多媒体技术
一、多媒体介绍
1.1 什么是多媒体
- 用于同时采集、处理、编辑、存储、表示两种及以上媒体类型的技术
- 一种能够创造、表示、处理、存储多种模态 信息的机器
Perception Medium:感知媒介
- 用于数据的采集和输入
- 如:麦克风、摄像头
Representation Medium:表示媒介
- 高效的将数据从一个地方传到另一个地方
- 如:网络、编码
Presentation Medium:展示媒介
- 将电信号转化为可以感知的信号
- 如:音响
Storage Medium:存储媒介
- 如:光盘、硬盘
Transition Medium:传输媒介
1.2 结构化数据
对于某个特定数据,计算机可以明确、快速的找到该数据的语义
- 非结构化数据:视频、音频、文本
- 结构化数据:关系型数据库
多媒体的任务:将非结构化的数据转化为结构化数据,让计算机能够处理
二、图形和图像数据表示
2.1 基础图像类型
2.1.1 1-bit 二值图像
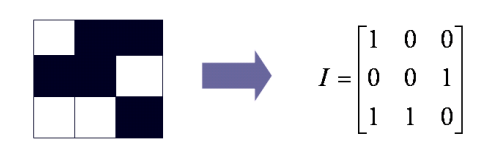
- 包含多个像素
- 每个像素存储1-bit:0--black,1--white
- 1表示有光照,因此是白的
- 图像的大小:
- 设分辨率为640×480,则大小为:640×480/8 = 38.4KB
- 用途:
- 存储简单图形、文本图像
2.1.2 8-bit 灰度图像
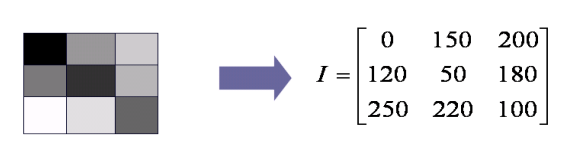
- 每个像素存储1-Byte = 0bit:有0~255共256个灰度等级
- 256表示白色
- 整个像素可以视为一个像素值的二维矩阵,被称为bitmap
- 8-bit灰度图像也可以视为8个1-bit图像的加权叠加
- 图像的大小:
- 设分辨率为640×480,则大小为:640×480 = 307,200 B
2.1.3 将一个8-bit图像用一个1-bit打印机打印出来
DPI:Dot per inch
- DPI越高,代表打印机的质量越好
1-bit打印机打印8-bit图像,本质上是用空间上的密度换取视觉上的感受
- 抖动算法Dithering:用多个点替代原本的每一个像素
- 如果每个像素用N×N个点替代,则最多表示0~N2的灰度等级
- 打印机的驱动程序:将8-bit灰度图像,通过抖动算法,转换为一个更大的二值图像
抖动矩阵:
- 将当前像素点的灰度值与抖动矩阵比较,如果抖动矩阵当前位的值 > 灰度值,则打印为黑色,否则打印为白色
- 不同硬件厂商,驱动中固化的抖动矩阵不同
- 对每一个像素,均通过抖动矩阵进行转化,从而可以得出一个更大的二值图像
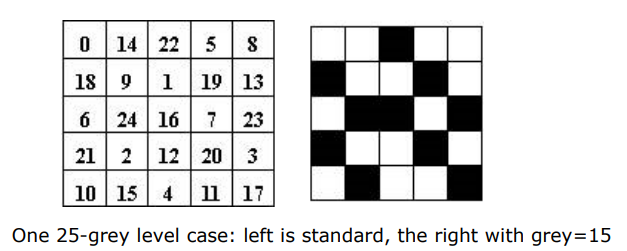
示例:


2.1.4 24-Bit 真彩色图像
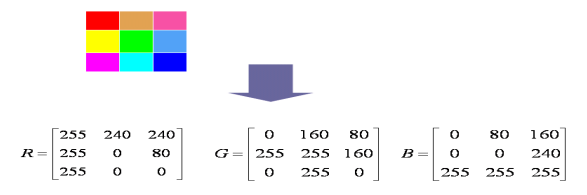
- 每个像素分为三个通道RGB,每个通道取值范围为0~255
- 颜色种类数:256×255×256
- 32-Bit图像多了一个alpha通道,表示透明度,用于特效设计
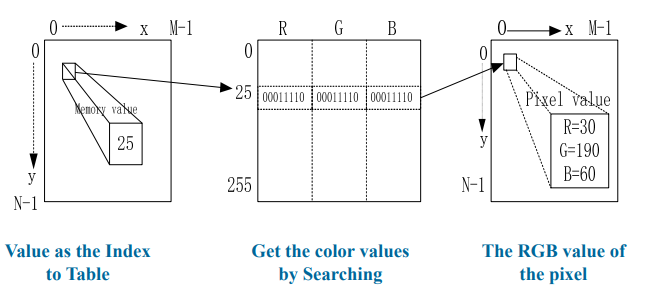
2.1.5 8-Bit 彩色图像:256色彩色图像

- 将8-Bit彩色图像,显示到RGB显示器中:颜色查找表Color Lookup
Table
- 每个像素存储的是颜色查找表中的索引
- 显示器显示该像素时,根据索引查找颜色查找表,然后显示表中对应项的RGB值
- 将24-bit彩色图像转化为8-bit彩色图像,一定会失真
- 不同算法,选出来的256种颜色不同
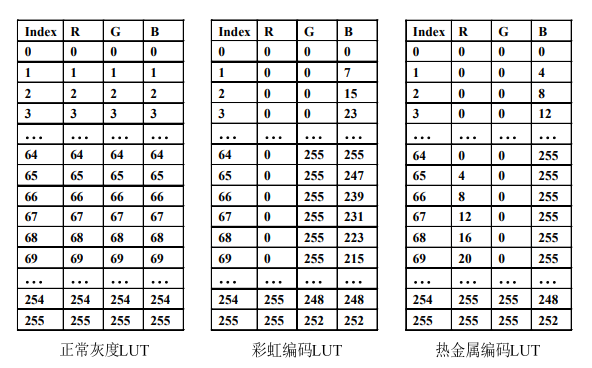
2.1.6 颜色查找表 Color Lookup Table
优点:只需要将颜色查找表替换,就能更改显示风格
用途:医学图像
2.1.7 设计颜色查找表
- 本质上是做一个聚类Clustering
- 将原本256×256×256个颜色,集合为256种颜色
2.1.7.1 示例:3-bit R,3-bit G,2-bit B


2.1.7.2 颜色直方图
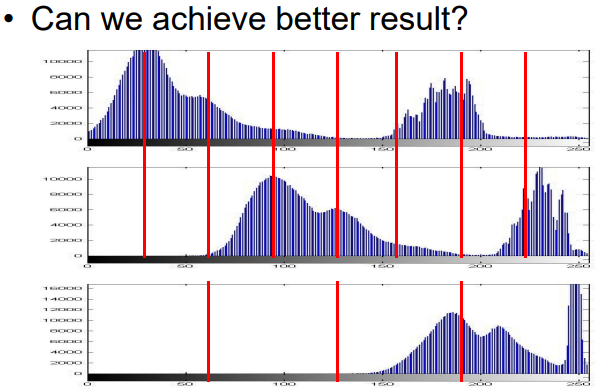
- 将一张图像,按照R、G、B通道分别统计每个值出现的频率
- 优化方法:让最后划分出来的256个桶中,像素个数基本相同
2.1.7.3 Median-cut:中值切分
- 每一次分割:将颜色直方图切分为两个部分,要求两个部分的离散积分(包含的像素点)相同
- 首先,根据图像的R值统计,然后进行分割
- 然后,根据上一次分割的情况,对每一个组,再次根据G值统计,然后进行分割
- 继续下去,按顺序总计进行了8次分割:RGBRGBRG
- 对每一个桶中的像素,取平均,即为颜色查找表中的颜色
2.2 场景图像文件格式
- 格式:图像的存储方式
2.2.1 GIF
- 一般情况下,使用8-bit彩色图像
- 通常经过了压缩

2.2.2 JPEG:Joint Photographic Experts Group
- JPEG一般均为压缩过的,在尽可能保存原有图像的质量下,最大化压缩比
- 也支持无损图像的存储
2.2.3 BMP:Windows的图像格式

- Original data without compression, most popular
- Run Length Encoding:Used for 8-bits image(256 colors)BI-RLE8
- RLE:used for 4-bits image (16 colors) BI_RLE4
三、图像和视频中的颜色
3.1 颜色科学
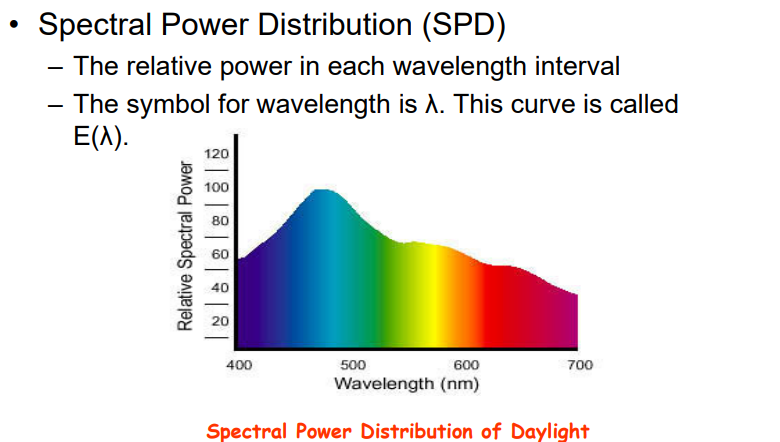
3.1.1 光与光谱 Light and Spectra
3.1.1.1 光是一种电磁波,其颜色以波长为特征
- 激光:单一波长
- 大多数光源:许多波长
- 短波–蓝色,长波–红色
- 可见光范围:400-700nm
3.1.1.2 不同波长的光,携带的能量不同:E(λ)
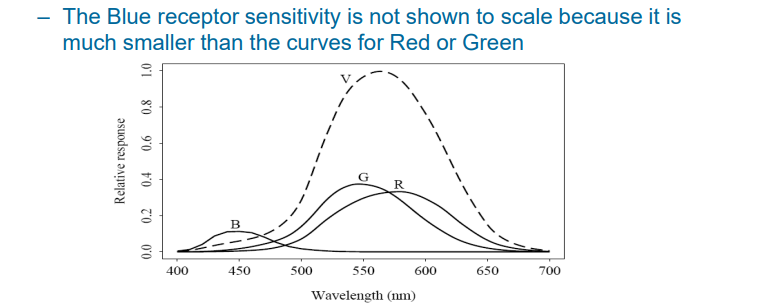
3.1.1.3 人的视觉
柱状细胞:只对明暗产生响应
锥体细胞:只对RGB三种颜色中的一种产生响应,对三种颜色的感知细胞数量不同
- R : G : B = 40 : 20 : 1
对不同波长的光,人眼的敏感度不同:Luminous-efficiency function
- \(q(λ)=(q_R(λ),q_G(λ),q_B(λ))^T\)
\(C(λ)=E(λ)S(λ)\):颜色信号
- \(E(λ)\):光源强度
- \(S(λ)\):反射率
颜色模型函数:
- \(R=\int E(λ)S(λ)q_R(λ)\ dλ\)
- \(G=\int E(λ)S(λ)q_G(λ)\ dλ\)
- \(B=\int E(λ)S(λ)q_B(λ)\ dλ\)
3.1.2 Gamma矫正
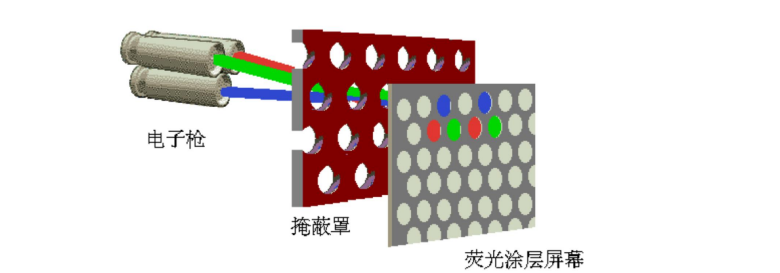
3.1.2.1 CRT显示原理
将RGB的数值转化为电压,通过电子轰击荧光涂层屏幕,使屏幕发光
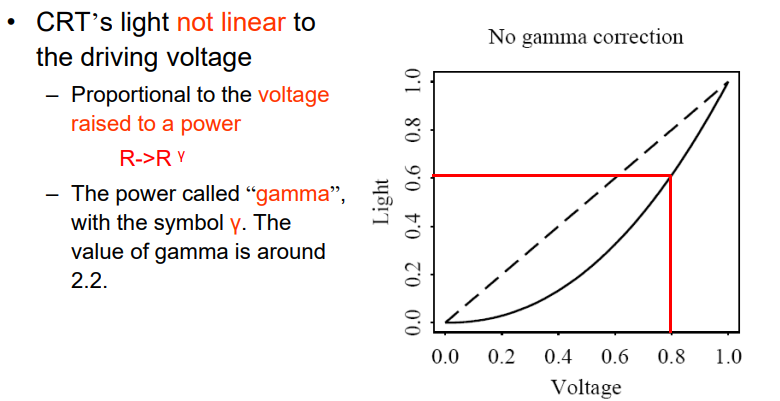
CRT发出的光,与输入的电压值,并不是线性关系的
- CRT发出的光的强度与升高的电压成比例:\(R=>R^γ\)
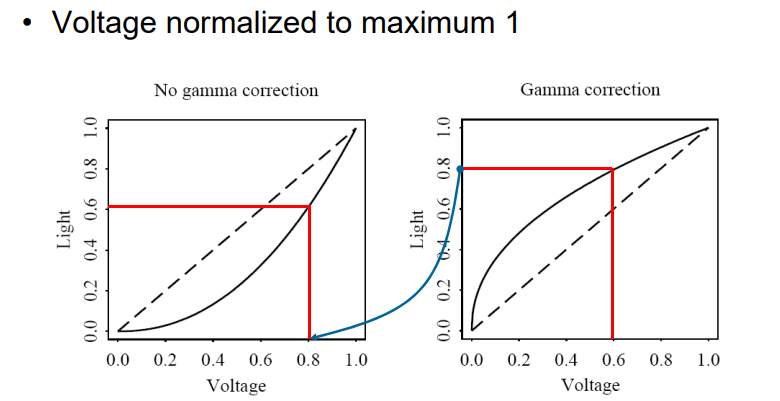
Gamma矫正:将期望的信号,首先进行一次放大,然后再输入给硬件
- \(R=>(R'=R^\frac{1}{γ})=>(R')^γ=>R\)
- \(\frac{1}{γ}\)通常为\(2.2\)
3.1.3 颜色匹配函数
测量出的颜色匹配函数:
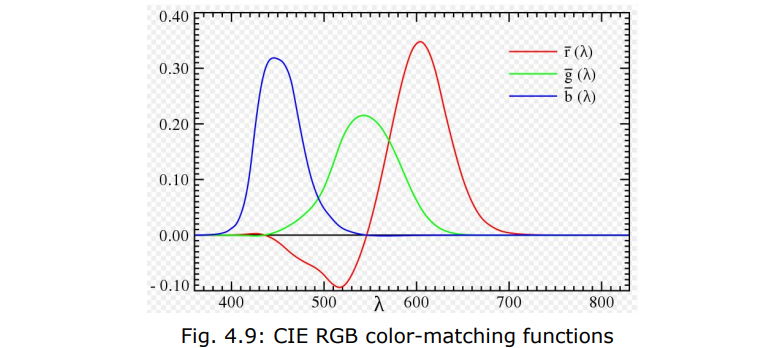
通过线性变换,将所有值映射为正数
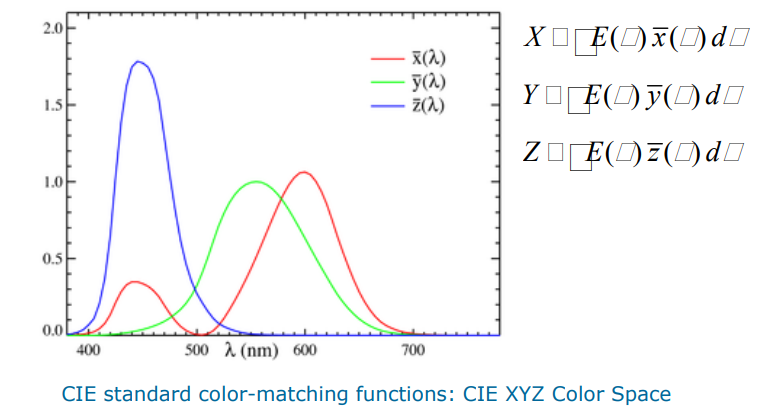
XYZ => RGB

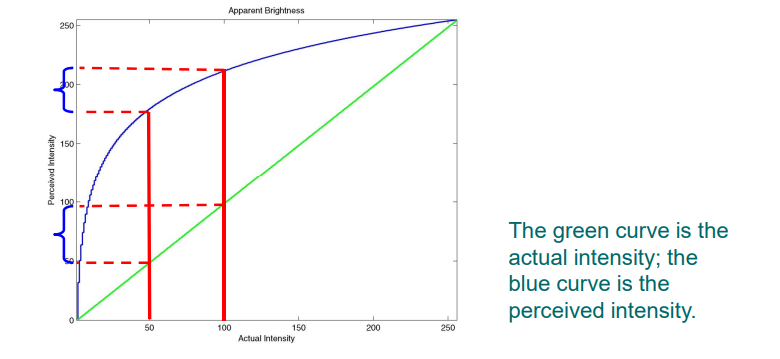
亮度敏感度:
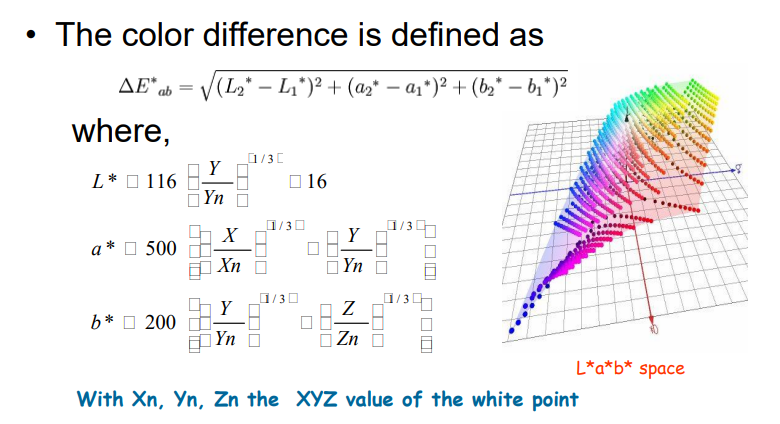
3.1.4 L * a * b * (CIELAB) 颜色模型
3.1.4.1 韦伯定律
- 人感受到的变化,是变化率,而不是绝对值
- 人的视觉系统,对于明暗变化的敏感度,远大于对于颜色变化的敏感度
3.1.4.2 L * a * b * 颜色模型:保证值的变化与人感知的变化相同
相当于进行了一次线性变换
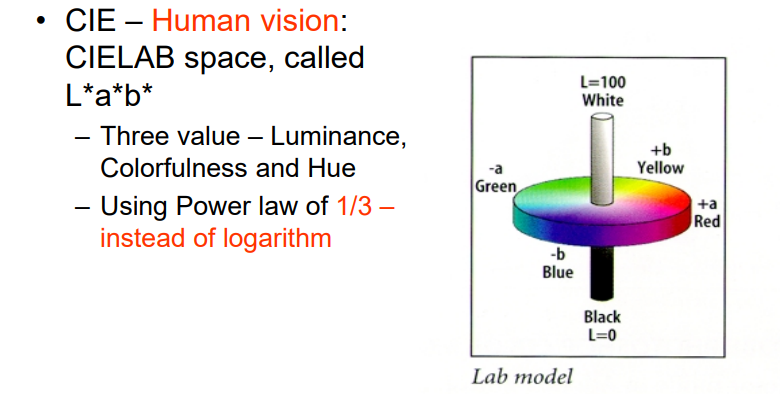
3.1.4.3 其他颜色模型:人脑--LHS
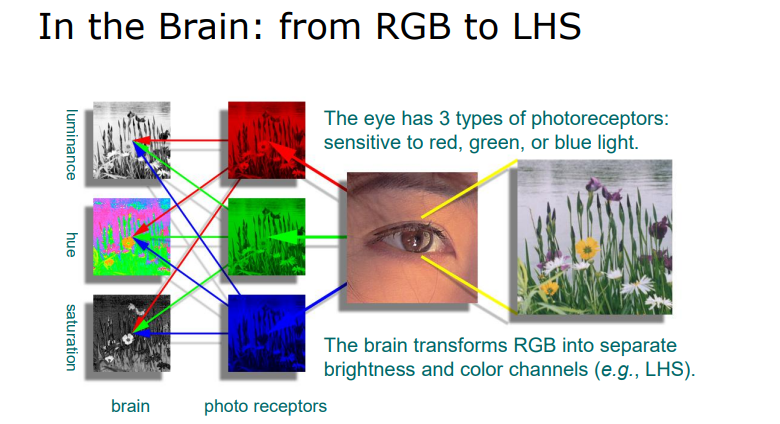
3.2 图像中的颜色模型
3.2.1 CRT显示:RGB
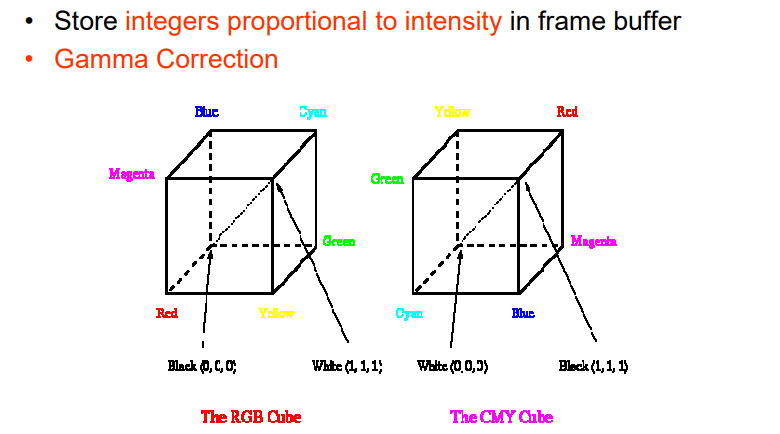
3.2.2 打印机:CMY(K)
- 打印机会使用四个墨盒
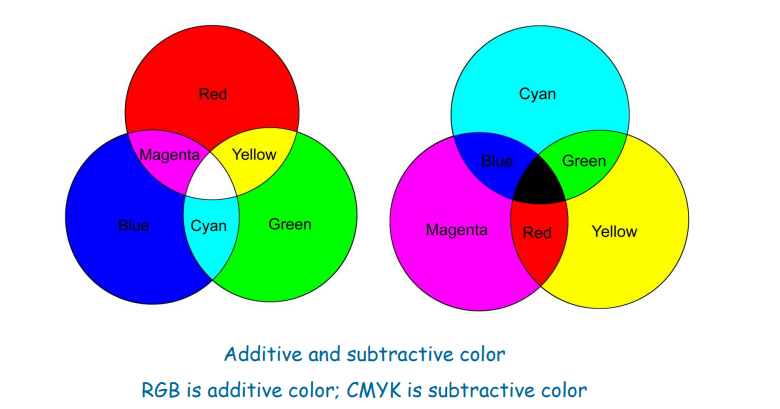

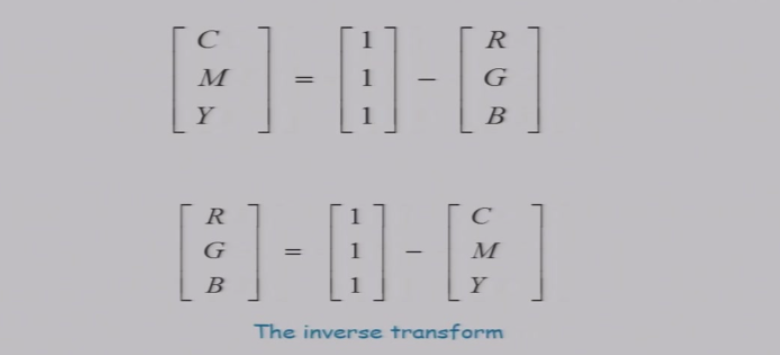
3.2.3 RGB <=> CMY
3.3 视频中的颜色模型
YUV、YIQ、YCbCr模型
- Y:灰度
- 另外两层是对颜色的划分
- 由于人眼对明暗的敏感性远大于色彩,因此在压缩过程中,灰度是不会改变的
3.3.1 YUV颜色模型


3.3.2 YIQ颜色模型

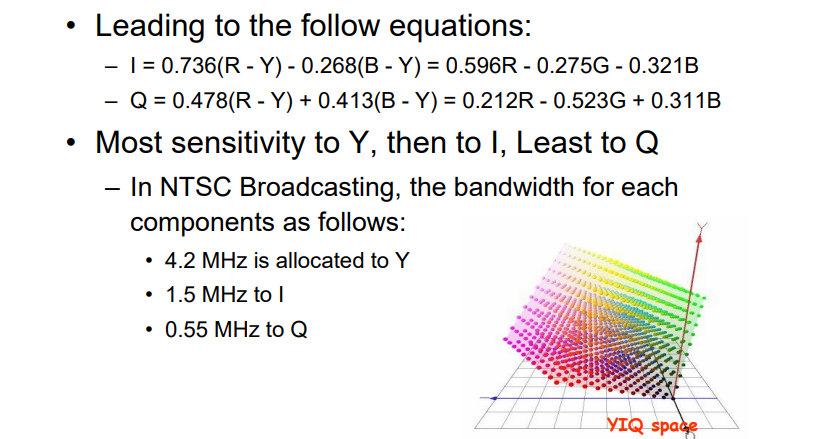
3.3.3 YCbCr颜色模型
JPEG图像,MPEG视频

四、视频基础概念
4.1 视频信号类别
- Component Video:分量视频
- Composite Video:复合视频
- S-Video:介于两者之间
4.1.1 分量视频

- 三根线,每根线负责传输RGB其中一个通道的视频信号
- 优点:RGB三个通道互不干扰,传输信号质量高、带宽大
- 干扰:crosstalk
- 也可以传输YIQ、YUV等其他模型的信号
- Luminance-chrominance transformation from RGB:RGB亮度色度变换
- 只能由彩色电视使用
4.1.2 复合视频

- 机顶盒:对数据进行解压,然后将数据送往电视机
- 将所有的信号,调制到一根电缆上传输
- 更多使用YIQ、YUV等模型
- 要进行数据的压缩
- Y用低频信号调制,UV/IQ用高频信号调制,然后再调制到一个通道上
- 天然与黑白电视兼容
- 可以在解码时只取Y通道
- 缺点:三个信号之间会存在一定的干扰

4.1.3 S-Video

- 4个引脚
- 1~2:接地
- 3:传输Y信号
- 4:传输颜色信号

4.2 模拟视频制式(与硬件有关)
4.2.1 相关概念
模拟信号是连续的,数字信号是离散的
- 连续:在任何时间,均有对应取值
- 离散:只有在采样点处,才有对应取值
模拟信号 Analog signal:f(t),随时间变化的图像
CRT显示器(至少85Hz,每秒至少扫85帧)
- 逐行扫描:从第一行开始,一行一行扫描
- 隔行扫描:从第一行开始,先扫1357...,再扫2468....
- 奇数线扫描出的是奇数场图像,偶数线扫描出的是偶数场图像
- 扫描线是斜线,但斜度较小
- field:场
- 水平回溯时间:上一条扫描线Q=>下一条扫描线R
- 垂直回溯时间:上一次扫描U=>下一次扫描V
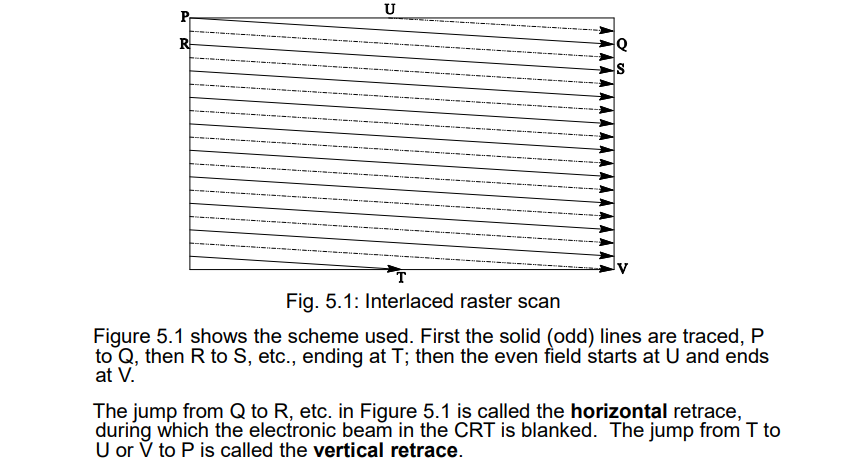
电视机=>隔行扫描,显示器=>逐行扫描
示例:
模拟电视的电视信号制式:
- NTSC:正交平衡调幅
- USA, Canada, Japan and Korea,1953 by USA
- PAL:逐行倒相正交平衡调幅
- Germany, England and China, 1962 by Germany
- SECAM:顺序传送彩色与存储
- France, Russia,1966 by France
- NTSC:正交平衡调幅
均可以同时兼容黑白、彩色,明暗度也会单独传输
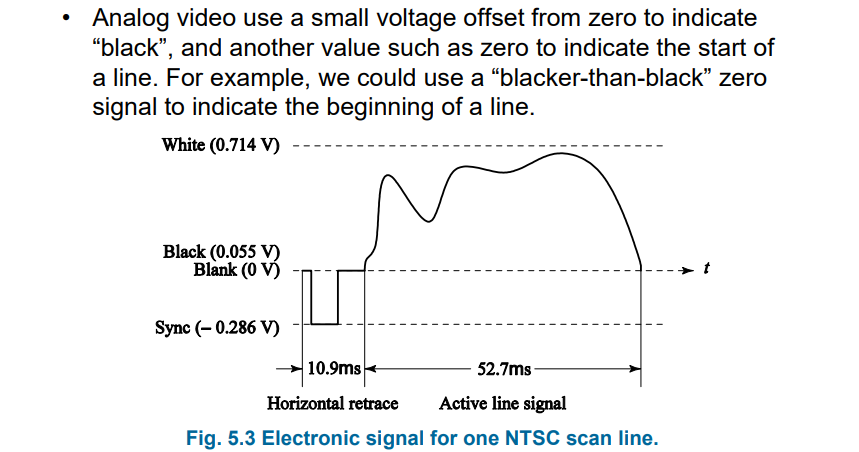
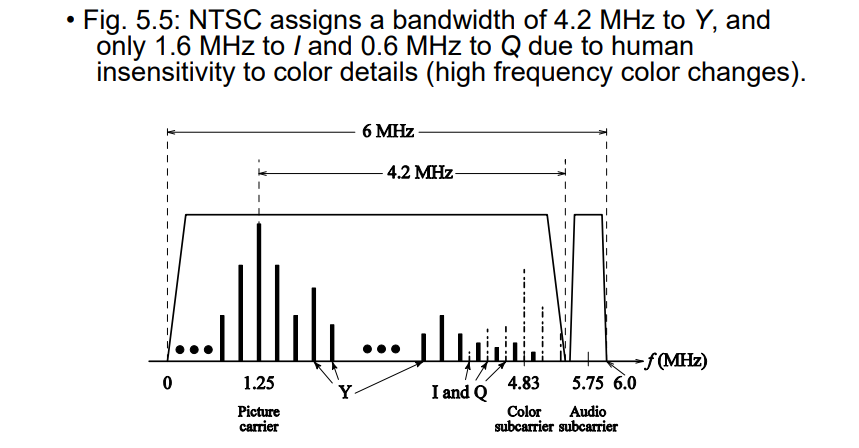
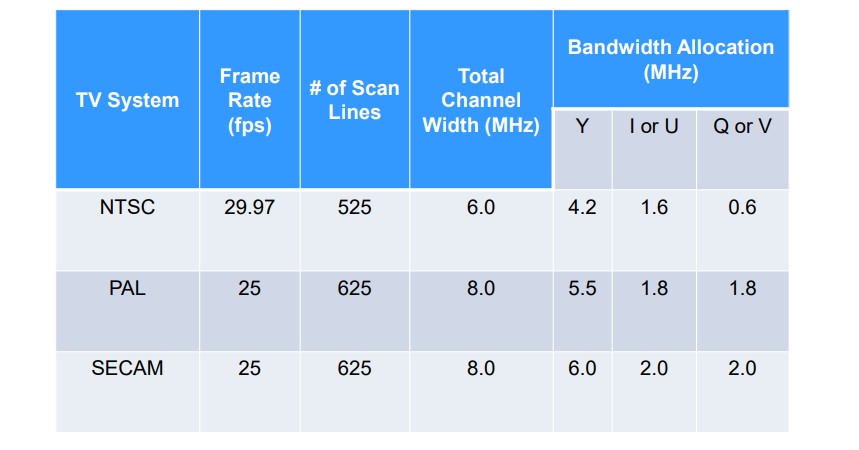
4.2.2 NTSC信号

NTSC:National Television Standards Committee,正交平衡调幅
- 长宽比:4:3
- 每一帧:525行
- 每一秒:30帧
- 颜色模型:YIQ
详细参数:
- FPS:29.97,33.37ms每帧
- 隔行扫描,每个场262.5行
- 水平扫描频率:525×29.97 = 15734行
- 每一行时间:1/15734 = 63.6 μsec
- 水平回溯:10.9
- 扫描:52.7
- 垂直回溯:每个场20行的时间,因此每一帧只有485行的时间
- 水平扫描:保留光栅的1/6
- 水平分辨率:每行样本数

调制方式:\(Y+I\cos(F_{sc}t)+Q\sin(F_{sc}t)\)
- \(YIQ\):为原始信号
- \(F_{sc}\):为一个高频信号


解调方式
- 通过一个低通滤波器,将\(Y\)、\(C=I\cos(F_{sc}t)+Q\sin(F_{sc}t)\)分离
- 将\(C*2cos(F_{sc}t)\),可得\(I+I\cos(2F_{sc}t)+2Q\sin(2F_{sc}t)\)
- 然后使用低通滤波器,将\(I\)分离出来
4.2.3 PAL信号

PAL:Phase Alteration Line,逐行倒相正交平衡调幅
- 颜色模型:YUV
4.2.4 SECAM信号

- SECAM:顺序传送彩色与存储
4.2.5 三种信号对比
4.3 数字视频
4.3.1 数字视频的优点
- 将视频存储在数字设备或存储器中
- 可随时处理并集成到各种多媒体应用程序中
- 直接访问:非线性视频编辑
- 重复记录而不降低图像质量
- 易于加密,更好地容忍信道噪声
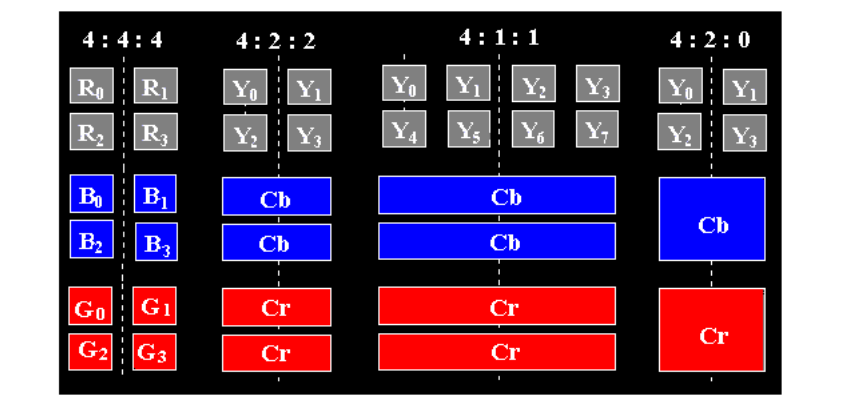
4.3.2 色度下采样 Chroma subsampling
色彩模型的转换,不会产生数据损失
- 人类视觉:对明暗变化的敏感度,远大于对于颜色变化的敏感度
- 每四个原始像素,实际发送的像素值是多少?
- 4:4:4:表示无二次采样
- 4:2:2:表示Cb和Cr的水平二次采样,系数为2
- 水平的两个像素,用一个像素值表示
- 4:1:1:表示Cb和Cr的水平二次采样,系数为4
- 水平的四个像素,用一个像素值表示
- 4:2:0:分别表示Cb和Cr的水平和垂直二次采样,系数为2
- 水平&垂直的2×2共4个像素,用一个像素值表示
- JPEG和MPEG中通常使用的4:2:0方案
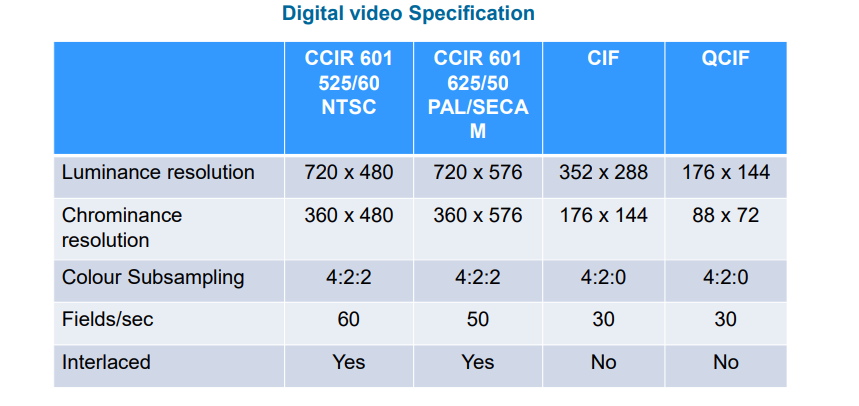
4.3.3 CCIR标准

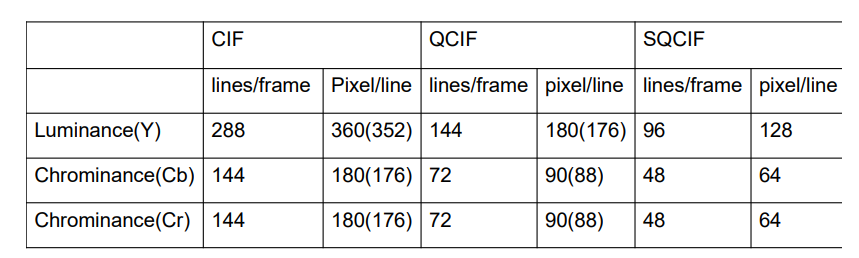
4.3.4 CIF标准


4.3.5 HDTV:High Definition TV

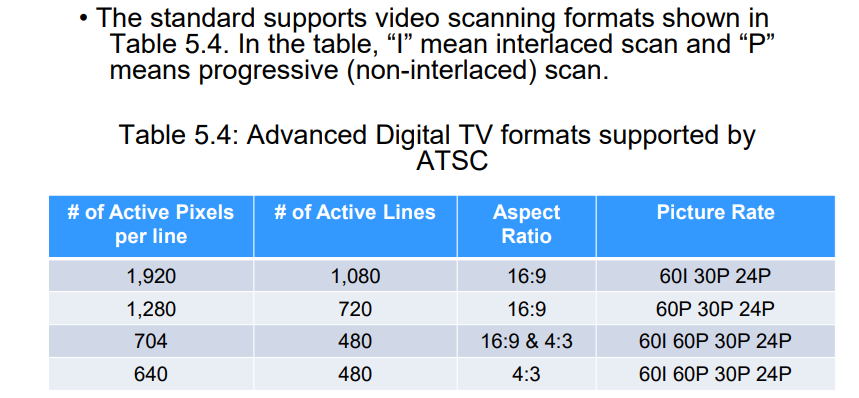


五、数字音频基础
5.1 声音的数字化
5.1.1 什么是声音
- 声音是像光一样的波动现象
- 没有空气–没有声音
- 声音是一种压力波,具有连续值
- 声音具有波的特性和行为
- 反射
- 折射
- 衍射
- 声音可以通过将压力转换为电压水平来测量
5.1.2 数字化
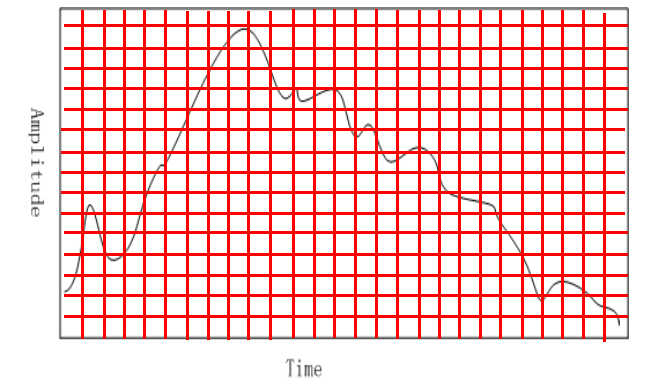
- 振幅Amplitude:连续值和随时间变化
- 在时间维度和振幅维度采样
- 时间维度:以均匀间隔采样
- 典型范围:8kHz至48kHz
- 人类可以听到20Hz到20kHz的声音
- 量化:振幅维度的采样
- 均匀采样 Uniform Sampling:等距采样
- 非均匀采样 Nonuniform Sampling:如u-law规则
- 典型的均匀量化率:
- 8位,256级
- 16位,65536级
- 三个关键问题
- 采样频率是多少?
- 采样到的数据如何量化?分成多少级?
- 音频数据如何存储?文件格式是什么?
在时间维度和振幅维度采样,需要将两个轴均离散化
5.1.3 奈奎斯特定理
- 奈奎斯特速率 Nyquist Rate:
- 采样频率必须是原始信号最大频率的2倍
- 奈奎斯特定理 Nyquist Theorem:
- 如果原始信号的最大频率为f1,最低频率为f2,带宽为f1-f2,则采样频率至少为2(f1-f2)
- 奈奎斯特频率 Nyquist Frequency:
- 如果数字信号的频率为F,则能够还原的无失真信号的最大频率为F/2
5.1.4 信噪比SNR
\(SNR = 10\log_10 \frac{V_{signal}^2}{V_{noise}^2}=10\log_10 \frac{V_{signal}}{V_{noise}}\)
- SNR:信号与噪声的功率之比称为信噪比,这是信号质量的度量。
- 单位:分贝dB,其中1dB为十分之一贝尔
- 信号的功率与电压的平方成正比
- 例如,如果信号电压Vsignal是噪声的10倍,则SNR为20log10(10)=20dB。
- 在功率方面,如果十把小提琴的功率是一把小提琴的十倍,则功率比为10dB或1B
5.1.5 SQNR
\(SQNR=20\log_{10}\frac{V_{signal}}{V_{quan\_noise}}=20\log_{10}\frac{2^{N-1}}{0.5}=20*N*\log_2=6.02N(dB)\)
- 在量化时,会人为引入误差,也被称为人为引入噪音


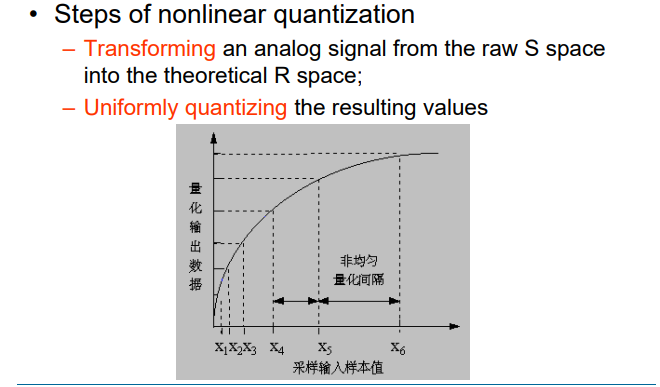
5.1.6 非线性采样
- 对于声音的采样来说,高频部分采样稀疏,低频部分采样密集
5.1.7 声音过滤
- 在采样和AD转换之前,通过过滤音频信号来去除不需要的频率
- 保留的频率取决于具体应用:
- 人的语音:50Hz至10kHz
- 音频音乐信号:20Hz至20kHz
- 其他频率被带通滤波器(也称为限带滤波)过滤掉了
- band-pass filter,band-limiting filter
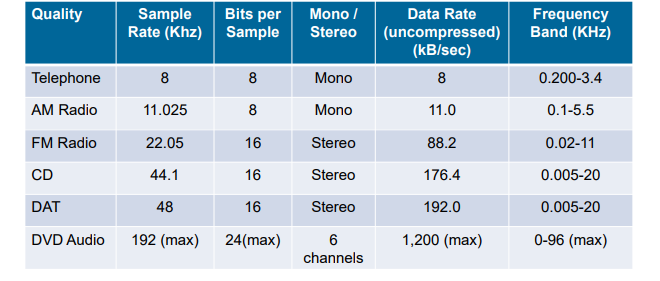
5.1.8 音频质量与数据速率
- 未压缩的数据速率随着用于量化的比特数的增加而增加
- 音频质量:数据速率和带宽
- 模拟设备,带宽以频率单位表示,赫兹
- 数字设备,比特每秒,bps
5.1.9 合成声音


5.2 乐器数字接口
5.2.1 MIDI
- MIDI存储的是合成声音的指令,而不是原始信号
- 机器根据MIDI的指令,合成固化在硬件中的波形
5.3 音频的量化和传输
每个压缩模式包含三个阶段:
- 对输入数据进行变换:不会产生信息差异
- 量化:会导致信息丢失
- 编码
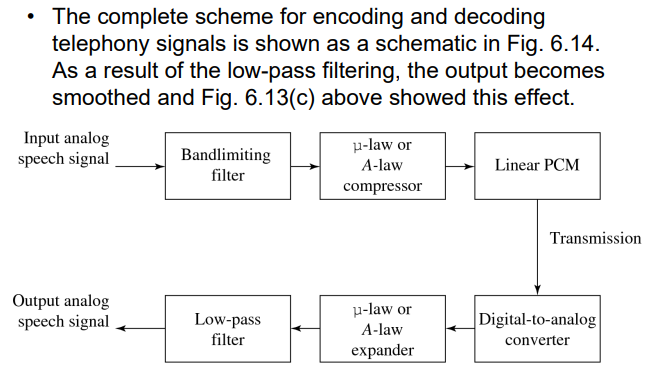
5.3.1 声音的编码
- 编码Coding:数据的量化与传输
- 时间上的冗余性:声音信号是连续的,即相邻的两个点的值差别不大
- 因此可以减少存储的数据量
- 编码调制
- PCM:脉冲编码调制
- DPCM:脉冲编码调制的差分版本
- ADPCM:Adaptive DPCM
5.3.2 PCM:Pulse Code Modulation
PCM的过程:确定采样点、求交、取整
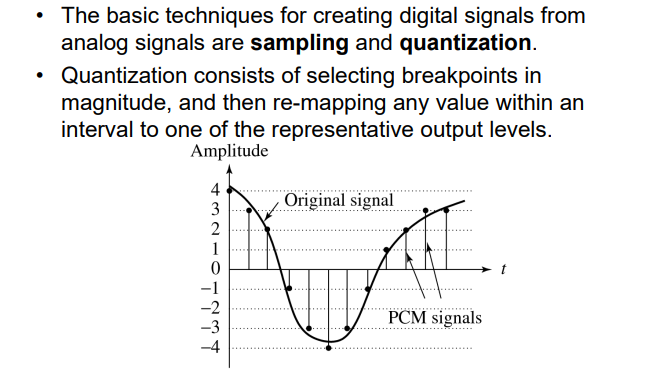
均匀量化:对采样到的值均匀的分为多个等级
非均匀量化:在某些部分分的等级多,某些部分分的等级少
在数转模的过程中,会引入高频噪声,因此需要一个低通滤波器
5.3.3 音频的差分编码 Difference coding of audio
- 存储当前采样点的值,与上一采样点的值的差值
- 信号分布的范围越广,压缩的可能性越低
5.3.4 无损预测编码 Lossless Predictive Coding
预测编码:
- 预测当前时刻值,为上一时刻的值\(\hat f_n = f_{n-1}\)
- 但是肯定会有误差,存储的数据即为误差本身\(e_n=f_n-\hat f_n\)

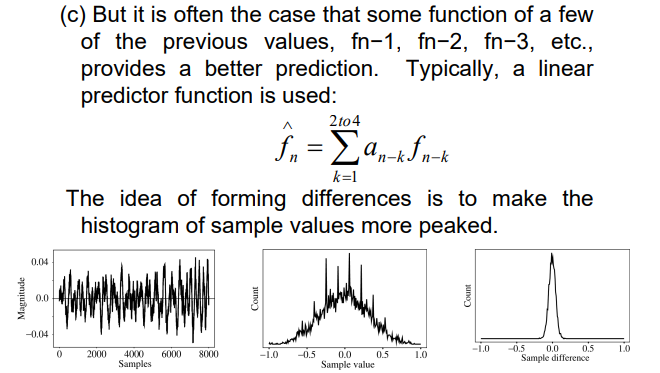
无损预测编码:解码器产生与原始信号相同的信号
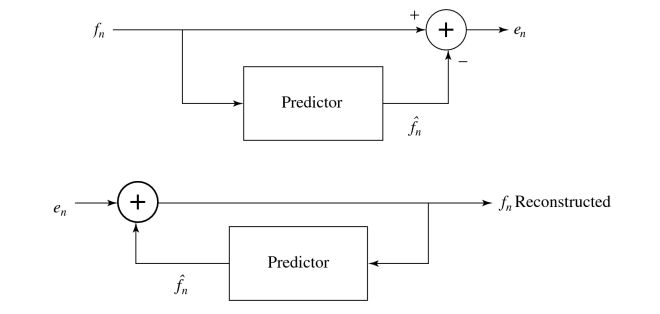
示例:\(\hat f_n =\lfloor \frac{1}{2} (f_{n-1} + f_{n-2}) \rfloor\),\(e_n=f_n-\hat f_n\)

5.3.5 DPCM

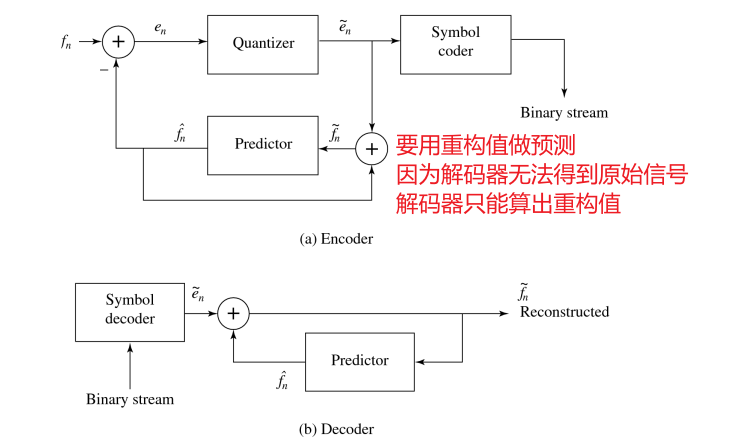

六、无损压缩算法
6.1 信息论基础
6.1.1 背景
- 压缩的目的:
- 节约存储空间、提高传输速率
- 不同的数据,出现的频率不同:
- 出现频率越高的数据,给越短的编码
6.1.2 数据压缩范式
- 压缩率:B0/B1
- B0:为压缩前的数据的bit数
- B1:为压缩后的数据的bit数
- 压缩算法用到某些数据上后,可能会导致数据bit数变大
- 压缩率越大,压缩算法越好
- 无损压缩:解码出的数据 == 压缩前的数据

6.1.3 信息论基础
熵 entropy:表征信源的信息量大小
- 如果要压缩一个文本文档,那么文本文档本身是信源,ASCII码表是信源的码表
- 熵越大,表示该系统更无序,压缩后的产物越大
- 压缩算法实际上就是降低信源的熵
计算方法:设码表为\(S=\{s1,s2...,sn\}\)
- 则熵为:\(\eta=H(S)=\sum_{i=1}^{n}p_i\log_2\frac{1}{p_i}=-\sum_{i=1}^{n}p_i\log_2p_i\)
- \(p_i\):表示\(s_i\)在信源中出现的概率,\(p_i=\frac{s1出现的次数}{信源包含的字符数}\)
- \(\log_2\frac{1}{p_i}\):表示信号\(s_i\)的熵 amount of information contained in characters


熵编码:高频出现的符号,码长更短
如果某个符号的熵为k,则使用熵编码后,其二进制位数至少为k bits
6.2 无损编码算法
6.2.1 Run-Length Coding 游程编码
思想:将连续出现多次的字符,转换为(字符, 出现次数)
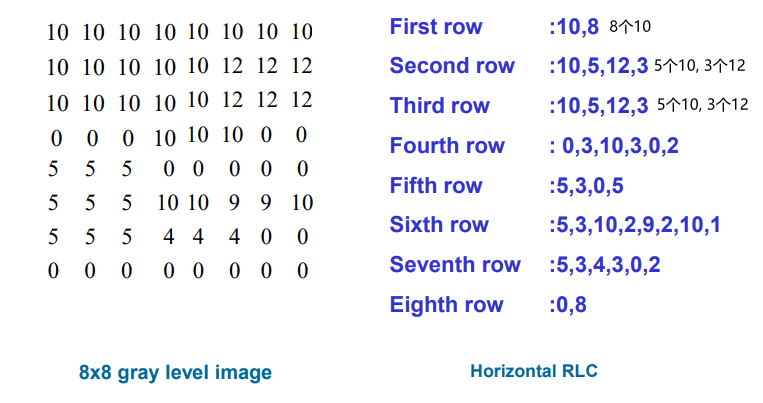

6.2.2 Variable-Length Coding 可变长编码
思想:计算出所有符号的熵后,根据熵的大小,赋予编码值
Shannon-Fano算法
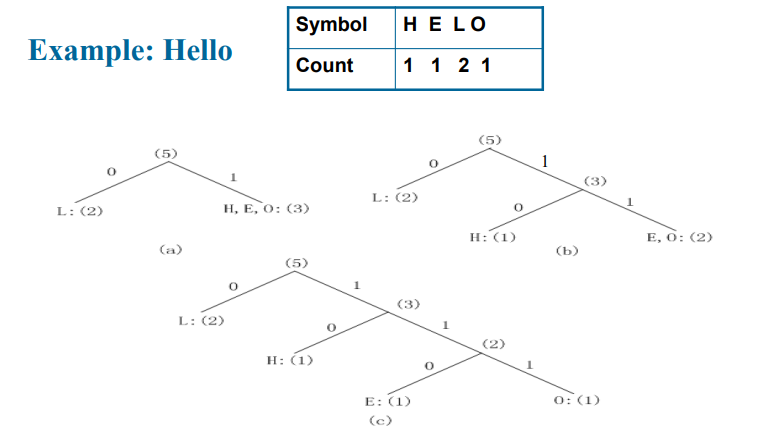
Huffman编码
- 先统计出现的概率,然后根据概率建树,最后对树进行编码
- 扩展Huffman编码:对于某些连续出现的字符,如abc,可以把它们作为整体定义为一个新的字符
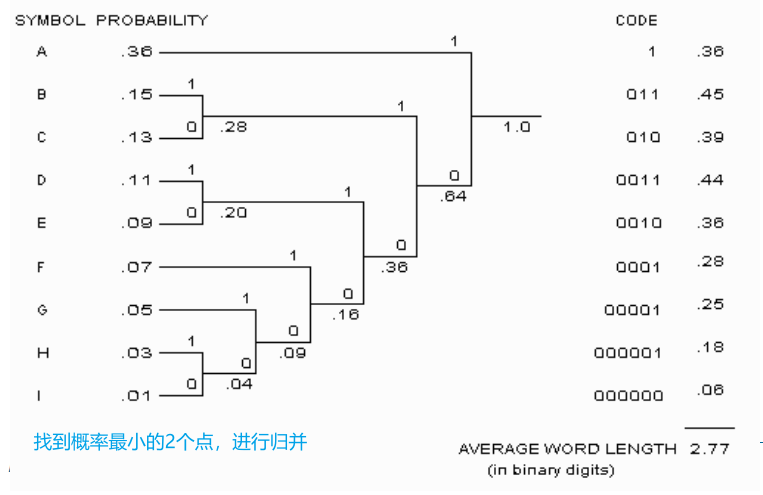
自适应Huffman编码
- 由于信源在不断发出信号,因此我们只能统计到当前位置,某个字符出现的概率
- 在编码器和解码器中,同时维护两棵树,根据发出的字符,动态调整树的结构
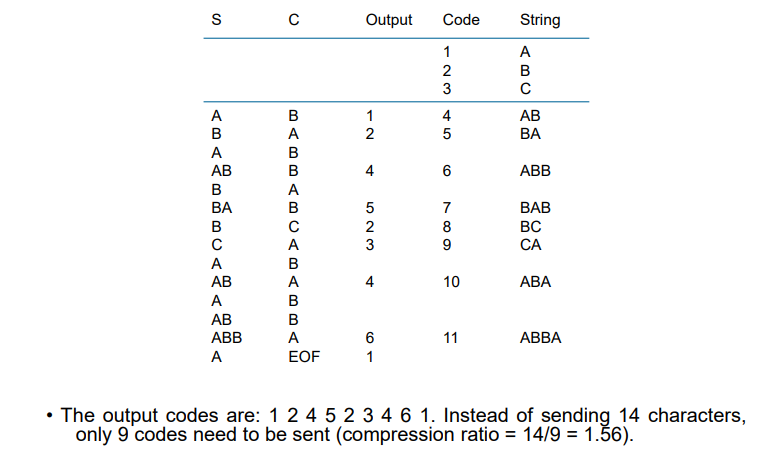
6.2.3 Dictionary-Based Coding 字典编码
思想:对出现的不同字符串,赋予一个编码,传输时同时传输码表

- 首先,将ABC分别赋予1、2、3
- 对于输入
ABABBABCABABBA- 将
A入栈,发现A在码表中,输出1,然后



6.2.4 Arithmetic Coding 算术编码
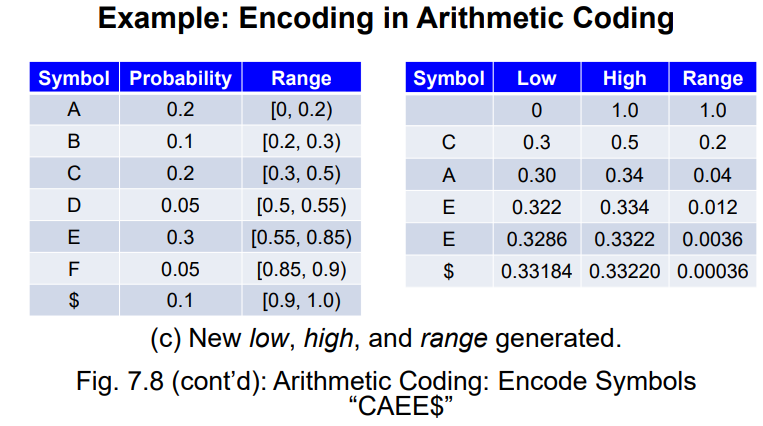
- 将每个字符,按出现的频率,划分
[0~1)的地盘- 第一个字符为
C,则将[0.3,0.5)的地盘再次根据频率划分地盘- 第二个字符为
A,则将[0.3,0.34)的地盘再次根据频率划分地盘- 重复以上过程,直到所有的字符均读入过
- 在最后得到的区间范围内,随机选取一个小数,作为编码结果
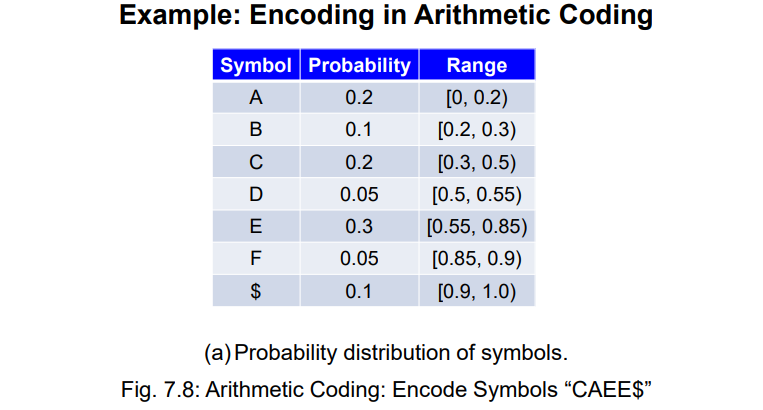
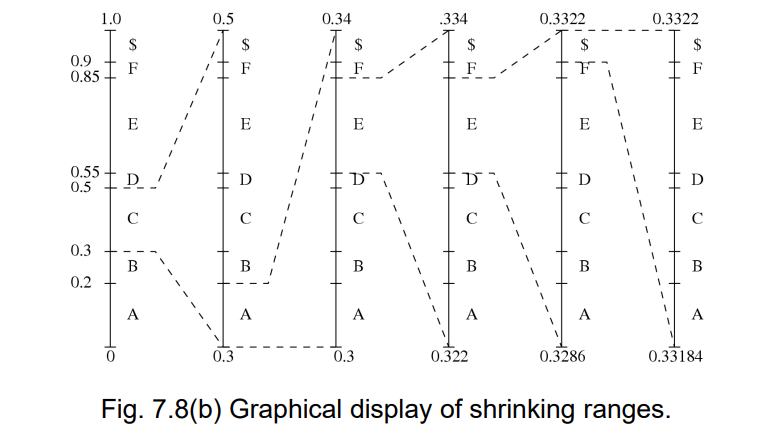

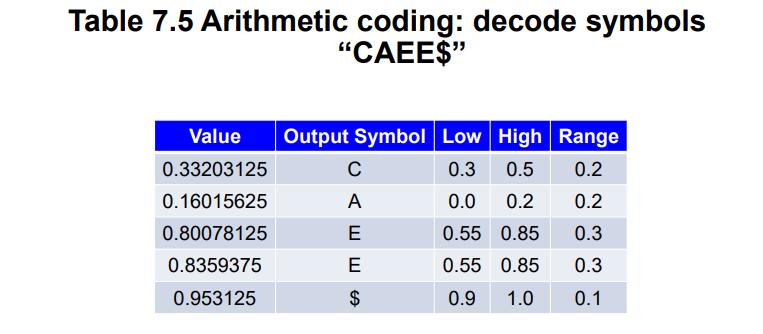
- 接收到的小数为
0.33203125,在[0.3,0.5)之间,则第一个字符为C- 第二个小数为
(0.33203125-0.3)/0.2=0.16015625,在[0.0,0.2)之间,则第二个字符为A- 第三个小数为
(0.16015625-0.0)/0.2=0.80078125,在[0.55,0.85)之间,则第三个字符为E- 重复上述操作,直到读到文档结束符号
$

6.3 无损图像压缩
6.3.1 图像差分编码:降低数据的熵
- 简单差分算子:\(d(x,y)=I(x,y)-I(x-1,y)\)
- 离散二维拉普拉斯算子:\(d(x,y)=4I(x,y)-I(x,y-1)-I(x,y+1)-I(x+1,y)-I(x-1,y)\)

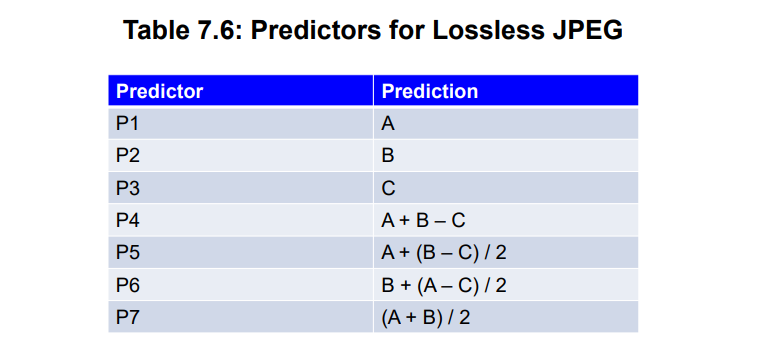
6.3.2 无损JPEG

JPEG中由很多种预测算法,目的是让预测尽可能的准确,从而让差分值接近0
七、有损压缩算法
7.2 损失测量 Distortion Measures
7.2.2 Distortion的数学测量
MSE:Mean Square Error,越大损失越多
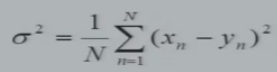
SNR:Signal-to-noise Ratio,越大损失越少

PSNR:Peak-signal-to-noise Ratio,越大损失越少

7.3 失真率
7.3.2 R-D函数
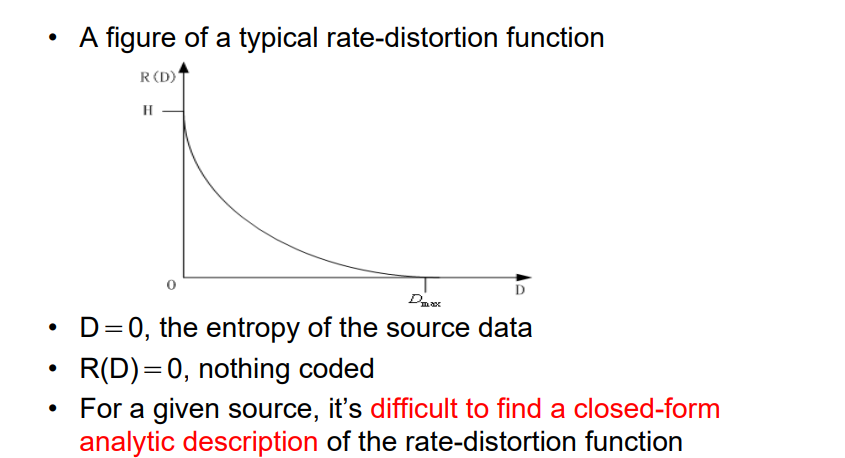
7.4 量化 Quantization--产生损失
7.4.2 Uniform Scalar Quantization




7.5 Transform Coding
7.5.1 基础思想
- 对于单个标量编码的效率,不如直接对整个向量编码
- 因为压缩成向量之后,相邻数据的相关性更低
- 如果存在一个线性变换
T,将向量X变换为Y,且Y的相关性小于X,则对Y编码的效率更高T不会导致信息的损失
- DCT:离散余弦变换
- 定义了一个长度为8的DCT
- 输入是长度为8的向量f(i),输出为长度为8的向量F(u)
- C(u)为一个常数

使用DCT压缩数据
- 输入为:
X - 做一次DCT变换:
Y = dct(X) - 量化:
Z = Y(0:7),此处产生了信息损失 - 编码:将
Z使用无损编码,进行保存&传输 - 解码:
X' = idct(Z)
目标:让X'与X尽可能接近
7.5.2 DCT:离散余弦变换 Discrete Cosine Transform
7.5.2.1 一维DCT变换

将F(u)展开,f(i)前面的系数,相当于定义了一个线性变换的矩阵,并且只要u和N确定,矩阵就是一个常量
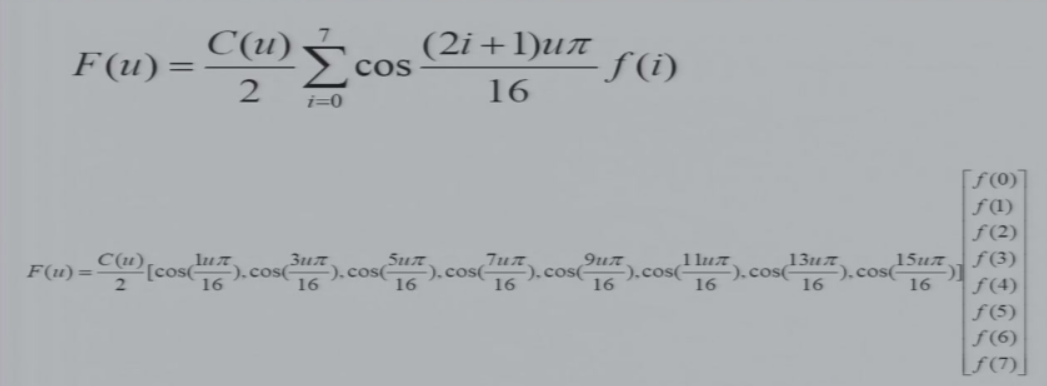

7.5.2.2 在三维空间的DCT变换示例
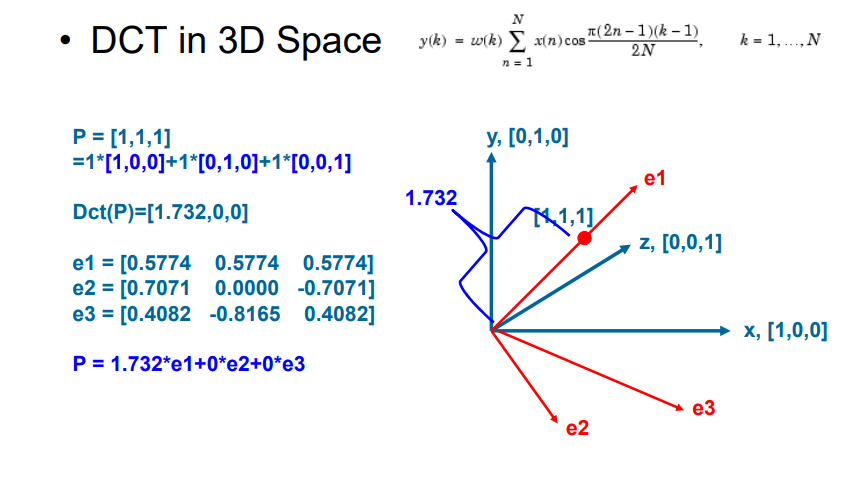
7.5.2.3 DCT是正交线性变换,即不同行向量的内积为0

7.5.2.4 DCT是线性变换,满足加法性质:\(T(\alpha p+ \beta q) = \alpha p + \beta q\)
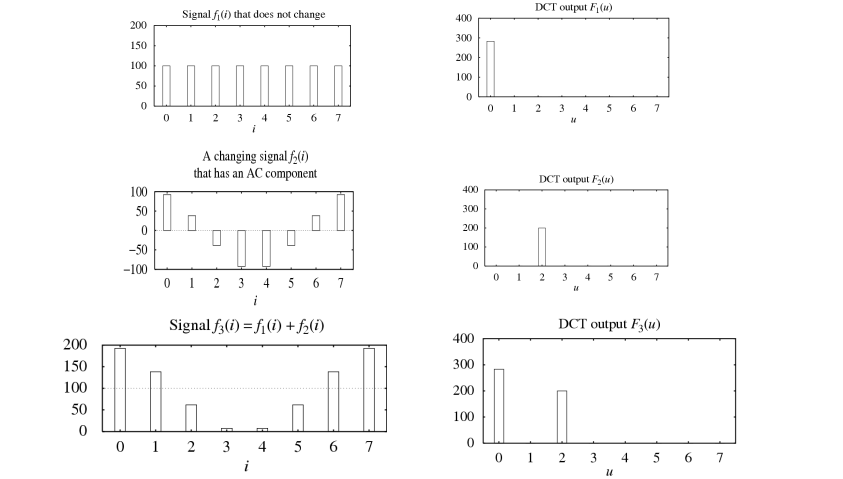
7.5.2.5 DCT的物理含义:给定任意一个输入信号,告诉该信号是如何有基信号组合而成的
- 原始信号 = 基向量的线性组合
- F[0]为DC系数,表示原始信号的直流系数;其他信号为AC系数,表示原始信号的交流系数
- DC = 0,表示原始信号没有直流分量
- 只有DC不为0,表示原始信号为直流信号
- 如果DC为负数,则说明输入信号的平均值 < 0
- 如果AC为负数,说明输入信号与基信号的相位,相差半个周期

7.5.2.6 2维DCT变换:定义了一组基矩阵
- 计算方法:将输入信号,与每一个基矩阵做卷积(对应元素相乘求和),然后将值写入对应位置
- 正向变换:信号分解
- 逆向变换:信号组合




7.5.2.6 DFT:离散傅里叶变换

7.6 Wavelet-Based Coding 小波变换
7.6.2 小波变换示例

7.6.3 一维Harr变换
- 设原始信号为:
{a1,a2,a3,a4,a5,a6,a7,a8} - 做1次变换:
{a12,a34,a56,a78,d12,d34,d56,d78} - 做2次变换:
{a12,a34,a56,a78,d12,d34,d56,d78}
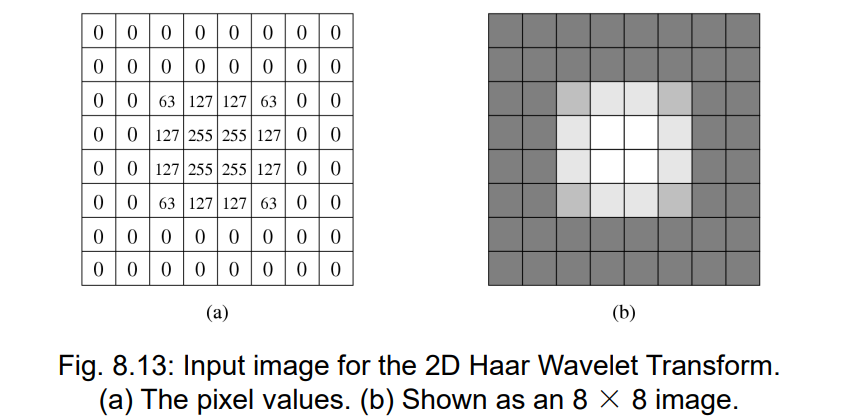
7.6.4 二维Harr变换

八、图像压缩标准
8.1 JPEG标准
Joint Photographic Experts Group
- 标准名:ISO 10918-1
- JEPG定义了图像的有损 & 无损压缩的流程及方法
- 图像:是一个二位函数
- 图像的有损压缩,即对图像做2D DCT变换
- 观测到的三个事实
- 图像具有空间冗余性,在某个较小的区域内,像素的颜色值变化不会很大
- 心理学实验告诉我们,人的视觉系统对于低频部分变化的感知能力,大于对于高频部分变化的感知能力:即对于低频信号敏感,高频信号不敏感
- 人的视觉系统,对于明暗变化的敏感度,大于对于色彩的敏感度
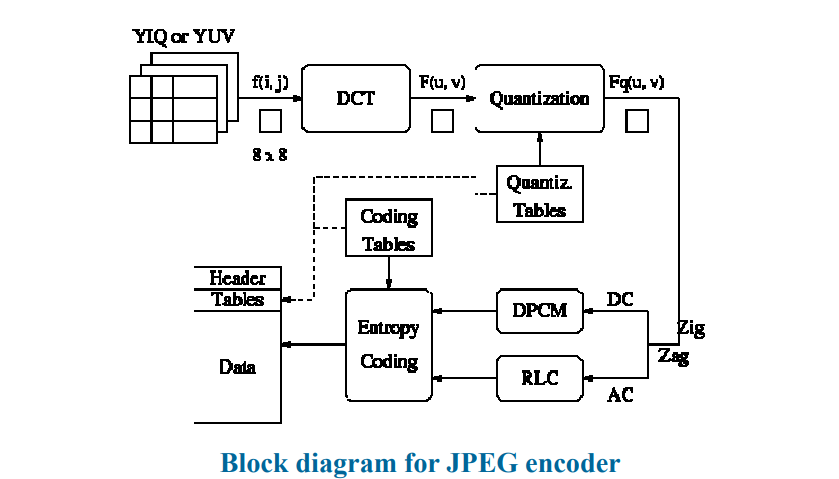
8.1.1 JEPG压缩步骤
- 将RGB转换为YIQ/YUV,然后对颜色进行下采样:出现损失
- 会有三个矩阵:一个较大的Y矩阵,两个较小的IQ/UV矩阵
- 对图像矩阵进行DCT变换
- 进行量化:出现损失
- Zigzag排序
- 对DC信号进行DPCM编码
- 对AC信号进行RLE编码
- 最后,进行熵编码
8.1.1.1 DCT
- 对图像切分为8×8的块,然后进行2D DCT变换
- 8×8是对准确率和计算效率的折中
- 块很大时,会出现马赛克效应
8.1.1.2 量化

- 量化时,不同层使用的量化矩阵不同
- 量化矩阵是通过心理学实验测出来的
- 灰度层的量化表更细,颜色层的量化表更粗
- 将图像矩阵
F(u,v)与量化矩阵Q(u,v)对应元素相除,然后取整
8.1.1.3 Zigzag展开
- 将8×8的矩阵,展开为长度64的向量
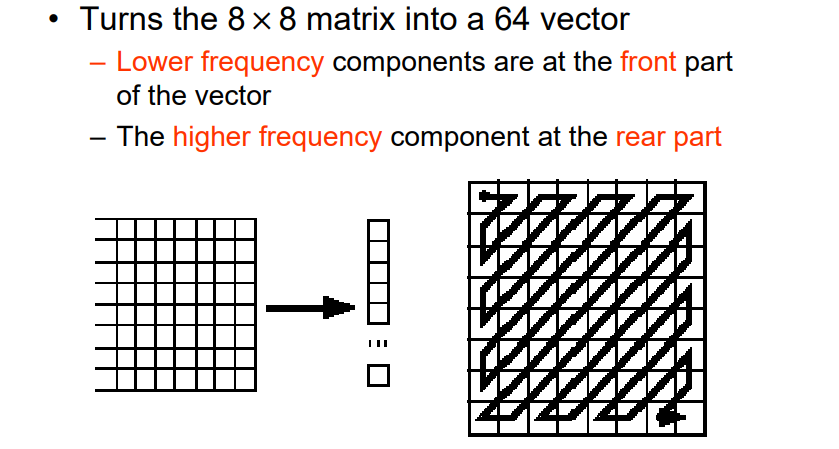
8.1.1.4 对AC信号做RLE编码
- RLE:游程编码

8.1.1.5 对DC信号做DPCM编码
- 将整张图的所有DC信号取出来,再做DPCM差分预测编码

8.1.1.6 对结果做熵编码

8.1.2 JPEG模式
8.1.2.1 顺序模式 Sequential
JPEG的默认模式
- 对图像进行编码时,使用从左到右,从上到下扫描方式
- 图像会从上到下依次显示
8.1.2.2 渐进模式 Progressive
- 方法一:先传输每一块的低频部分,然后传输每一块的高频部分
- 解码时,先解码低频信号,然后解码高频信号,将后面的解码结果叠加到原来的图像上
- 方法二:由于已经编码为二进制数,因此可以按每一个系数的位,依次传递
- 比如,可以先传输二进制数的最高位,然后依次传输后面的位
- 图像会由模糊变得清晰
8.1.2.3 层次模式 Hierarchical
- 将图像做多次下采样
- 传输时,按层次传输,每一次传输与上一层的差值
8.1.2.4 无损模式 Lossless
- 使用差分预测编码,而不是DCT编码
8.2 JEPG2000标准
- 同时提供了有损、无损两种形式
- 可以进行分区域编码:ROI(Region of insterest),不同区域使用不同的压缩矩阵
九、基础视频压缩算法
9.1 Introduction
三个可以压缩的方向:
空间信息冗余性:冗余度较小
颜色信息:将RGB转成YUV,然后再进行下采样
时间信息冗余性
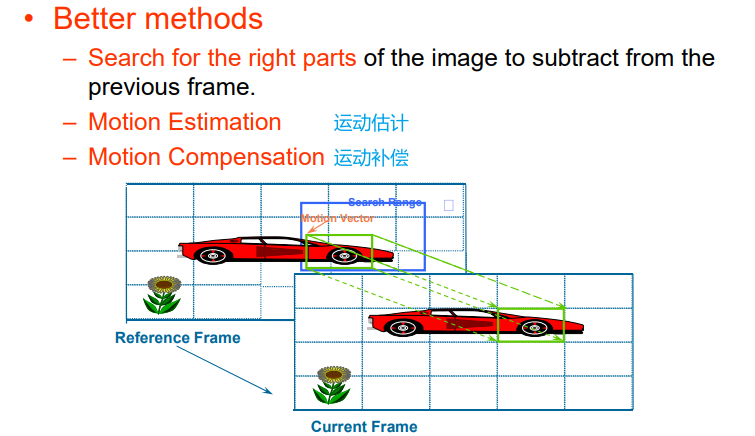
预测编码:假设第二帧和第一帧一样,传输差值,但是可能相邻两帧相差很大

因此不能直接对整张图像做差分,而是先将当前帧划分为16×16的宏块(Macro Block),到前一帧找到与它类似的宏块,然后再进行差分计算
- 传输时,既要传输残差,也要传输每个宏块对应的上一帧的部分,与当前宏块的位移差
- 位移称为运动向量
- 如果找不到,则直接传输当前宏块
9.2 基于运动补偿的视频压缩
9.2.1 时间冗余性
- 相邻的帧,通常很相似,因此需要通过差分信息进行编码
- 相邻两帧的差异,通常由于摄像机/物体的运动
- 基础思想:检测相邻两帧对应位置的差异
- 运动估计:判断哪两个宏块为对应位置
- 运动补偿:计算对应宏块的差异
- 两种帧:
- Intra-Frame I帧:独立编码,不做运动估计&补偿
- Inter-Frame:使用运动估计&补偿进行压缩
- P帧:参考帧在前面
- B帧:参考帧同时在前面&后面
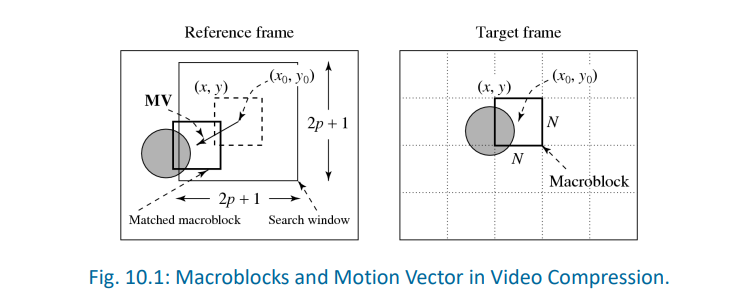
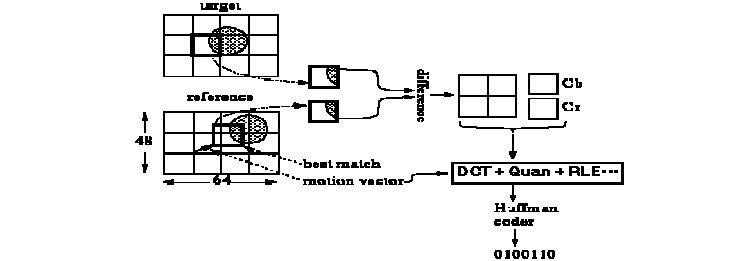
9.2.2 运动补偿 Motion Compensation
运动估计:
- 以当前宏块 macroblocks所在位置为中心,划定一个区域 (如 2p+1 × 2p+1),在该区域内进行搜索
- 如果能找到中心点在该区域,且与当前宏块类似,则停止该过程
- 计算当前宏块与对应位置的位移,称为运动向量
运动补偿:
- 运动向量搜索
- 基于运动补偿的预测
- 对残差进行编码
9.3 搜索运动向量
9.3.1 判断是否匹配
- C:当前帧
- R:参考帧
- 判断是否相同:对应位置求差,然后将绝对值加和

9.3.2 顺序搜索 Sequential Search
- 每次移动中心像素,每次移动一个像素
- 优点:可以在搜索区域内找到最优解
- 缺点:时间太长
9.3.3 2维对数搜索 2D-Logarithmic-search

- 以对应位置为中心,划定搜索范围,在整个范围内,均匀采样9个块
- 以最小的块为中心,搜索范围减半,均匀采样9个块,计算差值
- 重复第2步,直到搜索几次之后停止
- 优点:快
- 缺点:不一定能找到最优解
9.3.4 层次搜索 Hierarchical Search
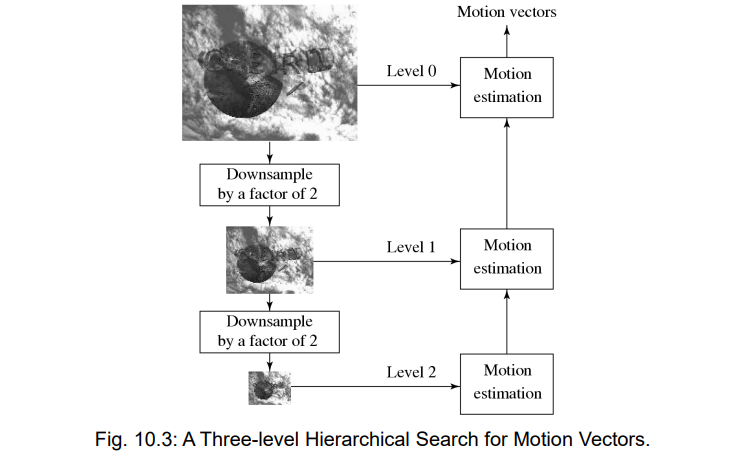
- 先进行下采样,在低层次中使用较小的块,找到与之相似的块,返回到上一层求精
9.4 H.261
9.4.1 总览
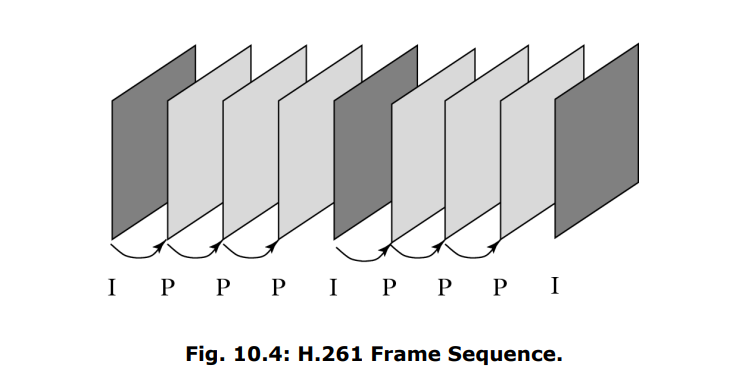
- 箭头:从箭头的尾帧推出箭头的指向帧
- I帧:独立帧,只去除空间冗余性
- P帧:根据前一帧进行预测
- 运动向量搜索只在Y层上做
- 差分在Y、U、V上均要做
- 对运动向量也要做差分预测编码
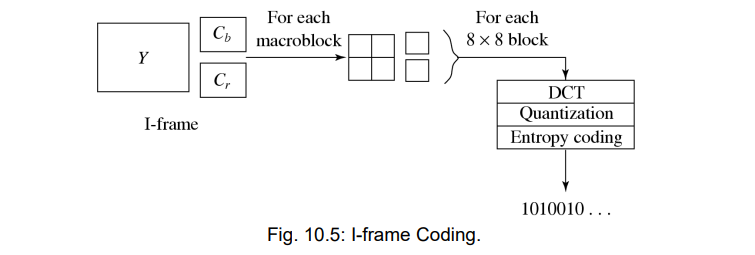
9.4.2 Intra-Frame Coding
9.4.3 Inter-Frame predictive Coding
9.4.4 量化

9.4.5 整个过程
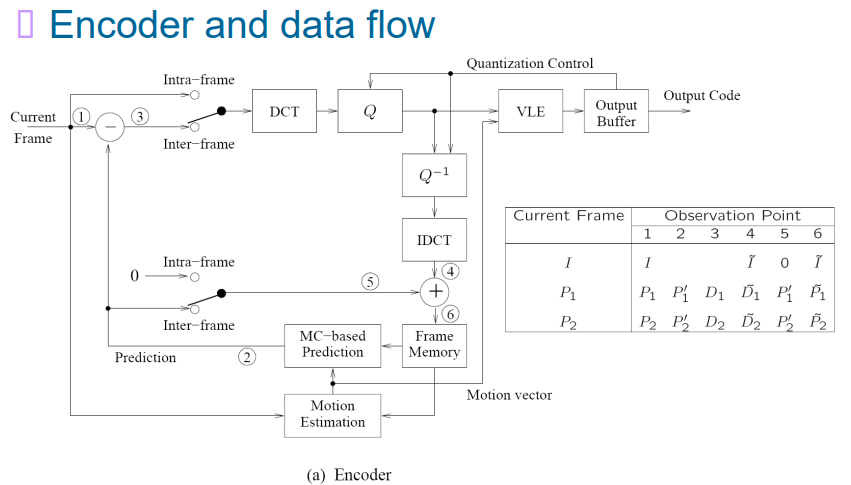
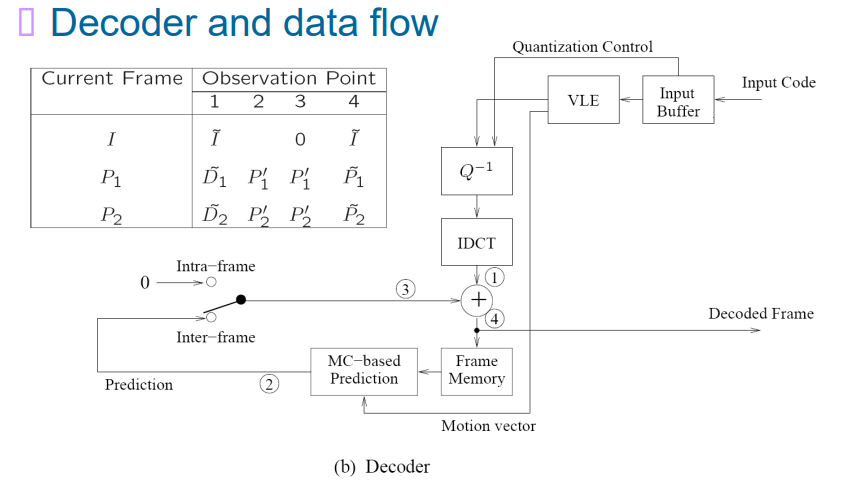
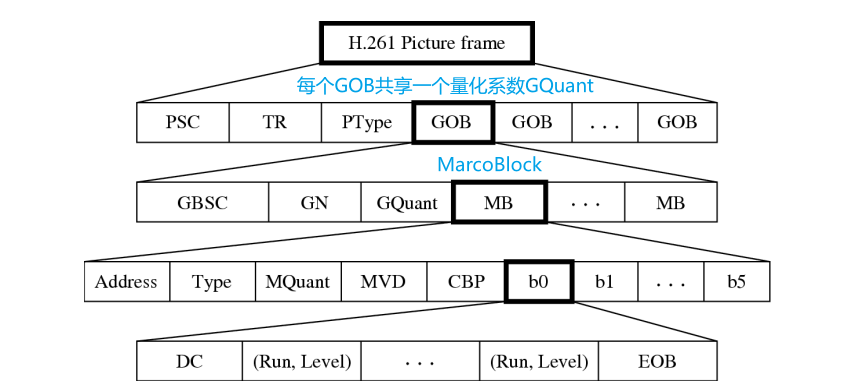
9.4.6 H.261 视频Bit流
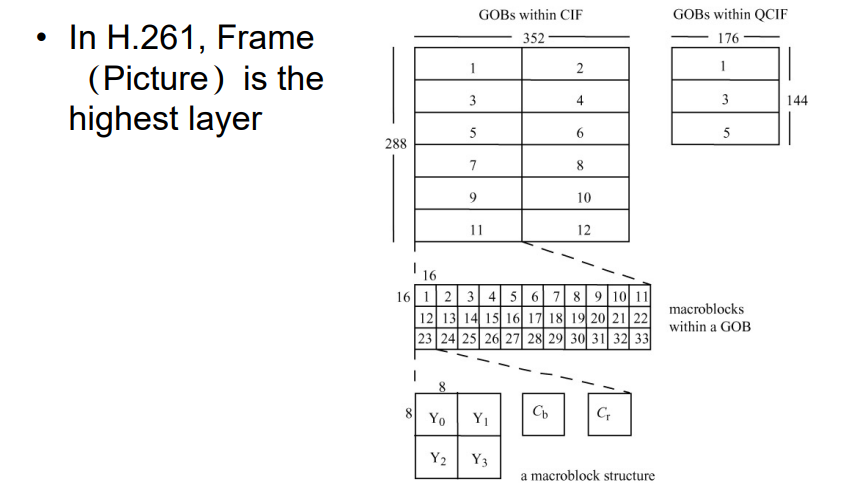
9.5 H.263
- 在宏块划分的基础上,允许对MV进行预测编码
- MV一定是无损压缩,仅仅是降低信息的熵
- 在运动预测时,允许每次移动半个像素查找
- 原本是每次只能移动一个像素,然后对应位判断差值
- 移动半个像素后,需要对像素进行差值
- 类似于提高了图像的分辨率
- 可以将参考帧的边缘进行延展,从而实现不受限的匹配
- 将边界进行复制
- 使用算数编码
- 宏块的大小更加灵活
- 可以进行双向预测
- 在前面的帧、后面的帧中均可找到一个相似的宏块
- 视频编解码可以有一定的延迟,因此可以等后面的帧出现了再进行预测
- 做残差时,与前后两个参考帧做残差,然后再做平均
十、MPEG视频编码
10.1 MPEG-1
- 只支持逐行扫描
- 4:2:0的色彩下采样
10.1.1 运动补偿
- 从前向的的I帧/P帧进行预测,可以跳帧匹配,从而找到更优匹配
- 也可以做双向预测,会乱序传递帧,但是可以通过帧编号确定顺序
- 前后参考帧先求平均,然后再与预测帧做残差
- 如果找不到,可以直接舍弃该参考帧
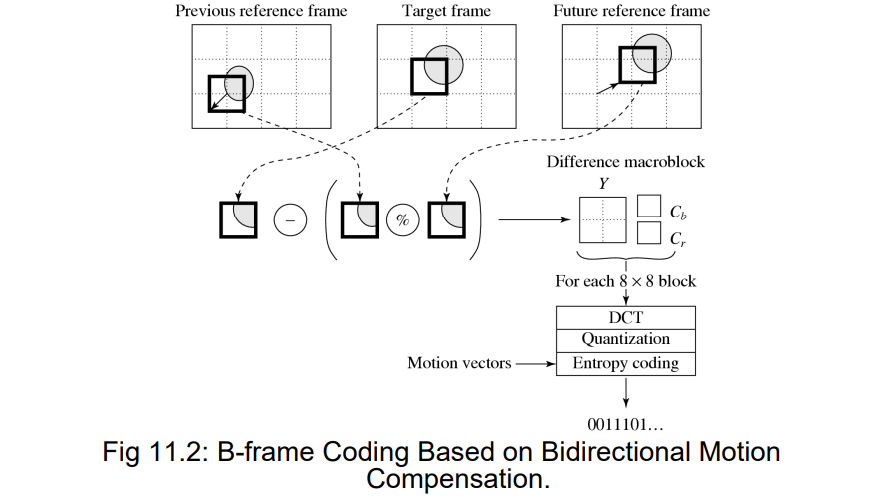
10.1.2 MPEG-1与H.261区别
支持的视频格式不同:
- H.261支持CIF、QCIF
- MPEG-1支持SIF
数据格式不同
- H.261将图像序列划分为了GOB
- MPEG-1将图像序列划分为了slices
- 不同slices之间相互独立,一个slice坏了,不影响其他区域的显示
量化不同
- H.261使用了很大的系数,直接进行压缩
- MPEG-1使用了量化表,并且添加了缩放系数,可以压缩的更狠一点
搜索范围不同
- H.261是[-15, 15]像素
- MPEG-1是[-512, 511.5]像素,并且可以进行半像素搜索
MPEG-1可以随机访问,因为有GOP(Group Of Picture)
- 将一段时间的视频帧打包到一起
10.1.3 MPEG-1视频比特流
GOP层 => 帧 => Slice(Block的组合) => Macroblock => Block
10.2 MPEG-2
10.2.1 总览
- 定义了7种profiles,针对不同的应用,每个profile定义了最多4个画质等级
10.2.2 支持隔行扫描
- Frame-picture:完整的一帧
- Top-field:奇数场图像
- bottom-field:偶数场图像
- 称为Field-picture
- 奇数场的参考帧,可能是奇数场,也可能是偶数场
- 偶数场也一样
5种预测模式
- Frame prediction for frame-pictures:
- 对完整帧进行预测
- Field prediction for field-pictures:
- 可以跨场预测
- Field prediction for frame-pictures:
- 将奇数场和偶数场完全分离
- 16 × 8场图像预测
- 宏块大小为16×8
- Dual-prime for P-pictures
Zigzag展开的方式也不太一样
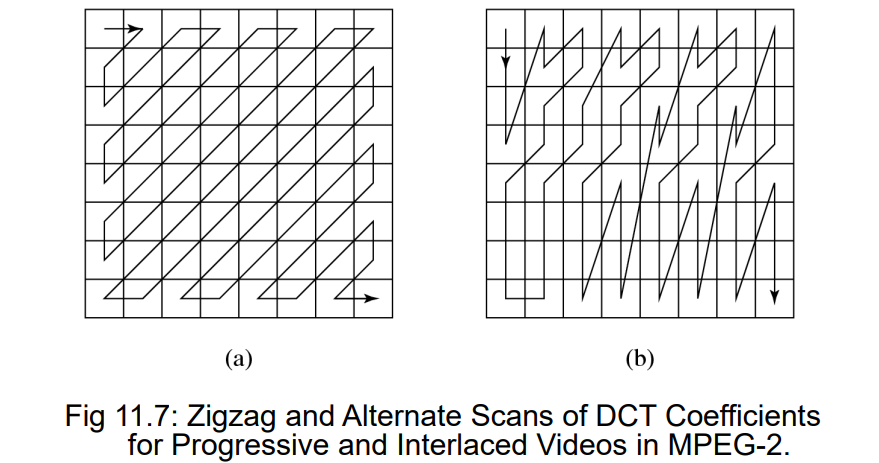
10.2.3 MPEG-2 Scalabilities 可伸缩性
10.2.3.1 可伸缩编码 Scalable Coding
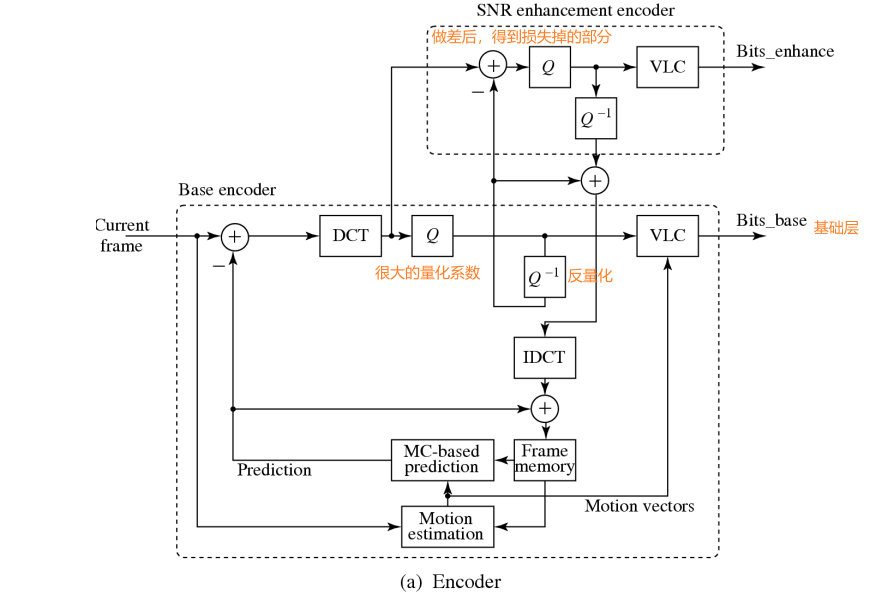
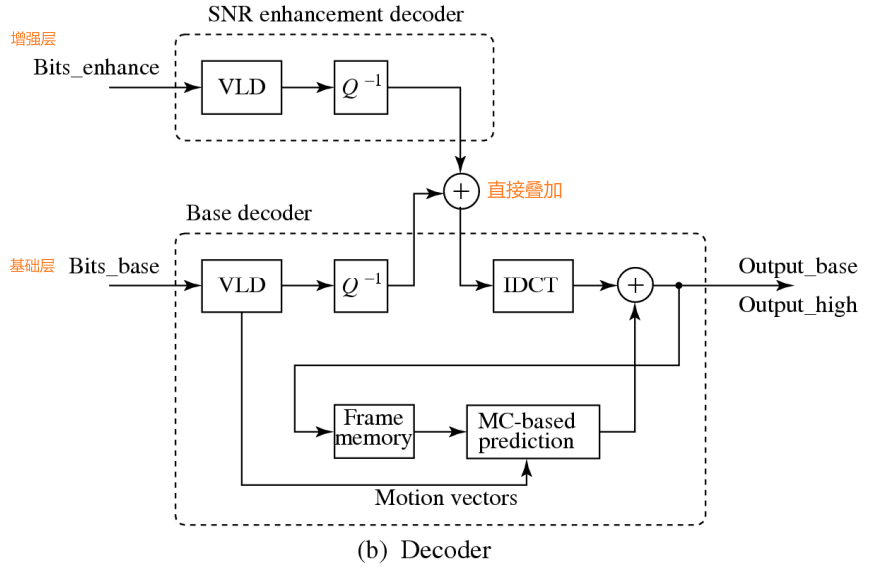
基本思想:
- 将图像划分为Base Layer 和 Enhancement Layer
- 将原有视频降低分辨率,得到Base Layer
- 再将Base Layer放大回去,与原视频做差,得到Enhancement Layer
- Base Layer只有一个,但是Enhancement Layer可以有多个
- 将这两层作为两个视频序列进行传输
- 接收端可以选择只接收Base Layer,或者两个都接受
- 两个都接受时,将Enhancement Layer叠加到Base Layer上即可
10.2.3.2 SNR可伸缩
10.2.3.3 空间可伸缩
- 先进行下采样,得到基础层
- 然后再进行上采样,再与原有图像做差,得到增强层
10.2.3.4 时间可伸缩
- 直接按照时间顺序,将一部分帧作为基础层,一部分帧作为增强层
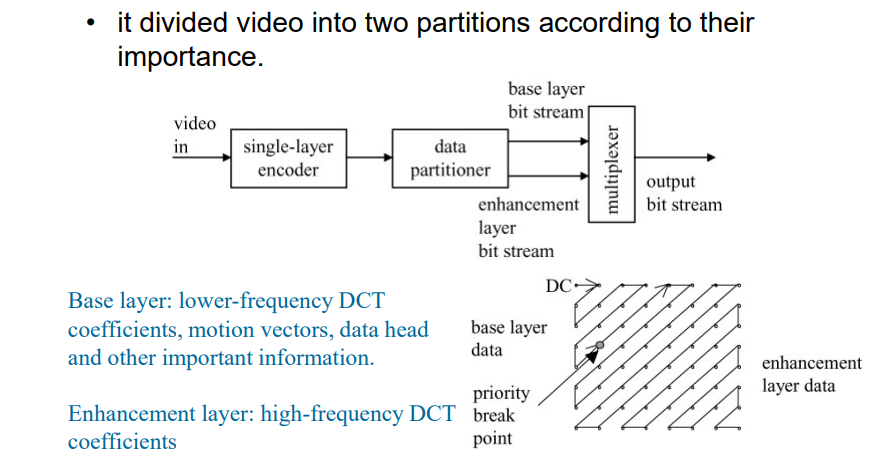
10.2.3.5 数据划分
- 昨晚DCT变换后,进行Zigzag展开
- 将前一部分数据,作为基础层进行传输
- 将后面的数据,切分为若干个部分,作为增强层,进行传输
10.2.4 其他区别
- MPEG-2有更好的容错率
- MPEG-2既可以4:2:0,也可以4:2:2、4:4:4
- Slice的划分不能跨越一行
十一、MPEG视频编码Ⅱ
11.1 MPEG-4
11.1.1 概览
一个更新的标准,除了压缩,还支持数据的上传
是基于对象的编码object-based coding
- 提高压缩比
- 便于对视频的内容进行再加工,即交互行为
- 静态图像编码
- Face对象编码、动画
- Body对象编码、动画
bit率:5kbps ~ 10 Mbps
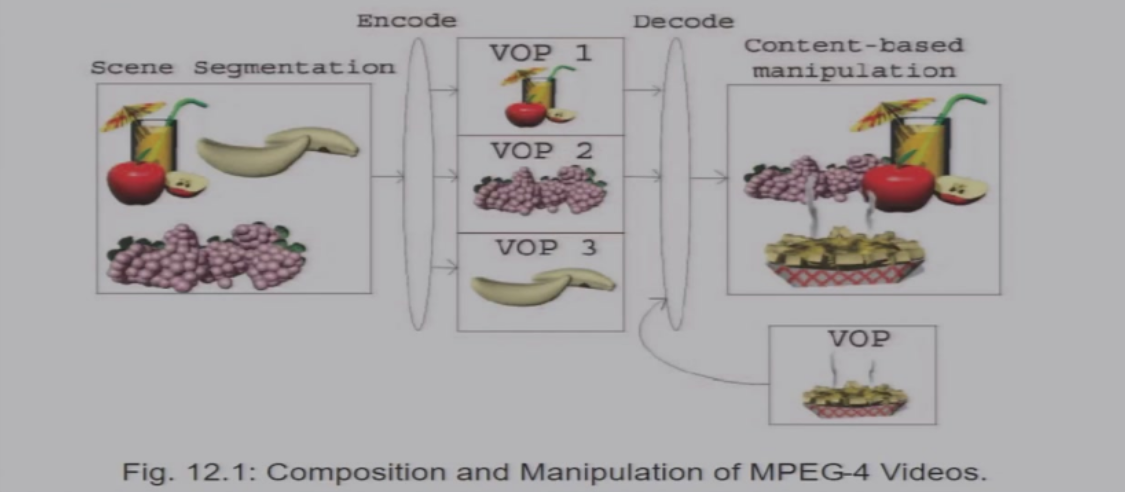
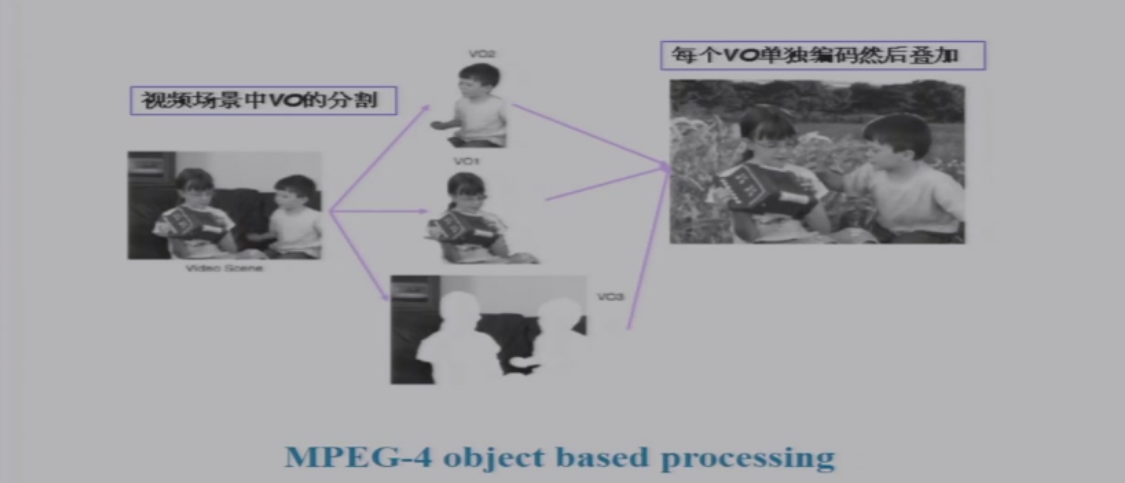
分离对象 => 对每个对象分别编码压缩 => 每个对象单独编码然后叠加
MPEG-4是一种全新的标准,可以支持:
- 组合视频对象,从而创建出预期的场景
- 支持对视频不同质量的服务QoS
- 与音视频场景进行交互
MPEG-4的结构:
- VS
- VO
- VOL:为了实现可伸缩编码,共享系数的GOV
- GOV:相邻的一组VOP
- VOP:某个时刻对于某个VO的一个快照

11.1.2 *基于对象的编码
11.1.2.1 Frame-Based Coding vs VOP-Based Coding
MPEG-1&MPEG-2:基于块的运动估计,没有VOP的概念,直接对帧进行切割
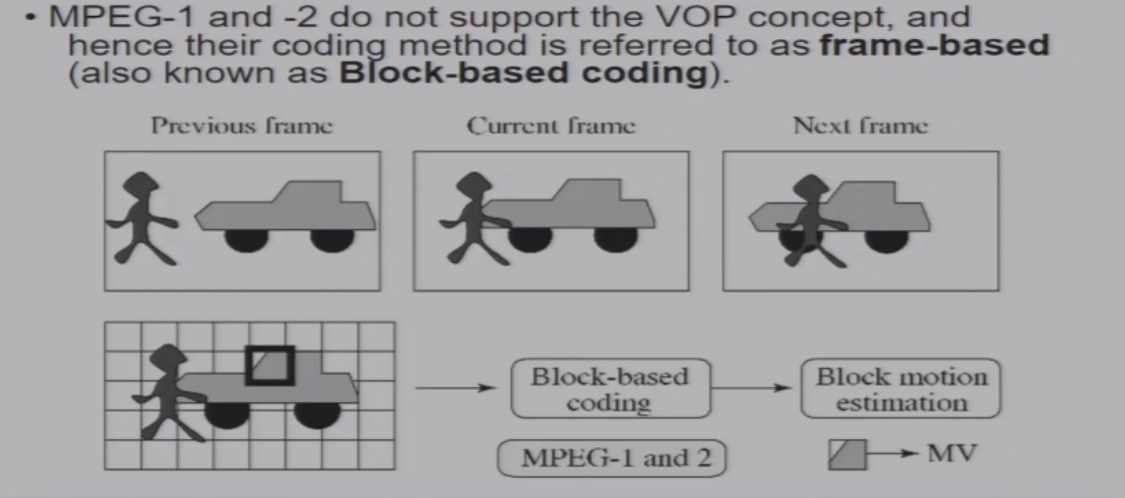
MPEG-4:首先将帧分为Object,然后对不同的Object序列进行编码
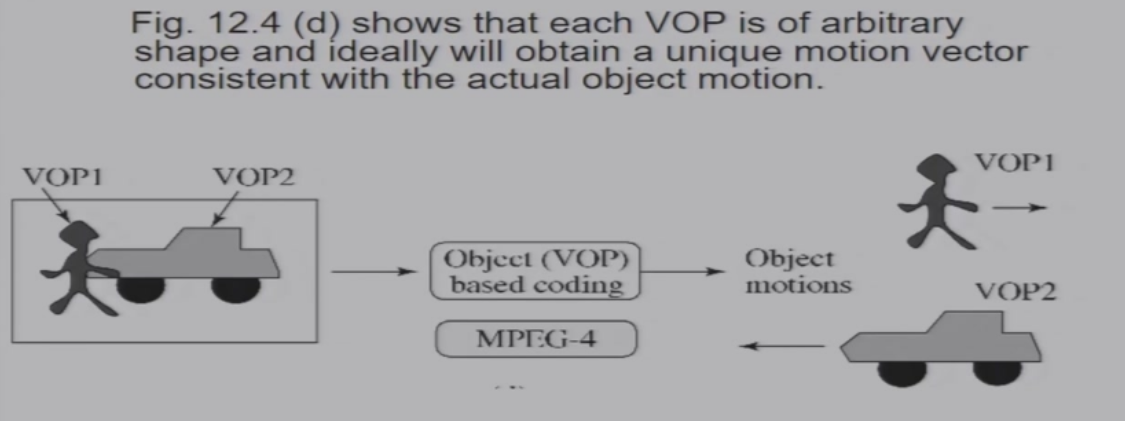
11.1.2.2 VOP-Based Coding
依旧是使用运动向量估计的方法,进行压缩
- 运动估计
- 基于运动向量的预测
- 对残差进行编码
也有I帧、P帧、B帧的概念
VOP会有不同的形状,最好对于形状和纹理分别编码
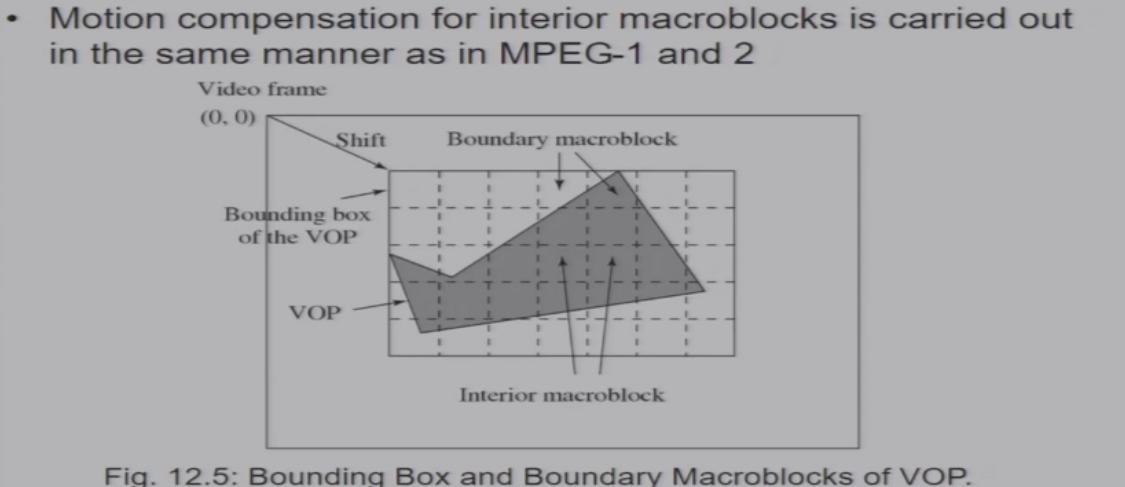
使用宏块将框出对象的包围盒
- 包围盒的大小一定是宏块的整数倍
- 内部宏块:完全在对象内部的宏块 ==> 直接进行编码
- 边缘宏块:一部分在对象内,一部分在对象外 ==> 存在没有定义的像素,需要进行padding
11.1.2.3 Motion Compensation
对于边缘宏块,在目标帧和参考帧之间,会存在没有定义的像素的预测,需要进行padding
- 即填充像素的值,使得边缘宏块填充完整
- 水平填充、垂直填充:对边缘像素进行延申

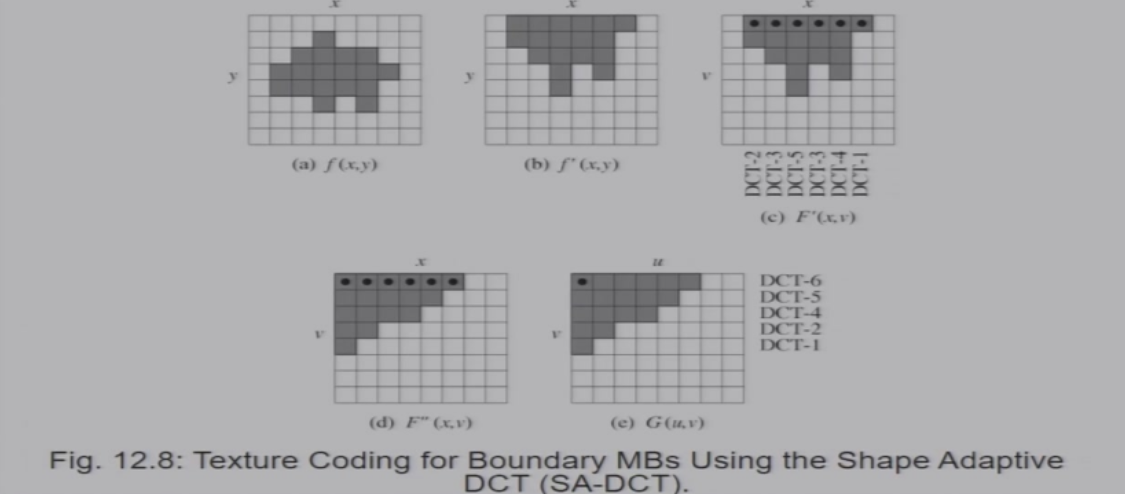
11.1.2.4 纹理编码
I-VOP:和JPEG的编码相同
P-VOP、B-VOP:需要进行编码
SA-DCT变换:
- 先将图像推到上面,然后对每一列进行DCT变换
- 然后将图像推导左边,然后对每一行进行DCT变换
11.1.2.5 形状编码
- 恢复原图像时,仅有纹理信息是不够的,还需要有形状信息:
- 对形状也进行DCT变换,记录下来
- 二元编码 Binary Shape coding
- 灰度编码 gray scale coding
11.1.2.6 静态纹理压缩 Static Texture Coding
- 使用小波变换进行编码
11.1.2.7 动态编码 Sprite Coding
- 可以将图像分为背景+运动物体的合成
- 对背景、运动物体分别处理
- 背景:将大背景全部传过去,在每一帧时,修正相机的姿态,选取对应的位置
- 运动物体:正常编码
- 每一帧,将选中的背景与运动物体合成到一起
11.1.3 动态物体编码
先将整个形象传过去,然后只需要传输人物的姿态变化
- 第一帧:对角色进行网格剖分
- 之后每一帧:传输运动信息

十二、基于内容的多媒体检索
12.1 CBMR:基于内容的多媒体检索
- 用于检索到各种类型的多媒体数据
- 包含图像、视频、音频、物理等
- 基于物理内容、语义内容,而不是字符串匹配
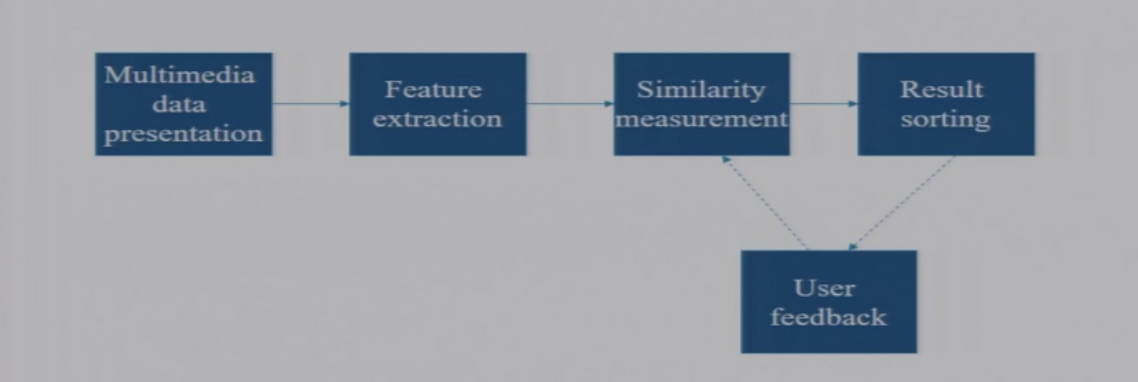
CBMR的基础方法
- 对多媒体数据进行表示
- 特称抽取
- 相似度匹配
- 结果排序
- 用户反馈
12.2 CBIR:基于内容的图像检索
给定一个查询图像,返回与之相似的图像
- 由于图像的尺寸不同,因此需要提取图像的有效特征features
- 基于抽象特征,做索引
- 定义两个特征的相似度评价
语义鸿沟 Semantic Gap
- 如何让计算机理解图像/视频的内容
- 如何判断高维图像和低维语义之间的关系
12.2.1 特征
用内容特征表示图像
颜色
形状

纹理
12.2.2 相似度计算
用向量表示特征
- 图像1:\(I = [f_{11}\ f_{12}\ ...\ f_{1n}]\)
- 图像2:\(Q = [f_{21}\ f_{22}\ ...\ f_{2n}]\)
- 相似度/距离函数:
- \(D_1=\sum_{i=1}^{n}|I_i - Q_i|\)
- \(D_1=\sum_{i=1}^{n}(I_i - Q_i)^2\)
- 还可以计算两个向量的夹角、距离等等
12.3 3DMR
12.3.1 特征提取
- 基于几何的方法
- 提取形状
- 提取拓扑结构
- 将模型投影为图像
- 从不同角度进行拍照(形状采样),然后编号
- 穷举对应顺序,取最小的作为相似度(取平均也可以)
- 也可以先分析重心,找到主轴,让主轴的方向相同,然后再拍照
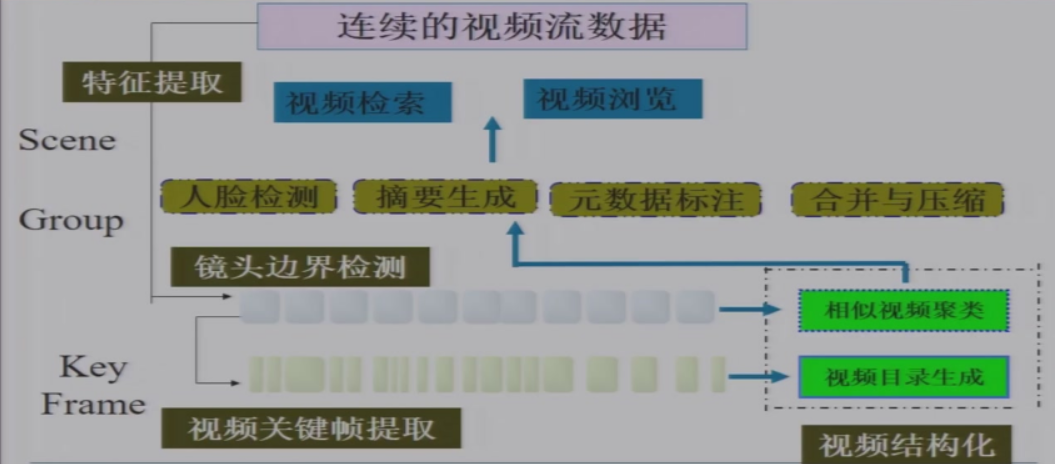
十三、视频结构化
13.1 视频结构
13.1.1 概念
- 帧Frame:视频流中的基本组成单元
- 物理上的最小单元
- 每一帧均可看成一个独立的图像
- 视频流数据就是由连续图像帧构成的
- 关键帧Key Frame:用来代表镜头内容的图像
- 从一个镜头包含的帧中抽取一部分帧,代表这个镜头的内容
- 镜头Shot:摄像机拍下的不间断帧序列
- 逻辑上的最小单元
- 是视频数据流进一步结构化的基础结构层
- 在同一组镜头中,属于同一组镜头的图像帧之间的特征保持稳定,如果相邻图像帧之间的特征发生了明显变化,认为发生了镜头变化,需要对视频数据进行切分
- 组Group:介于物理镜头和语义场景之间的结构
- 例如:一段采访录像,镜头在主持人与被采访者之间频繁切换,整个采访属于一个场景,而那些关于主持人的所有镜头属于一组,关于被采访者的所有镜头属于另一组
- 场景Scecne:语义上相关和时间上相邻的若干组镜头组成了一个场景
- 场景是视频所蕴含的高层抽象概念和语义表达
- 场景可以使用属于这个场景的若干个镜头所对应的关键帧来表示
- 视频Video
13.1.2 视频结构化的任务
- 划分镜头
- 分组
- 构成场景
13.2 镜头检测
问题定义:给定一个视频V包含n个镜头,找到每个镜头的起始和结束
- 也被称为 边界检测boundary detection 或 过渡检测transition detection
13.2.1 镜头的分类
- Hard cuts:硬切,直接在两个镜头之间切换
- Fades:前一个镜头淡出,下一个镜头淡入
- Dissolves:上一个镜头淡出的同时,下一个镜头淡入,两个镜头之间会叠加起来
- Wipe:其他花样切换方式
13.2.2 特征提取
每次计算相邻两帧的特征差\(\Delta=f(t+1)-f(t)\),如果发生跳变\(\Delta>T(k)\),则说明发生了镜头切换
- 特征:可以是每一帧的直方图,彩色图像可以转化为灰度图像然后再计算直方图
13.2.3 镜头边缘检测算法
实质:
- 找到一种或几种良好的视频图像特征
- 然后基于这样的特征定义,计算其相似度函数
- 确定阈值
13.2.3.1 绝对帧间差法
- 判断相邻图像帧之间特征的绝对差是否大
- 具体特征:某一帧中所有像素的色彩亮度之和
13.2.3.2 图像像素差法
- 判断相邻图像帧中像素点发生变化的多少
- 缺点:对镜头移动十分明暗,对噪声的容错性较差
13.2.3.3 颜色直方图法
- 将图像转化为灰度图像,然后计算归一化后的颜色直方图
- 判断特征差
- \(d(f,f')=\sum_{j=0}^{N}|H(f,j)-H(f',j)|\)
- 也可以是带权直方图、两个特征向量的夹角
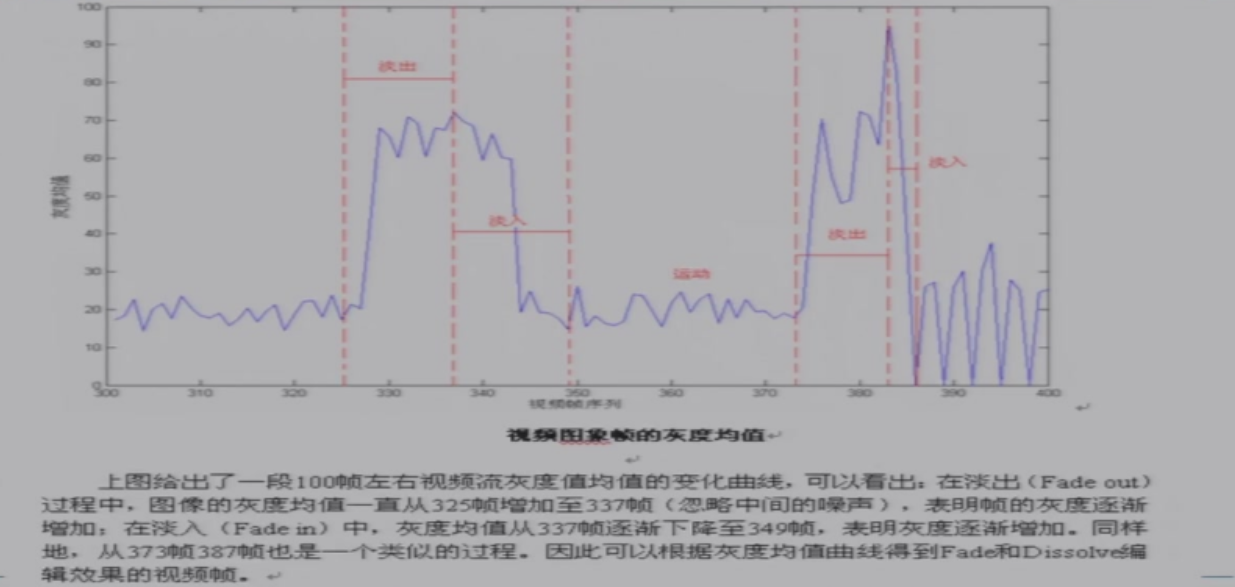
13.2.4 渐变镜头的数学模型


灰度均值:开口向下的抛物线
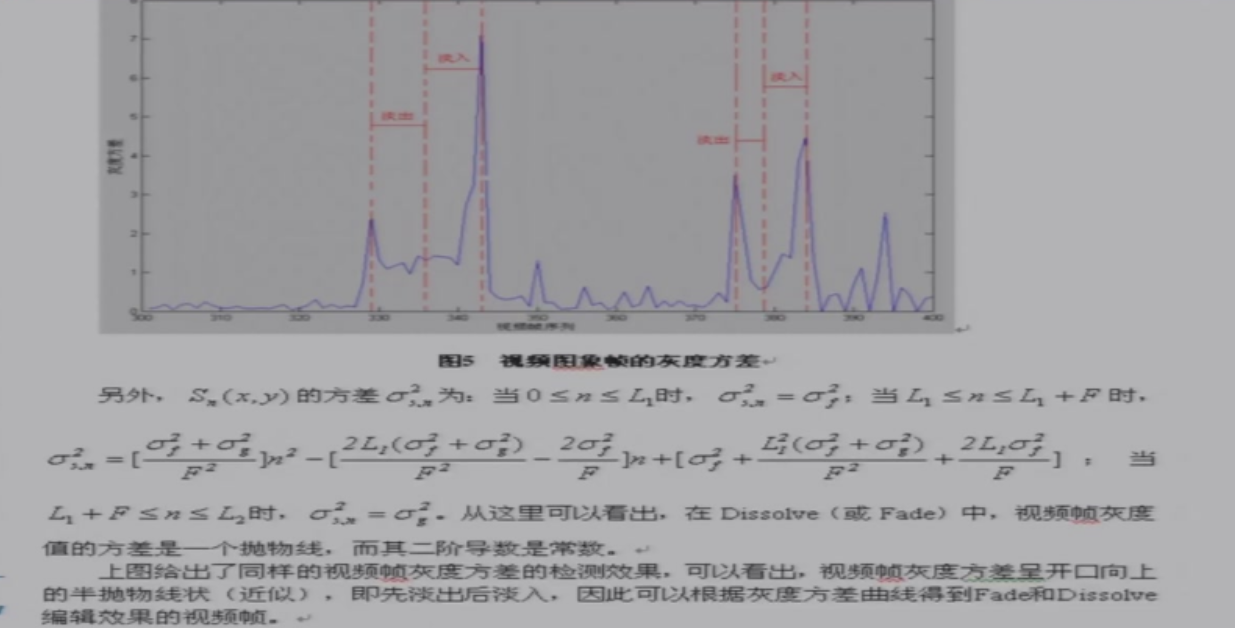
灰度方差:开口向上的抛物线
13.3 关键帧抽取
- 视频数据流中的图像帧之间存在空间和时间冗余度
- 可以从视频中找到一些代表性的帧,用这些少量的帧来代表冗长的视频数据流,使用户看过关键帧后,就能知道整个视频数据流所蕴含的内容,再通过提取这些帧的底层信息来建立索引,方便用户对视频内容查询
13.3.1 镜头边界法
- 将镜头中的第一幅图像和最后一幅图像作为镜头关键帧
- 每个镜头的关键帧只能有2个关键帧
13.3.2 基于特征转变法
- 将镜头当前帧与之前判断的最后一个关键帧作比较,如果差异较大,则作为新的关键帧
13.3.3 基于运动分析法
- 如果两个帧的重叠部分小于某个阈值,则将后一帧作为新的关键帧
13.3.4 基于聚类的关键帧提取
- K平均聚类方法,聚类之后,从每一类中选择一个帧作为关键帧