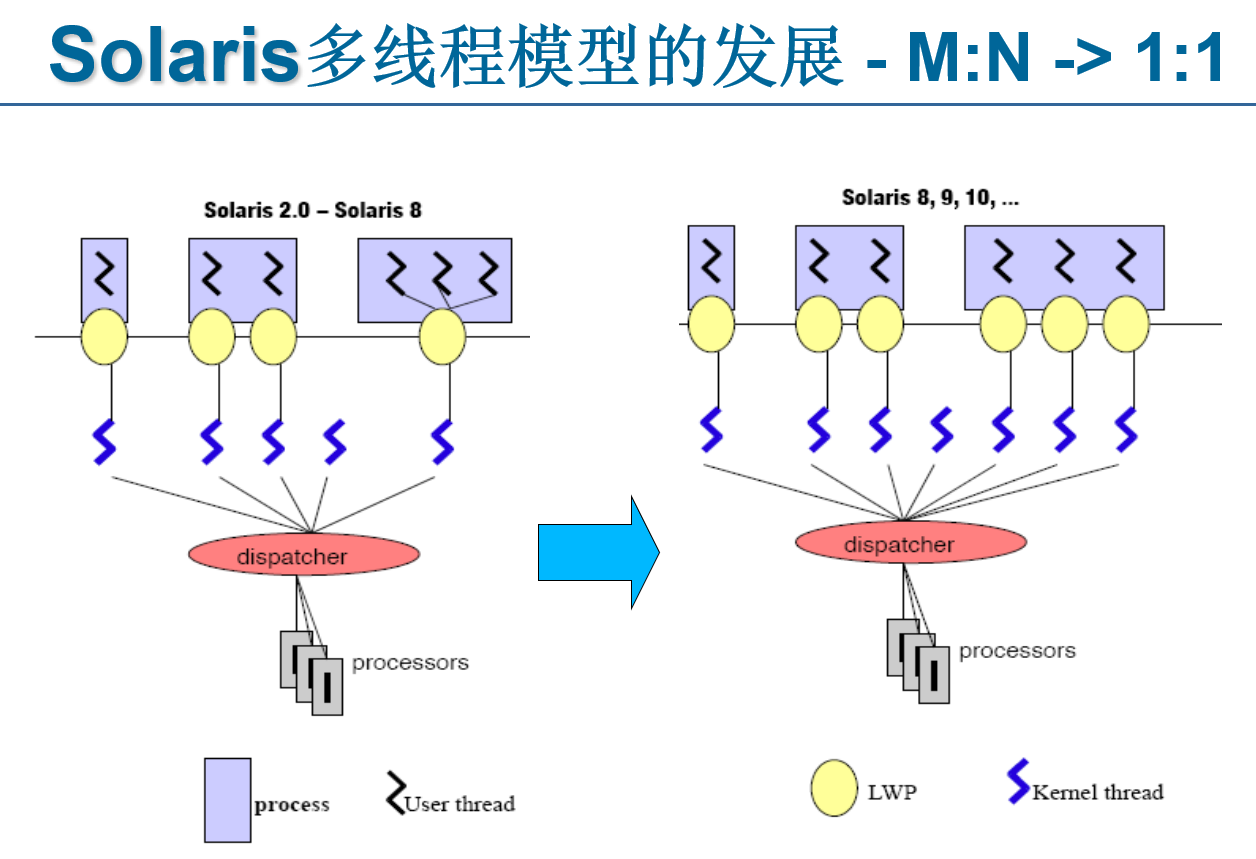
- Solaris的多线程是与传统UNIX调度模型相区别的主要特征
- LWP:每个进程内的内核线程的虚拟执行环境
- LWP允许进程内的内核线程互相独立地进行系统调用
- 如果没有LWP,一次就只能进行一次系统调用
- 每次的系统调用由一个线程来引发,它的寄存器会被放在LWP的堆栈里面,等它返回的时候,系统调用返回代码也会被放在LWP里面
- M-N的优点:
- 快速的用户线程创建和删除
- 线程同步不需要系统调用
- 快速的用户线程上下文切换
- M-N的缺点:
- 复杂的编程模型
- 信号处理的问题
- 1-1模型的优点:
- 每个用户级线程都有一个lwp和一个 kthread 相对应
- 只有内核级的线程调度
- 线程创建和删除、线程同步的开销大
- 线程调度和同步更到位
4.3.7 Solaris用户线程、内核线程、LWP三者之间的关系
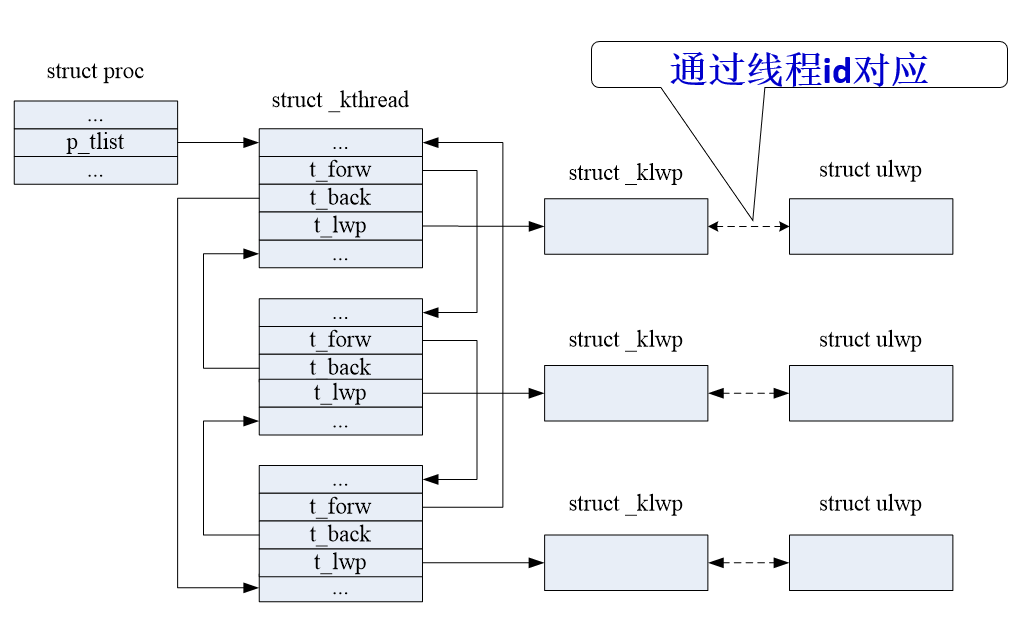
- 对于一个用户进程来说,它的每个线程分成两个部分,一个部分是用户态下的部分,一个是系统态下的部分,也就是用户线程和内核线程
- 一个线程在用户态下执行的时候,运行的是用户线程的代码,而当发生系统调用的时候,就由内核线程来执行内核代码
- 在Solaris的线程模型中,每一个用户线程对应一个内核线程,这种对应通过lwp来体现。
- 所用的内核线程串成一个双向循环链表,可以通过进程的proc结构中的p_tlist字段找到这个链表
- 每一个lwp用_ klwp数据结构表示,每个内核线程用一个_ kthread结构表示,_ kthread结构中有一个字段t_lwp指向它所对应的**_klwp**结构。
- 用户线程用ulwp表示,ulwp与**_kthread的对应不是用指针来表示的,而是通过线程id**
- ulwp,**_kthread和_klwp中都有一个字段表示线程的id,通过id**它们就可以一一对应起来
4.4 Thread Libraries 线程库
- 线程库为程序员提供了创建和管理线程的API
- 实施的两种主要方式
- 没有内核支持的库:代码和数据结构都在用户空间,只导致用户空间中本地函数调用(而不是系统调用)
- 由操作系统直接支持的内核级库:代码和数据结构都在内核空间,通常导致系统调用
4.4.1 Pthread
可以作为用户级或内核级提供
用于线程创建和同步的POSIX(Portable Operating System Interface,便携式操作系统接口)标准(IEEE 1003.1c)API
http://standards.ieee.org/reading/ieee/stad_public/description/posix
API指定线程库的行为,实现取决于库的开发
在UNIX操作系统(Solaris、Linux、Mac OS X)中常见
4.4.2 Java Threads
- Java线程由JVM管理
- 通常使用底层OS提供的线程模型实现
- Java线程可以通过以下方式创建:
- extend 线程类
- 实现Runnable接口
4.5 Implicit Threading 隐私多线程
- 多核系统多线程编程,一个应用程序有可能有几百个甚至上千的线程,这样的程序面临许多挑战
- 编程挑战:任务分解、任务的工作量平衡、数据分割、数据依赖、测试与调试
- 程序执行顺序的正确性问题:同步、互斥
- 策略:隐私线程Implicit
Threading,当前一种流行趋势
- 将线程的创建与管理交给编译器和运行时库来完成
- 几种隐私线程的设计方法:
- Thread Pools:线程池
- Fork Join
- OpenMP:用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案
- OpenMP支持的编程语言包括C、C++和Fortran。
- Grand Central Dispatch(GCD,大中央调度)
- Apple for its macOS and iOS operating systems.
- Intel Thread Building Blocks(TBB):
- Intel开发的构建多线程库,open source
- TBB是一个可移植的C++库,能够运行在Windows、Linux、Macintosh以及UNIX等系统上
- Java
4.5.1 Thread Pool 线程池
- 预先创建出一系列线程,然后分配
- 线程池中如果没有空余线程,则需要等待
4.5.2 Fork-Join Parallelism
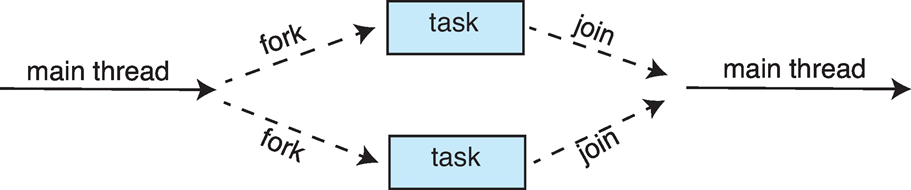
主线程将任务分为多个子任务fork,然后再合并到主线程join
伪代码

这一过程可以递归的进行
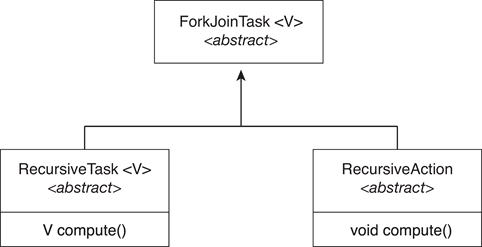
示例:
- The ForkJoinTask is an abstract base class
- RecursiveTask and RecursiveAction classes extend ForkJoinTask
- RecursiveTask returns a result (via the return value from the compute() method)
- RecursiveAction does not return a result


4.5.3 OpenMP
编译器指令集和C、C++、FORTRAN的API
为共享内存环境中的并行编程提供支持
标识并行区域–可以并行运行的代码块
int main(){
/* 串行代码 */
{
printf("I am a parallel region.");
}
for(int i = 0; i < N; i++)
c[i] = a[i] + b[i];
/* 串行代码 */
return 0;
}
4.5.4 Grand Central Dispatch
用于macOS和iOS操作系统的Apple技术
C、C++和Objective-C语言、API和运行时库的扩展
允许识别平行部分
管理线程的大部分细节
块位于“^{}”:
^{printf("I am a block");}
Block放置在调度队列中
- 从队列中移除时,分配给线程池中的可用线程
两种类型的调度队列:
- 串行:按FIFO的顺序删除块,队列按进程,称为主队列
- 程序员可以在程序中创建额外的串行队列
- 并行:按FIFO的顺序删除块,但一次可以删除多个
- 按服务质量划分的四个全系统队列:
- QOS_CLASS_USER_INTERACTIVE
- QOS_CLASS_USER_INITIATED
- QOS_CLASS_USER_UTILITY
- QOS_CLASS_USER_BACKGROUND
- 串行:按FIFO的顺序删除块,队列按进程,称为主队列
对于Swift语言,任务定义为闭包,类似于块,减去插入符号
- 使用dispatch_async()函数将闭包提交到队列
let queue = dispatch.get.global.queue(QOS.CLASS.USER/INITIATED, 0)
dispatch.async(queue, {print("I am a closure.")} )
4.5.5 Intel Threading Building Blocks (TBB)
用于设计并行C++程序的模板库
简单for循环的串行版本
for(int i = 0; i < n; i++)
apply(v[i]);使用TBB的parallel_for语句编写的for循环:
parallel_for(size_t(0), n, [=](size_t i){ apply(v[i]); } );
4.6 Threading Issues
- fork()和exec()系统调用的语义
- 目标线程的线程删除
- 异步或延迟
- 信号处理
- 线程池
- 线程特定数据
- 调度器激活
4.6.1 fork()和exec()的语义
- fork():有的Unix系统有两种形式的fork(),与应用程序有关
- 复制所有线程:如果调用fork()后不调用exec(),复制所有线程
- 只复制调用fork()的线程:如果调用fork()后立即调用exec(),操作系统只需复制调用fork()的线程
- exec():如果一个线程调用exec(),exec()参数指定的程序会替换整个进程(包括所有线程)
4.6.2 Thread的删除
- 线程取消(thread cancellation):在线程完成之前终止线程的任务,要取消的线程称为目标线程
- 线程取消的两种情况:
- 异步取消(asynchronous
cancellation):由一个线程立即终止目标线程。
- 对于异步取消,因为如果在已经给目标线程分配资源或目标线程正在更新与其他线程共享的数据的情况下,操作系统从回收系统资源时不能将所有资源全部回收。
- 延迟取消(deferred cancellation):目标线程周期性地检查其是否应该终止,允许目标线程以有序方式终止自己
- 异步取消(asynchronous
cancellation):由一个线程立即终止目标线程。
4.6.3 Signal Handling 信号处理
- UNIX系统中使用信号通知进程发生了特定事件
- 信号处理器用于处理信号
- 信号由特定事件生成
- 信号被传递到进程
- 信号已处理
- Options:
- 将信号传递给信号适用的线程
- 将信号传递给进程中的每个线程
- 将信号传递给进程中的某些线程
- 分配特定线程以接收进程的所有信号
- 信号可分为同步和异步:
- 同步信号:被发送到产生信号的同一进程
- E.g. 非法访问内存、被0所除
- 异步信号:由运行进程之外的事件产生,通常被发送到另一进程
- E.g. 使用特殊键、定时器到期
- 同步信号:被发送到产生信号的同一进程
4.6.4 Thread Pool 线程池
- 多线程服务器的潜在问题:
- 处理请求前创建线程需要时间,线程完成工作后要被丢弃;
- 如果允许所有并发请求都用新线程处理,则无法限制系统中并发执行的线程数量,大量消耗系统资源
- 在等待工作的池中创建多个线程
- 优点:
- 使用现有线程服务请求通常比创建新线程稍快
- 允许将应用程序中的线程数绑定到池的大小
4.6.5 Thread Specific Data 线程特有数据
- 允许每个线程拥有自己的数据副本
- 当您无法控制线程创建过程时(即使用线程池时),此功能非常有用
4.6.5 Scheduler Activations 调度器激活
- M:N和两级模型都需要通信来维护分配给应用程序的适当数量的内核线程
- 轻量级进程(Lightweight process, LWP):实现多对多模型或二级模型的系统在用户线程和内核线程之间通常设置一种中间数据结构,通常为LWP。
- 对于用户线程库,LWP表现为一种应用程序可以调度用户线程来运行的虚拟处理器。每个LWP与内核线程相连,该内核线程被操作系统调度到物理处理器上运行。如果物理处理器上运行的内核线程阻塞,则与其相连的LWP也阻塞,关系链顶端与LWP相连的用户线程也阻塞
- 调度程序激活提供了向上调用:一种从内核到线程库的通信机制
- upcall:内核通知应用程序与其有关的特定事件的过程;
- upcall handler:upcall处理句柄,在虚拟处理器(LWP)上运行。
- 此通信允许应用程序维护正确数量的内核线程
调度器激活(scheduler activation):一种解决用户线程与内核间通信的方法。
- 工作方式:内核提供一组LWP给应用程序,应用程序可调度用户线程到一个可用的LWP上。
- 当一个应用线程将要阻塞时,事件引发内核发送upcall到应用程序,通知应用程序线程阻塞并标识特殊线程
- 内核分配一个新的LWP给应用程序
- 应用程序在该新LWP上运行upcall handler:
- 保存该阻塞线程的状态
- 放弃阻塞线程运行的原虚拟处理器
- upcall handler调度另一个适合在新LWP上运行的线程
- 当原先阻塞的线程准备好执行时,内核发送另一个upcall到线程库,通知线程库原先阻塞的线程已经能够运行了
- 内核可能分配一个新的LWP
- 或抢占一个用户线程并在其LWP用于运行处理该事件的upcall handler
- 应用程序将已处于未堵塞状态的线程标记为“能够运行”,调度一条合适的线程到可用LWP上运行
4.7 Operating-System Examples
4.7.1 Windows XP Thread
- 应用程序以独立进程方式运行,每个进程可包括一个或多个线程
- 使用一对一映射,也提供对fiber库的支持(多对多模型)
- 每个线程包含
- 线程id
- 寄存器集
- 独立的用户堆栈和内核堆栈
- 专用数据存储区
- 寄存器集、堆栈和专用存储区域称为线程的上下文
- 同属一个进程的每个线程都能访问进程的地址空间
- 线程的主要数据结构包括:
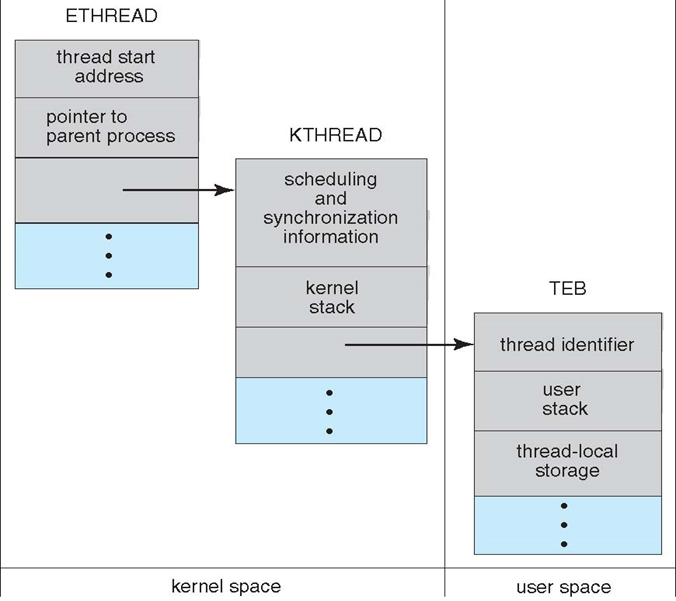
- ETHREAD(executive thread block):执行线程块,包括指向线程所属进程的指针、线程开始控制的子程序的地址、指向KTHREAD的指针
- KTHREAD(kernel thread block):内核线程块,包括线程的调度和同步信息、指向内核栈的指针、指向TEB的指针
- TEB(thread environment block):用户空间的数据结构,供线程在用户模式下运行时访问,包含许多其他域、用户模式栈、用于线程特定数据的数组
4.7.2 Linux Threads
Linux不区分进程和线程,通常称之为任务(task)
- Task_struct:Linux系统中每个任务都有一个唯一的内核数据结构struct task_struct,它并不保存任务本身的数据,而是指向其他存储这些数据的数据结构(e.g. 打开文件列表、信号处理信息、虚拟内存等)的指针
系统调用fork()提供传统进程复制功能,系统调用clone()提供创建线程功能。
调用fork()时,所创建的新任务具有父进程所有数据的副本
调用clone()时,所创建新任务根据所传递标志集指向父任务的数据结构。
调用clone()时传递一组标志,决定父任务与子任务之间发生多少共享

Chapte 5:CPU Scheduling
5.1 基础概念 Basic Concepts
5.1.1 CPU调度
CPU调度 == 处理器调度 == 进程调度
最大化CPU的利用率
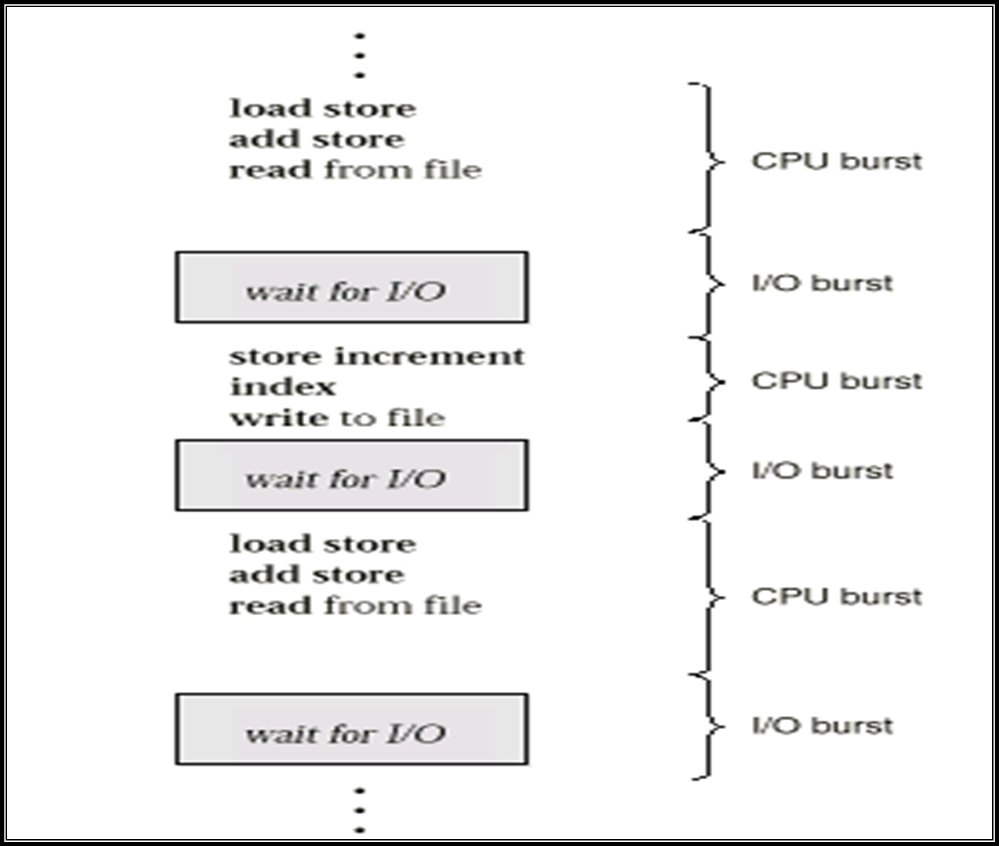
进程执行的特点:CPU Burst 和 I/O Burst交替进行
- CPU Burst Time,I/O Burst Time
- CPU-bound program:以CPU计算为主的程序
- I/O-bound program:以I/O为主的程序
- 只考虑进程的CPU Burst Time
进程的CPU Burst Time的统计规律
- 短时间的CPU Burst Time占据绝大部分
- 因此CPU调度是高频调度
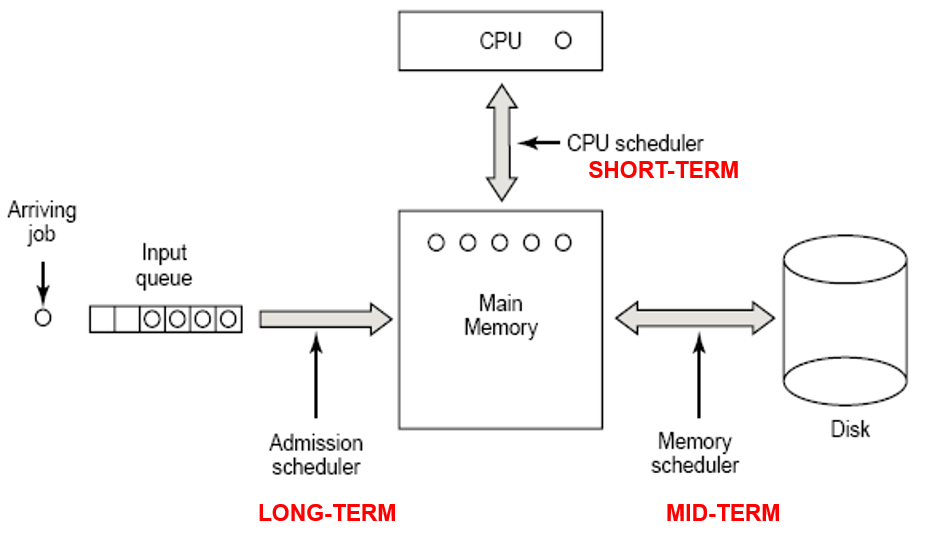
5.1.2 CPU调度器 Scheduler
- 调度器起作用的时机:
- 进程从running到waiting状态
- 进程从running到ready状态
- 进程从waiting到ready状态
- 进程终止
- 调度方式:
- Nonpreemptive非抢占式调度:
- 调度程序一旦把处理器分配给某进程后,它便会一直运行下去,直到进程完成或发生某事件而阻塞时,才把处理器分配给另一个进程
- 调度时机:上述1、4
- Preemptive抢占式调度:
- 当一个进程正在运行时,系统可以基于某种原则,剥夺已分配给它的处理机,将之分配给其它进程
- 剥夺原则有:优先权原则、短进程优先原则、时间片原则
- 调度时机:上述2、3
- Nonpreemptive非抢占式调度:
5.1.3 调度程序 Dispatcher
- 实际执行调度的模块,任务如下:
- 切换上下文
- 切换到user mode
- 跳转到user program中正确的位置,并且重新启动program
- Dispatcher Latency调度延迟:调度程序停止一个进程到启动一个进程所需要的时间
5.2 调度标准 Scheduling Criteria
5.2.1 调度算法的选择准则和评价
- 面向用户(User-oriented)的准则和评价
- 周转时间Turnaround
time:进程从提交到完成所经历的时间。包括:在CPU上执行,就绪列和阻塞队列中等待。
- 周转时间 T = 完成时间 - 提交时间
- 平均周转时间 = \(\sum\) 周转时间/进程数
- 带权周转时间W = T(周转时间)/t(CPU执行时间)
- 平均带权周转时间 = \(\sum\) W/进程数
- 响应时间Response
time:从进程提出请求到首次被响应的时间段
- 第一次被调度到,而不是输出结果
- 在分时系统环境下
- 等待时间Waiting time:进程在就绪队列中等待的时间总和
- 截止时间:开始截止时间和完成截止时间
- 实时系统,与周转时间有些相似
- 开始截止时间:在某个时间点之前必须开始
- 完成截止时间:在某个时间点之前必须完成
- 公平性:不因作业或进程本身的特性而使上述指标过分恶化
- 如长进程等待很长时间
- 不同进程之间的上述指标不能差异过大
- 优先级:可以使关键任务达到更好的指标
- 周转时间Turnaround
time:进程从提交到完成所经历的时间。包括:在CPU上执行,就绪列和阻塞队列中等待。
- 面向系统的调度性能准则
- 吞吐量Throughput:单位时间内所完成的进程数
- 跟进程本身特性和调度算法都有关系
- 批处理系统
- 平均周转时间不是吞吐量的倒数,因为并发执行的进程在时间上可以重叠
- 如:在2小时内完成4个进程,而每个周转时间是1小时,则吞吐量是2个进程/小时
- 处理器利用率CPU utilization:使CPU尽可能的忙碌
- 各种设备的均衡利用:
- 如CPU繁忙的进程和I/O繁忙的进程搭配
- 大中型主机
- 吞吐量Throughput:单位时间内所完成的进程数
- 调度算法本身的调度性能准则
- 易于实现
- 执行开销比较小
5.2.4 最优准则 Optimization Criteria
- 最大的CPU利用率 Max CPU utilization
- 最大的吞吐量 Max throughput
- 最短的周转时间 Min turnaround time
- 最短的等待时间 Min waiting time
- 最短的响应时间 Min response time
- 公平
5.3 调度算法 Scheduling Algorithms (计算)
| 算法名 | 注释 |
|---|---|
| First-Come, First-Served (FCFS) Scheduling | 先来先服务调度 |
| Shortest-Job-First (SJF) Scheduling | 短作业优先调度 |
| Priority Scheduling | 优先权调度 |
| Round Robin (RR) | 时间片轮转调度 |
| Multilevel Queue Scheduling | 多级队列调度 |
| Multilevel Feedback Queue Scheduling | 多级反馈队列调度 |
- 高响应比优先调度算法:Highest Response Ratio
Next(HRRN)
- 响应比R = (等待时间 + 要求执行时间) / 要求执行时间
5.3.1 先来先服务调度 FCFS
5.3.1.1 算法内容
FCFS算法:First-Come, First-Served Scheduling
- 按照进程或作业提交顺序形成就绪状态的先后次序,分派CPU
- 当前进程或作业占用CPU,直到执行完或阻塞,才出让CPU(非抢占方式)
- 在进程或作业唤醒后(如I/O完成),并不立即恢复执行,通常等到当前作业或进程出让CPU
- 最简单的算法
FCFS的特点
- 比较有利于长进程,而不利于短进程
- 有利于CPU Bound的进程,而不利于I/O Bound的进程
5.3.1.2 示例
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
Gantt Chart:根据进程的顺序排列,下标画时间点

Turnaround Time:终止时间 - 到达时间
- P1 = 24,P2 = 27,P3 = 30
- Average Turnaround Time = (24 + 27 + 30) / 3 = 27
Waiting Time:Turnaround Time - 实际运行的时间
- P1 = 24 - 24 = 0,P2 = 27 - 3 = 24,P3 = 30 - 3 = 27
- Average Waiting Time = (0 + 24 + 27) / 3 = 17
5.3.2 短作业优先调度 SJF
5.3.2.1 算法内容
SJF算法:Shortest-Job-First (SJF) Scheduling
- 对预计执行时间短的作业(进程)优先分派处理器
- 又称为“短进程优先”SPF(Shortest Process First),这是对FCFS算法的改进,其目标是减少平均周转时间
两种模式
- 非抢占nonpreemptive:一旦CPU被赋予进程,它就不能被抢占,直到完成其CPU Burst
- 抢占preemptive:如果新进程到达时CPU
Burst长度小于当前执行进程的剩余时间,则抢占
- 该方案被称为最短剩余时间优先(SRTF,Shortest-Remaining-Time-First)
优点:平均等待时间最小
5.3.2.2 最短剩余时间优先 SRTF
最短剩余时间优先SRTF(Shortest Remaining Time First):基于抢占的SJF算法
允许比当前进程剩余时间更短的进程来抢占
5.3.2.3 最高响应比优先 HRRN
- 最高响应比优先HRRN(Highest Response Ratio Next)
- 响应比R = (等待时间 + 要求执行时间) / 要求执行时间
- 是FCFS和SJF的折中
5.3.2.4 示例
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 7 |
| P2 | 2 | 4 |
| P3 | 4 | 1 |
| P4 | 5 | 4 |
- SJF (non-preemptive):

- 第0时刻只有P1到来,因此先执行P1
- P1结束后为第7时刻,此时的进程有P2, P3, P4,P3的Burst Time最短,因此执行P3
- Turnaround Time
- P1 = 7 - 0 = 7,P2 = 12 - 2 = 10,P3 = 8 - 4 = 4,P4 = 16 - 5 = 11
- Average Turnaround Time = (7 + 10 + 4 + 11) / 4 = 8
- Waiting Time
- P1 = 0 - 0 = 0,P2 = 8 - 2 = 6,P3 = 7 - 4 = 3,P4 = 12 - 5 = 7
- Average Waiting Time = (0 + 6 + 3 + 7) / 4 = 4
- SJF (preemptive):
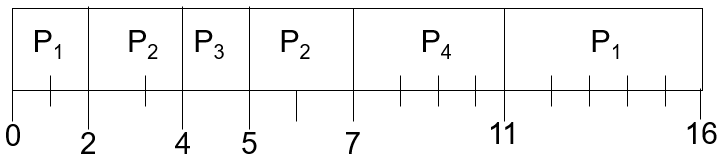
- 第2时刻,P2到来,其时间比P1剩余时间短,因此打断P1,执行P2
- 第4时刻,P3到来,其时间比P2剩余时间短,因此打断P2,执行P3
- 第5时刻,P3结束,此时等待队列如下,因此执行P2
- P1:5s
- P2:2s
- 第7时刻,P2结束,P4到来,此时等待队列如下,因此执行P4
- P1:5s
- P4:4s
- 第11时刻,P4结束,执行P1
- Turnaround Time
- P1 = 16 - 0 = 16,P2 = 7 - 2 = 5,P3 = 5 - 4 = 1,P4 = 11 - 5 = 6
- Average Turnaround Time = (16 + 5 + 1 + 6) / 4 = 7
- Waiting Time
- P1 = (0 - 0) + (11 - 2) = 9,P2 = (2 - 2) + (5 - 4) = 1,P3 = 4 - 4 = 0,P4 = 7 - 5 = 2
- Average Waiting Time = (9 + 1 + 0 + 2) / 4 = 4
5.3.3.5 预测CPU Burst Time:指数平均法
只能估计长度
可以通过使用以前CPU突发的长度,使用指数平均来完成
- \(t_n\) = 第n次CPU burst的真实值
- \(\tau_n\) = 第n次CPU burst的预测值
- \(\alpha\),\(0 \le \alpha \le 1\)
- 定义:\(\tau_{n+1}=\alpha t_n+(1-\alpha)\tau_n\)
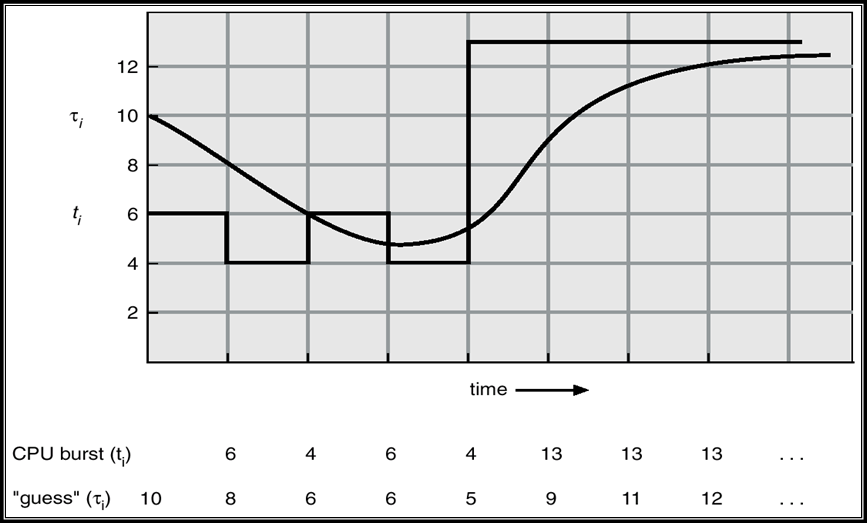
几种\(\alpha\)的取值
- \(\alpha=0\):\(\tau_{n+1} = \tau_{n}\),只考虑预测值
- \(\alpha=1\):\(\tau_{n+1} = t_{n}\),只考虑实际值
展开\(\tau_{n+1}\) \[ \begin{aligned} \tau_{n+1}= &\ \ \ \ \ \ \alpha t_n \\ &+ (1-\alpha)\ t_{n-1} \\ &+ \ ...\\ &+(1-\alpha)^i\ \alpha t_{n-i} \\ &+ \ ...\\ &+(1-\alpha)^{n+1} \tau_{0} \end{aligned} \]
5.3.3 优先级调度 Priority Scheduling
5.3.3.1 算法内容
- 该算法总是把处理机分配给就绪队列中具有最高优先权的进程
- SJF是以下一次CPU脉冲长度作为优先数的优先级调度
- 常用以下两种方法来确定进程的优先权:
- 静态优先权:静态优先权是在创建进程时确定的,在整个运行期间不再改变。依据有:进程类型、进程对资源的要求、用户要求的优先权。
- 动态优先权:动态优先权是基于某种原则,使进程的优先权随时间改变而改变。
- 假定:最小的整数 <=> 最高的优先级.
- 两种模式
- 非抢占式Non-preemptive priority
scheduling:将优先级较高的进程置于队列的前端
- 默认所有进程一起到来
- 抢占式Preemptive priority
scheduling:在较高优先级进程到达时中断并抢占正在运行的进程
- 默认所有进程的到达时间有前后区别
- 非抢占式Non-preemptive priority
scheduling:将优先级较高的进程置于队列的前端
- 问题:饥饿Starvation,低优先级的进程永远不会被执行
- 解决方法:老化Aging,随着进程运行时间的增长,其优先级会降低
5.3.3.2 示例
非抢占式:non-preemptive
| Process | Burst Time | Priority |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |

- 平均Turnaround time:(16+1+18+19+6) / 5 = 12
- 平均waiting time:(6+0+16+18+1) / 5 = 8.2
抢占式:preemptive
| Process | Arrival Time | Burst Time | Priority |
|---|---|---|---|
| P1 | 0 | 10 | 3 |
| P2 | 1 | 1 | 1 |
| P3 | 4 | 2 | 4 |
| P4 | 5 | 1 | 2 |
| P5 | 8 | 5 | 2 |
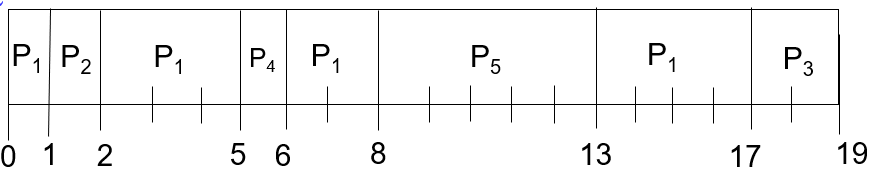
- 平均Turnaround time:(17+1+15+1+5) / 5 = 7.8
- 平均waiting time:(7+0+13+0+0) / 5 = 4
5.3.4 时间片轮转调度 RR
5.3.4.1 算法内容
- 基本思路:通过时间片轮转,提高进程并发性和响应时间特性,从而提高资源利用率。
- RR算法:Round Robin
- 将系统中所有的就绪进程按照FCFS原则,排成一个队列
- 每次调度时将CPU分派给队首进程,让其执行一个时间片
(timeslice)
- 时间片的长度从几个ms到几百ms
- 在一个时间片结束时,发生时钟中断
- 调度程序据此暂停当前进程的执行,将其送到就绪队列的末尾,并通过上下文切换执行当前的队首进程
- 进程可以未使用完一个时间片,就出让CPU(如阻塞)
- 每个进程都有一小单位的CPU时间(time quantum),通常为10-100毫秒。经过这段时间后,进程被抢占并添加到就绪队列的末尾
- 如果ready
queue中有n个进程,并且time
quantum为q,那么每个进程一次获得最多为q个时间单位的CPU时间的1/n,进程最大等待(n-1)q个时间单位
- 当q很大时,变为了FIFO
- 当q很小时,上下文切换的开销过高
- 时间片长度的影响因素:
- 就绪进程的数目:当响应时间一定时,数目越多,时间片越小
- 系统的处理能力:应当使用户输入通常在一个时间片内能处理完,否则使响应时间、平均周转时间、平均带权周转时间过长
- 优点:response更好
- 缺点:比SJF的average turnaround time长
5.3.4.2 示例
| Process | Burst Time |
|---|---|
| P1 | 53 |
| P2 | 17 |
| P3 | 68 |
| P4 | 24 |
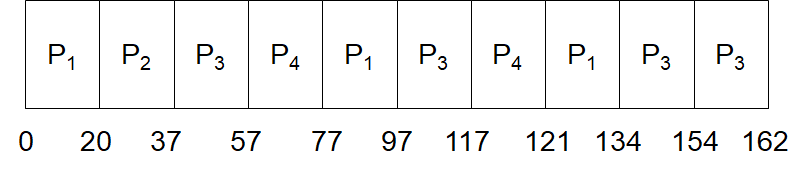
- 平均Turnaround time:(134+37+162+121) / 4 = 113.5
- 平均waiting time:(81+20+94+97) / 4 = 70.5
5.3.4.3 Time Quantum 时间片的选择
- 要求80%的CPU burst time应该小于q
5.3.5 多级队列调度
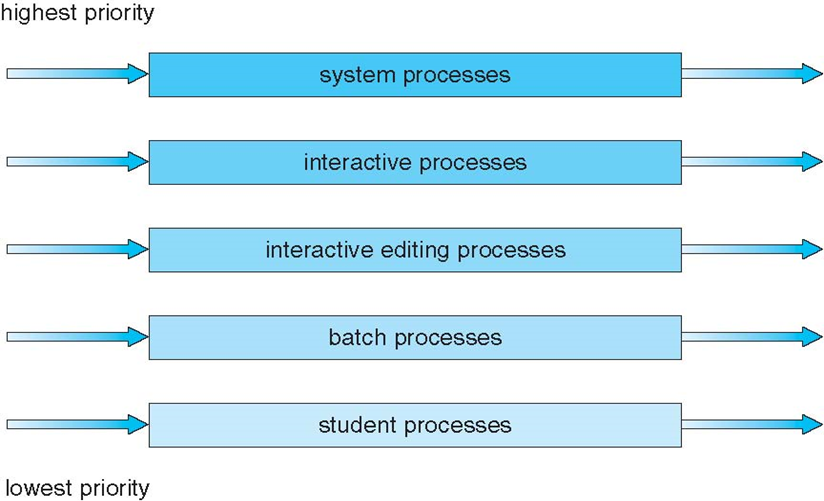
本算法引入多个就绪队列,通过各队列的区别对待,达到一个综合的调度目标
- 根据进程的性质或类型的不同,将Ready队列再分为若干个子队列
- 每个作业固定归入一个队列
- 各队列的不同处理:不同队列可有不同的优先级、时间片长度、调度策略等
- 如:系统进程、用户交互进程、批处理进程等
- Ready Queue的分类
- foreground (interactive) 前台(交互式)— RR,时间片轮转调度
- background (batch) 后台 (批处理)— FCFS,先来先服务调度
- 多级队列算法调度须在队列间进行
- 固定优先级调度:即前台运行完后再运行后台
- 有可能产生饥饿
- 给定时间片调度:即每个队列得到一定的CPU时间,进程在给定时间内执行
- 不同队列的时间片长度不一样
- 如,80%的时间执行前台的RR调度,20%的时间执行后台的FCFS调度
- 固定优先级调度:即前台运行完后再运行后台
5.3.6 多级反馈队列
- 多级反馈队列算法:Multilevel Feedback Queue Scheduling
- 是时间片轮转算法和优先级算法的综合和发展
- 同一个进程可以在不同队列之间转移
- 优点:
- 为提高系统吞吐量和缩短平均周转时间而照顾短进程
- 为获得较好的I/O设备利用率和缩短响应时间而照顾I/O型进程
- 不必估计进程的执行时间,动态调节
- 方法:
- 设置多个就绪队列,分别赋予不同的优先级,如逐级降低,队列1的优先级最高。每个队列执行时间片的长度也不同,规定优先级越低则时间片越长,如逐级加倍
- 新进程进入内存后,先投入队列1的末尾,按FCFS算法调度;若按队列1一个时间片未能执行完,则降低投入到队列2的末尾,同样按FCFS算法调度;如此下去,降低到最后的队列,则按"时间片轮转"算法调度直到完成
- 仅当较高优先级的队列为空,才调度较低优先级的队列中的进程执行。如果进程执行时有新进程进入较高优先级的队列,则抢占执行新进程,并把被抢占的进程投入原队列的末尾
- 几点说明:
- I/O型进程:让其进入最高优先级队列,以及时响应I/O交互。通常执行一个小时间片,要求可处理完一次I/O请求的数据,然后转入到阻塞队列
- 计算型进程:每次执行完时间片,进入更低优先级级队列。最终采用最大时间片来执行,减少调度次数
- I/O次数不多,而主要是CPU处理的进程:在I/O完成后,优先放回I/O请求时离开的队列,以免每次都回到最高优先级队列后再逐次下降
- 为适应一个进程在不同时间段的运行特点,I/O完成时,提高优先级;时间片用完时,降低优先级;
5.4* 多处理器调度 Multiple-Processor Scheduling
- 当多个CPU可用时,CPU调度更加复杂
- 多处理器中的 同构处理器Homogeneous processors
- 负载分担
- 非对称多处理Asymmetric multiprocessing:只有一个处理器访问系统数据结构,减少了数据共享的需要
5.5* 线程调度 Thread Scheduling
- 本地调度:线程库如何决定将哪个线程放入可用的LWP
- 全局调度:内核如何决定下一个运行哪个内核线程
5.6 操作系统示例 Operating Systems Examples
- 两种算法:Time-sharing、Real-time
- 时间共享 Time-sharing
- 基于credit的优先级:下一步执行拥有最高credit的进程
- 触发计时器中断时扣除credit
- 当credit=0时,选择另一个进程
- 当所有进程的credit均为0时,将重新编辑
- 基于优先级和历史等因素
- 实时 Real-time
- 软实时
- Posix.1b compliant:两种
- FCFS和RR
- 优先级最高的进程总是首先运行
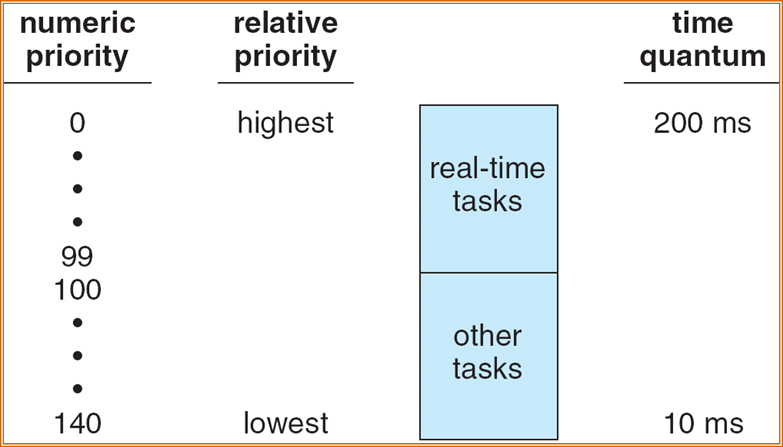
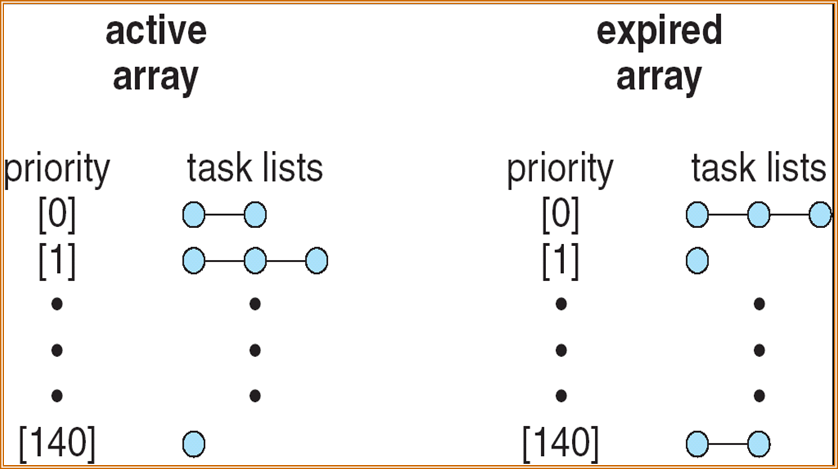
5.7 总结
- CPU Burst Time 、I/O Burst Time
- CPU-bound program(CPU型程序) 、I/O-bound program(I/O型程序)
- long-term scheduler(长程调度)、medium-term scheduler(中程调度)short-term scheduler(短程调度)
- time slicing(时间片)
- response time(响应时间)、turnaround time(周转时间)、waiting time(等待时间)、Average Turnaround time(平均周转时间)Average waiting time(平均等待时间)
- preemptive scheduling(抢占式调度)、Nonpreemptive scheduling(非抢占式调度)
- throughput(吞吐量):单位时间内完成的任务
- 从ready queue中选择一个进程,为它分配CPU
- 调度算法
- first-come, first served (FCFS)
- shortest job first (SJF)
- provably optimal, but difficult to know CPU burst
- general priority scheduling
- starvation, and aging
- round-robin (RR)
- for time-sharing, interactive system
- problem: how to select the time quantum?
- Multilevel queue
- different algorithms for different classes of processes
- Multilevel feedback queue
- allow process to move from one (ready) queue to another
Chapter 6:Process Synchronization 进程同步
6.1 Background
对共享数据的并发访问可能导致数据不一致:data inconsistency
维护数据一致性需要有机制来确保合作流程的有序执行
有界缓冲区问题的共享内存解决方案(第3章)允许缓冲区中最多有n-1个项。使用所有N个缓冲区的解决方案并不简单
假设我们通过添加一个变量counter来修改生产者–消费者代码
- counter初始化为0,并在每次向缓冲区添加新项时递增
- counter++和counter--必须被原子性的执行
typedef struct {
. . .
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;
int counter = 0;
// Producer process(thread):
item nextProduced;
while (1) {
while (counter == BUFFER_SIZE) ; /* do nothing */
buffer[in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
// Consumer process (thread):
item nextConsumed;
while (1) {
while (counter == 0) ; /* do nothing */
nextConsumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--;
}
6.1.1 原子操作
原子操作 Atomic operation:是指完整地完成而不中断的操作
counter++和counter--均会被实现为三条指令:
register = counter;
register = register +/- 1;
counter = register;如果生产者和消费者都试图同时更新缓冲区,汇编语言语句可能会交错
交错取决于生产者和消费者流程的安排方式
6.1.2 非原子操作冲突示例
有两个进程P1、P2,它们分别执行下面的程序体,其中total是两个进程都能访问的共享变量,初值为0(可理解为共享存储段中的存储单元),count是每个进程的私有变量。假设这两个进程并发执行,并可自由交叉(interleave),则这两个进程都执行完后,变量total可能得到的最小取值是
3
int count;
for (count =1; count <= 50; count++)
total = total + 1;
}
P2: {
int count;
for (count =1; count <= 50; count++)
total = total + 2;
}
total = total + 1和total = total + 2经过编译后各为三条指令

P1和P2并发执行过程中,这些指令会交替运行。如果两个进程按如下顺序执行:
操作 对应指令 对应的值 P1第1次循环 register1 = total register1 = 0 P1第1次循环 register1 = register1 + 1 register1 = 1 P2循环49次 P1第1次循环 total =register1 total =1 P2第50次循环 register2 = total register2 = 1 P2第50次循环 register2 = register2 + 2 register2 = 3 P1循环48次 P1第50次循环 register1 = total register1 = 49 P1第50次循环 register1 = register1 + 1 register1 =50 P1第50次循环 total = register1 total = 50 P2第50次循环 total = register2 total = 3 两个进程运行结束后,变量total的值为3。
6.1.3 Race Condition
- Race Condition(竞争条件):多个进程同时访问和操作共享数据,共享数据的最终值取决于哪个进程最后完成,执行的结果取决于访问发生的特定顺序
- 为了防止出现争用情况,必须同步并发进程
6.1.4 进程同步的概念
进程之间竞争资源面临三个控制问题:
- 互斥(mutual exclusion):指多个进程不能同时使用同一个资源
- 死锁(deadlock):指多个进程互不相让,都得不到足够的资源
- 永远得不到资源
- 饥饿(starvation):指一个进程长时间得不到资源(其他进程可能轮流占用资源)
- 资源分配不公平
6.2 The Critical-Section Problem(重点)
6.2.1 问题的定义
- n个进程都在竞争使用某些共享数据
- 每个流程都有一个代码段,称为关键部分(临界区), 其中访问共享数据。
- 问题:确保当一个进程在其关键部分执行时,不允许其他进程在其重要部分执行
6.2.2 临界区&临界资源
- 临界资源:一次只允许一个进程使用(访问)的资源
- 如:硬件打印机、磁带机等,软件的消息缓冲队列、变量、数组、缓冲区等。
- 临界区:访问临界资源的那段代码
- 对临界区问题的解法必须满足:
- Mutual Exclusion(互斥)
- 如果进程Pi正在临界区中执行,则其他进程不能在临界区中执行
- Progress(空闲让进)
- 如果没有进程在临界区中执行,并且存在一些进程希望进入临界区,则不能无限期地推迟选择下一个将进入临界区的进程
- Bounded Waiting(让权等待)
- 在一个进程发出进入临界区的请求之后,在该请求被批准之前,其他进程被允许进入临界区的次数必须存在一个界限
- 不是必须的
- Mutual Exclusion(互斥)
6.2.3 一个进程的结构应该是

6.3 多进程临界区问题的解决方法:软件方法
6.3.1 Peterson Solutions:两个进程
- Software Solution:通过软件方法解决进程互斥
- 针对两个进程之间的同步
- 假设Load和Store均是原子操作
6.3.1.1 算法1
只有两个进程P0,P1
共享变量
- int turn = 0
- turn = i:表示轮到Pi进入临界区,i = 0/1
进程P0和P1的操作:

满足互斥,但是不满足空闲让进
缺点:
- 强制轮流进入临界区,没有考虑进程的实际需要。容易造成资源利用不充分
- 在Pi出让临界区之后,Pj使用临界区之前,Pi不可能再次使用临界区
6.3.1.2 算法2-1
共享变量
- bool flag[2] = false
- flag[i] = true:表示Pi想要进入临界区,i = 0/1
进程P0和P1的操作:

满足互斥,但是不满足空闲让进
缺点:
- P0和P1可能都进入不了临界区
- 当P0执行了flag[0] = true后,然后P1执行了flag[1] = true,这样两个进程都无法进入临界区
6.3.1.3 算法2-2
共享变量
- bool flag[2] = false
- flag[i] = true:表示Pi想要进入临界区,i = 0/1
进程P0和P1的操作:

满足空闲让进,但是不满足互斥
缺点:
- P0和P1可能同时进入临界区
- 当flag [0] = flag [1] = false时, P0执行了while (flag[1])后,P1执行while (flag[0]) ,这样两个进程同时进入了临界区
6.3.1.4 Peterson算法
共享变量
- int turn = 0
- bool flag[2] = false
- turn = i:表示轮到Pi进入临界区,i = 0/1
- flag[i] = true:表示Pi准备好进入临界区,i = 0/1
进程P0和P1的操作:

满足了三个要求,但是只能解决2个进程的临界区问题
6.3.2 Bakery Algorithm:n个进程
思想:
- 进入临界区之前,进程会获得一个number,拥有最小number的进程可以进入临界区
- 如果Pi和Pj的number相同,则先执行进程id小的进程
- 编号方案总是按枚举的递增顺序生成数字,如1,2,3,3,3,3,4,5...
定义:
- order:(a, b),a为number,b为进程id
- (a, b) < (c, d):当且仅当 a<c 或者 a=c, b<d
共享数据:
- bool choosing[n] = false;
- int number[n] = 0;
- choosing[i] = true:表示Pi正在获取它的number
- number[i]:是Pi的当前number。如果值为0,表示Pi未参加排队,不想获得该资源
进程Pi的操作:
do { |
6.4 多进程临界区问题的解决方法:硬件方法
- 许多系统为关键部分代码提供硬件支持
- 单处理器:可以禁用中断
- 当前运行的代码将在没有抢占的情况下执行
- 在多处理器系统上通常效率太低
- 使用此功能的操作系统不可广泛扩展
- 特殊的原子硬件指令:原子 => 不可中断
- 从内存中取一个变量并且设置为某个值:test and set
- 交换内存中两个变量的内容:swap
6.4.1 Test-and-Set:测试与设置
返回变量的原始值,并将其赋值为true
bool TestAndSet(bool &target) {
bool rv = target;
target = true;
return rv;
}将其变为一条原子指令之后,进程与临界区的交互变为:
bool lock = false; // 共享数据
// 进程P[i]
while(1) {
// 第一个进程准备进入临界区时, 该指令返回false, 并将lock赋值为true
// 其它进程再执行该指令时, 会由于返回值为true, 而停到这里
// 进程执行完成后, 将lock赋值为false, 其它进程可以访问临界区
while(TestAndSet(lock));
critical_section(); // 进入临界区执行的部分
lock = false; // 之后的第一个进程可以进入临界区
remainder_section();// 不需要进入临界区执行的部分
};
6.4.2 Swap:交换
交换两个变量的值
void Swap (boolean *a, boolean *b){
boolean temp = *a;
*a = *b;
*b = temp:
}将其变为一条原子指令之后,进程与临界区的交互变为:
bool lock = false; // 共享数据
// 进程P[i]
while(1) {
bool key = true;
// 第一个进程准备进入临界区时, key与lock交换, key变为false, lock变为true
// 其它进程再执行该指令时, key与lock交换后均为true, 会停到这里
// 进程执行完成后, 将lock赋值为false, 其它进程可以访问临界区
while(key == true) Swap(&lock, &key);
critical_section(); // 进入临界区执行的部分
lock = false; // 之后的第一个进程可以进入临界区
remainder_section();// 不需要进入临界区执行的部分
};
6.4.3 硬件方法的优缺点
优点
- 适用于任意数目的进程,在单处理器或多处理器上
- 简单,容易验证其正确性
- 可以支持进程内存在多个临界区,只需为每个临界区设立一个布尔变量
缺点
- 不能实现让权等待:
- 因为等待要耗费CPU时间
- 可能饥饿:
- 从等待进程中随机选择一个进入临界区,有的进程可能一直选不上
- 可能死锁:
- 单CPU情况下,P1执行特殊指令进入临界区,这时拥有更高优先级P2执行并中断P1
- 如果P2又要使用P1占用的资源,按照资源分配规则拒绝P2对资源的要求,P2陷入等待循环
- 然后P1也得不到CPU,因为P1比P2优先级低
- 不能实现让权等待:
解决饥饿
- waiting[i]:进程Pi正在等待进入临界区
bool waiting[n] = false, lock = false; // 共享数据
// 进程P[i]
while(1) {
// 第一个进程准备进入临界区时, 将lock变为true, 返回给key为false
// 之后的进程始终为true, 也就是不能进入临界区
waiting[i] = true;
bool key = true;
while (waiting[i] && key) key = TestAndSet(lock);
waiting[i] = false;
critical_section(); // 进入临界区执行的部分
// 选择下一个进入临界区的进程(下一个waiting[j] = true)
// 让waiting[j] = false, 则被选中的进程跳出while循环, 可以进入临界区
// lock的释放由进程P[j]执行
int j;
for(j = (i + 1) % n; j != i; j = (j + 1) % n){
if(waiting[j]) {
waiting[j] = false;
break;
}
}
// 没有进程等待进入临界区, 则直接释放lock
if (j == i) lock = false ;
remainder_section();// 不需要进入临界区执行的部分
}- 该算法满足所有关键部分的要求。
- 证明满足互斥要求:
- 我们注意到,只有当waiting[i]=false或key=false时,进程Pi才能进入临界区
- 只有在执行TestAndSet时,key的值才能变为false
- 执行TestAndSet的第一个进程将发现key==false;所有其他人都必须等待
- 只有当另一个进程离开临界区时,waiting[i]才能变为false;只有一个waiting[i]设置为false,保持互斥要求。
6.4.4 自旋锁 spinlock
- Windows、Linux内核用来达到多处理器互斥的机制“自旋锁”,它类同于TestAndSet指令机制。自旋锁是一个与共用数据结构有关的锁定机制。
- 自旋锁像它们所保护的数据结构一样,储存在共用内存中。为了速度和使用任何在处理器体系下提供的锁定机构,获取和释放自旋锁的代码是用汇编语言写的。例如在Intel处理器上,Windows使用了一个只在486处理器或更高处理器上运行的指令。
- 当线程试图获得自旋锁时,在处理器上所有其它工作将终止。因此拥有自旋锁的线程永远不会被抢占,但允许它继续执行以便使它尽快把锁释放。内核对于使用自旋锁十分小心,当它拥有自旋锁时,它执行的指令数将减至最少。
6.5 Semaphores 信号量
6.5.1 信号量
信号量分类:
- 整型信号量:integer semaphore
- 记录型信号量:record semaphore
- AND型信号量,信号量集
- 二值信号量:binary semaphore
信号量的任务:解决busy waiting,即之前进程中的while()语句
整型信号量:S
对S的两个标准操作:wait()、signal()
- 也成为P()、V()
- 这两个操作是原子操作
两种信号量
- 计数信号量 Counting semaphore:整数取值范围
- 二值信号量 Binary semaphore:只有0/1两个值
6.5.2 用信号量解决冲突
wait(S){ |
Semaphore mutex = 1; // 共享数据, 初始值表示最多可以有多少个进程同时进入临界区 |
- 必须保证没有两个进程可以在同一信号量上同时执行wait()和signal()
- 没有解决busy waiting的问题
- 但是将解决临界区问题的代码简化了
6.5.3 没有busy waiting的信号量实现
实现了一个waiting queue,等待队列中的每一个实体有2个元素:
typedef struct{
int value; // S: 记录型信号量
struct process *list; // 等待队列中的下一个进程
} semaphore;2个操作
- block():将调用操作的进程放置在适当的等待队列中
- 进程:running → waiting
- wakeup():删除等待队列中的一个进程,并将其置于就绪队列中
- 进程:waiting → ready
- block():将调用操作的进程放置在适当的等待队列中
具体实现
wait(semaphore * S){
S->value--;
if(S->value < 0){
// 将这个进程加入S->list
block();
}
}
signal(semaphore *S) {
S->value++;
if (S->value <= 0) {
// 将进程P从S->list中移除
wakeup(P);
}
}
6.5.4 wait、signal操作讨论
- 通常用信号量表示资源或临界区
- 信号量的物理含义
- S.value>0:表示有S.value个资源可用;
- S.value=0:表示无资源可用或表示不允许进程再进入临界区;
- S.value<0:则|S.value|表示在等待队列中进程的个数或表示等待进入临界区的进程个数
- wait(S)≡P(S)≡down(S):表示申请一个资源
- signal(S)≡V(S)≡up(S): 表示释放一个资源
- wait、signal操作必须成对出现,有一个wait操作就一定有一个signal操作
- 当为互斥操作时(控制A, B不会同时访问临界区),它们同处于同一进程
- 当为同步操作时(控制先让A执行, 再让B执行),则不在同一进程中出现
- 如果两个wait操作相邻,那么它们的顺序至关重要,而两个相邻的signal操作的顺序无关紧要
- 一个同步wait操作与一个互斥wait操作在一起时,同步wait操作在互斥wait操作前
- wait、signal操作的优缺点
- 优点:简单,而且表达能力强
- 缺点:不够安全;wait、signal操作使用不当会出现死锁;实现复杂
6.5.5 信号量用于通用同步操作
先执行Pi中的A操作,再执行Pj中的B操作
- 信号量flag初始化为0
P[i] P[j] … … A wait(flag) signal(flag) B … … 一组合作进程,执行顺序如图。请用P(wait)、V(signal)操作实现进程间的同步操作
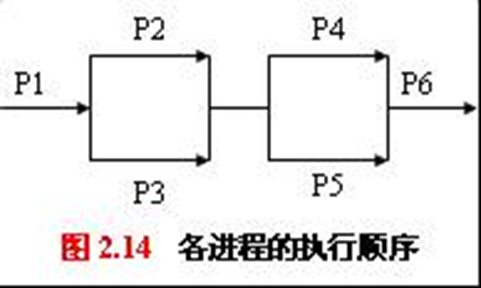
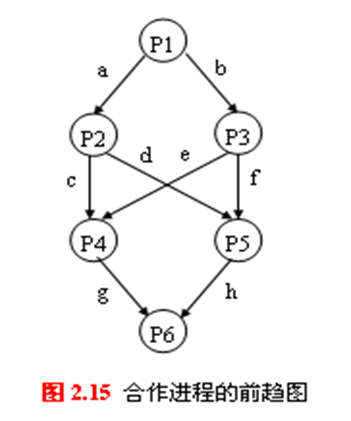
设置8个信号量a~h,初始值均为0
各进程的操作:
P1(){
...;
signal(a);
signal(b);
}
P2(){
wait(a);
...;
signal(c);
signal(d);
}
P3(){
wait(b);
...;
signal(e);
signal(f);
}
P4(){
wait(c);
wait(e);
...;
signal(g);
}
P5(){
wait(d);
wait(f);
...;
signal(h);
}
P6(){
wait(g);
wait(h);
...;
}
两个进程互斥:信号量初始为1

6.5.6 死锁和饥饿
死锁Deadlock:两个或多个进程无限期地等待一个事件,该事件只能由其中一个等待进程引起
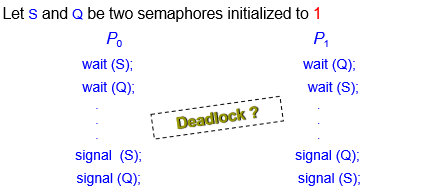
饥饿Starvation:无限期阻塞。进程可能永远不会从其挂起的信号量队列中删除
优先级反转Priority Inversion:低优先级进程持有高优先级进程所需的锁时的调度问题
6.6 同步的经典问题
6.6.1 有限缓冲区问题:Bounded-Buffer Problem
有限缓冲区问题,也成为生产者-消费者问题,是最著名的同步问题
- 它描述一组生产者(P1……Pm)向一组消费者(C1……Cq)提供消息
- 它们共享一个有限缓冲池(bounded buffer pool)
- 生产者向其中投放消息,消费者从中取得消息
- 生产者-消费者问题是许多相互合作进程的一种抽象
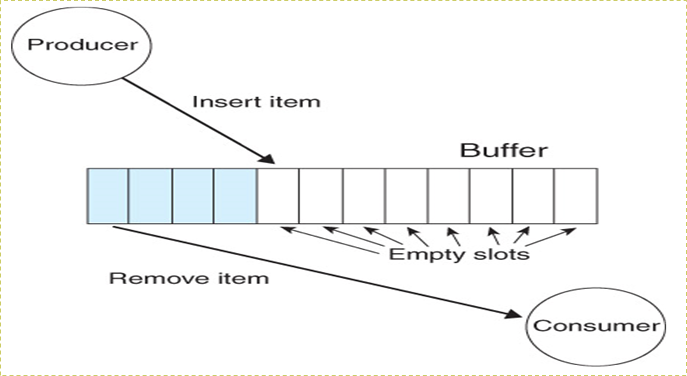
N个buffer,每个可以存储1个item
- 信号量full:初始化为0,表示已经使用的buffer个数
- 信号量empty:初始化为N,表示还未使用的buffer个数
- 信号量mutex:初始化为1,作为互斥信号量
需要保证:
- 对同一个buffer的操作是互斥操作
生产者进程:
do {
// produce an item in nextp
...;
wait(empty); // 保证所有生产者插入的数量 < 当前buffer的剩余空间的大小
wait(mutex); // 保证互斥
// add nextp to buffer
...;
signal(mutex); // 保证互斥
signal(full); // 声明有一个数据插入到buffer中, 便于消费者的使用
} while (1);消费者进程:
do {
wait(full); // 保证所有消费者使用的数量 < 当前buffer中存在的数据数量
wait(mutex); // 保证互斥
// remove an item from buffer to nextc
...;
signal(mutex); // 保证互斥
signal(empty); // 声明有一个buffer已经为空, 便于生产者使用
// consume the item in nextc
...;
} while (1);
6.6.2 读写问题:Readers and Writers Problem
- 一个数据集(如文件)如果被几个并行进程所共享:
- Reader:有些进程只要求读数据集内容,它称读者
- Writer:一些进程则要求修改数据集内容,它称写者
- 几个Reader可以同时读些数据集,而不需要互斥
- 一个Writer不能和其它进程(不管是写者或读者)同时访问些数据集,它们之间必须互斥
6.6.2.1 第一Readers-Writers问题
读优先,要求:
- 允许多个Reader同时阅读
- 同一时间只有一个写入程序可以访问共享数据
- Writer能会挨饿
共享数据:
- Data set
- 信号量mutex:初始化为1,作为互斥信号量
- 信号量wrt:初始化为1,作为不同Writer之间的互斥信号量
- 整数readcount:初始化为0
Writer进程:
do {
wait (wrt); // 有wrt锁时, Writer不能写
// writing is performed
...;
signal (wrt); // 释放wrt锁
} while (1);Reader进程:
do{
wait(mutex); // 对readcount的互斥锁
readcount++;
if(readcount == 1) wait(wrt); // 第一个Reader到时
signal(mutex); // 释放对readcount的互斥锁
...;
// reading is performed
...;
wait(mutex); // 对readcount的互斥锁
readcount--;
if(readcount == 0) signal(wrt); // 最后一个Reader离开时
signal(mutex); // 释放对readcount的互斥锁
}while(1);
6.6.2.2 第二Readers-Writers问题
- 要求:
- 一旦Writer准备好了,Writer就会尽快进行写作
- Reader可能会饿死
6.6.3 哲学家就餐问题:Dining-Philosopher Problem
多进程、多资源的同步问题
问题说明:
- n个哲学家坐在一个圆桌旁
- 每个哲学家与邻居共用一根筷子
- 每个哲学家都必须有一双筷子才能吃
- 邻居不能同时吃饭
- 哲学家在思考和吃饭之间交替
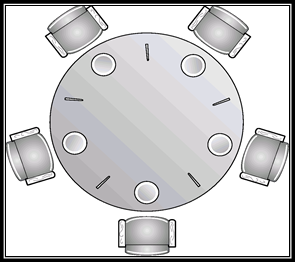
共享数据:
- 信号量:chopstick[5],初始值为1
哲学家i:
do {
// 等待两只筷子的使用
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
// 使用两只筷子
...;
eat();
...;
// 声明已经使用完两只筷子
signal(chopstick[i]);
signal(chopstick[(i+1) % 5]);
// 不使用筷子的操作
...;
think();
...;
} while (1);该方法很容易产生死锁
- 原因:两个wait语句并不是原子操作
- 例如:每个哲学家均拿起了自己左边的一根筷子
避免死锁的方法:
- 同时只允许n-1个哲学家申请资源 ==> 至少有一个哲学家拿到了2个筷子
- 奇数编号的哲学家先拿左边再拿右边,偶数编号的哲学家先拿右边再拿左边
- 把哲学家分为三种状态:思考、饥饿、吃饭,并且一次拿到两只筷子,否则不拿
- hungry状态唯有保证自己能够拿到2只筷子,才能进入eat状态
- 本质上是保证了两句wait的原子性
- 每个哲学家拿起第1根筷子一定时间后,若拿不到第2根筷子,再放下第1根筷子
- 但是可能大家一起拿一起放
6.7* Monitors(管程)
管程是一种高级同步机制
- 管程是管理进程间同步的机制,它保证进程互斥地访问共享变量,并方便地阻塞和唤醒进程
- 管程可以函数库的形式实现
- 相比之下,管程比信号量好控制
6.7.1 信号量同步的缺点
- 同步操作分散:信号量机制中,同步操作分散在各个进程中,使用不当就可能导致各进程死锁(如wait、signal操作的次序错误、重复或遗漏)
- 可读性差:要了解对于一组共享变量及信号量的操作是否正确,必须通读整个系统或者并发程序
- 不利于修改和维护:各模块的独立性差,任一组变量或一段代码的修改都可能影响全局
- 正确性难以保证:操作系统或并发程序通常很大,很难保证这样一个复杂的系统没有逻辑错误
6.7.2 管程的引入
1973年,Hoare和Hanson所提出;其基本思想是把信号量及其操作原语封装在一个对象内部。即:将共享变量以及对共享变量能够进行的所有操作集中在一个模块中。
- 管程的定义:管程是关于共享资源的数据结构及一组针对该资源的操作过程所构成的软件模块
- 管程可增强模块的独立性:系统按资源管理的观点分解成若干模块,用数据表示抽象系统资源,同时分析了共享资源和专用资源在管理上的差别,按不同的管理方式定义模块的类型和结构,使同步操作相对集中,从而增加了模块的相对独立性
- 引入管程可提高代码的可读性,便于修改和维护,正确性易于保证:采用集中式同步机制。一个操作系统或并发程序由若干个这样的模块所构成,一个模块通常较短,模块之间关系清晰
6.7.3 管程的主要特性
- 模块化:一个管程是一个基本程序单位,可以单独编译
- 抽象数据类型:管程是一种特殊的数据类型,其中不仅有数据,而且有对数据进行操作的代码
- 信息封装:管程是半透明的,管程中的外部过程(函数)实现了某些功能,至于这些功能是怎样实现的,在其外部则是不可见的
6.7.4 管程的实现要素
- 管程中的共享变量在管程外部是不可见的,外部只能通过调用管程中所说明的外部过程(函数)来间接地访问管程中的共享变量
- 为了保证管程共享变量的数据完整性,规定管程互斥进入
- 管程通常是用来管理资源的,因而在管程中应当设有进程等待队列以及相应的等待及唤醒操作
6.7.5 管程的的组成
- 名称:为每个共享资源设立一个管程
- 数据结构说明:一组局部于管程的控制变量
- 操作原语:对控制变量和临界资源进行操作的一组原语过程(程序代码),是访问该管程的唯一途径。这些原语本身是互斥的,任一时刻只允许一个进程去调用,其余需要访问的进程就等待
- 初始化代码:对控制变量进行初始化的代码
monitor monitor-name{ |
6.7.6 管程中的多个进程进入
- 当一个进入管程的进程执行等待操作时,它应当释放管程的互斥权;当一个进入管程的进程执行唤醒操作时(如P唤醒Q),管程中便存在两个同时处于活动状态的进程,如何处理?。
- 若进程P唤醒进程Q,则随后可有两种执行方式(进程P、Q都是管程中的进程)
- P等待,直到Q离开管程或下一次等待。Hoare采用。
- Q等待,直到P离开管程或下一次等待。1980年,Lampson和Redell采用
- 入口等待队列(entry queue):因为管程是互斥进入的,所以当一个进程试图进入一个巳被占用的管程时它应当在管程的入口处等待,因而在管程的入口处应当有一个进程等待队列,称作入口等待队列
- 紧急等待队列:如果进程P唤醒进程Q,则P等待Q继续,如果进程Q在执行又唤醒进程R,则Q等待R继续,...,如此,在管程内部,由于执行唤醒操作,可能会出现多个等待进程(已被唤醒,但由于管程的互斥进入而等待),因而还需要有一个进程等待队列,这个等待队列被称为紧急等待队列。它的优先级应当高于入口等待队列的优先级
6.7.7 条件变量(condition)
- 由于管程通常是用于管理资源的,因而在管程内部,应当存在某种等待机制。当进入管程的进程因资源被占用等原因不能继续运行时使其等待。为此在管程内部可以说明和使用一种特殊类型的变量---条件变量
- 每个条件变量表示一种等待原因,并不取具体数值---相当于每个原因对应一个队列
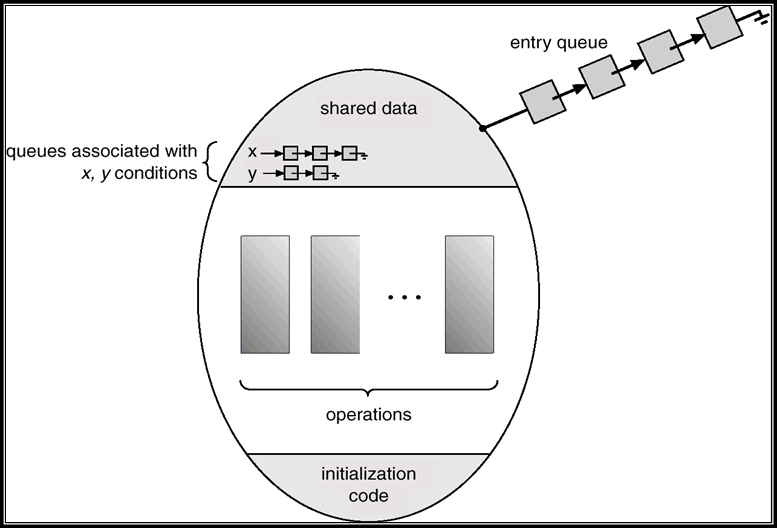
6.7.8 同步操作原语
- 同步操作原语wait和signal:针对条件变量x,x.wait()将自己阻塞在x队列中,x.signal()将x队列中的一个进程唤醒
- x.wait():如果紧急等待队列非空,则唤醒第一个等待者;否则释放管程的互斥权,执行此操作的进程排入x队列尾部
- 紧急等待队列与x队列的关系:紧急等待队列是由于管程的互斥进入而等待的队列,而x队列是因资源被占用而等待的队列
- x.signal():如果x队列为空,则相当于空操作,执行此操作的进程继续;否则唤醒第一个等待者,执行x.signal()操作的进程排入紧急等待队列的尾部
6.7.9 用管程解决哲学家问题
monitor dp { |
6.8 总结

Chapter 7:Deadlocks死锁
7.1 System Model
- 死锁:
- 一组被阻塞的进程,每个进程持有一个资源,并等待获取该组中另一个进程持有的资源
- 指多个进程因竞争共享资源而造成的一种僵局,若无外力作用,这些进程都将永远不能再向前推进
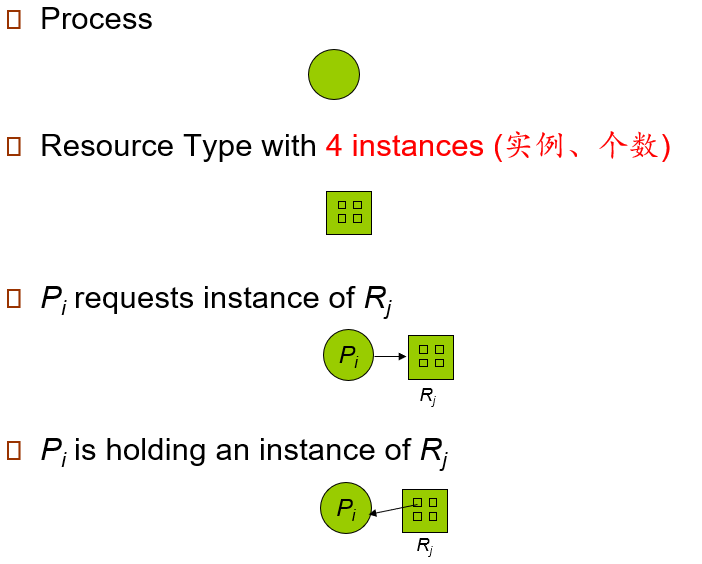
- 系统模型
- 资源类型\(R_1,R_2,...R_m\)
- CPU时钟、内存空间、I/O设备
- 每个资源类型\(R_i\)可以有\(W_i\)个实例
- 每种资源类型可以有多个实例
- 实例对应着实际能够分配的资源类型
- 进程对资源的使用有以下三种类型
- Request 申请
- Use 使用
- Release 释放
- 资源类型\(R_1,R_2,...R_m\)
7.2 死锁的特征
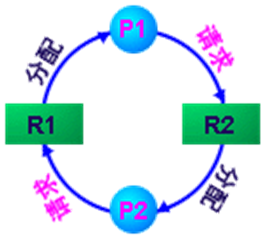
7.2.1 产生死锁的4个必要条件
- Mutual exclusion互斥:
- 同一时间只有一个进程能够使用一个资源实例
- Hold and wait占有并等待、请求和保持:
- 进程已经保持了至少一个资源,但又提出了新的资源要求,而该资源又已被其它进程占有,此时请求进程阻塞,但又对已经获得的其它资源保持不放
- No preemption不可抢占、不剥夺:
- 资源只能由持有该资源的进程在该进程完成任务后自愿释放
- Circular wait循环等待:
- 存在一组{P0,P1,…,Pn}等待进程,使得P0正在等待P1所持有的资源,P1正在等待P2持有的资源,…,Pn–1正在等待Pn持有的资源,Pn正在等待P0持有的
7.2.2 资源分配图 Resource-Allocation Graph
节点\(V\):
- 进程节点:P = {P1, P2, …, Pn}
- 资源节点:R = {R1, R2, …, Rm}
边\(E\):
- 请求边:Pi → Rj
- 分配边:Rj → Pi
节点&边的图例
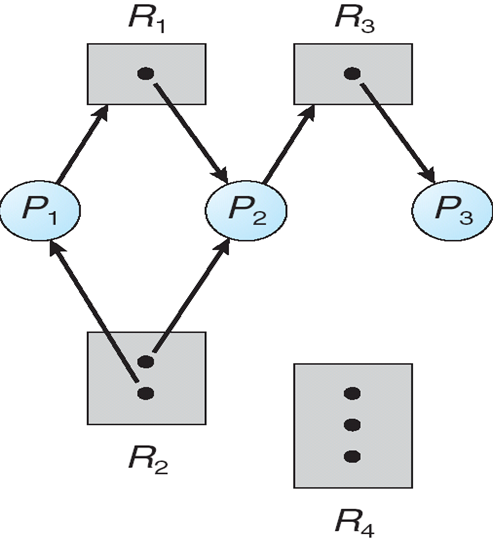
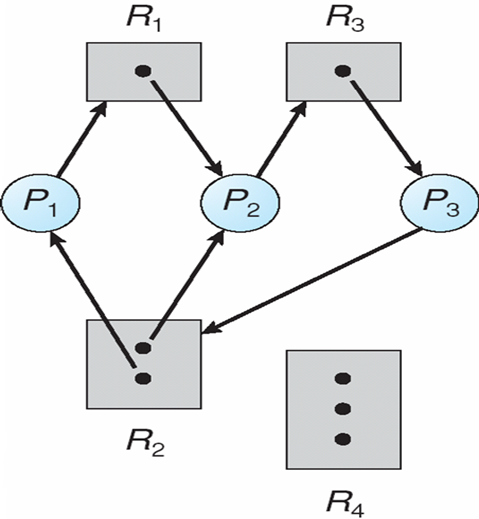
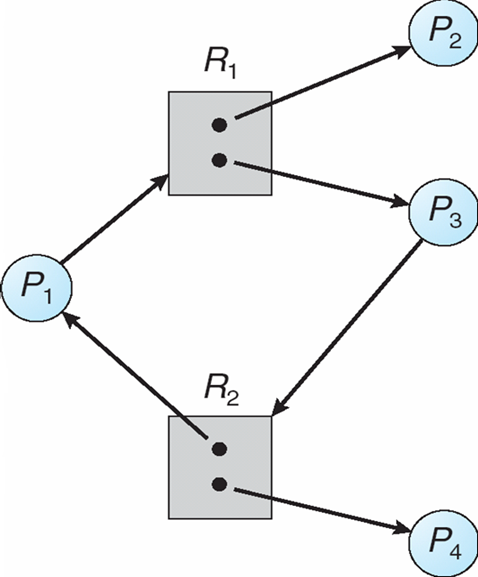
例:
- P1获取了R2资源,请求R1的资源
- P2获取了R1、R2资源,请求R3资源
- P3获取了R3资源
判断条件
- 如果图中没有环 ==> 没有死锁
- 如果图中有环
- 如果每个资源只有一个实例 ==> 死锁
- 如果每个资源拥有多个实例 ==> 有可能死锁,也可能不死锁
死锁定理:
- \(S\)为死锁状态的充分条件是:\(S\)状态的资源分配图是不可完全简化的
- 资源分配图(有向图)的简化:离散数学算法
7.3 处理死锁的方法
- 保证系统不进入死锁状态
- Prevention死锁预防
- Avoidance死锁避免
- 允许系统进入死锁状态,然后恢复
- Detection死锁检测
- Recovery死锁解除
- 忽略死锁状态,操作系统假装不发生死锁,人为解决死锁状态
7.4 死锁预防 Deadlock Prevention
- 不保证相互排斥(Mutual Exclusion)
- 不需要可共享资源;必须保留不可分割的资源
- 虚拟化
- 不保证保持等待(Hold and Wait)
- 必须确保无论进程何时请求资源,它都不会保留任何其他资源
- 要求进程在开始执行之前请求并分配其所有资源,或者仅当进程没有资源时才允许进程请求资源
- 资源静态预分配方式
- 资源利用率低;可能导致饥饿
- 允许抢占(No Preemption)
- 如果持有某些资源的进程请求另一个无法立即分配给它的资源,那么当前持有的所有资源都将被释放
- 抢占的资源将添加到进程正在等待的资源列表中
- 只有当进程能够重新获得它的旧资源以及它所请求的新资源时,它才会重新启动
- 保证不出现循环等待(Circular Wait)
- 给所有资源类型的编号,并要求每个进程以递增的顺序请求资源
- F(磁带驱动器)=1,F(磁盘驱动器)=5,F(打印机)=12
- 资源的有序申请破坏了循环等待条件
7.5 死锁避免 Deadlock Avoidance
- 要求每个进程声明其可能需要的每种类型的最大资源数量
- 死锁避免算法动态检查资源分配状态,以确保永远不会出现循环等待条件
- 资源分配状态由可用和已分配资源的数量以及进程的最大需求来定义
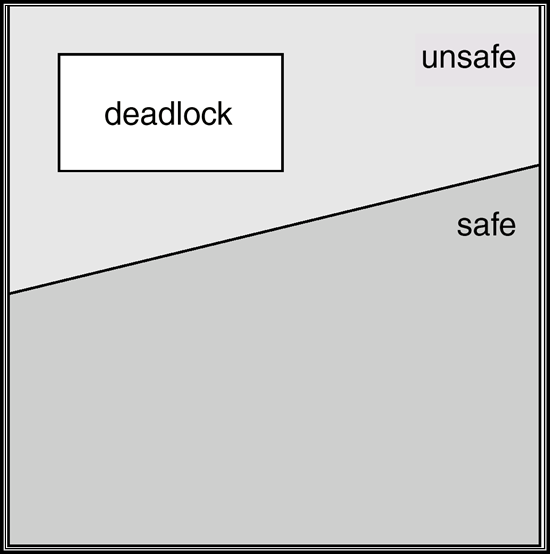
7.5.1 安全状态 Safe State
当进程请求可用资源时,系统必须决定立即分配是否使系统处于安全状态
安全状态是指系统的一种状态,在此状态开始系统能按某种顺序(如P1、P2……Pn)来为各个进程分配其所需资源,直至最大需求,使每个进程都可顺序地一个个地完成。
- 这个序列(P1、P2…….Pn)称为安全序列
- 若系统此状态不存在一个安全序列,则称系统处于不安全状态
- 如果存在所有进程的安全序列,则系统处于安全状态
序列(P1、P2……Pn)是安全的, 满足:对于每个Pi,Pi仍然可以请求的资源,可以由当前可用资源+所有Pj所持有的资源来满足,其中j<i。
- 如果Pi资源需求不立即可用,则Pi可以等到所有Pj完成
- 当Pj完成时,Pi可以获得所需的资源、执行、返回分配的资源并终止
- 当Pi终止时,Pi+1可以获得其所需的资源,依此类推
定理
- 系统处于安全状态 ==> 没有死锁
- 系统处于不安全状态 ==> 可能死锁
- 死锁避免:保证系统不会进入不安全状态
避免算法
- 每个资源只有一个实例:resource-allocation graph
- 每个资源有多个实例:banker’s algorithm
7.5.3 Resource-Allocation Graph Algorithm 资源分配图算法
- 需求边Pi→Rj:Pi可能会请求资源Rj,用虚线表示
- 需求边转化为请求边:当且仅当该进程请求了该资源
- 请求边转化为分配边:当且仅当资源被分配给了这个进程
- 分配边转化为请求边:当且仅当资源被进程释放
- 资源必须在系统中声明优先级
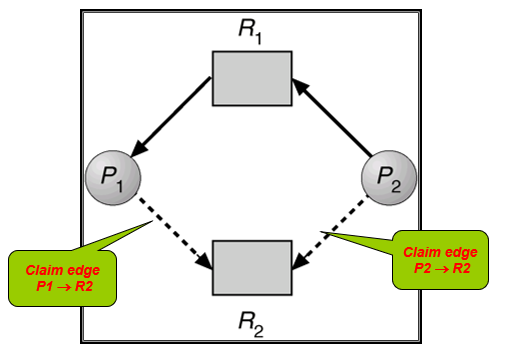
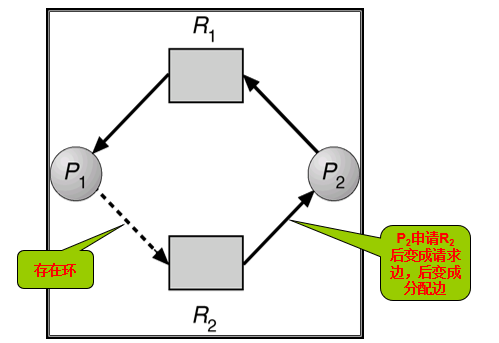
- 算法:假设进程Pi申请资源Rj。只有在需求边Pi→Rj变成分配边 Rj→Pi 而不会导致资源分配图形成环时,才允许申请。
- 用算法循环检测,如果没有环存在,那么资源分配会使系统处于安全状态。如果存在环,资源分配会使系统不安全。进程Pi必须等待。
7.5.3 Banker’s Algorithm 银行家算法
- 每个过程必须事先声明最大使用量
- 当进程请求资源时,它可能需要等待
- 当一个进程获得其所有资源时,它必须在有限的时间内返回这些资源
- 参数定义
- n:进程数目
- m:资源的种类
- Available:长度为m的向量。如果Availabe[j]=k,表示Rj有k个实例可以使用
- Max:n×m的矩阵。如果Max[i] [j]=k,那么Pi会申请至多k个Rj资源
- Allocation:n×m的矩阵。如果Allocation[i] [j]=k,那么Pi已经申请了k个Rj资源
- Need:n×m的矩阵。如果Need[i]
[j]=k,那么Pi还需要k个Rj资源来完成任务
- Need[i] [j] = Max[i] [j] - Allocation[i] [j]
7.5.3.1 Safety Algorithm 安全算法
- 令Work为一个长度为m的向量,Finish为一个长度为n的向量,初始化为:
- Work = Availabe
- Finish[i] = { false }
- 找到一个序号i,满足
- Finish[i] = false
- Need[i] \(\le\) Work
- 如果不存在,进入步骤4
- Work = Work + Allocation[i]
- Finish[i] = true
- 返回步骤2
- 如果Finish = { true },则系统已经在安全状态
7.5.3.2 Resource-Request Algorithm 资源-请求算法
Request[i]:进程Pi的请求向量,如果Request[i] [j]=k,那么Pi想要申请k个Rj资源
如果Request[i] \(\le\) Need[i],则进入步骤2。否则,引发错误条件,因为进程已超过其最大声明
如果Request[i] \(\le\) Availabe,则进入步骤3。否则,Pi必须等待,因为资源不能满足需求
通过如下修改状态,尝试将请求的资源分配给Pi
Available = Available - Request[i];
Allocation[i] = Allocation[i] + Request[i];
Need[i] = Need[i] - Request[i];- 调用Safety Algorithm
- 如果安全,则可以分配给Pi
- 如果不安全,则Pi必须等待,并恢复旧的资源分配状态
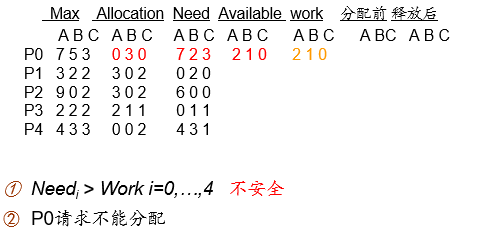
7.5.3.3 例
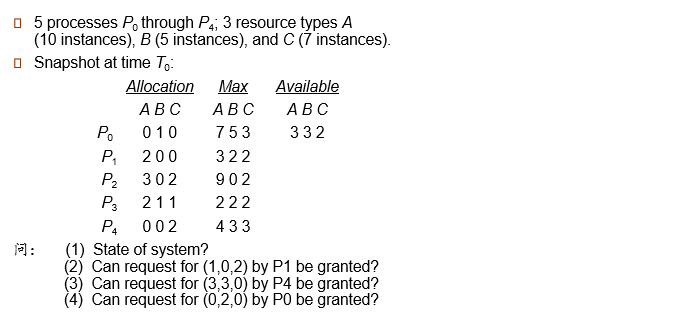
系统的状态(是否安全)?

P1的请求(1,0,2)是否通过?


P4的请求(3,3,0)是否通过?

P0的请求(0,2,0)是否通过?

7.6 死锁检测 Deadlock Detection
7.6.1 每个资源只有一个实例
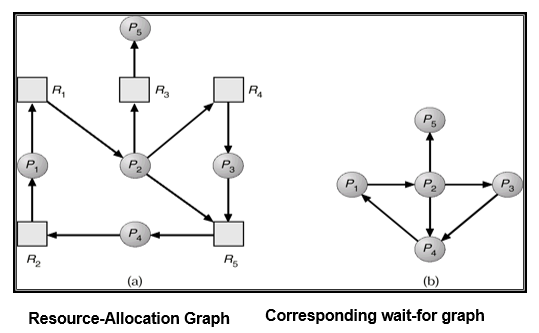
- 维护一个等待图wait-for-graph:资源分配图的变形
- 节点:进程
- 边:Pi→Pj表示Pi正在等待Pj释放资源
- 定期调用检测图中是否存在环的算法
- 检测图中是否存在环的算法为O(n2),其中n是图中顶点的数量
7.6.2 每个资源有多个实例
- 数据结构:
- Available:长度为m的向量。如果Availabe[j]=k,表示Rj有k个实例可以使用
- Allocation:n×m的矩阵。如果Allocation[i] [j]=k,那么Pi已经申请了k个Rj资源
- Request:n×m的矩阵。如果Request[i] [j]=k,那么Pi正在申请k个Rj资源
- 检测算法:O(m×n2)
- 令Work为一个长度为m的向量,Finish为一个长度为n的向量,初始化为:
- Work = Availabe
- Finish[i] = { Allocation[k] [i]==0 ? true : false }
- 找到一个序号i,满足
- Finish[i] = false
- Request[i] \(\le\) Work
- 如果不存在,进入步骤4
- Work = Work + Allocation[i]
- Finish[i] = true
- 返回步骤2
- 如果存在Finish[i] == false,则系统处于死锁状态,且是Pi被死锁
- 令Work为一个长度为m的向量,Finish为一个长度为n的向量,初始化为:
7.6.3 示例
一共5个进程:P0~ P4,3中资源:A(7个示例)、B(2个示例)、C(6个示例)
T0时的snapshot:
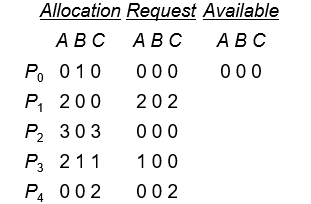
- 执行序列:P0, P2, P3, P1, P4
T1时的snapshot:
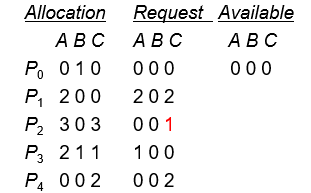
- 将P0执行结束后,无法执行P1~ P4的任意一个进程,系统进入死锁状态
- 处于死锁状态的进程为P1~ P4
7.6.4 死锁检测算法的使用
- 死锁检测算法的使用频率,取决于死锁发生的频率、希望有多少进程需要被回滚
- 死锁发生的频率越高,死锁检测算法的使用频率越高
- 希望回滚的进程越少,死锁检测算法的使用频率越高
- 如果随机调用检测算法,那么资源图中可能会有很多循环,因此我们将无法判断是哪个死锁进程“导致”了死锁
7.7 从死锁中恢复
- 检测到死锁后采取措施:
- 通知系统管理员
- 系统自己恢复
- 打破死锁两种方法:
- 进程终止
- 抢占资源
7.7.1 进程终止 Process Termination
- 中止所有死锁进程
- 一次中止一个进程,直到消除死锁循环
- 许多因素可能决定选择哪种进程,包括:
- 进程的优先级
- 这个进程计算了多长时间,还有多长时间才能完成
- 进程使用的资源
- 资源进程需要完成
- 需要终止多少进程
- 该进程是交互式的还是批处理的
7.7.2 抢占资源 Resource Preemption
- 选择受害者:将成本降至最低最小化代价
- 回滚rollback: 返回到某个安全状态,从该状态重新启动进程。
- 饥饿starvation:同样的过程可能总是被选为受害者,包括成本因素中的回滚次数。
Chapter 8:Main Memory
8.1 Background
- 程序必须(从磁盘)放入内存,并放置在进程中才能运行
- CPU只能直接访问主存储器和寄存器
- 寄存器访问的时间:1个CPU clock
- 主存储器访问的时间:需要很多周期
- cache位于主内存和CPU寄存器之间
- 确保正确操作所需的内存保护
8.1.1 存储架构
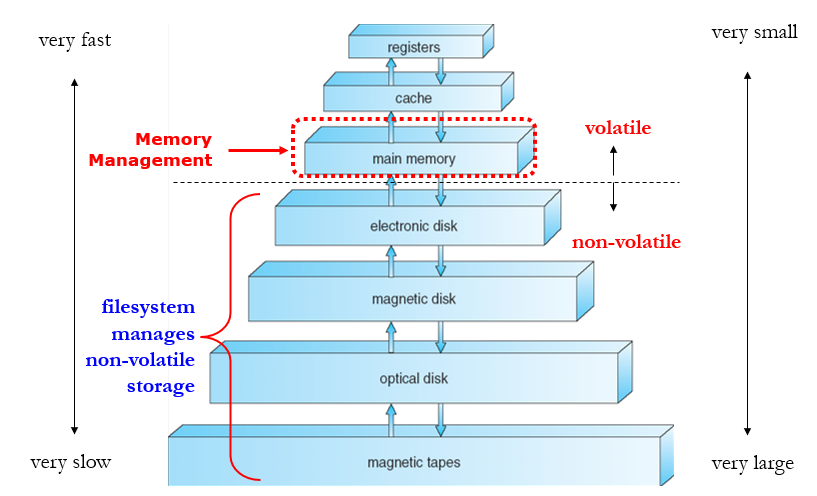
8.1.2 主存
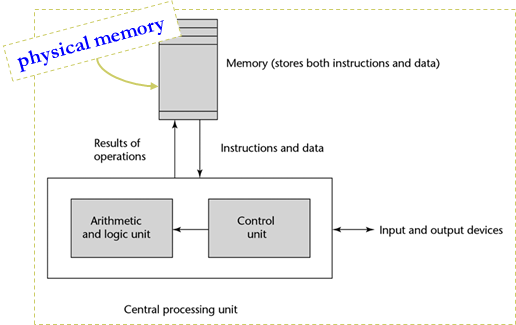
基于冯·诺依曼体系结构,数据和程序指令存在于共享内存空间中
- 程序重复执行以下内容:fetch-decode-execute
- 执行部分通常需要:数据获取和存储操作
8.1.3 逻辑地址 vs 物理地址
- Logical
address(逻辑地址,相对地址,虚地址):generated by the CPU; also
referred to as virtual address
- 用户的程序经过汇编或编译后形成目标代码,目标代码通常采用相对地址的形式。
- 其首地址为0,其余指令中的地址都相对于首地址来编址。
- 不能用逻辑地址在内存中读取信息。
- Physical address(物理地址,绝对地址,实地址)
:address seen by the memory unit
- 内存中存储单元的地址。物理地址可直接寻址
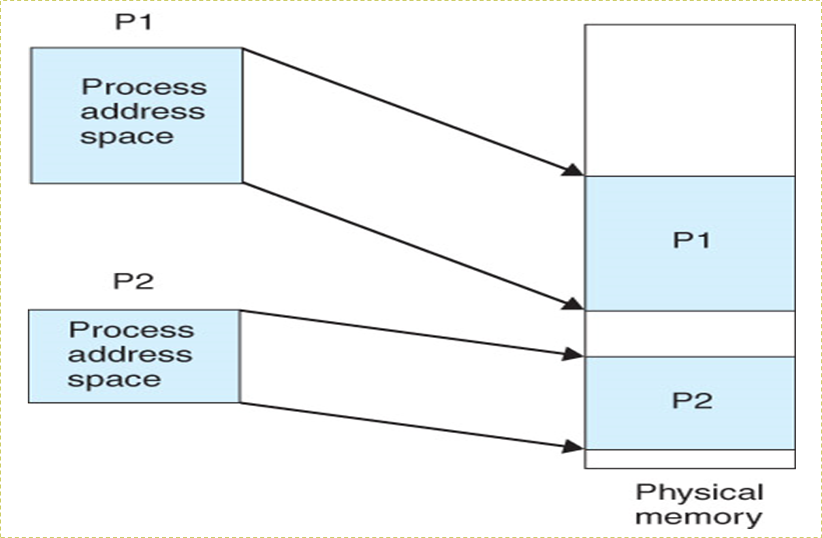
8.1.4 基址寄存器、限长寄存器
基址寄存器base register、限长寄存器limit register:定义了逻辑内存空间
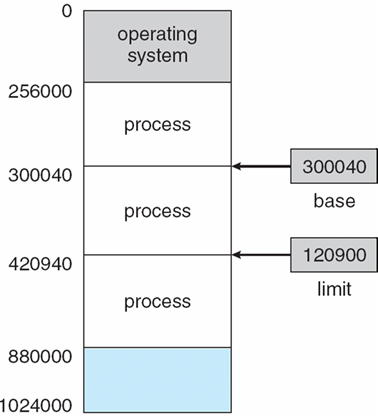
8.1.5 将指令和数据与内存绑定
Address binding(地址绑定、地址映射、重定位):指令和数据到内存地址的转换可以在三个不同的阶段进行
- 编译时间:
- 如果内存位置先验已知,则可以生成绝对代码
- 如果开始位置更改,则必须重新编译代码
- 加载时间:
- 如果编译时内存位置未知,则必须生成可重定位代码 relocatable code
- 执行时间:
- 如果进程在执行过程中可以从一个内存段移动到另一个内存,则绑定延迟到运行时
- 需要地址映射的硬件支持(如:Base and Limit Registers)
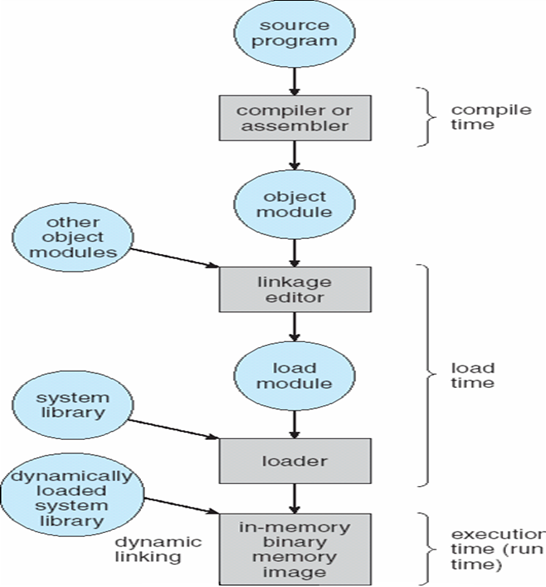
8.1.6 Memory-Management Unit (MMU)
- 将虚拟地址映射到物理地址的硬件设备
- 在MMU方案中,重定位寄存器(relocation register)中的值被添加到用户进程在发送到内存时生成的每个地址
- 用户程序处理逻辑地址;它永远看不到真实的物理地址
8.1.7 Dynamic Loading 动态载入
- 使用动态加载,进程启动时不会加载外部库
- 库以可重定位的形式存储在磁盘上
- 仅在需要时将库加载到内存中
- 更好的内存空间利用率;从未加载未使用的例程
- 当需要大量代码来处理不经常发生的情况时很有用
- 无需通过程序设计实现操作系统的特殊支持
8.1.8 Dynamic Linking 动态链接
- 使用动态链接,可以将外部库预加载到(共享)内存中
- 当进程调用库函数时,确定相应的物理地址
- 一小段代码 (stub) 用于定位适当的内存驻留库例程
- Stub用例程的地址替换自身,并执行例程
- 操作系统需要检查例程是否在进程的内存地址中
- 动态链接对库的调用特别有用
- 这种模式也称为共享库
- Dynamically Linked Library 动态链接库
8.2 Swapping 交换技术
8.2.1 交换技术
- 进程可以临时从内存中交换到后备存储,然后再带回内存中继续执行
- Backing
store备份存储:足够大的快速磁盘,可容纳所有用户的所有内存映像副本;必须提供对这些内存映像的直接访问
- Linux、UNIX-交换区
- Windows-交换文件(pagefile.sys)
- Roll out,Roll in(调出,调进)
- 用于基于优先级的调度算法的交换变量
- 低优先级进程被交换出去,以便可以加载和执行高优先级进程
- 交换时间的主要部分是传输时间;总传输时间与交换的内存量成正比
- 在许多系统(如UNIX、Linux和Windows)上都可以找到经过修改的交换版本
- 系统维护一个准备好运行的进程队列,这些进程在磁盘上具有内存映像
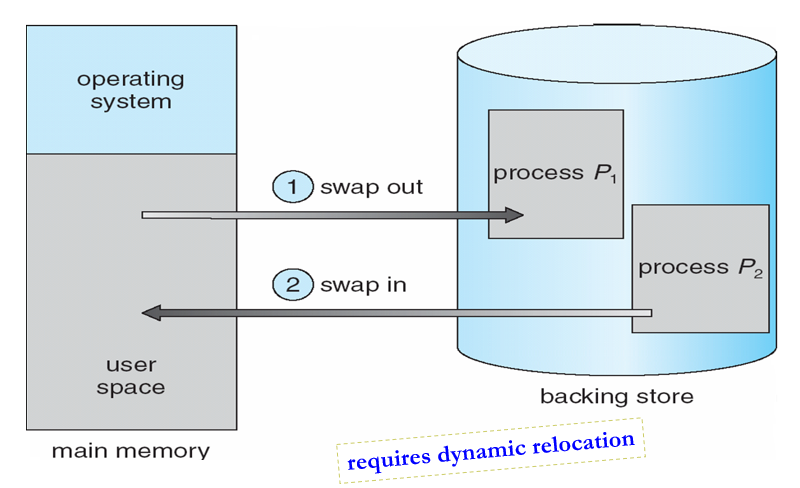
8.2.2 不同操作系统的Swapping
- UNIX, Linux, and Windows:
- 正常情况下,禁止交换
- 当空闲内存低于某一个阈值时,启用交换换出
- 当空闲内存增加一定数量时,停止换出
- 移动系统不支持交换,Flash memory based:
- 小空间
- 闪存写次数限制
- 在移动平台上闪存和CPU之间的吞吐量很低
- iOS要求应用程序自愿放弃分配的内存
- 只读数据从系统中直接删除,已修改数据不会被删除
- OS可以终止任何未能释放足够空间的应用
- Android如果空闲内存不足,会终止应用程序,但首先会将应用程序状态写入闪存,以便快速重启
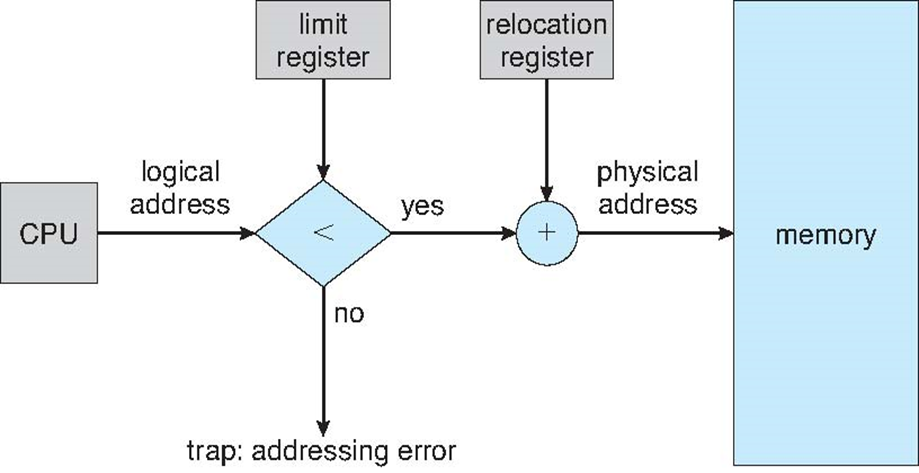
8.3 Contiguous Allocation 连续分配
8.3.1 连续分配
- 主内存通常分为两个分区(分区):
- Resident operating system常驻操作系统:通常保存在具有中断向量的低内存中
- User processes用户进程:保存在高内存中
- Relocation registers
重新定位寄存器:用于保护用户进程彼此不受影响,以及防止操作系统代码和数据发生变化
- Base register基址寄存器:包含最小物理地址的值
- Limit register限制寄存器:包含逻辑地址范围–每个逻辑地址必须小于限制寄存器
- MMU动态映射逻辑地址
8.3.2 Multiple-partition allocation 多分区分配
分区式管理的基本思想是将内存划分成若干个连续区域,称为分区。每个分区只能存放一个进程
8.3.2.1 Fixed Partitioning 固定分区
- 预先将内存空间切分成多个分区,当进程需要分区时,将一个大小匹配的分区分配给它
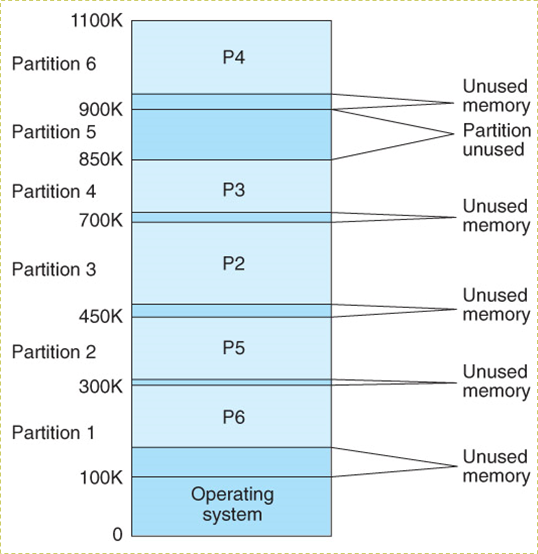
8.3.2.2 Dynamic Partitions 动态分区
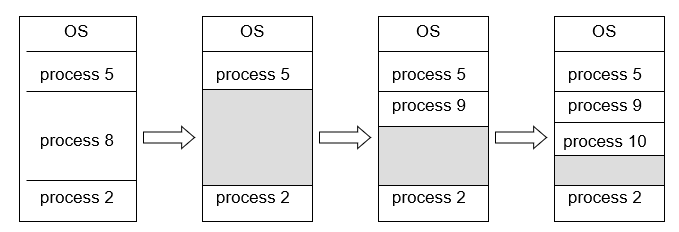
动态划分内存,在程序装入内存时把可用内存“切出”一个连续的区域分配给该进程,且分区大小正好适合进程的需要
操作系统需要维护的信息包括:
- allocated partitions 已分配的分区
- free partitions (hole) 空闲的分区
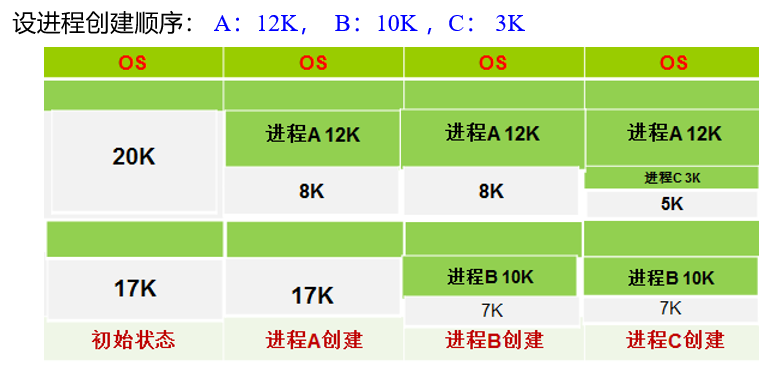
如何满足free holes列表中大小为n的请求
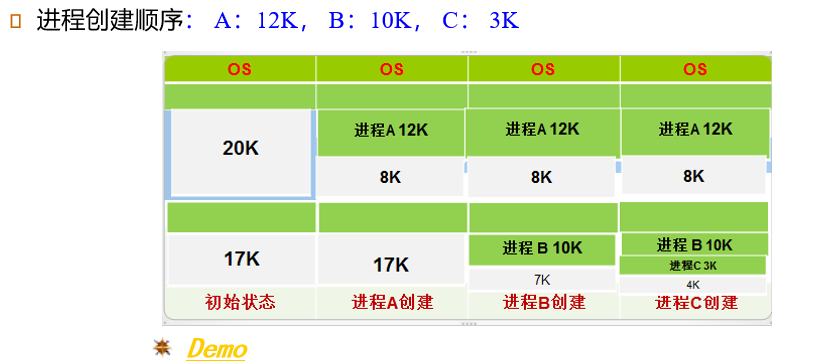
First-Fit:找到第一个能够满足要求的hole
Best-Fit:找到能够满足要求的、最小的hole
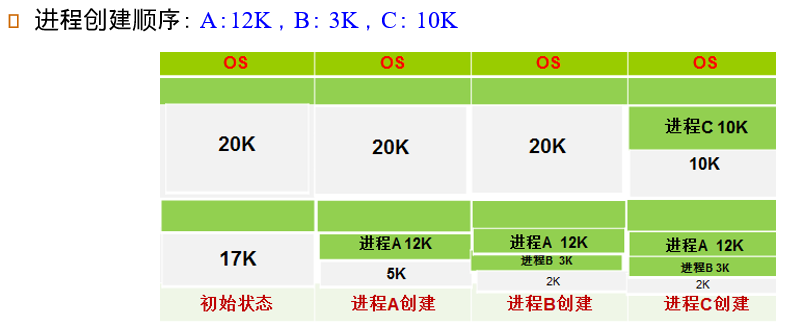
Worst-Fit:找到能够满足要求的、最大的hole
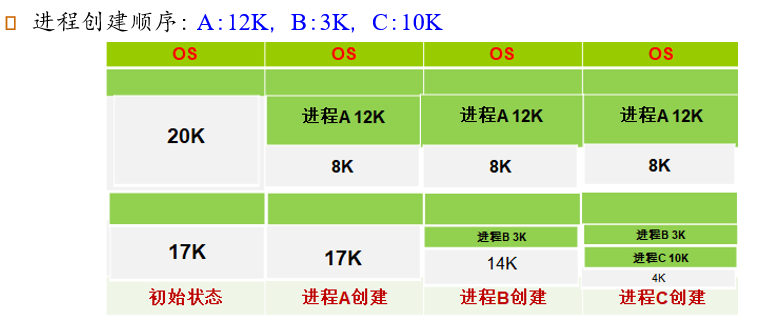
Next-Fit:从上次查找结束的地方开始,找到第一个能够满足要求的hole
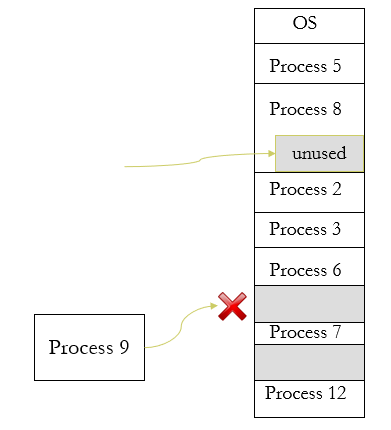
8.3.3 Fragmentation 碎片
内存因碎片而浪费,这可能会导致性能问题
- Internal fragmentation(内碎片、内零头):在单个进程内存空间中浪费内存
- External fragmentation(外碎片、外零头):可能会减少可运行进程的数量
- 总内存剩余空间可以满足要求,但由于内存空间不连续,导致程序不能运行
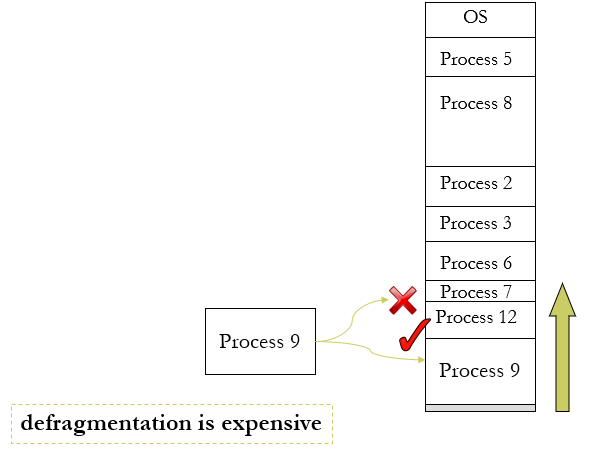
通过压缩或整理碎片减少外部碎片(compaction or defragmentation )
- 重新排列内存内容,将所有可用内存块组织在一个大块中
- 只有当重新定位是动态的并且在执行时完成时,才能进行压缩
8.4 Paging 分页,页式存储管理
8.4.1 Paging
- 进程的物理地址空间可能是不连续的;只要物理内存可用,就为进程分配物理内存
- 将物理内存划分为固定大小的块,称为frames(帧、物理块、页框)
- 大小为2的整数次幂,介于512 bytes和8192 bytes之间
- Linux、Windows for x86:4K
- 将逻辑内存分成与帧大小相同的块,称为pages(页)
- 使用paging的模式
- 跟踪所有空闲帧
- 要运行n pages大小的程序,需要找到n个空闲的frames,然后加载程序
- 如果找不到,可以使用swap技术,将一部分程序放进内存,另一部分程序放入swap区
- 设置page table(页表),将逻辑地址转换为物理地址
- page table 列出了进程的逻辑页与其在主存中的物理帧间的对应关系
- 会存在Internal fragmentation
8.4.2 Noncontiguous Allocation 非连续内存分配
- 当一个进程需要n个page运行时,操作系统会找到n个空闲的frame
- 操作系统通过一个page table,跟踪页的使用
- 一般情况下,最后一个page都无法用满,但是系统依旧会给它分配一个frame
- 会导致Internal fragmentation
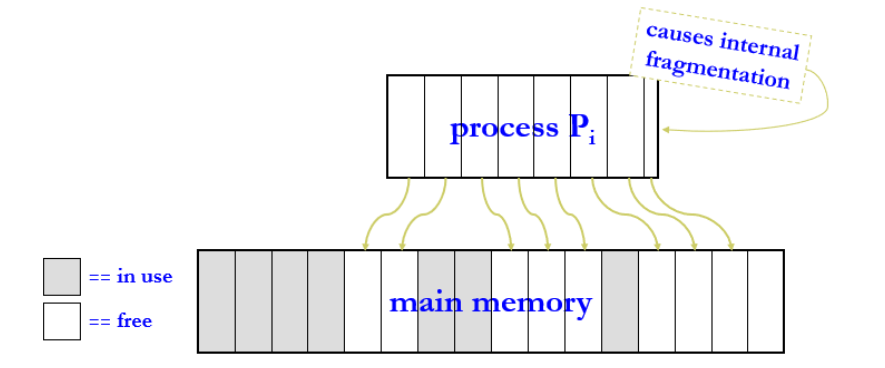
8.4.3 逻辑和物理内存的分页模型
page table将逻辑内存地址映射到物理内存地址
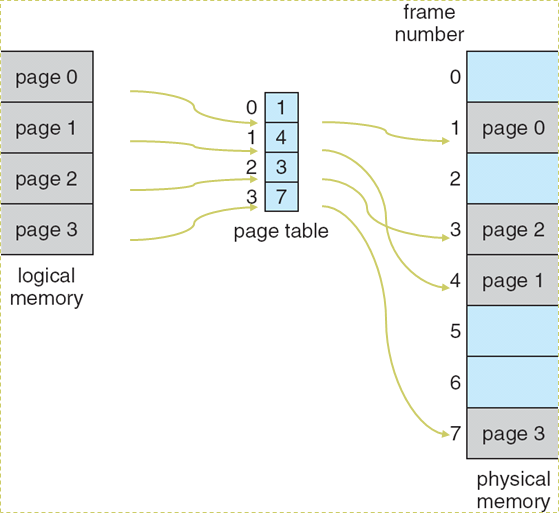
例:进程\(P_i\)需要16字节的逻辑内存
- 逻辑内存通过页面表映射到32字节内存,页面大小为4字节
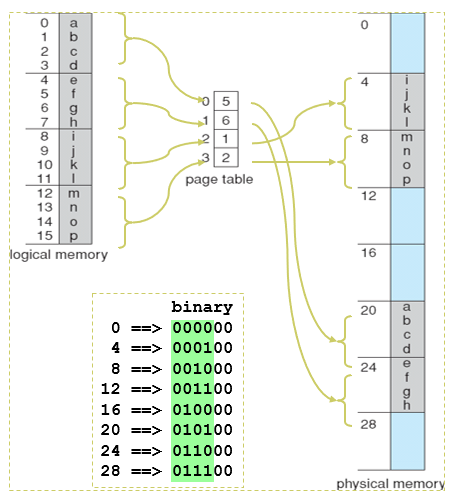
8.4.4 Address Translation Scheme 地址变换
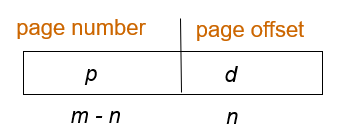
CPU生成的地址分为:
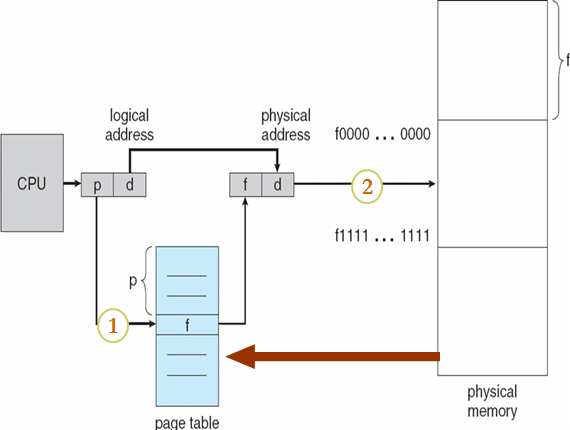
- page number(p)页号:用作页表的索引,该页表包含物理内存中每个页的基地址
- page offset(d)偏移:与基地址相结合以定义发送到存储器单元的物理存储器地址
若page size = 2n,地址空间为 2m,则地址可以分为:
Paging Hardware
页面大小为4KB,虚地址2362H、1565H的物理地址分别是?页表如下
页号 页框 (Page Frame)号 0 101H 1 102H 2 254H - 4KB=1000H
- 逻辑地址2362H对应的页号为2,254000H+362H = 254362H
- 逻辑地址1565H对应的页号为1,102000H+565H = 102565H
8.4.5 Page Table的实现
- 页表保存在Main Memory中
- 页表基寄存器(PTBR, Page-table base register):指向页表,x86:cr3
- 页表长度寄存器(PTLR, Page-table length register ):表示页表的大小
- 在该方案中,每个数据/指令访问都需要两次memory访问
- 一个用于页表
- 一个用于数据/指令
- 两次内存访问可以通过使用cache来加速,该cache被称为联想寄存器、快表
- associative memory
- TLB:translation look-aside buffers
- 一些TLB在每个TLB条目中存储地址空间标识符(ASID, address-space identifiers):唯一标识每个进程,为该进程提供地址空间保护
8.4.6 Associative Memory
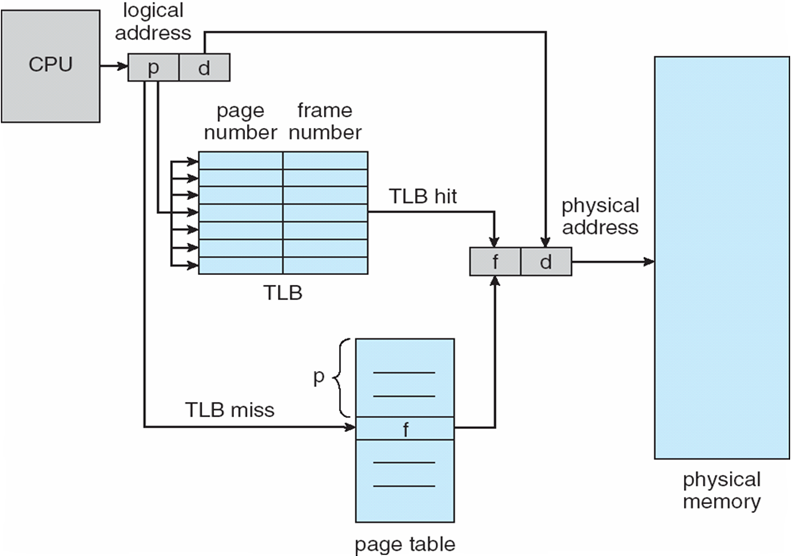
- 并行查找:Address translation(p, d)
- 如果p在Associative Memory中,则取出帧#
- 否则,从内存中的页表获取帧#
8.4.7 Effective Access Time 有效访问时间
- 快表访问时间:Associative Lookup = \(\epsilon\) time unit
- 内存访问时间:memory cycle time = \(t\)
- 命中率:Hit ratio = \(\alpha\)
- 有效访问时间:EAT = \((t+\epsilon)\alpha+(t+t+\epsilon)(1-\alpha)\)

8.4.8 Memory Protection 内存保护
- 通过将保护位与每个帧相关联来实现内存保护
- Valid-invalid bit 附加到页表中每个条目:
- “valid”表示关联页面位于进程的逻辑地址空间中,因此是合法页面
- “invalid”表示页面不在进程的逻辑地址空间中

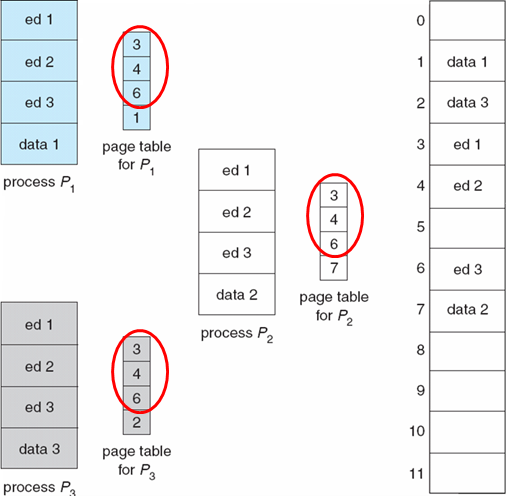
8.4.9 共享页面
- 共享代码
- 进程之间共享的只读代码的一个副本。
- 共享代码必须出现在所有进程的逻辑地址空间中的同一位置
- 私有代码和数据
- 每个进程都保留代码和数据的单独副本
- 私有代码和数据的页面可以出现在逻辑地址空间的任何位置
- 重新输入代码(重入代码)、 纯代码(纯代码)
8.4.10 Page Table的数据结构
8.4.10.1 分级页表 Hierarchical Paging
x86的逻辑地址空间有232Byte,如页面大小为4KB(212Byte),则页表项最多有1M(220)个,每个页表项占用4Byte,故每个进程的页表占用4MB内存空间,还要求是连续的,显然这是不现实的。
将逻辑地址空间分解为多个页表
- 一种简单的技术是两级页表
- Linux:四级页表
- Windows:两级页表
两级页表
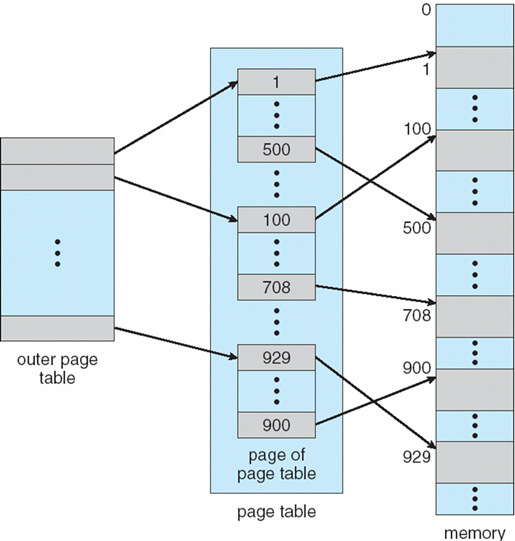
两级页表示例:
逻辑地址(在具有4K页面大小的32位机器上)分为:
- 20-bit page number
- 12-bit page offset
由于页表是分页的,页码进一步分为:
- 10-bit page number
- 10-bit page offset
因此,逻辑地址如下:

其中p1是outer page table的索引,p2是page of the page table的偏移量
地址转换模式:
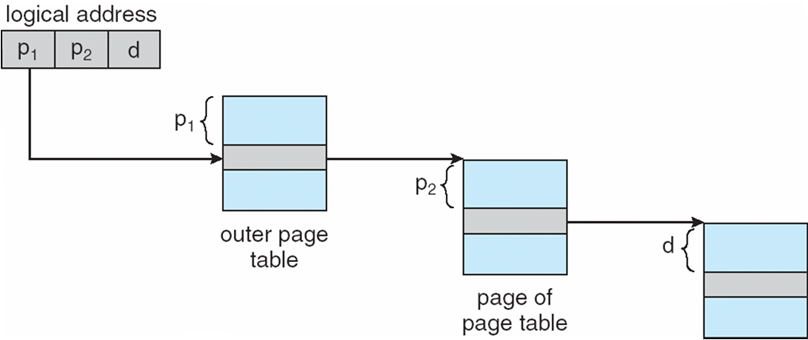
三级Page

8.4.10.2 哈希页表 Hashed Page Tables
- 通常情况下,地址空间>32位
- 虚拟页码被hash到页表中
- 此页表包含hash到同一位置的元素链
- 在此链中比较虚拟页码以搜索匹配项
- 如果找到匹配,则提取相应的物理帧
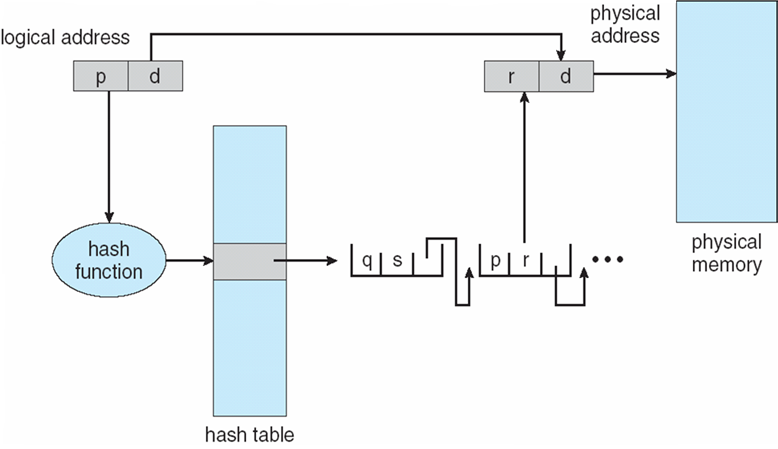
8.4.10.3 反向(反置)页表 Inverted Page Table
- 每个进程均有一个页表,想要让所有进程共享一个页表
- 每个进程自己的page number都是从0开始,但是所有进程的page number均会映射到唯一的frame number
- 在Inverted Page Table中,索引对应物理内存中的frame number,值对应进程+virtual number
- 进程在找frame时,需要遍历Inverted Page Table,十分耗时
- 通过hash table降低遍历所需时间
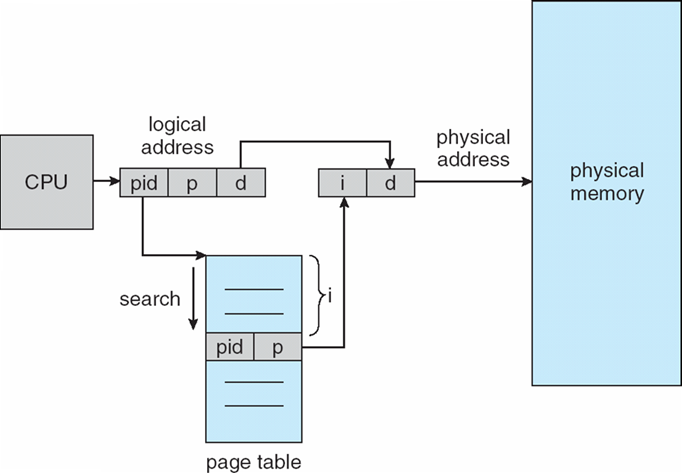
8.5 Segmentation 分段,段式管理
将同一类别的数据,放到对应大小的连续的内存空间
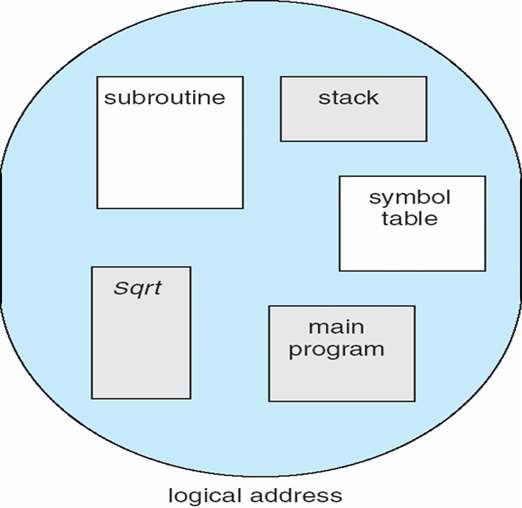
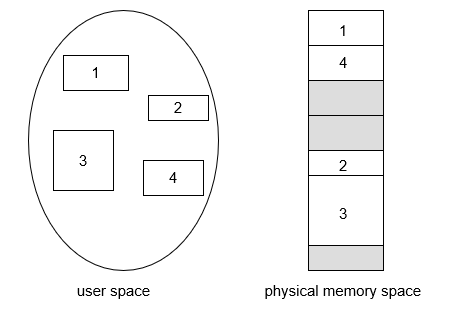
8.5.1 Segmentation Architecture
逻辑地址分为两个部分:段号+段内地址

Segment table(段表):映射二维物理地址;每个entry具有:
- base:包含段在内存中的起始物理地址
- limit:指定段的长度
Segment-table base register(STBR)段表基址寄存器:指向段表在内存中的位置
Segment-table length register(STLR)段表限长寄存器:指示程序使用的段数;
- 如果s<STLR,则段号s合法
保护:
- Segment table中的每一个entry都会包含:
- 有效位 validation bit:为0时表示该segment无效
- 读/写/执行 权限
- 保护位与段相关;代码共享发生在段级别
- 由于段的长度不同,内存分配是一个动态存储分配问题
- 下图显示了一个分段示例
- Segment table中的每一个entry都会包含:
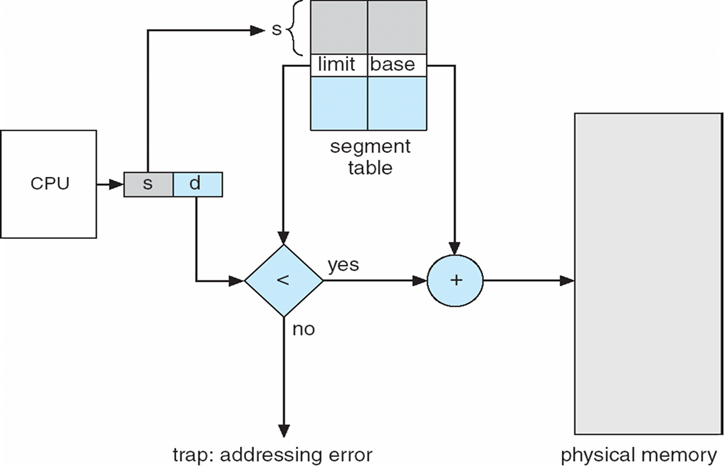
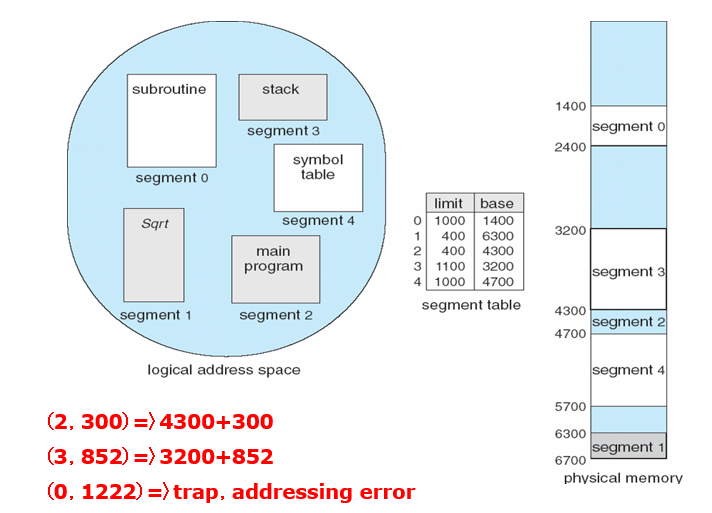
8.6 Example: The Intel Pentium
- 支持分段和分页分段
- CPU生成逻辑地址
- 给分段单元
- 产生线性地址
- 将线性地址给到paging unit
- 在主内存中生成物理地址
- paging units相当于MMU
- 给分段单元

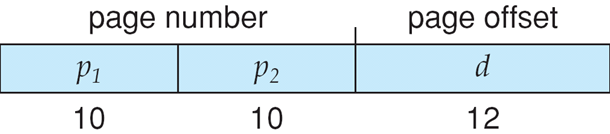
Chapter 9:Virtual Memory
9.1 Background
9.1.1 Virtual Memory
- Virtual Memory:只有运行程序的一部分需要加载到内存中执行
- 虚拟内存将用户逻辑内存与物理内存分开
- 逻辑(或虚拟)地址空间可以大于物理地址空间
- 允许多个进程共享物理地址空间
- 实现更快的流程创建
- Virtual Memory的实现方法:
- Demand paging (请求调页,按需调页,请求页式管理)
- 0Demand segmentation(请求段式管理)
9.1.2 局部性原理
- 局部性原理(principle of
locality):指程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。表现为:
- 时间局部性:一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短时期内
- 空间局部性:当前指令和邻近的几条指令,当前访问的数据和邻近的数据都集中在一个较小区域内
- 虚拟存储器是具有请求调入功能和置换功能,能仅把进程的一部分装入内存便可运行进程的存储管理系统,它能从逻辑上对内存容量进行扩充的一种虚拟的存储器系统
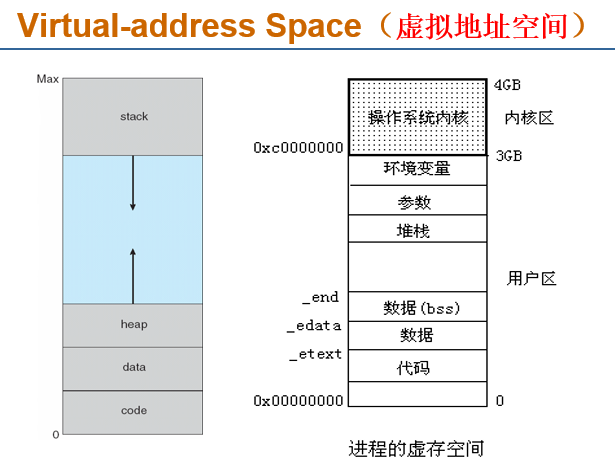
9.2 Demand Paging:按需调页、请求调页
9.2.1 Demand Paging
- 仅在需要时将页面放入内存
- 所需I/O更少
- 所需内存更少
- 更快的响应
- 更多用户
- 需要页面 → 对它的引用
- 无效的引用 → abort
- 不在内存中 → bring to memory
- Lazy swapper:除非需要页面,否则永远不要将页面交换到内存中
- 处理页面的swapper是一个pager
Transfer of a Paged Memory to Contiguous Disk Space
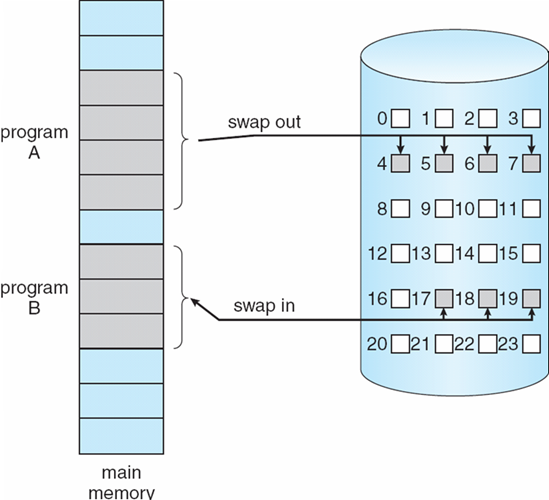
9.2.2 Valid-Invalid Bit
每个页表条目都有一个Valid-Invalid Bit:v → 在内存中,i → 不在内存中
初始化:所有条目上的Valid-Invalid Bit设置为i
页表快照示例:
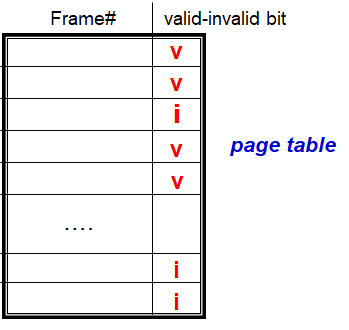
在地址转换期间,如果页表条目中的Valid-Invalid Bit为i → page fault
Page Table When Some Pages Are Not in Main Memory
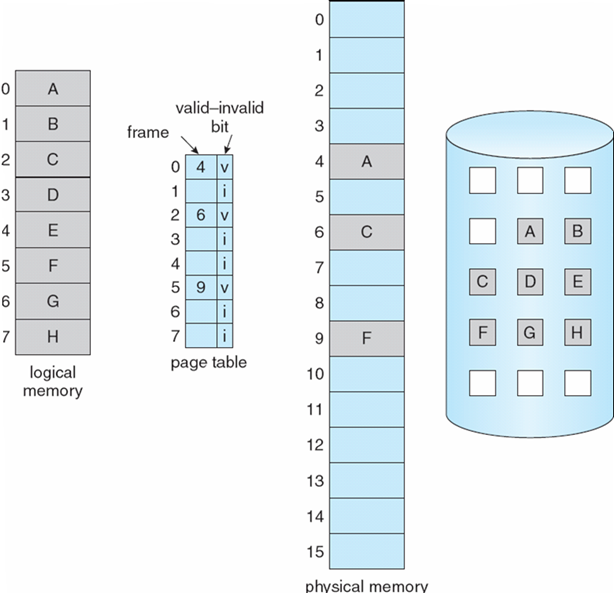
9.2.3 更完整的页表

- 在请求分页系统中的每个页表项如图所示:
- 状态位P(存在位):用于指示该页是否已调入内存,供程序访问时参考
- 访问字段A:用于记录本页在一段时间内被访问的次数,或最近已有多长时间未被访问,提供给置换算法选换出页时参考。
- 修改位R/W:表示该页在调入内存后是否被修改过
- 外存地址:用于指出该页在外存上的地址,供调入该页时使用
9.2.4 Page Fault:缺页
如果存在对页面的引用,则对该页面的第一次引用将会产生:Page Fault(缺页)
- 操作系统查看另一个表以决定:
- 无效的引用 → abort
- 仅仅是不在内存中
- 获取空帧
- 将page交换进frame
- 重置表格
- 设置Valid-Invalid Bit = v
- 重新启动导致页面错误的指令
Steps in Handling a Page Fault
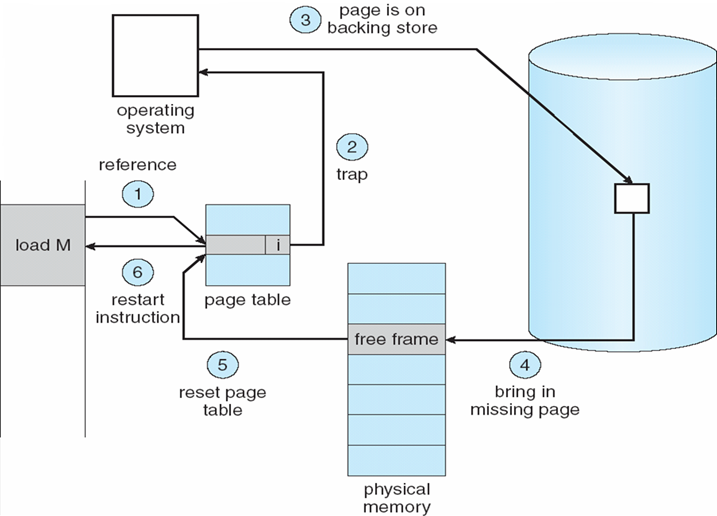
9.2.5 Demand Paging Performance
page fault rate p:
- p=0.0:没有page fault
- p=1.0:所有page均发生page fault
- 通常p很小
effective memory-access time:EAT
- (1-p) × physical-memory-access + p × page-fault service time
page-fault service time:
- page-fault-overhead + swap-page-out + swap-page-in + restart-overhead
要计算EAT,我们必须知道需要多少时间来处理page fault。page fault导致以下操作顺序发生:
- 操作系统发生trap
- 保存用户寄存器和进程状态
- 确定中断是page fault
- 检查页面引用是否合法,并确定页面在磁盘上的位置
- 向空闲帧发出磁盘读取请求:
- 在队列中等待设备,直到读取请求得到服务
- 等待设备查找时间和延迟时间
- 开始将page转移到free frame
- 等待时,将CPU分配给其他用户(CPU调度,可选)
- 从磁盘中断(I/O完成)
- 为其他用户保存寄存器和进程状态(如果执行步骤6)
- 确定中断来自磁盘
- 更正页面表和其他表,以显示所需页面现在已在内存中
- 等待CPU再次分配给此进程
- 恢复用户寄存器、进程状态和新页表,然后恢复中断指令
page-fault service time中的三个主要的部分
- Service the page-fault interrupt:缺页中断服务时间
- Read in the page:将缺页读入时间
- Restart the process:重新启动进程时间
示例:

9.3 Process Creation
- 虚拟内存在进程创建过程中提供了其他好处:Copy-on-Write写时拷贝
- Copy-on-Write写时拷贝:允许父进程和子进程最初共享内存中的相同页面。如果任何一个进程修改了共享页面,则只复制该页面
- COW允许更高效的流程创建,因为只复制修改过的页面
- 可用页面是从一个清零页面池中分配的
- Windows、Linux、Solaris
Before Process 1 Modifies Page C
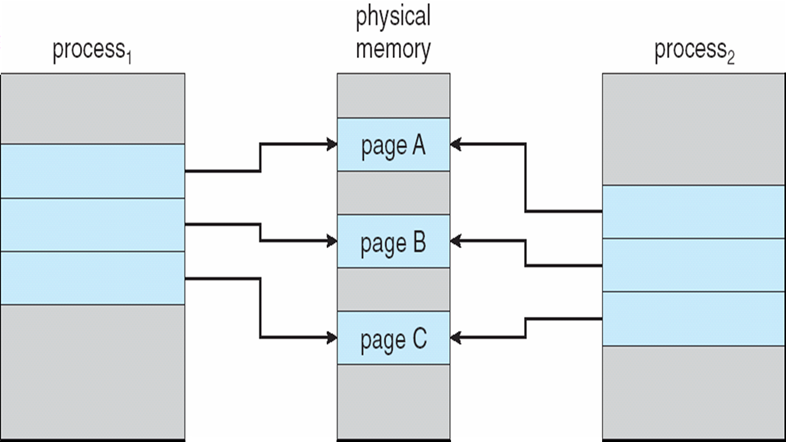
After Process 1 Modifies Page C
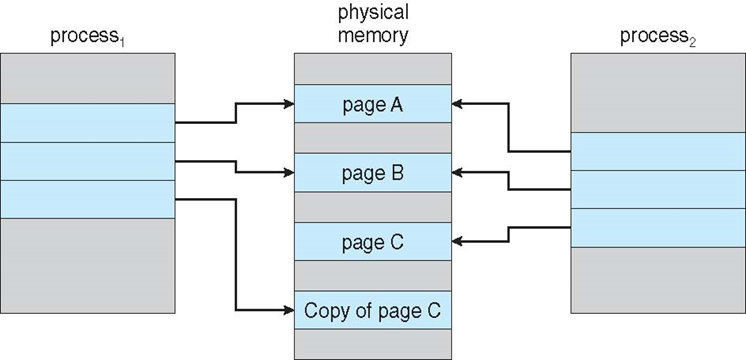
9.4 Page Replacement 页面置换
9.4.1 Page Replacement
如果没有free frame:
- Page Replacement:在内存中找到一些页面,但没有真正使用,请将其替换
- 算法
- 性能:需要寻找一个可能导致page fault最少的算法
- 同一页可能会多次进入内存
- 通过修改 page-fault service routine 以实现页面替换,防止内存过度分配
- 使用modify(dirty)位减少页面传输的开销:只有修改过的页面才会写入磁盘
- 页面替换完成了逻辑内存和物理内存之间的分离:可以在较小的物理内存上提供较大的虚拟内存
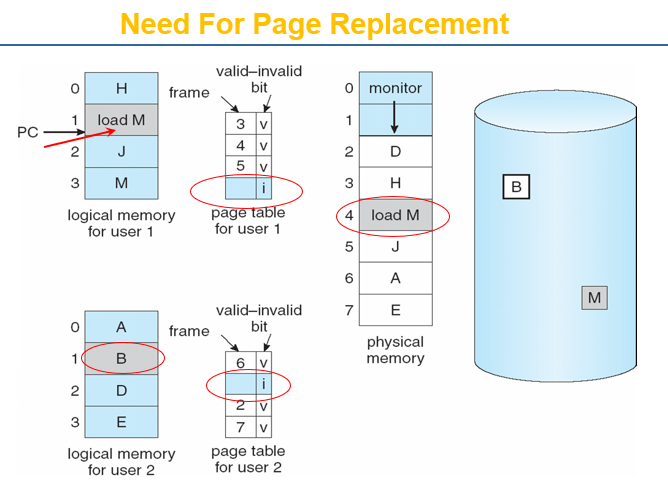
9.4.2 页面置换的过程
- 在磁盘上查找所需页面的位置
- 查找空闲帧:
- 如果有空闲帧,请使用它
- 如果没有空闲帧,则使用页面替换算法选择victim frame
- 将victim page写入磁盘;相应地更改页面和框架表。
- 将所需页面放入(新的)free frame;更新页面和框架表
- 重新启动流程
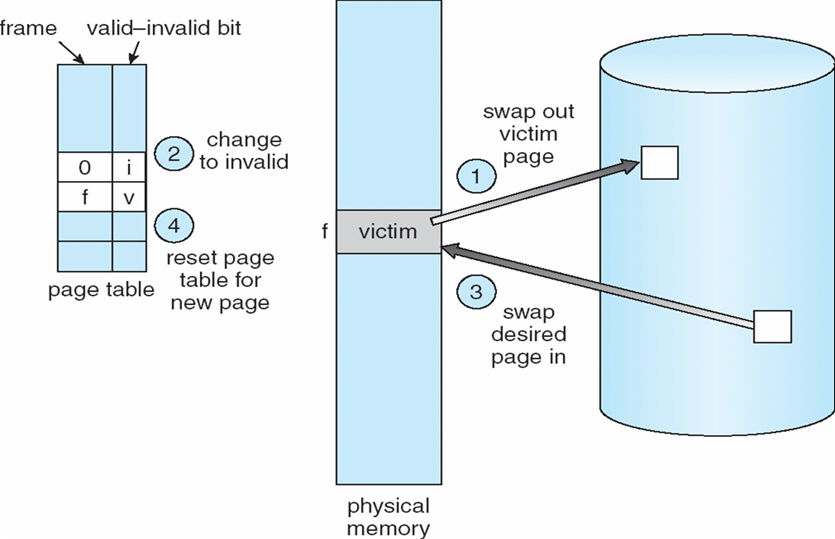
9.4.3 页面置换的算法
希望page-fault rate最低
通过在一个特定的内存引用字符串(reference string,引用串)并计算该字符串上的页面错误数,来判断算法的优劣
reference string:(每页100字节)
0100, 0432, 0101, 0612, 0102, 0103, 0104, 0611, 0120
→ 1, 4, 1, 6, 1, 6, 1
在我们的所有示例中,reference string为:
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
一般来说,帧数越多,page fault越小
页面置换算法:
- First-In-First-Out Algorithm:FIFO,先进先出算法
- Optimal Algorithm:OPT,最佳页面置换算法
- Least Recently Used Algorithm:LRU,最近最少使用算法
- LRU Approximation Algorithms :近似LRU算法
- Additional-Reference-Bits Algorithm
- Second-Chance(clock) Algorithm
- Enhanced Second-Chance Algorithm
- Counting-Base Page Replacement:
- Least Frequently Used Algorithm:LFU,最不经常使用算法
- Most Frequently Used Algorithm:MFU,引用最多算法00000000000000000000000000
- Page Buffering Algorithm:页面缓冲算法
9.4.3.1 FIFO算法
- 先进先出算法
- Belady’s Anomaly:更多的帧反而导致更多的page fault

9.4.3.2 Optimal Page Replacement
- OPT(最佳页面置换算法):选择距离下次使用最远的page进行替换
- 理论最优,但是实际情况中很难判断哪个page距离下次使用最远
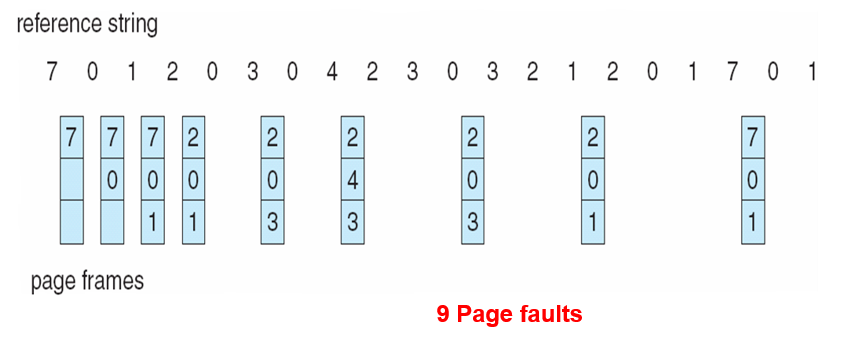
9.4.3.3 LRU算法
LRU(最近最少使用算法):选择内存中最久没有引用的页面被置换
- 这是局部性原理的合理近似,性能接近最佳算法
- 但由于需要记录页面使用时间,硬件开销太大
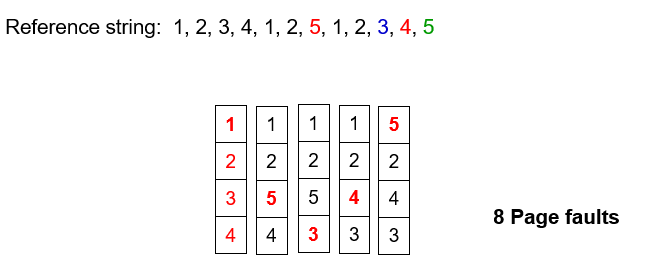
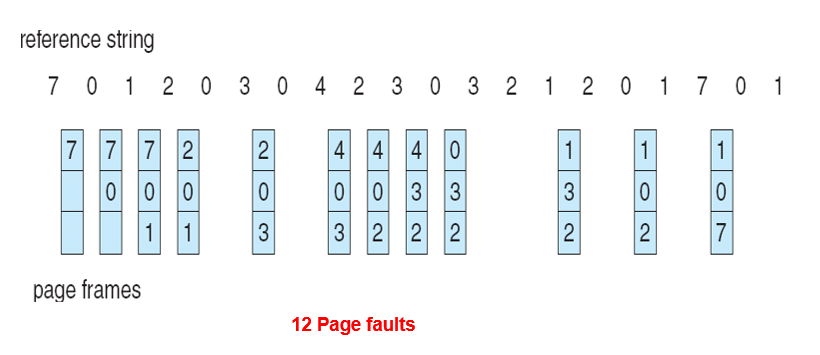
如何获知“多长时间没引用”?
- counter实现
- 每个页面条目都有一个计数器;每次通过该条目引用页面时,将clock复制到计数器中
- 当需要更改页面时,查看计数器以确定要更改的页面
- stack实现:以双向链表形式保存页码堆栈
引用的页面:
- 将其移至顶部
- 需要更改6个指针
不搜索替换
- counter实现
9.4.3.4 LRU Approximation Algorithms
Reference bit
- 每个页表条目关联一个位,初始值为0
- 当页面被引用时,Reference bit设置为1
- 替换Reference bit为0的页(如果存在)
- 然而,我们不知道页被访问的顺序
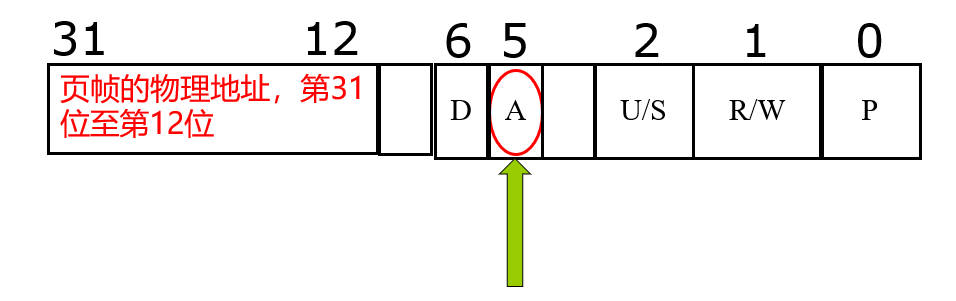
9.4.3.4.1 Additional-Reference-Bits Algorithm
附加引用位算法:
- 为内存中的表中的每一页保留8位字节
- 每隔一段时间(每100毫秒),timer中断将控制权转移到OS
- OS将每个页面的Reference Bit移到其8位字节的最高位,将其他位右移1位,丢弃低位
- 这些8位字节包含过去8个clock的页面使用历史
- 如果我们将这些8位字节解释为无符号整数,则编号最低的页面是LRU页面,可以替换
- 被访问时左边最高位置1,定期右移并且最高位补0,于是寄存器数值最小的是最久未使用页面。
9.4.3.4.2 Second-Chance (clock) Algorithm
Second chance(clock算法):
- 需要Reference Bit
- 循环替换
- 如果要替换的页面(按顺时钟顺序)的Reference Bit=1,则:
- 将Reference Bit设置为0
- 将页面留在内存中
- 替换下一页(按顺时钟顺序),遵循相同规则
9.4.3.4.3 Enhanced Second-Chance Algorithm
增强二次机会算法(改进型的clock算法)
- 使用引用位和修改位:引用过或修改过置成1
- (Reference bit, modified bit) :
- (0,0):最优先需要被替换的页
- (0,1):也可以被替换,但不如上一种更优
- (1,0):可能会马上被使用
- (1,1):最不应该被替换的页
- 淘汰次序:(0,0) → (0,1) → (1,0) → (1,1)
9.4.3.5 Counting Algorithm
- 记录每页的引用次数
- LFU(Least Frequently Used) Algorithm (最不经常使用算法):替换被引用次数最少的页面
- MFU(Most Frequently Used) Algorithm (经常使用算法):被引用次数最小的页面可能刚刚被引入,尚未被使用
9.4.3.6 Page Buffering Algorithm 页面缓冲算法
页面缓冲算法:通过被置换页面的缓冲,有机会找回刚被置换的页面
- 被置换页面的选择和处理:用FIFO算法选择被置换页,把被置换的页面放入两个链表之一。即:如果页面未被修改,就将其归入到空闲页面链表的末尾,否则将其归入到已修改页面链表
- 需要调入新的页面时,将新页面内容读入到空闲页面链表的第一项所指的页面,然后将第一项删除
- 空闲页面和已修改页面,仍停留在内存中一段时间,如果这些页面被再次访问,这些页面还在内存中
- 当已修改页面达到一定数目后,再将它们一起调出到外存,然后将它们归入空闲页面链表
9.5 Allocation of Frames 帧分配
9.5.1 Fixed Allocation 固定分配
- Equal allocation 平均分配法:将帧平均分配给每个进程
- Proportional allocation 按比例分配法:根据进程的大小按比例分配

9.5.2 Priority Allocation 优先级分配
- 根据进程的优先级,按比例分配
- 如果进程Pi发生了page fault
- 选择Pi自己的一个帧进行替换
- 选择比Pi优先级低的一个进程的一个帧进行替换
9.5.3 Global vs. Local Allocation
置换策略:
- Global replacement 全局置换:进程从所有帧的集合中选择替换帧;一个进程可以从另一个进程获取帧
- Local replacement 局部置换:每个进程仅从其自己的一组分配帧中进行选择
分配策略:
- 固定分配
- 可变分配
9.5.4 帧的分配和置换策略
组合成三种策略:
- 固定分配局部置换策略
- 可变分配全局置换策略
- 可变分配局部置换策略
9.6 Thrashing 颠簸、抖动
- 如果一个进程没有足够的page,则page-fault rate会很高,会导致:
- 很低的CPU利用率
- 误导OS以为有必要提高多任务的程度
- 误导OS装入更多作业,内存中驻留更多进程
- 于是,每个进程拥有的页帧数更少
- 如此恶性循环,会怎样 ?
- Thrashing = a process is busy swapping pages in and out

9.6.1 Demand Paging and Thrashing
- 为什么会有demand page work:局部性原理
- 进程从一个位置迁移到另一个位置
- 地点可能重叠
- 为什么会有trash:\(\sum\)locality的大小 > 总内存大小
9.6.2 Working-Set Model
- working set(WS)工作集:在最近Δ次页访问的页的集合
- working-set window工作集窗口Δ:固定次数的页访问
- 如:10000 instruction
- WSSi working set size of Process
Pi工作集大小 = 在最近Δ时间内的页访问总次数
- 如果Δ太小:不能表示整个局部空间
- 如果Δ太大:包括了多个局部空间
- 如果Δ=∞:包括了整个程序
- \(D = \sum
WSS_i\):总共需要的帧;\(m\):总共可用的帧
- \(D>m\)时,会出现Thrashing,需要减少进程数目

9.6.3 Page-Fault Frequency Scheme 缺页频率
缺页频率应该保证在一个区间
- 如果过低:从进程收回帧
- 如果过高:给进程分配帧
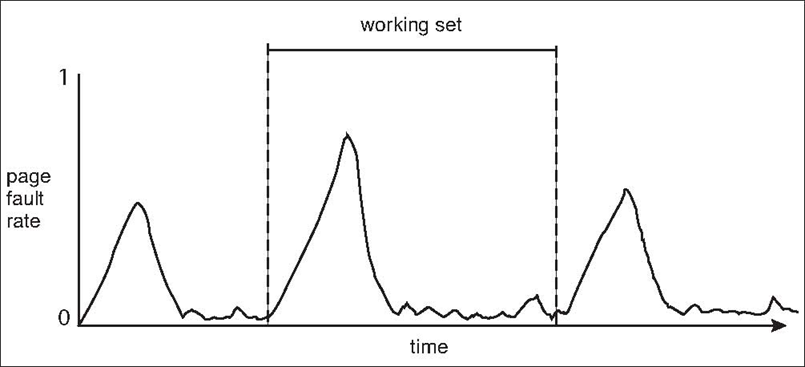
9.7 Memory-Mapped Files
- Memory-Mapped Files I/O:通过将磁盘块映射到内存中的页面,允许将文件I/O视为例行内存访问
- 最初使用请求分页读取文件。文件的页面大小部分从文件系统读取到物理页面中。对文件的后续读/写被视为普通内存访问。
- 通过内存而不是read() write() 系统调用处理文件I/O,简化了文件访问
- 还允许多个进程映射同一文件,从而共享内存中的页面
9.8 Allocating Kernel Memory
9.8.1 Allocating Kernel Memory
- 与分配用户空间的方式不同
- 通常从空闲内存池分配
- 内核根据结构,请求不同大小的内存
- 某些内核内存需要是连续的
9.8.2 Buddy System
- 从由物理上连续的页组成固定大小的段,然后分配内存
- 使用power-of-2 allocator分配内存
- 每个单元的大小为2n
- 每次分配内存的请求对齐到2n,如请求6,则分配23
- 当请求的内存比可用的段小时,当前段被分成两个2n-1的伙伴
- 继续,直到大小合适的块可用
9.8.3 Slab Allocator
另一种内存分配策略
- Slab:是一个或多个物理上连续的页面
- Cache:由一个或多个slab组成
- 每个唯一内核数据结构 <==> 一个cache
- 每个cache都填充了object:数据结构的实例
- 创建cache时,填充标记为空闲的对象
- 存储结构时,对象标记为已使用
- 如果slab中充满了已使用的对象,则从空slab中分配下一个对象
- 如果没有空slab,则分配新的slab
- 优点:没有碎片、快速满足内存请求
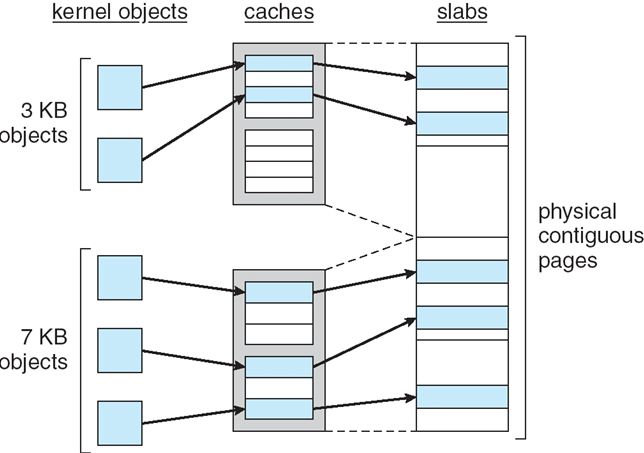
9.9 Other Considerations
9.9.1 Prepaging 预调页
- 减少进程启动时出现的大量page-faults
- 在进程启用之前,预先将一些页调到内存中
- 但是如果预调页没有被使用,则会浪费I/O
- 假设预调页的页数为\(s\),其中\(\alpha\)个页被用到
- 节省的page fault数:\(s*\alpha\)
- 浪费的预调页:\(s*(1-\alpha)\)
- 如果\(\alpha\)接近0,则称为prepaging loses
9.9.2 Page Size 页大小
- 页大小会影响:
- 碎片的大小 fragmentation:页越大,碎片越大
- 页表的大小:页越大,页表越小
- I/O消耗:页越大,I/O消耗越大
- 局部性 Locality:如果页小于working set,则page fault会比较大
- 增加页大小:
- 会导致碎片的大小增加
- 并且并不是所偶有的应用程序都需要一个大的页大小
- 提供多种页大小:
- 这使得需要更大页大小的应用程序有机会在不增加碎片的情况下使用它们
9.9.3 TLB范围
- TLB Reach:TLB能够到达的内存范围
- TLB Reach = TLB Size × Page Size
- 理想情况下,每个进程的working set均存储在TLB中,否则page fault会比较大
9.9.4 程序结构
- 遍历二维数组时,先枚举列还是先枚举行
int data[128][128]; |
9.9.5 I/O锁定
- I/O Interlock:页面有时必须锁定在内存中
- 考虑I/O:用于从设备复制文件的页面必须被锁定,以防止页面替换算法被选中而替换
9.10 Operating System Examples
9.10.1 Windows XP
- Uses demand paging with clustering. Clustering brings in pages surrounding the faulting page
- Processes are assigned working set minimum and working set maximum
- Working set minimum is the minimum number of pages the process is guaranteed to have in memory
- A process may be assigned as many pages up to its working set maximum
- When the amount of free memory in the system falls below a threshold, automatic working set trimming is performed to restore the amount of free memory
- Working set trimming removes pages from processes that have pages in excess of their working set minimum
9.10.2 Solaris
- Maintains a list of free pages to assign faulting processes
- Lotsfree – threshold parameter (amount of free memory) to begin paging
- Desfree – threshold parameter to increasing paging
- Minfree – threshold parameter to being swapping
- Paging is performed by pageout process
- Pageout scans pages using modified clock algorithm
- Scanrate is the rate at which pages are scanned. This ranges from slowscan to fastscan
- Pageout is called more frequently depending upon the amount of free memory available
Chapter 10:File-System Interface
10.1 File Concept
文件:是存储某种介质上的(如磁盘、光盘、SSD等)并具有文件名的一组相关信息的集合
一个文件是在某些硬件设施上的一系列字符

类型:
- 数据型:数字型、字符型、二进制型
- 程序型
10.1.1 文件属性
- Name:文件名
- Identifier:文件标识,唯一标记文件系统中的文件
- Type:文件类型,系统用于支持不同类型的文件
- Location:文件在设备中的位置
- Size:当前文件大小
- Protection:控制谁可读/写/执行
- Time, date, and user identification:用于保护/安全/使用监视的数据
- 有关文件的信息保存在磁盘上维护的目录结构中
10.1.2 文件操作
文件是一个抽象数据类型
- create
- write
- read
- reposition within file
- delete
- truncate
- open(Fi):在磁盘上的目录结构中搜索entry Fi,并将条目的内容移动到内存中
- close(Fi):将内存中entry Fi的内容移动到磁盘上的目录结构
10.1.3 打开文件
用于打开文件的数据信息:
- File pointer:指向文件打开的每个进程的最后一个读/写位置的指针
- File-open count:文件打开次数的计数器,允许在最后一个进程关闭时从打开的文件表中删除数据
- Disk location of the file:数据访问信息缓存
- Access rights:每个进程访问模式信息
10.1.4 文件的内部结构
- None 流文件结构
- 一系列word/byte
- Simple record structure 记录文件结构
- 行
- 固定长度
- 可变长度
- Complex Structures
- 格式化文档
- 可重定位的加载文件
- 通过插入适当的控制字符,可以使用第一种方法模拟后两种
- Who decides:
- 操作系统
- 对应程序
10.2 Access Methods
Sequential Access 顺序存取
Direct Access 直接存取
使用Direct-access File模拟顺序存取
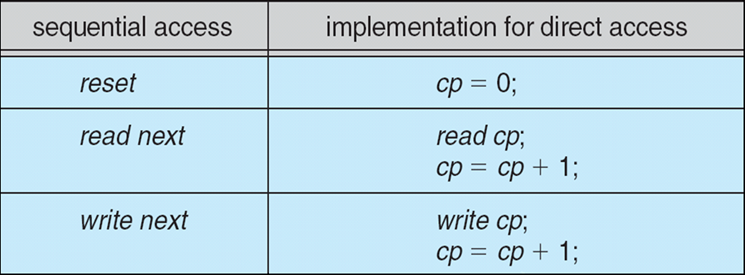
Indexed sequential-acess 索引顺序
Index and Relative File
10.3 Directory Structure 目录结构
10.3.1 目录结构
目录:一个节点的集合,包含所有文件的相关信息
10.3.2 磁盘结构
- 磁盘可以被分割为partitions(分区)
- 磁盘/分区可以作为RAID来预防failure
- 磁盘/分区可以使用raw,即使没有文件系统 或者 没有被文件系统格式化过
- 分区,也被称为minidisk,slice
- 包含文件系统的示例被称为volume(卷)
- 包含文件系统的每个卷还跟踪设备目录或卷目录中的文件系统信息
- 除了通用文件系统外,还有许多专用文件系统,通常都在同一操作系统或计算机中
10.3.3 目录的操作
- 搜索文件
- 创建文件
- 删除文件
- 列出目录
- 重命名文件
- 遍历文件系统
10.3.4 文件目录的组织结构
需要考虑以下问题:
- 查找效率:能够快速定位一个文件
- 重名:不同用户是否可以拥有同名文件,相同文件是否可以拥有不同名字
- 分组:通过文件的特性对文件分组
10.3.4.1 Single-Level Directory 单级目录
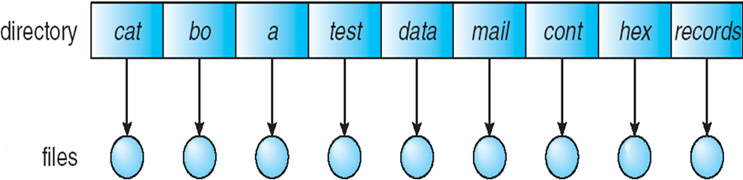
- 重名:不同用户不能拥有同名文件,相同文件不能拥有不同名字
- 分组:不能按照文件类型进行分组
10.3.4.2 Two-Level Directory 二级目录
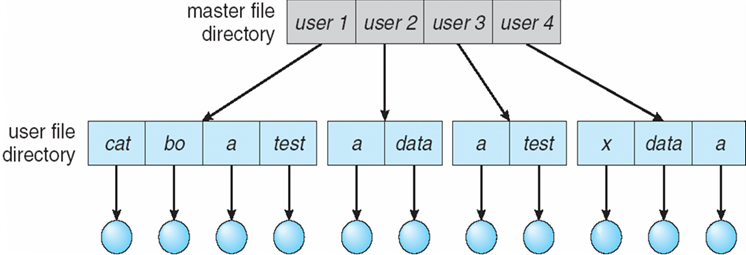
- 查找效率:使用路径名
- 重名:不同用户可以拥有同名文件,相同文件不能拥有不同名字
- 分组:不能按照文件类型进行分组
10.3.4.3 Tree-Structured Directories 树型目录
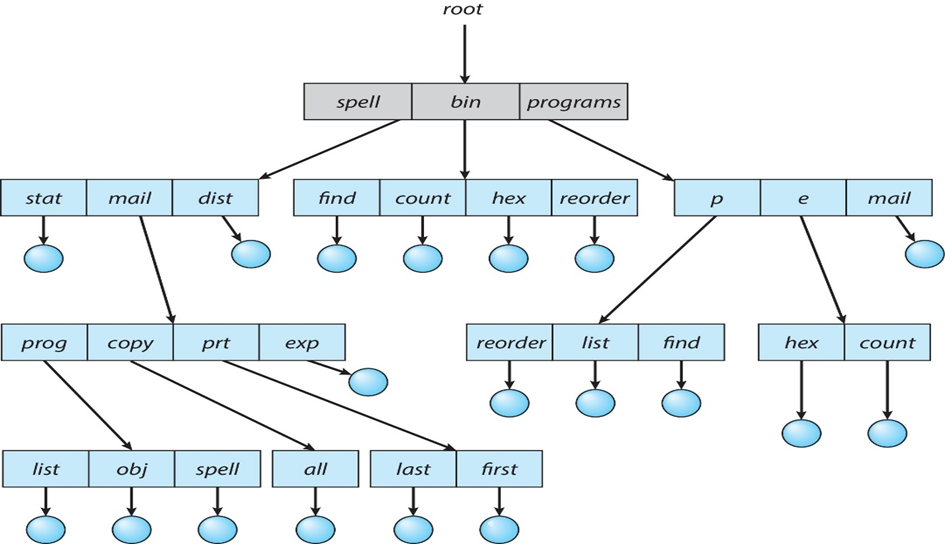
查找效率:使用路径名,需要有当前目录的路径(绝对路径/相对路径)
- cd /spell/mail/prog
- type list
重名:不同用户可以拥有同名文件,相同文件不能拥有不同名字
分组:可以按照文件类型进行分组
删除文件:
rm <file-name>添加目录:
mkdir <dir-name>示例:当前路径为
/mail,执行mkdir count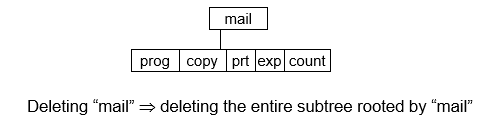
10.3.4.4 Acyclic-Graph Directories 有向无环图结构目录
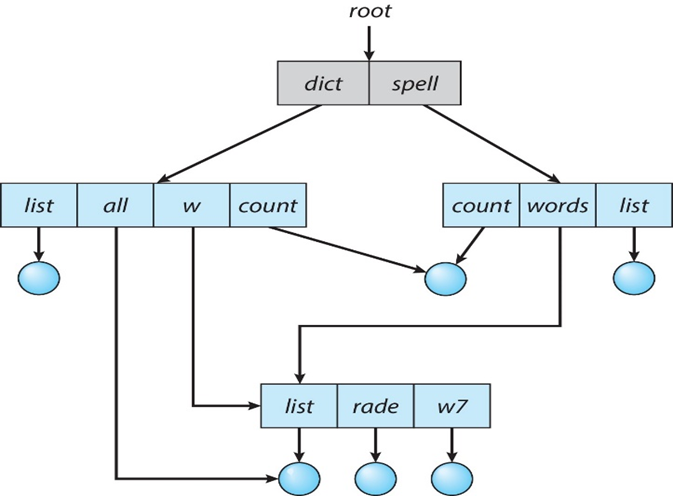
- 同一个文件可以有不同的名字
- 如果文件被删除了,但是指针没有被删除,则会导致dangling
pointer,解决方法:
- Backpointers 逆向指针:删除文件时删除所有指针
- Backpointers 使用菊花图的组织方式
- Entry-hold-count solution 表项保留计数
- 新的目录实体类型
- Link:一个已经存在的文件的另一个名字(指针)
- Resolve the link:通过指针定位文件
10.3.4.5 General Graph Directory 普通图结构目录
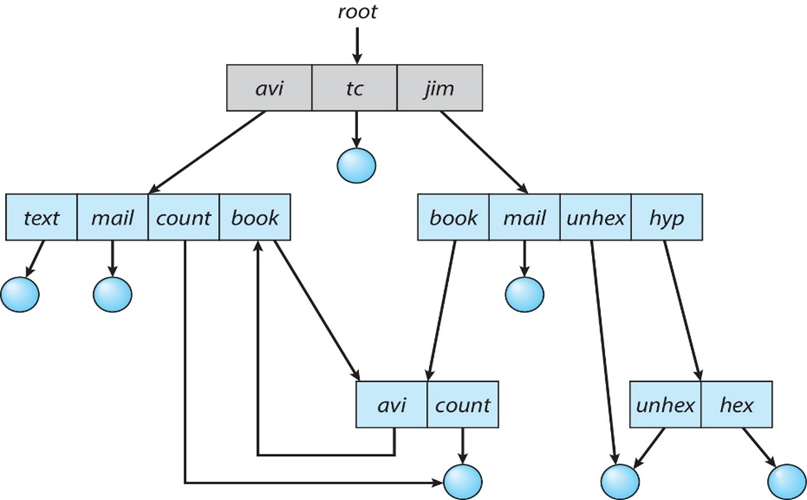
如何保证没有环
- 只允许到文件的link,不允许到目录的链接
- 垃圾回收机制
- 检测自我引用的文件,其引用计数不等于0
- 垃圾收集涉及遍历整个文件系统,并标记所有可访问的空间。然后,第二次将所有没有标记的
- 部分收集到空闲空间链表上。
- 每次添加新link时,使用环检测算法(cycle detection algorithm),确定是否可以添加
10.4 文件系统的挂载
- 文件系统只有被挂载了(mounted),才能被使用
- 文件系统会被挂载到挂载点(mount point)上
- Existing (b) Unmounted Partition
mount point 挂载点
10.5 文件共享
- 多用户系统需要实现文件的共享
- 共享的文件可能是保护模式
- 在分布式系统中,文件可以通过网络共享
- 通常使用Network File System (NFS) 实现分布式文件共享
10.5.1 文件共享:多用户
- User IDs:识别用户,授予每个用户权限和保护
- Group IDs:允许用户在组中,授予组访问权限
10.5.2 文件共享:远程文件系统
- 使用网络允许系统之间的文件系统访问
- 使用FTP等程序手动共享
- 使用分布式文件系统distributed file systems自动共享
- 通过万维网world wide web半自动共享
- 客户端-服务器模型允许客户端从服务器装载远程文件系统
- 服务器可以为多个客户端提供服务
- 客户端和用户对客户端标识不安全或复杂
- NFS是标准的UNIX客户端-服务器文件共享协议
- CIFS是标准的Windows协议
- 标准操作系统文件调用被转换为远程调用
- LDAP、DNS、NIS、Active Directory等分布式信息系统(分布式命名服务)实现了对远程计算所需信息的统一访问
10.5.3 文件共享:错误模式
- 由于网络故障、服务器故障,远程文件系统添加了新的故障模式
- 故障恢复可能涉及有关每个远程请求状态的状态信息
- 无状态协议(如NFS)包含每个请求中的所有信息,允许轻松恢复,但安全性较低
10.5.4 文件共享:一致性问题
一致性语义Consistency semantics:指定多个用户如何同时访问共享文件
- 类似于Ch 7 进程同步算法
- 由于磁盘I/O和网络延迟,会相对简单一点
- Andrew文件系统(AFS)实现了:
- 复杂的远程文件共享语义
- Unix文件系统(UFS)实现了:
- 写入同一打开文件的其他用户立即可见的打开文件
- 共享文件指针以允许多个用户同时读写
- AFS具有会话语义
- 仅对文件关闭后开始的会话可见的写入
10.6 Protection
- 文件的拥有者/创建者需要能够控制:
- 可以做什么
- 谁可以做
- 操作的类型:
- 读
- 写
- 执行
- 扩展
- 删除
- 列表
10.6.1 Access Lists and Groups
- 基础操作:读R、写W、执行X
- 三种用户
- 所有者owner
- 组group
- 公共public
- 要求管理员创建group、添加用户到group
- 对一个特定的文件/子目录,定义访问的权限
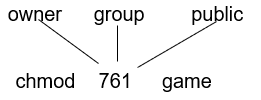
Chapter 11:File System Implementation
11.1 File-System(organized) Structure
- 文件的结构:
- 逻辑存储单元
- 相关信息的集合
- 文件系统总是分层结构
- 文件系统存储在磁盘上
- 通过允许轻松地存储、定位和检索数据,提供对磁盘的高效和方便的访问
- 文件系统:是操作系统中以文件方式管理计算机软件资源的软件和被管理的文件和数据结构(如目录和索引表等)的集合
- File control block 文件控制块:由文件信息(属性)组成的存储结构
- Device driver 设备驱动:控制物理设备
11.1.1 分层设计的文件系统
- 应用程序:
- 发送文件请求的代码
- 逻辑文件系统
- 管理元数据:文件系统的所有结构数据,而不包括实际数据(或文件内容)
- 根据给定符号文件名来管理目录结构
- 逻辑文件系统通过文件控制块(FCB)来维护文件结构
- 文件组织模块
- 知道文件及其逻辑块和物理块。
- 空闲空间管理器
- 基本文件系统
- 向合适的设备驱动程序发送一般命令就可对磁盘上的物理块进行读写
- I/O控制
- 由设备驱动程序和中断处理程序组成,实现内存与磁盘之间的信息转移

11.1.2 文件系统的类型



11.2 文件系统的实现
11.2.1 在磁盘中的文件系统结构
在磁盘上,文件系统可能包括如下信息:
- 如何启动所存储的操作系统
- 总的块数
- 空闲块的数目和位置
- 目录结构以及各个具体文件等
磁盘结构包括
- Boot control block:包含系统从该卷启动OS所需的信息
- Volume(卷)control block:包含卷详细信息
- Directory structure:组织文件
- Per-file File Control Block (FCB,文件控制块):包含文件的许多详细信息
一个典型的文件控制块如下:
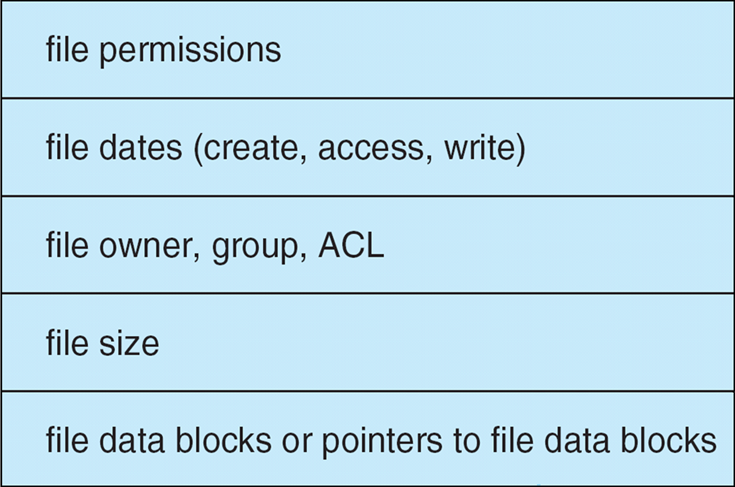
11.2.2 在内存中的文件系统结构
- An in-memory partition table:分区表
- An in-memory directory structure:目录结构
- The system-wide open-file table:系统打开文件表
- The per-process open-file table:进程打开文件表
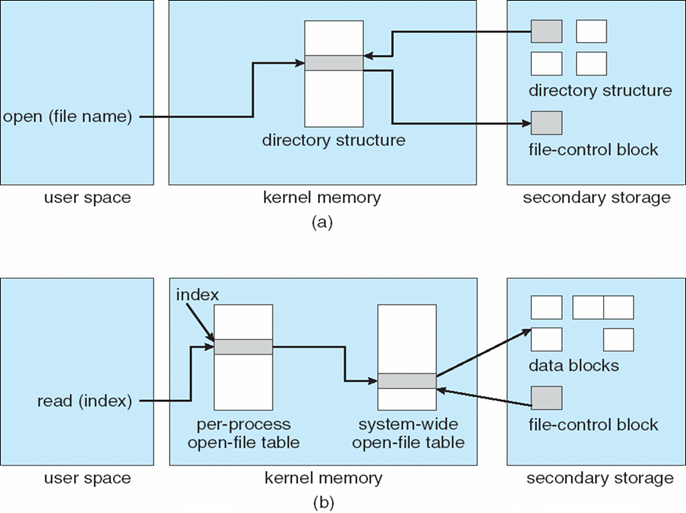
11.2.3 虚拟文件系统
- 虚拟文件系统(VFS)提供了一种实现文件系统的面向对象方法
- VFS允许相同的系统调用接口(API)用于不同类型的文件系统
- API用于VFS接口,而不是任何特定类型的文件系统
11.3 目录实现
11.3.1 线性列表
- Linear list线性列表:存储文件名、指向数据块的指针
- 实现简单
- 但是访问文件需要线性遍历
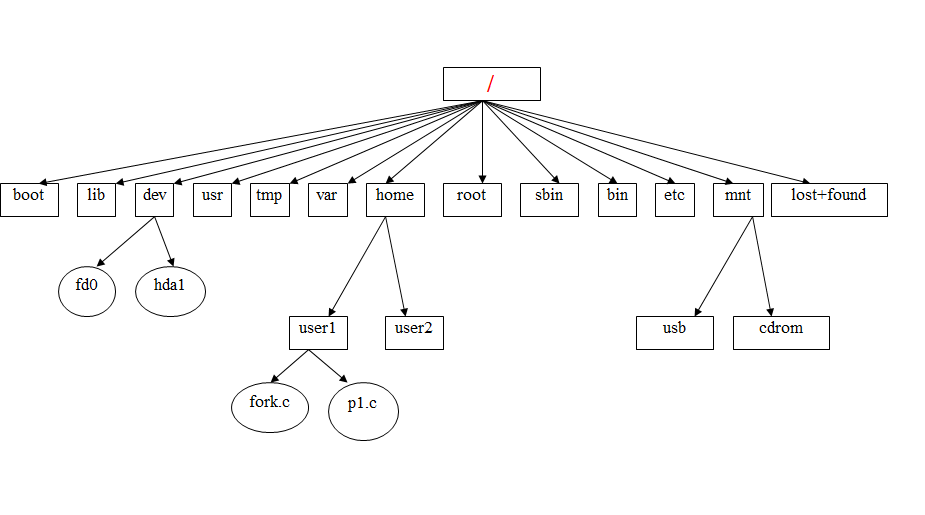
11.3.2 哈希表
- Hash Table哈希表:
- 降低了搜索时间
- collision冲突:当两个文件名hash到同一个位置时,会发生冲突
- fixed size:哈希表的最大困难是其通常固定的大小和哈希函数对大小的依赖性
- 可以使用两层hash优化
11.4 Allocation Methods, 文件物理结构
- An allocation method refers to how disk blocks are allocated for
files:
- Contiguous allocation 连续分配
- Linked allocation 链接分配
- Indexed allocation 索引分配
- Unix、Linux直接间接混合分配方法
11.4.1 连续分配
11.4.1.1 连续分配
每个文件占据磁盘上连续的块
简单:只需要知道文件的起始位置(block #)和长度(number of blocks)
Random Access 随机存取
如果动态分配的话,会浪费空间
文件变动的成本很高
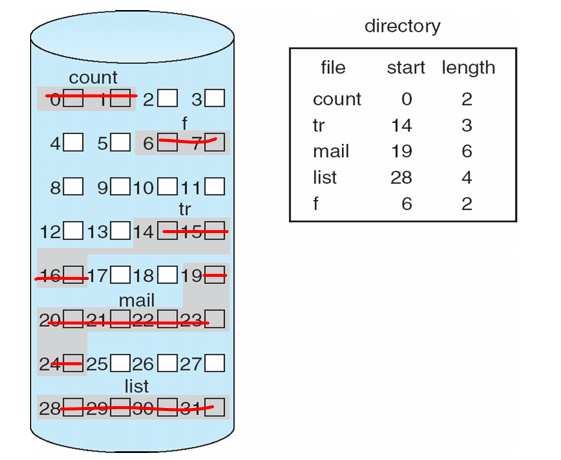
逻辑地址 => 物理地址:LA / 512
- LA:存取文件的逻辑地址
- 512:每块的大小
- 待访问的块:Q+starting address
- 块内偏移量:R
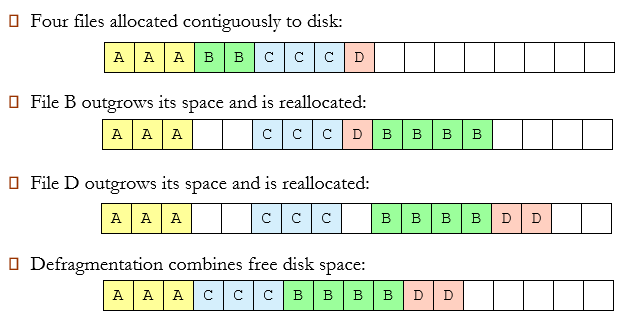
11.4.1.2 基于扩展的连续分配系统
- 将程序分为多个段
- 每个段是空间中的一片连续的空间
- 不同段之间可以不连续

11.4.2 链接分配
11.4.2.1 链接分配
- 文件的内容放在内存中不同的块,通过链表将不同块连接起来
- 简单:只需要存储链表的起始地址,每个块内部会有指向下一个块的指针
- 不会浪费空间
- 不能随机访问
- 逻辑地址 => 物理地址:LA / 512
- 缺点:如果其中一个块的指针被修改了,那么后面的块均无法访问
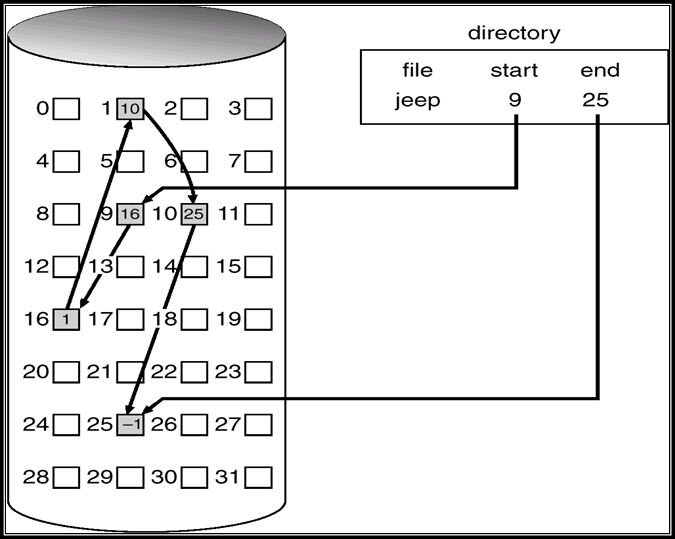
11.4.2.2 链接分配的变种:FAT文件系统
File-allocation table(FAT):文件分配表,是一个单独的数据结构,存储文件的链表信息
- 原本的链表指针存储在每个数据块中
- FAT表使用单独的空间,存储了整个文件的每一个块的链表指针
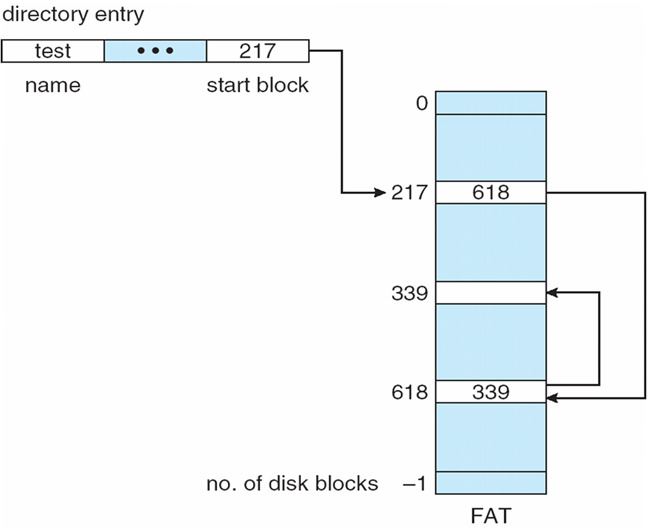
FAT12、FAT16、FAT32
FAT32引导区记录被扩展为:包括重要数据结构的备份,根目录为一个普通的簇链,其目录项可以放在文件区任何地方
FAT32磁盘的结构:
- 主引导记录MBR:是主引导区的第一个扇区,它由两个部分组成:
- 第一部分主引导代码,占据扇区的前446个字节,磁盘标识符(FD 4E F2 14)位于这段代码的未尾
- 第二部分是分区表,分区表中每个条目有16字节长,分区表最多有4个条目,第一个分区条目从扇区的偏移量位置是0x01BE
- 扩展引导记录:与主引导记录类同,如该扩展分区未装操作系统则第一部分主引导代码为0,标签字也标记一个扩展分区引导区和分区引导区的结束
- 计算机系统启动时,首先执行的是BIOS引导程序,完成自检,并加载主引导记录和分区表,然后执行主引导记录,由它引导激活分区引导记录,再执行分区引导记录,加载操作系统,最后执行操作系统,配置系统
- 主引导记录MBR:是主引导区的第一个扇区,它由两个部分组成:
FAT32目录项结构
- FAT的每个目录项为32个字节
FAT32长文件名的目录项由几个32B表项组成
- 用一个表项存放短文件名和其他属性(包括簇号、文件大小,最后修改时间和最后修改日期、创建时间、创建日期和最后存取日期),短文件名的属性是0x20
- 用连续若干个表项存放长文件名,每个表项存放13个字符(使用Unicode编码,每个字符占用2个字节)
- 长文件名的表项首字节的二进制数低5位值,分别为00001 、00010 、 00011 、……,表示它们的次序,左起第2位为1(也就是在低5位基础上加40H)表示该表项是最后一项。最后项存放13个字符位置多余时,先用2个字节0表示结束,再用FFH填充
- 长文件名的属性是0x0F
- 长文件名项的第13、27、28字节为0x00,第14字节为短文件名校验和
- 长文件名The quick brown.fox(短文件名为THEQUI~1.FOX)目录项格式如下:
11.4.2.3 NTFS文件系统
NTFS卷布局:

每个分区均有一个主文件表Master File Table(MFT)
- MFT用数据库记录形式组织,每条记录(MFT表项)长度1K
- MFT由一个个MFT项(也称为文件记录)组成,每个MFT项占用1024字节的空间
- MFT前16个记录用来存放元数据文件的信息,它们占有固定的位置
- 每个MFT项的前部几十个字节有着固定的头结构,用来描述本MFT项的相关信息。后面的字节存放着文件属性等
- 每个文件或目录的信息都包含在MFT中,每个文件或目录至少有一个MFT项

11.4.3 索引分配
11.4.3.1 索引分配
将所有指针统一放到索引块 index block中
逻辑视图
每个文件都使用磁盘上的索引块来包含文件使用的其他磁盘块的地址
当写入第\(i\)个块时,块的地址被放置在索引块的第\(i\)个位置
方法会浪费空间,因为对于小文件,大部分索引块都被浪费了
- 如果索引块太小,我们可以:
- 将几个链接在一起
- 使用多级索引
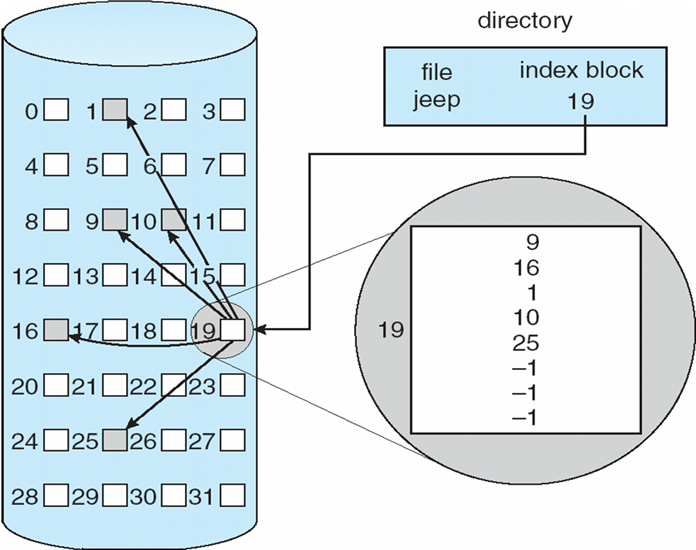
- 如果索引块太小,我们可以:
需要索引表
可以实现随机访问
动态分配不会产生额外的碎片,但是会浪费索引块的空间
在最大大小为256KB、块大小为512B的文件中从逻辑映射到物理。索引表只需要1个块
11.4.3.2 链接索引
- 将索引表,使用链表连接起来
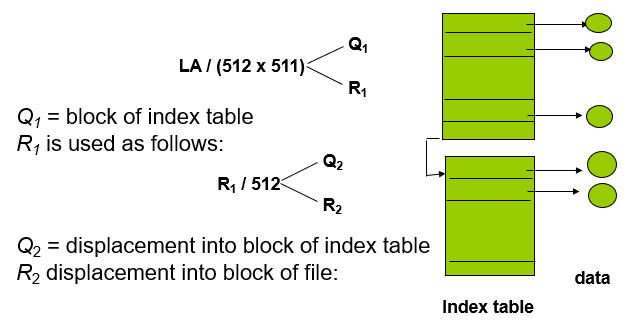
11.4.3.3 二级索引
- Two-level index
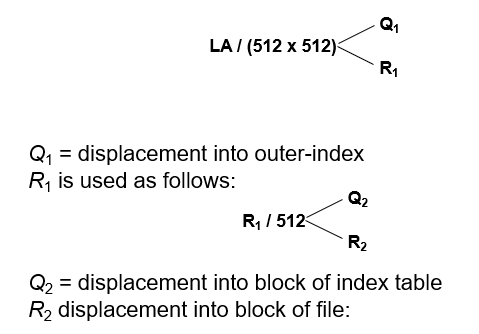
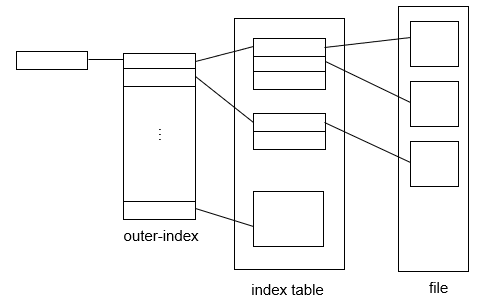
11.4.4 组合模式
- 使用不同索引,适配不同大小的文件
- direct blocks:直接指向数据所在的位置
- single indirect:指向一级索引块
- double indirect:指向二级索引块
Linux ext2/ext3
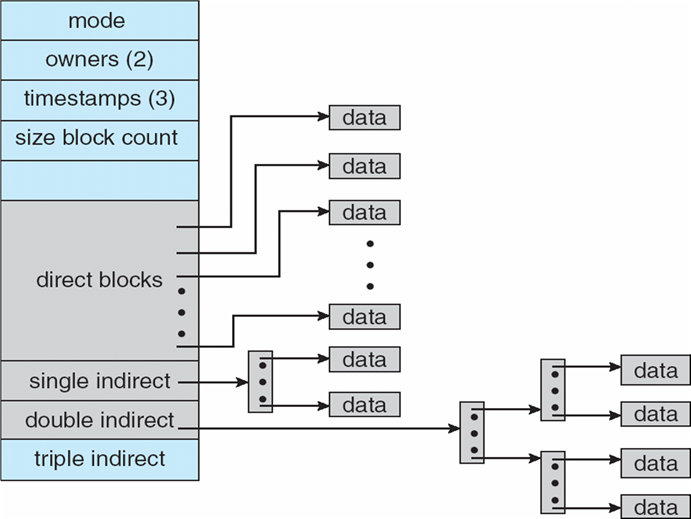
11.5 Free-Space Management 空闲空间管理
Bitmap 位图
对于有n个blocks的空间 \[ bit[i]=\left\{ \begin{aligned} & 0 => block[i]空闲\\ & 0 => block[i]被占用 \end{aligned} \right. \]
Bitmap需要额外的空间来记录空闲空间

Free list 空闲列表
- 将空闲的空间连接起来
- 没有空间浪费
- 但是不能容易的得到连续的空间
Grouping 分组
- 可以较为容易的得到一块连续的空间
- 如果分组大小为固定的,则难以满足所有程序的需求
- 如果分组大学为动态的,则容易产生碎片
Counting 空闲表
需要保护的内容:
- 指向空闲列表的指针
- Bitmap:
- 必须保存在磁盘上
- 内存和磁盘中的副本可能不同
- 不能允许block[i]在内存中的bit[i]=1,而在磁盘上的bit[i]=0
- 解决方法:
- set 磁盘中的 bit[i] = 1
- 申请block[i]
- set 内存中的 bit[i] = 1
Linked Free Space List on Disk
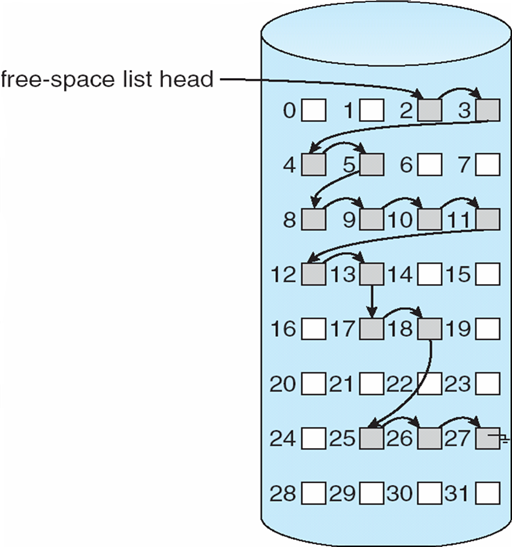
11.6 效率和性能
- 效率依赖于:
- 磁盘分配、目录算法
- 文件中目录项的数据的类型
- 性能:
- disk cache:在内存中开辟一块空间,访问磁盘时先访问这块内存
- free-behind and read-ahead:释放时不真正将内存中的内容刷新,读取时提前将相关的block读入内存
- 通过将部分内存用作虚拟磁盘或RAM磁盘来提高PC性能
11.6.1 Page Cache
- Page Cache使用虚拟内存技术缓存页面而不是磁盘块,
- Memory-mapped I/O会使用Page Cache
- 通过文件系统的例行I/O使用缓冲区(磁盘)缓存
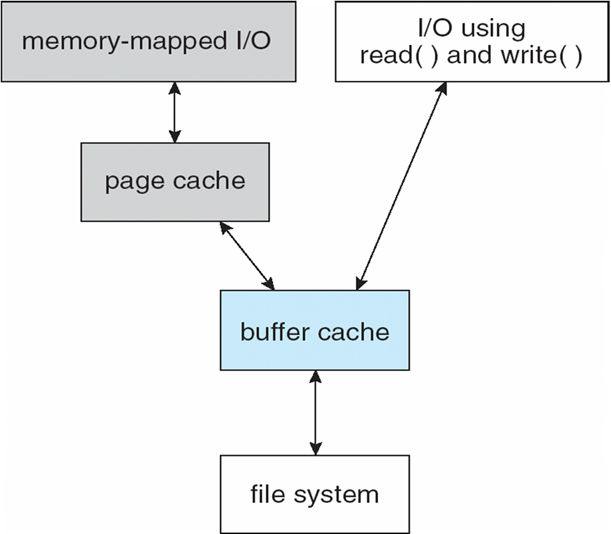
11.6.2 Unified Buffer Cache
- Unified Buffer Cache 统一缓冲区缓存:使用相同的页面缓存来缓存memory-mapped pages 和普通文件系统I/O
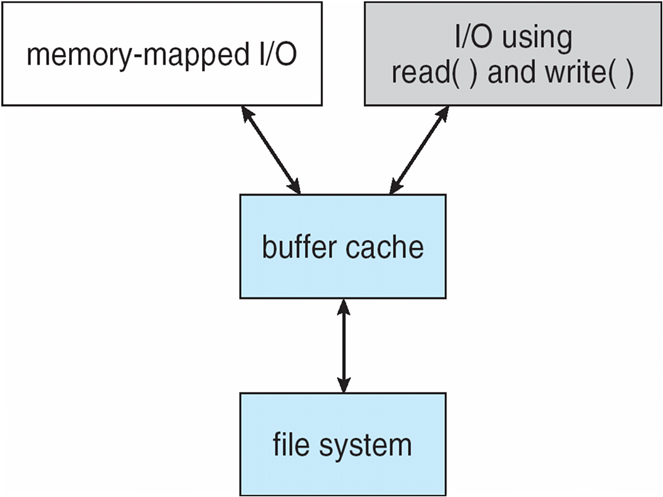
11.7 Recovery
- Consistency checking 一致性比较:将目录结构中的数据与磁盘上的数据块进行比较,并尝试修复不一致性
- back up 备份:使用系统程序将数据从磁盘备份到其他存储设备(磁带、其他磁盘、光盘)
- restoring 恢复:通过从备份中恢复数据来恢复丢失的文件或磁盘
11.7.1 Log Structured File Systems
- Log structured 日志结构(或日志)文件系统:将文件系统的每次更新记录为事务 transaction
- 所有事务都写入日志
- 事务写入日志后即被视为已提交
- 但是,文件系统可能尚未更新
- 日志中的事务将异步写入文件系统
- 修改文件系统时,事务将从日志中删除
- 如果文件系统崩溃,则仍必须执行日志中的所有剩余事务
11.7.2 Network File System (NFS) 网络文件系统
11.7.2.1 NFS
- NFS:跨LAN/WAN访问远程文件的软件系统的实现和规范
- 该实现是使用不可靠数据报协议(UDP/IP协议和以太网)在Sun工作站上运行的Solaris和SunOS操作系统的一部分
- 互连工作站被视为一组具有独立文件系统的独立计算机,允许以透明的方式在这些文件系统之间共享
- 远程目录加载在本地文件系统目录上
- 加载的目录看起来像本地文件系统的一个完整子树,替换了从本地目录向下的子树(mount的过程)
- 装载操作的远程目录的规范是不透明的;必须提供远程目录的主机名
- 然后可以以透明的方式访问远程目录中的文件
- 根据访问权限认证,可能任何文件系统(或文件系统中的目录)都可以远程安装在任何本地目录的顶部
- 远程目录加载在本地文件系统目录上
- NFS旨在在不同机器、操作系统和网络架构的异构环境中运行;独立于这些介质的NFS规范
- 这种独立性是通过使用构建在两个独立于实现的接口之间使用的外部数据表示(External Data Representation XDR)协议之上的RPC原语(RPC primitives)实现的
- NFS规范区分了装载机制提供的服务和实际的远程文件访问服务
11.7.2.2 NFS Mount Protocol
- 在服务器和客户端之间建立初始逻辑连接
- mount操作包括:要装载的远程目录的名称、存储该目录的服务器计算机的名称
- mount请求被映射到相应的RPC,并转发到服务器计算机上运行的装载服务器
- Export list导出列表:指定服务器导出以进行mount的本地文件系统,以及允许mount它们的计算机的名称
- 在符合其导出列表的装载请求之后,服务器返回一个文件句柄:一个用于进一步访问的密钥
- 文件句柄:一个文件系统标识符和一个inode编号,用于标识导出的文件系统中装载的目录
- 装载操作仅更改用户的视图,不会影响服务器端
11.7.2.3 NFS Protocol
- 为远程文件操作提供一组远程过程调用。程序支持以下操作:
- 在目录中搜索文件
- 读取一组目录条目
- 操作链接和目录
- 访问文件属性
- 读取和写入文件
- NFS服务器是无状态stateless:每个请求都必须提供一组完整的参数
- NFS V4刚刚推出,非常不同,有状态
- 修改数据时,必须先修改服务器的磁盘,才能将数据返回客户端
- 保证了同步
- 失去缓存的优势
- NFS协议不提供并发控制机制
11.7.2.4 NFS架构中的三个主要层
- UNIX文件系统接口
- 基于打开、读取、写入和关闭调用以及文件描述符
- 虚拟文件系统(VFS)层:区分本地文件和远程文件,本地文件根据其文件系统类型进一步区分
- VFS根据文件系统类型激活文件系统特定操作以处理本地请求
- 为远程请求调用NFS协议过程
- NFS服务层:体系结构的底层
- 实施NFS协议
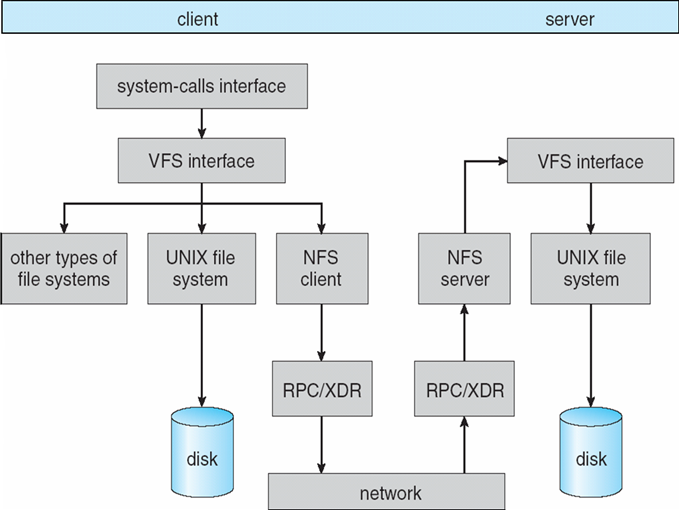
11.7.2.5 NFS Path-Name Translation
- 通过将路径拆分为组件名称并对每对组件名称和目录vnode执行单独的NFS查找调用来执行
- 为了加快查找速度,客户端的目录名查找缓存保存远程目录名的vnode
11.7.2.6 NFS远端操作
- 常规UNIX系统调用与NFS协议RPC之间几乎一一对应(打开和关闭文件除外)
- NFS遵循远程服务范式,但为了性能考虑,采用了缓冲和缓存技术
- 文件块缓存:打开文件时,内核会与远程服务器检查是否获取或重新验证缓存的属性
- 仅当相应的缓存属性是最新的时,才使用缓存文件块
- 文件属性缓存:每当新属性从服务器到达时,都会更新属性缓存
- 在服务器确认数据已写入磁盘之前,客户端不会释放延迟的写入块
*11.8 示例:WAFL文件系统
- 用于Network Appliance“Filers”:分布式文件系统设备
- 在任何位置写入文件布局
- 为NFS、CIFS、http、ftp提供服务
- 随机I/O优化,写优化
- 用于写缓存的NVRAM
- 类似于Berkeley Fast File System,具有广泛的修改
The WAFL File Layout
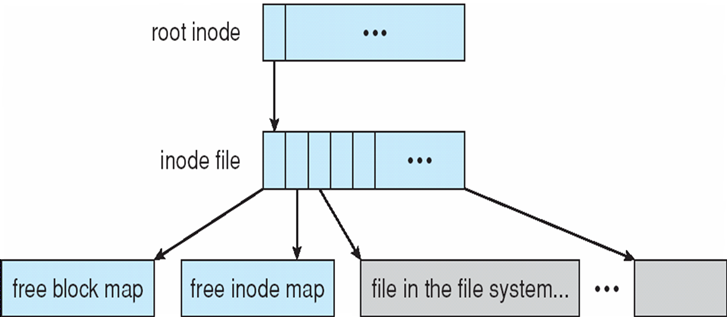
Snapshots in WAFL
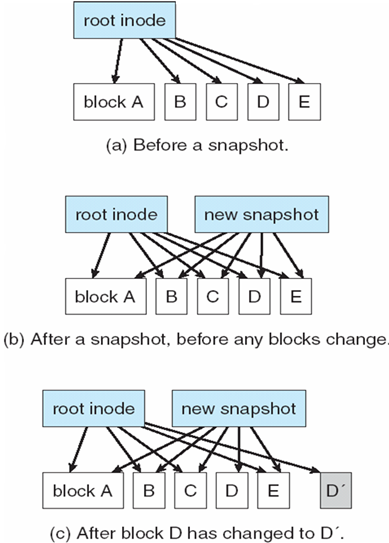
Chapter 12:Mass-Storage Systems
12.1 大容量存储系统 概览
分层存储体系
- 磁盘
Magnetic disks:- 每秒钟60~200转
- 传输速率
Transfer Rate:从驱动器到计算机之间的数据传输速率- 与磁盘、计算机连接驱动的方式有关
- 定位时间
Positioning Time/Random-access time:分为两部分- 将磁盘臂移动到所需柱面的时间(寻道时间
seek time) - 所需扇区在磁盘头下旋转的时间(旋转延迟
rotational latency)
- 将磁盘臂移动到所需柱面的时间(寻道时间
Head Crash:磁头与磁盘相碰,会导致磁盘坏区- 磁盘可以被移除
- 驱动通过I/O总线与计算机相连
- 总线有很多种,如:EIDE, ATA, SATA, USB, Fibre Channel, SCSI
- 计算机中的主机控制器使用总线与内置在驱动器或存储阵列中的磁盘控制器通信
- 固态硬盘
Solid State Drives:- 简称固盘,固态硬盘用固态电子存储芯片阵列制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成
- 第一只SSD出现在1978年(STK 4305,每MB售价8800美元,DRAM)
- 全闪存阵列(AFAS)和混合闪存阵列(HFA)呈爆发式增长
- 现在SSD的容量是15.36TB(SAS)
- 非易失性、低功耗(只有HDD的三分之一)
- 无活动部件、可靠性高:―位误码率(
BER)1x10-17 - 读取存取时间:0.2毫秒,存取时间比HDD大概快 50倍
- 磁带
Magnetic tape:- 出货的磁带驱动器中超过85%是LTO(Linear Tape Open)
- 磁带驱动器的可靠性、数据传输速率和容量已超过磁盘
- 磁带的原生容量为10TB,压缩容量超过25TB。(LTO-10:48TB)
- 磁带的原生数据传输速率为360MB/s
- LTFS(Liner Tape File System)为磁带提供了一种通用、开放的文件系统
- 由于总体拥有成本,云采用磁带解决方案用于归档服务
- 对企业级磁带和LTO而言,磁带介质的寿命至少是30年
12.2 磁盘结构
12.2.1 磁盘结构
- 磁盘被划分为逻辑块的一个一维阵列,其中逻辑块是最小的传输单位
- 逻辑块的大小通常为512字节
- 逻辑块的一维阵列按顺序映射到磁盘的扇区中
- 扇区0:是最外柱面上,第一个磁道的,第一个扇区
- 映射顺序:磁道上的其它扇区 => 柱面上的其它磁道 => 其它柱面
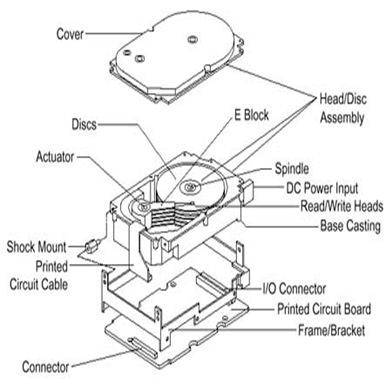 |
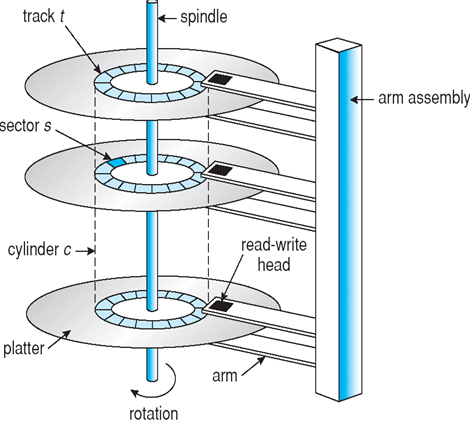 |
|---|
12.2.2 Host-attached storage
主机通过I/O接口与I/O总线进行通信
IDE:- 每个I/O bus 最多2个驱动器
SCSI:- SCSI本身是一条总线,一根电缆上最多有16个设备,SCSI启动器请求操作,SCSI目标执行任务
- 每个目标最多可以有8个逻辑单元(连接到设备控制器的磁盘)
FC:Fibre Channel,光纤通道- 可以是具有24位地址空间的交换结构,这是存储区域网络(SAN, storage area networks)的基础,其中许多主机连接到许多存储单元
- 可仲裁126个设备的环路(FC-AL)
NAS:Network-attached storage- 网络连接存储(NAS)是通过网络而不是通过本地连接(如总线)提供的存储
- NFS和CIFS(通用Internet文件系统)是通用协议
- 通过主机和存储之间的远程过程调用(RPC)实现
- 新的iSCSI协议使用IP网络来承载SCSI协议
SAN:Storage Area Network- 在大型存储环境中很常见(而且越来越常见)
- 多个主机连接到多个存储阵列—灵活
存储虚拟化技术:
SNIA(Storage Networking Industry Association,存储网络联合会)官方对于Virtualization(存储虚拟化技术)的定义如下:- 是将存储(子)系统内部功能与具体应用、主机及通用网络资源分离、隐藏及抽象的行为。以期达到存储或数据管理的网络无关性
- 对于存储服务及设备的虚拟化应用,以期达到整合设备功能、隐藏复杂细节以及向已经存在的底层存储资源添加新的应用
12.4 磁盘调度
12.4.1 磁盘调度
- 操作系统负责有效地使用硬件-对于磁盘驱动器,这意味着具有快速的访问时间和磁盘带宽
- 访问时间有三个主要组成部分
Seek time(寻道时间):是磁盘将磁头移动到包含所需扇区的气缸的时间Rotational latency(旋转延迟):是等待磁盘将所需扇区旋转到磁盘头的额外时间Transfer time(传输时间)
- 目标:最小化寻道时间
- seek time ≈ seek distance 寻道时间 ≈ 寻道距离
- 磁盘带宽:传输的总字节数 / 第一次服务请求和最后一次传输完成之间的总时间
- 7200(转/每分钟)的硬盘,每旋转一周所需时间为60×1000(毫秒)÷7200=8.33毫秒, 则平均旋转延迟时间为8.33÷2=4.17毫秒(平均情况下,需要旋转半圈)。
- 7200转机械硬盘的寻道时间一般为12-14毫秒,固态硬盘可以达到0.1毫秒甚至更低
- 固态硬盘持续读写速度超过500MB/s
- 机械硬盘读写速度超过50~200MB/s(接口不同)
- 磁带的原生数据传输速率为360MB/s
12.4.2 磁盘调度算法
假设
- 请求队列为:
98, 183, 37, 122, 14, 124, 65, 67 - 磁头目前在:
53
12.4.2.1 FCFS 先来先服务
总距离:
640个磁道距离
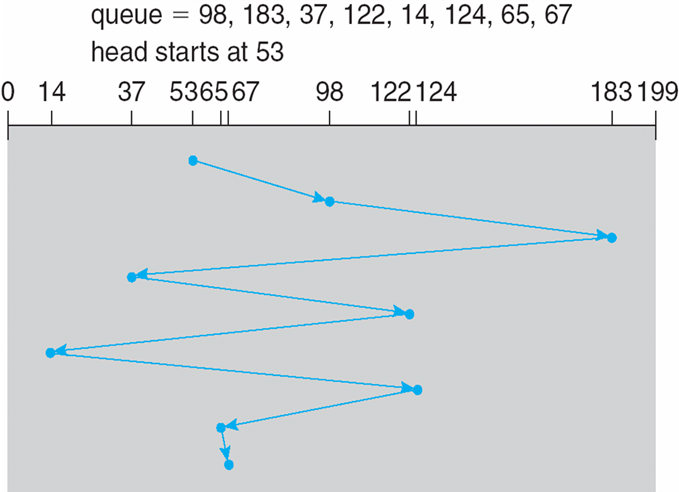
12.4.2.2 SSTF 最短寻道时间优先
- 选择对于当前磁头来说,所需寻道时间最小的请求
- SSTF(Shortest Seek Time First)是SJF的一个变种,可能会导致starvation
总距离:
236个磁道距离
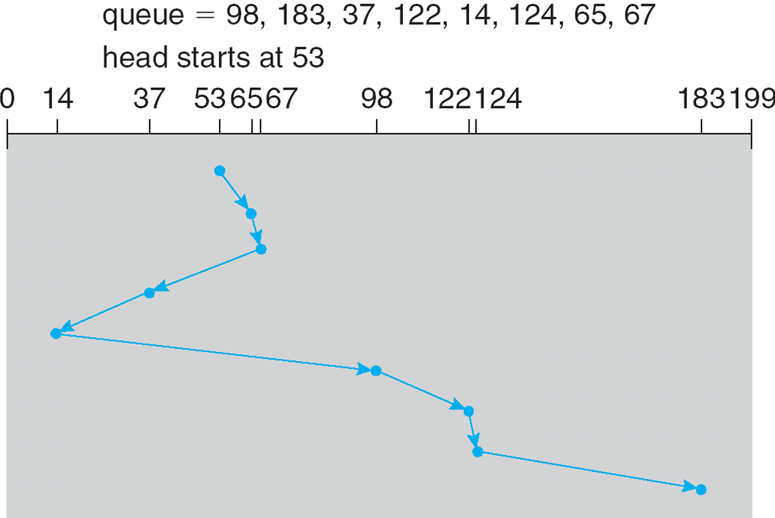
12.4.2.3 SCAN 扫描
- 磁盘臂从磁盘的一端开始,向另一端移动,当遇到请求的块时,直接读取,直到到达磁盘的另一端
- 此时磁头移动方向取反,继续响应途中遇到的请求
- SCAN算法有时称为电梯算法
- SCAN算法的稳定性不高
总距离:
236个磁道距离
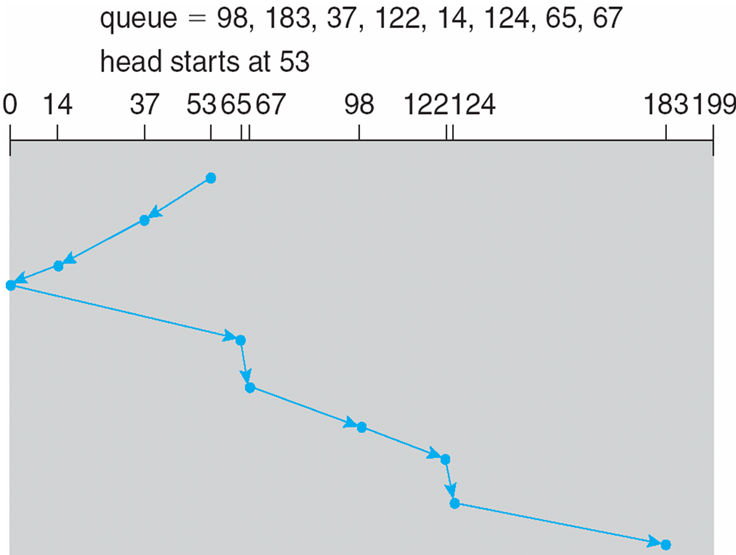
12.4.2.4 C-SCAN
- 磁盘臂从磁盘的一端开始,向另一端移动,当遇到请求的块时,直接读取,直到到达磁盘的另一端
- 此时磁头直接跳转到磁盘的开始端,然后继续向另一端移动
- C-SCAN更加稳定,因为保证了同一时间遇到的请求可以在一次SCAN过程中都取到
总距离:
382个磁道距离
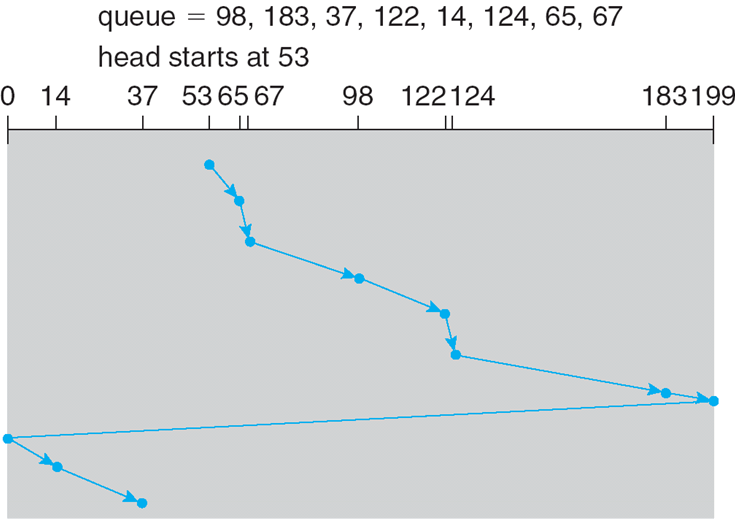
12.4.2.5 LOOK
- SCAN的时候,不一定要到边上,只要到达所有请求的最小/大值处,即可折返
总距离:
208个磁道距离
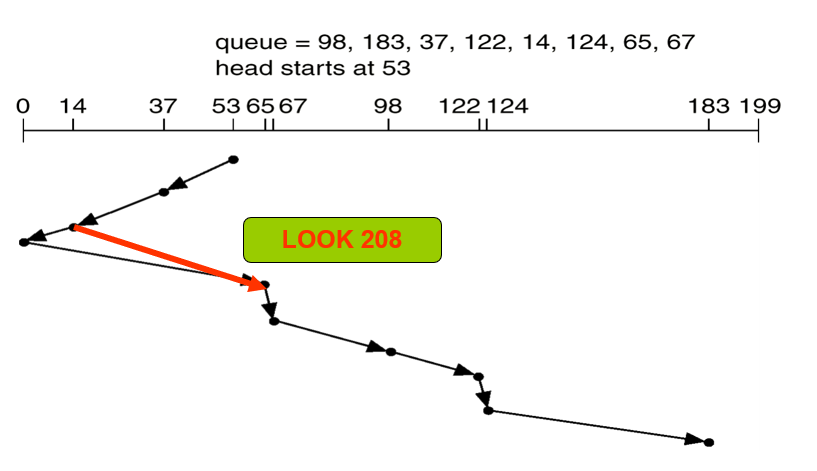
12.4.2.6 C-LOOK
- C-SCAN的时候,不一定要到边上,只要到达所有请求的最小/大值处,即可折返
总距离:
322个磁道距离
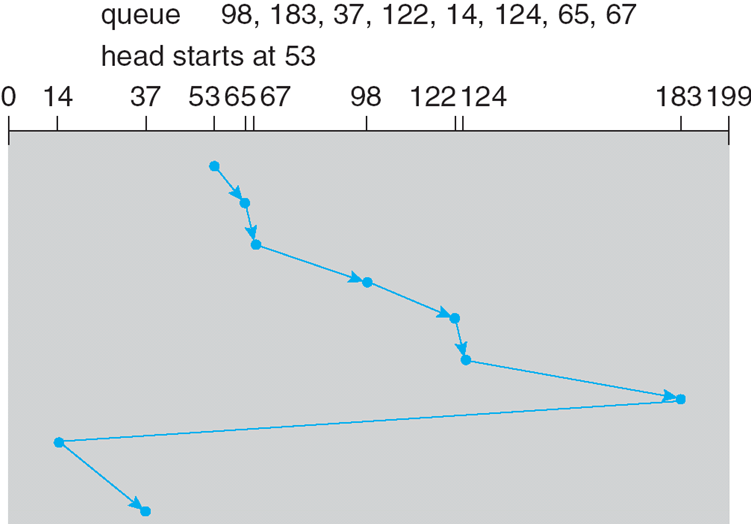
12.4.3 选择一种磁盘调度算法
- SSTF很常见,具有自然吸引力
- SCAN和C-SCAN在磁盘负载较大的系统中表现更好
- 性能取决于请求的数量和类型
- 磁盘服务请求可能会受到文件分配方法的影响
- 磁盘调度算法应作为操作系统的一个单独模块来编写,允许在必要时使用不同的算法来替换
- SSTF或LOOK是一种合理的默认算法
12.5 磁盘控制
12.5.1 磁盘控制
- Low-level formatting / physical formatting 低级格式化/物理格式化:
- 为每个扇区采用特别的数据结构,包括头、数据区域和尾部组成
- 头部和尾部包含了一些磁盘控制器所使用的信息,例如扇区号码和纠错代码(ECC)
- 当控制器在正常I/O时写入一个扇区数据时,ECC会用一个根据磁盘数据计算出来的值更新
- 当读入扇区时,ECC值会重新计算,并与原来存储的值相比较,如果两个值不一样,那么可能表示扇区的数据可能已损坏或扇区可能变坏
- 要使用磁盘保存文件,操作系统仍需要在磁盘上记录自己的数据结构
- Partition分区:
- 一个分区可以用来存储操作系统的可执行代码,而其他分区用来存储用户数据
- 分区可看做一个独立的磁盘
- Logical formatting 逻辑格式化:
- 操作系统将初始的文件系统数据结构存储到磁盘上
- 这些数据结构包括空闲和已分配的空间(FAT和inode)和一个初始为空的目录
- cluster 簇:
- 为了提高效率,大多数操作系统将块集中到一大块,叫做簇cluster
- 磁盘I/O通过块完成,文件系统I/O通过簇完成,确保I/O可以进行更多的顺序存取和更少的随机存取
- Partition分区:
12.5.2 Boot Block 启动块
- Boot block 初始化系统:
- 引导程序(自举程序)初始化系统从cpu寄存器到设备控制器和内存,接着启动操作系统
- 自举程序应找到磁盘上的操作系统内核,装入内存,并转到起始地址,开始操作系统的执行
- 经典的启动顺序
- ROM中的代码(简单引导)
- ROM中保留一个很小的自举加载程序,它的作用是进一步从磁盘上调入更为完整的自举程序
- Boot Block中的代码(完全引导)
- 引导加载程序,例如Grub或LILO
- 磁盘上的自举程序可以容易地进行修改,拥有启动分区的磁盘称为启动磁盘或系统磁盘
- 操作系统的整个内核
- ROM中的代码(简单引导)
12.5.3 Windows 2000的启动
- Windows系统通过运行系统ROM上的代码,开始启动,指示系统从MBR读取引导代码。MBR包含一个硬盘分区列表和一个说明系统引导分区的标志
- 引导分区,boot partition,包含操作系统和设备驱动程序。系统一旦确定引导分区,它读取该分区的第一个扇区,所谓引导扇区,并继续余下的启动过程,包括加载各种子系统和系统服务
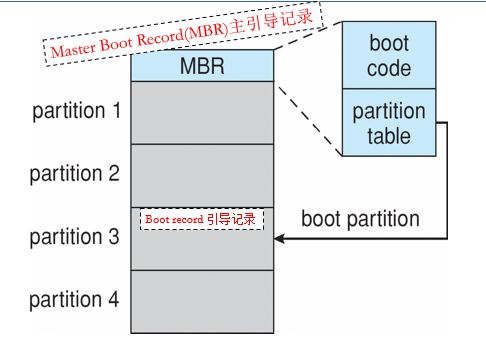
12.5.4 Bad Block 坏块
有坏块是正常的,出厂的时候就有可能有坏块。对于简单磁盘,Format进行逻辑格式化时找到坏块,就在相应的FAT条目上写上特殊值以通知分配程序不要使用该块。如果在正常使用中块变坏,就必须人工的执行chkdsk来搜索坏块。
- 磁盘经常有缺陷块或坏块
- 坏块的处理方法
- MS-DOS的处理方法: format,chkdsk命令
12.6 交换空间的管理
- 交换空间:虚拟内存使用磁盘空间作为主内存的扩展
- 交换空间可以有2种形式:
- 在普通的文件系统中:windows--
pagefile.sys文件 - 在独立的磁盘分区种:linux、unix--
SWAP分区
- 在普通的文件系统中:windows--
- 交换空间的大小:
- 交换空间太大容易造成浪费
- 交换空间太小容易造成死机现象:中断进程或使整个系统死机
- BSD在进程启动时分配交换空间;保存文本段(程序)和数据段
- 内核使用交换映射来跟踪交换空间的使用
- Solaris 2仅在页面被强制移出物理内存时才分配交换空间,而不是在首次创建虚拟内存页面时
Data Structures for Swapping on Linux Systems
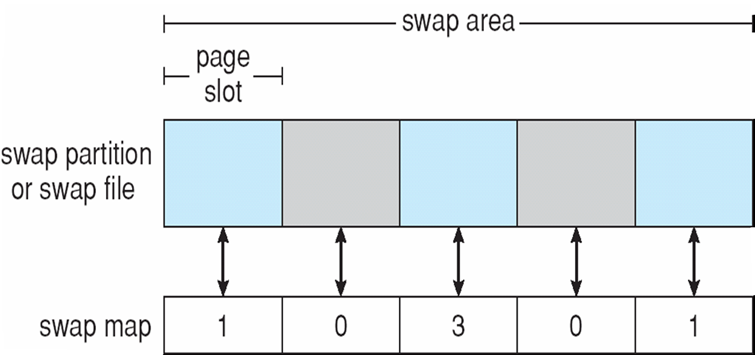
12.7 RAID结构
12.7.1 RAID介绍
- RAID:Redundant Arrays of Inexpensive(Independent)
Disks,冗余廉价磁盘阵列
- RAID是一种把多块独立的硬盘(物理硬盘)按不同的方式组合起来形成一个硬盘组(逻辑硬盘),从而提供比单个硬盘更高的存储性能和提供数据备份技术
- Inexpensive => Independent
- RAID:使用多个磁盘,通过冗余提供可靠性
- 增加平均故障时间
- 通常与NVRAM组合使用,提升性能
- 分为了6个级别
- 磁盘使用技术的一些改进涉及使用多个磁盘协同工作
- 磁盘条带化(striping):将一组磁盘用作一个存储单元
- RAID方案通过存储冗余数据来提高存储系统的性能和可靠性
- 镜像(Mirroring)或shadowing(RAID 1):保留每个磁盘的副本
- 条带化镜像(RAID 1+0)或镜像条带(RAID 0+1):提供了高性能和高可靠性
- 块交错奇偶校验(RAID 4、5、6):使用更少的冗余
- 如果阵列发生故障,存储阵列中的RAID仍可能发生故障,因此阵列之间的数据自动复制很常见
- 通常,少数hot-spare disks不会被分配,自动替换故障磁盘并将数据重建到这些磁盘上
12.7.2 RAID层级
- Raid 0:没有冗余性的保证,但是可以将多个磁盘条带化成1个
- Raid 1:镜像磁盘,是数据的一个完整拷贝
- Raid 2:内存方式的差错纠正代码结构,内存系统中的每个字节都有一个相关奇偶位,以记录字节中置为1的个数是偶数还是奇数
- Raid3:按位校验,奇偶校验码和其它磁盘的相应扇区或块一起用于恢复出错磁盘的扇区和块
- Raid4:按块校验,奇偶校验码和其它磁盘的相应扇区或块一起用于恢复出错磁盘的扇区和块
- Raid5:将数据和奇偶校验分布在所有N+1块磁盘上
- Raid6:保存了额外的冗余信息以防止多个磁盘出错,每4个位的数据使用了2个位的冗余数据,这样系统可以容忍两个磁盘出错。
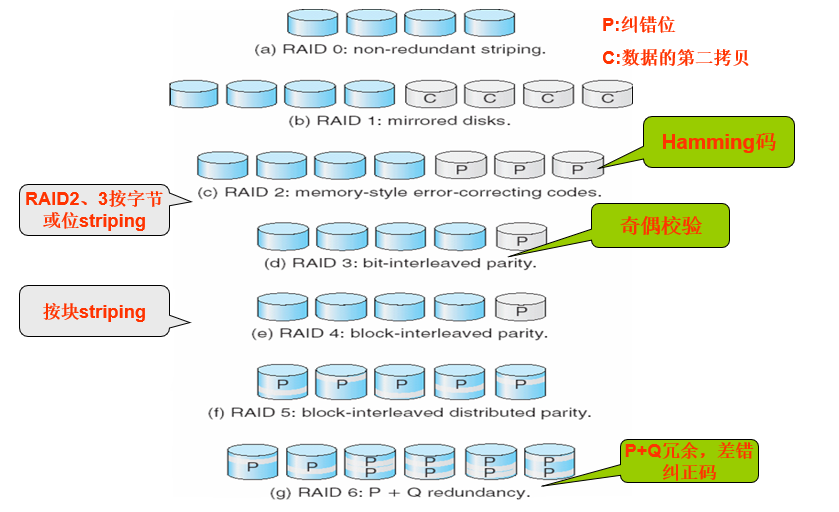
12.7.3 RAID(0+1) 和 RAID(1+0)
- RAID 0+1:
- 先分散,再镜像
- 一组磁盘分散成条,每一条再镜像到另一条
- RAID 0和RAID 1的组合,RAID 0提供性能,RAID 1提供可靠性
- RAID0+1允许坏多个盘,但只能在坏在同一个RAID0中,不允许两个RAID 0都有坏盘
- RAID 1+0:
- 先镜像,再分散
- 如果单个磁盘不可用,其它镜像仍如其它磁盘一样可用
- RAID1+0允许坏多个盘,只要不是一对磁盘坏就可以
- RAID 1+0在整体容错能力和恢复代价上比RAID 0+1更有优势,所以更为常用
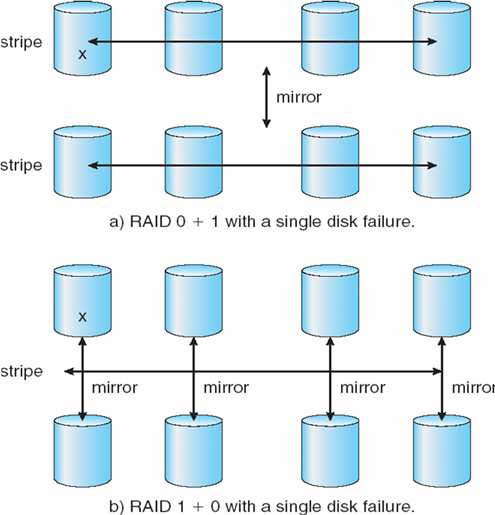
12.7.4 拓展
- 单独使用RAID无法防止或检测数据损坏或其他错误,只是防止磁盘故障
- Solaris ZFS添加了所有数据和元数据的校验和
- 与对象指针一起保存的校验和,用于检测对象是否正确以及是否已更改
- 可以检测并纠正数据和元数据损坏
- ZFS还删除了卷、分区
- 磁盘分配到pool中
- 具有池的文件系统共享该池,使用和释放空间,如“malloc”和“free”内存分配/释放调用
ZFS Checksums All Metadata and Data
Traditional and Pooled Storage
Chapter 13:I/O System
13.1 Overview
- 计算机的两个主要工作
- I/O
- 计算
- 与计算机相连的设备的控制是操作系统设计者的主要关注点
- I/O设备技术出现两个相矛盾的趋势:
- 硬件和软件接口日益增长的标准化
- I/O设备日益增长的多样性。
- 操作系统内核设计成使用设备驱动程序模块的结构
- 设备驱动程序为I/O子系统提供了统一接口
13.2 I/O硬件
- I/O系统的组成:
- PC总线型I/O系统
- 大型机I/O系统
- 通用概念
- Port ,端口
- Bus (daisy chain or shared direct access),总线
- Controller (host adapter),控制器
- I/O instructions控制设备
- 寻址方式
- 直接使用I/O指令
- 内存映射I/O
PC总线型I/O
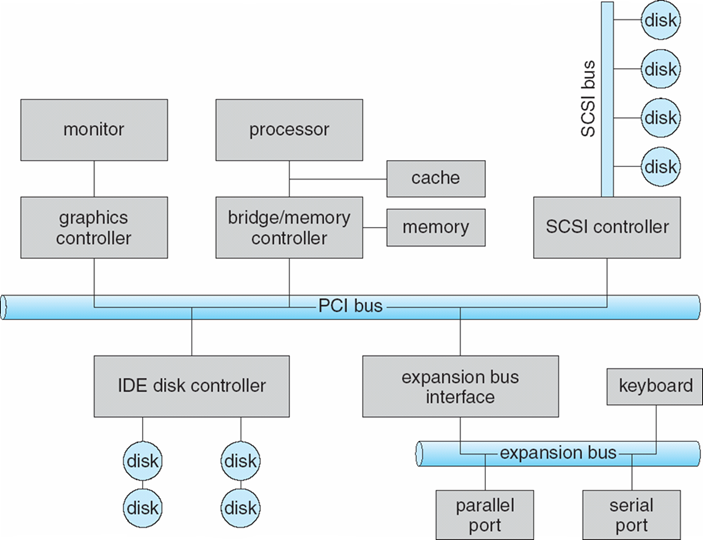
Mainframe Systems 大型机(主机)系统
- 这类计算机以存储器为中心,CPU和各种通道都与存储器相连
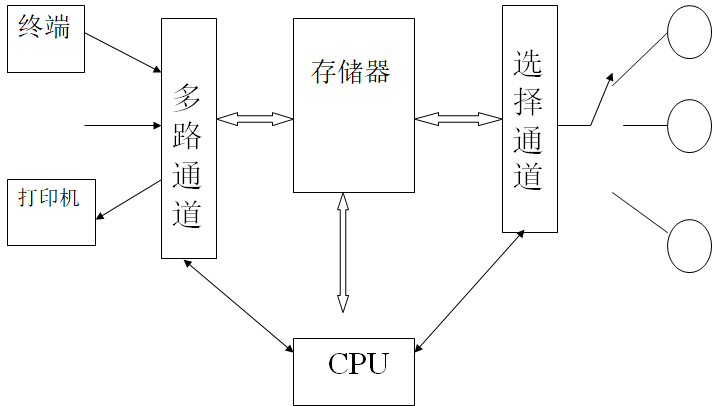
13.3 I/O方式
13.3.1 轮询
- CPU查询I/O的状态
- I/O返回当前状态
- command-ready
- busy
- error
- 如果I/O没有准备好,则会返回第1步,进入busy-wait(忙等待)状态
- 如果I/O准备好了,则CPU读取I/O的数据,写入内存,然后返回第1步
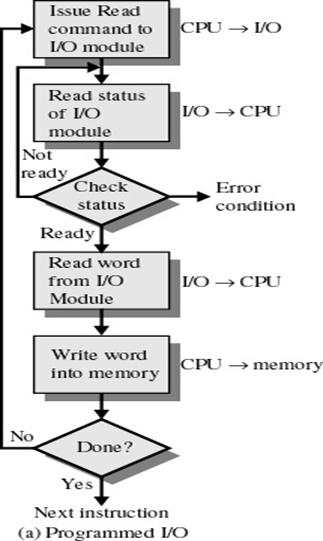
13.3.2 Interrupt中断
- CPU硬件有一条中断请求线(interrupt-request line,
IRL),由I/O设备触发
- 设备控制器通过中断请求线发送信号而引起中断,CPU捕获中断并派遣到中断处理程序,中断处理程序通过处理设备来清除中断。
- 两种中断请求
- 非屏蔽中断:主要用来处理如不可恢复内存错误等事件
- 可屏蔽中断:由CPU在执行关键的不可中断的指令序列前加以屏蔽
- 中断向量
- 中断优先级:能够使CPU延迟处理低优先级中断而不屏蔽所有中断,这也可以让高优先级中断抢占低优先级中断处理。
- 中断的用途
- 中断机制用于处理各种异常,如被零除,访问一个受保护的或不存在的内存地址
- 系统调用的实现需要用到中断(软中断)
- 中断也可以用来管理内核的控制流
中断驱动I/O循环
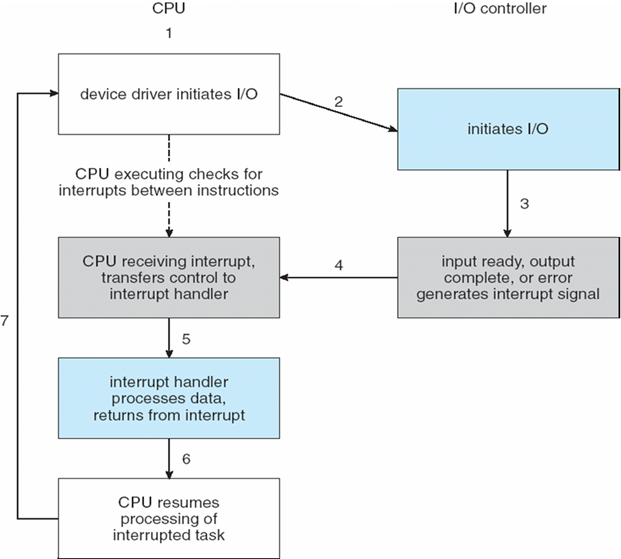
13.3.3 直接内存访问DMA(Direct Memory Access)
- 用来避免处理大量数据移动时按字节来向控制器送入数据的问题
- 需要DMA控制器
- 绕过CPU直接在内存与I/O设备之间进行数据传输
- 步骤:
- 硬件告诉设备驱动器:要传输在地址X处的磁盘数据
- 设备驱动器告诉磁盘控制器:从磁盘中读取地址X处的C个字节到buffer
- 磁盘控制器:初始化DMA传输
- 磁盘控制器:传输字节,给到DMA控制器
- DMA控制器:传输字节给到buffer,地址++,C--,直到C=0
- 当C=0时,DMA中断CPU,声明传输已经结束
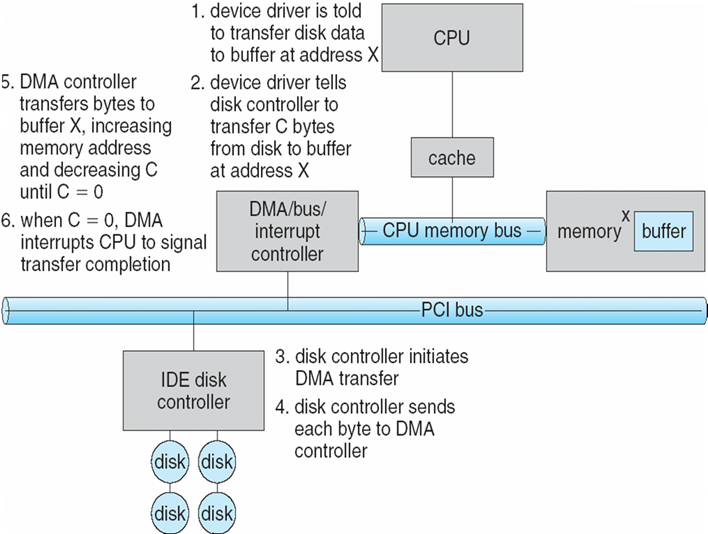
13.4 应用I/O接口
- I/O系统调用:实现统一的I/O接口
- I/O系统调用将设备行为封装在泛型类中,如块设备I/O系统调用包括磁盘、磁带、光盘等一系列块设备的read、write、seek。
- 设备驱动程序(Device-driver)层从内核隐藏I/O控制器之间的差异
- 设备在许多方面都有所不同
- Character-stream or block 字符流或者块设备
- Sequential or random-access 顺序或随机访问设备
- Synchronous or aSynchronous 同步或异步
- Sharable or dedicated 共享或独占设备
- Speed of operation 操作速度(快速、中速、慢速)
- read-write, read only, or write only 读写、只读、只写设备
- 大多数操作系统存在后门,允许应用程序将任何命令透明的传给设备控制器
- 对UNIX,这个系统调用是ioctl()
- 系统调用ioctl能使应用程序访问由设备驱动程序实现的一切功能
- Ioctl有三个参数
- 第一个文件描述符,引用某一个硬件设备
- 第二个是整数,来确定哪个命令
- 第三个是内存中的指针,使得应用程序和控制器传输任何必要的命令信息或数据
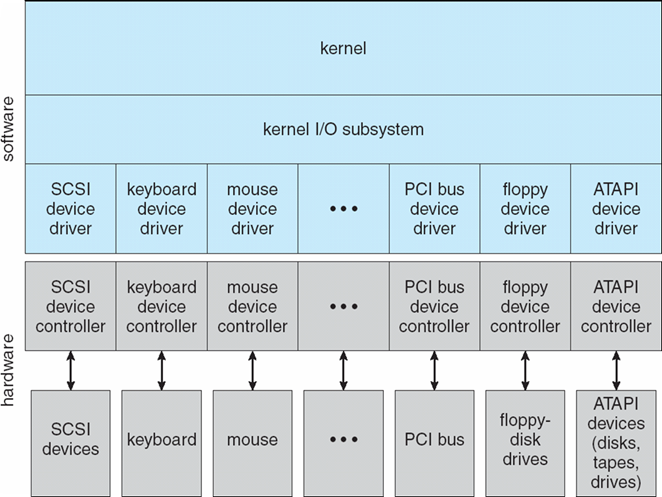
13.4.1 Block and Character Devices 块和字符设备
read,write,seek描述了块存储设备的基本特点,这样应用程序就不必关注这些设备的底层差别。
原始I/O或直接I/O文件操作模式
- 原始I/O:将块设备当做一个简单的线性块数组来访问
- 直接I/O:文件采用禁止缓存和锁的文件操作模式
内存映射文件访问是建立在块设备驱动程序之上的。内存映射接口不是提供read和write操作,而是提供通过内存中的字节数组来访问磁盘存储。
应用程序可以get或put一个字符。在此基础上,可以构造库以提供具有缓冲和编辑功能的按行访问。
这种访问方式也有助于输出设备,例如打印机、声卡,这些设备适合于线性字节流
- Block devices(块设备) include disk drives
- Commands include read, write, seek
- Raw I/O or file-system access
- Memory-mapped file access possible
- Character devices (字符设备) include keyboards, mice, serial ports
- Commands include get(), put()
- Libraries layered on top allow line editing
13.4.2 Network Devices 网络设备
- 网络I/O的性能与访问特点与磁盘I/O相比有很大差别,绝大多数操作系统所提供的网络I/O接口也不同于磁盘的read-write-seek接口
- 许多OS所提供的是网络套接字接口
- 套接字接口还提供了select函数,以管理一组套接字
- 调用select可以得知哪个套接字已有接收数据需要处理,哪个套接字已有空间可以接收数据以便发送
13.4.3 Clocks and Timers 时钟和定时器
- 提供以下三个基本函数
- 获取当前时间
- 获取已经逝去的时间
- 设置定时器以在T时触发操作X
- 测量逝去时间和触发器操作的硬件称为可编程间隔定时器(programmable
interval timer)
- 可被设置为等待一定的时间,然后触发中断
- 也可设置成做一次或重复多次以产生定时中断
13.4.4 Blocking and Nonblocking I/O 阻塞和非阻塞I/O
- Blocking:进程挂起直到I/O完成为止
- 很容易使用和理解
- 对某些需求是低效的
- Nonblocking:I/O调用立刻返回
- 用户界面
- 通过多进程实现
- 返回读/写了多少个字节
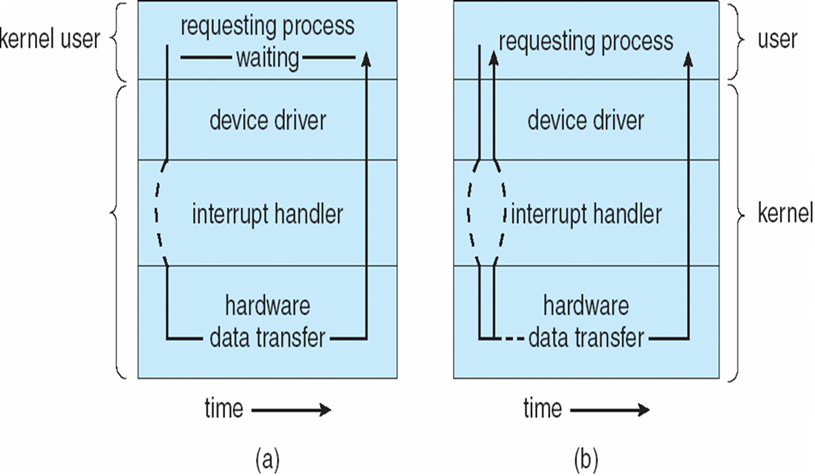
13.4.5 Asynchronous 异步
- Asynchronous(异步):进程与I/O同时运行
- 难以使用
- 当I/O完成时,I/O子系统会提醒进程
- 非阻塞与异步系统调用的差别:
- 非阻塞read调用会马上返回,其所读取的数据可以等于或少于所要求的,或为零
- 异步read调用所要求的传输应完整地执行,其具体执行可以是将来某个特定时间
13.5 内核I/O子系统
- 内核与I/O有关服务:
- I/O scheduling:I/O调度
- buffering:缓存
- caching:高速缓存
- spooling:假脱机
- device reservation:设备预定
- error handling:错误处理
- 内核I/O子系统负责:
- 文件和设备命名空间的管理
- 文件和设备访问控制
- 操作控制(for example, a modem cannot seek())
- 文件系统空间的分配
- 设备分配
- 缓冲、高速缓存、假脱机
- I/O调度
- 设备状态监控、错误处理、失败恢复
- 设备驱动程序的配置和初始化
13.5.1 I/O调度
- I/O调度:调度一组I/O请求就是确定一个好的顺序来执行这些请求
- 某些I/O需要按设备队列的顺序:先来先服务
- 某些操作系统尝试着公平:优先级高者优先
- 磁盘I/O调度
- 实现
- OS通过为每个设备维护一个请求队列来实现调度。
- 可以试图公平,也可以根据不同的优先级进行I/O调度。
- 其他方法:缓冲、高速缓冲、假脱机
13.5.2 缓冲buffer
拷贝语义:
- 某应用程序需要将缓冲区内的数据写入磁盘,它可以调用write()系统调用
- 当系统调用返回时,如果应用程序改变了缓冲区的内容,根据拷贝语义,操作系统保证要写入磁盘的数据就是write()系统调用发生时的版本
- 一个简单方法就是操作系统在write()系统调用返回前,将应用程序缓冲区复制到内核缓冲区中
- 缓冲 Buffering:用来保存在两设备之间或在设备和应用程序之间所传输数据的内存区域。
- 缓冲作用:
- 解决设备速度不匹配
- 解决设备传输块的大小不匹配
- 为了维持拷贝语义“copy semantics”要求
- 缓冲区管理:为了解决CPU与I/O之间速度不匹配的矛盾,在它们之间配置了缓冲区。这样设备管理程序又要负责管理缓冲区的建立、分配和释放。
- 单缓冲、双缓冲、多缓冲、缓冲池
13.5.3 高速缓冲cacheing
高速缓存 Caching :fast memory holding copy of data
缓冲与高速缓存的差别是缓冲只是保留数据仅有的一个现存拷贝,而高速缓存只是提供了一个驻留在其他地方的数据的一个高速拷贝
高速缓存和缓冲是两个不同的功能,但有时一块内存区域也可以同时用于两个目的
当内核接收到I/O请求时,内核首先检查高速缓存以确定相应文件的内容是否在内存中。如果是,物理磁盘I/O就可以避免或延迟
13.5.4 假脱机技术 SPOOLing
- SPOOLing(Simultaneous Peripheral Operation On
Line)称为假脱机技术:
- 用来保存设备输出的缓冲,这些设备如打印机不能接收交叉的数据流
- 操作系统通过截取对打印机的输出来解决这一问题。应用程序的输出先是假脱机到一个独立的磁盘文件上。当其它应用程序完成打印时,假脱机系统将相应的待送打印机的假脱机文件进行排队
- Printing:打印机虽然是独享设备,通过SPOOLing技术,可以将它改造为一台可供多个用户共享的设备
13.5.5 设备预定 Device reservation
- 设备预定 Device reservation
- 提供对设备的独占访问
- 分配和再分配的系统调用
- 有可能产生死锁
13.5.6 错误处理 Error Handling
- 错误处理 Error Handling
- 操作系统可以恢复磁盘读,设备无效,暂时的失败
- 当I/O失败时,大多数返回一个错误码
- 系统日志记录了出错报告
13.5.7 I/O保护
- 用户进程可能通过非法的I/O指令,来恶意打破一些正常操作
- 所有I/O指令被特权化
- I/O必须通过系统调用
- 内存映射和I/O端口内存位置也必须受到保护
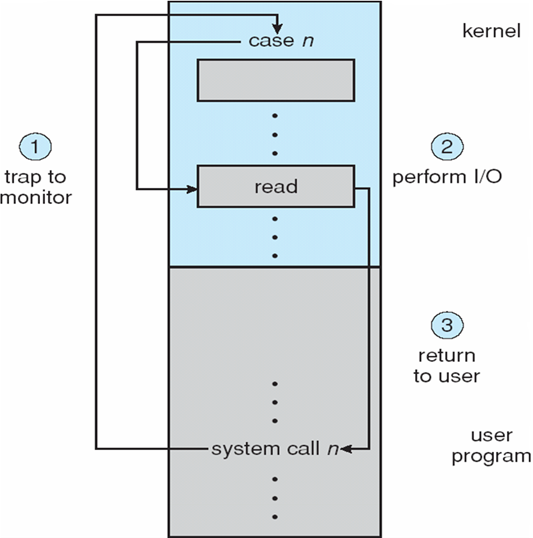
13.5.8 内核数据结构
- 内核需要保存I/O组件使用的状态信息,包括打开文件表,网络连接,字符设备状态等
- 许多复杂的数据结构用来跟踪缓冲,内存分配,及“脏”块
- 某些OS用面向对象的方法和消息传递的方法来实现I/O
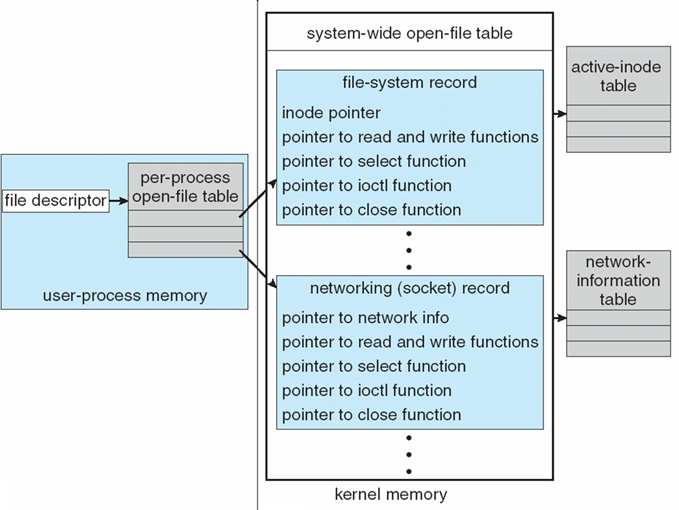
13.6 I/O Requests to Hardware Operations
进程从磁盘中读取一个文件:
- 确定保存文件的设备
- 转换名字到设备的表示法
- 把数据从磁盘读到缓冲区中
- 通知请求进程数据现在是有效的
- 把控制权返回给进程
一次I/O请求的生命周期
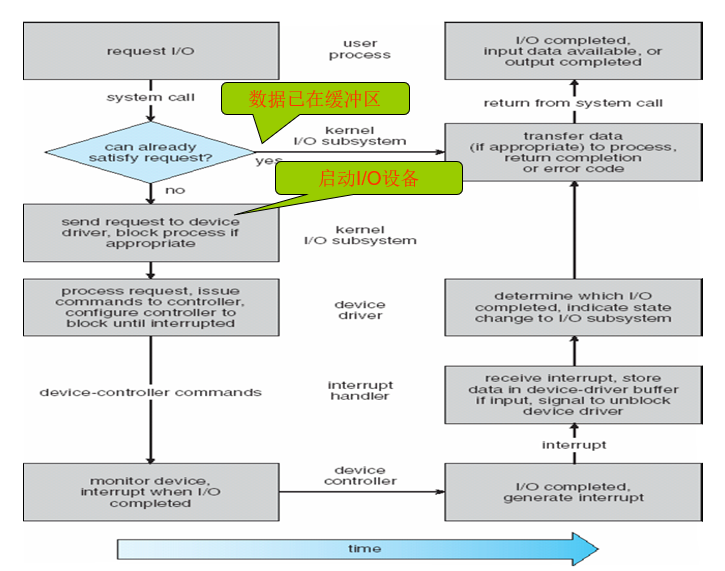
13.7 STREAMS
- STREAMS:Unix System V及更高版本中用户级进程与设备之间的全双工通信信道
- 流包括:
- STREAM头与用户进程接口
- 驱动端与设备接口——它们之间没有或多个STREAM模块。
- 每个模块包含一个读队列和一个写队列
- 消息传递用于队列之间的通信
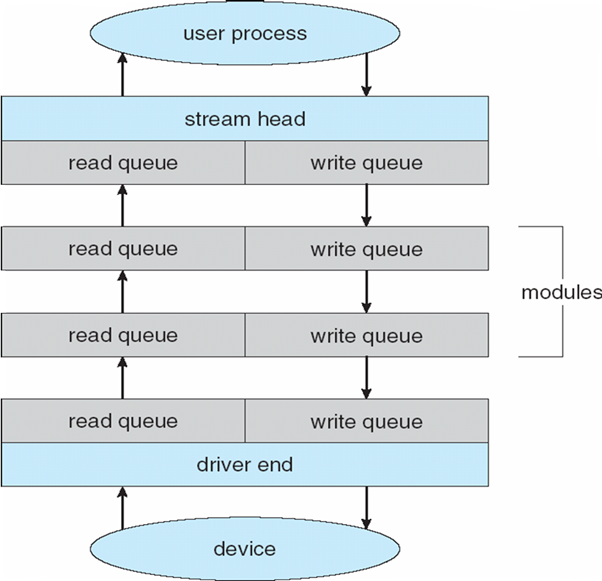
13.8 性能
- I/O是系统性能的一个主要因素:
- 要求CPU执行设备驱动程序、内核I/O代码
- 中断导致的上下文切换
- 数据复制
- 网络流量尤其紧张
- 提高性能的方法:
- 减少上下文开关的数量
- 减少数据拷贝
- 通过使用大型传输、智能控制器和轮询减少中断
- 使用DMA
- 平衡CPU、内存、总线和I/O性能,实现最高吞吐量
计算机之间的通信