自然语言处理导论
一、全连接前馈神经网络 FCFN
全连接前馈网络:Fully Connect Feedforward Network
1.1 机器学习 => 寻找目标函数
给定一个函数的集合,机器学习实际上就是找到这个集合中的一个函数,能够符合预期要求
训练数据:相当于一套卷子,通过做这套卷子的得分,判断哪个函数更好
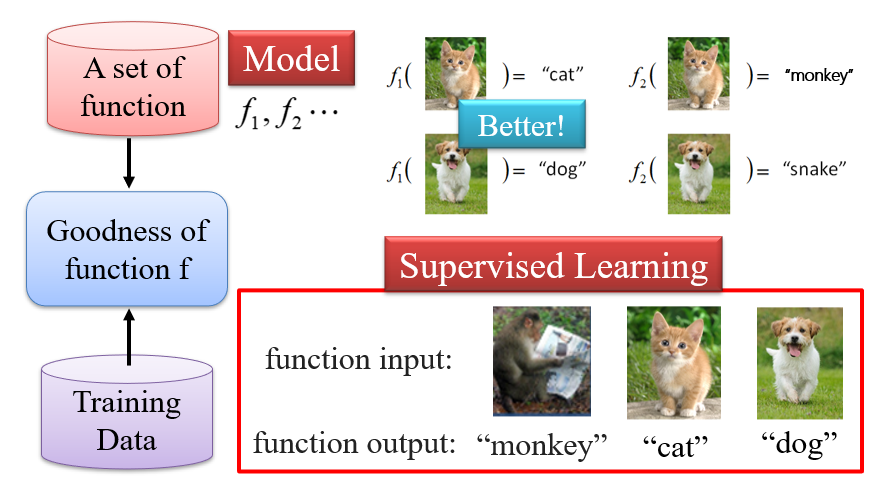
推理Testing:找到给定的函数后,对于其他的输入,期望得到目标输出,也就是泛化
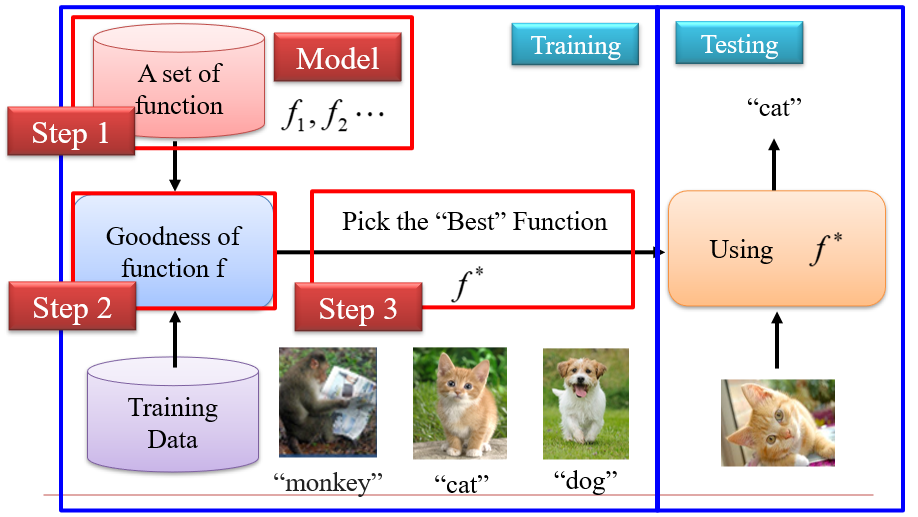
机器学习的三个步骤:
- 定义函数集合
- 设计评价函数(损失函数):函数=>得分
- 找到最优函数
神经网络 Neural Network:即为一种定义函数集合的方式
1.2 神经网络:定义函数集合
1.2.1 神经元 Neuron
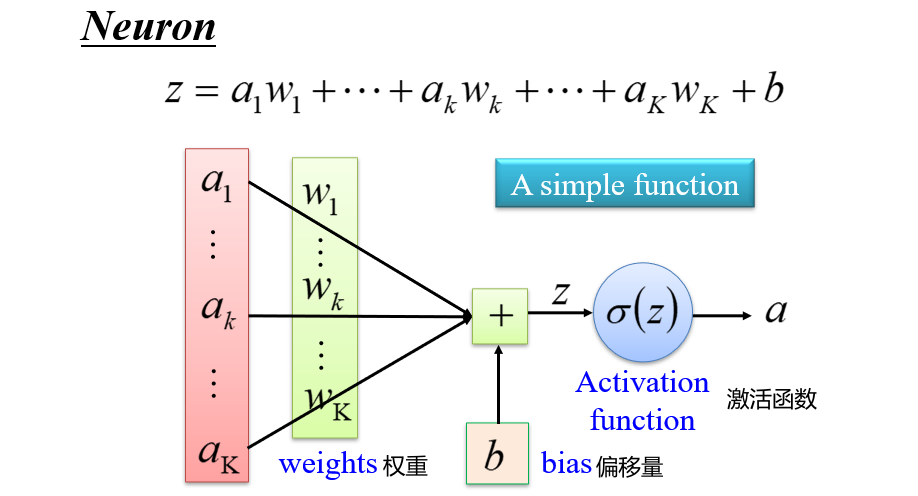
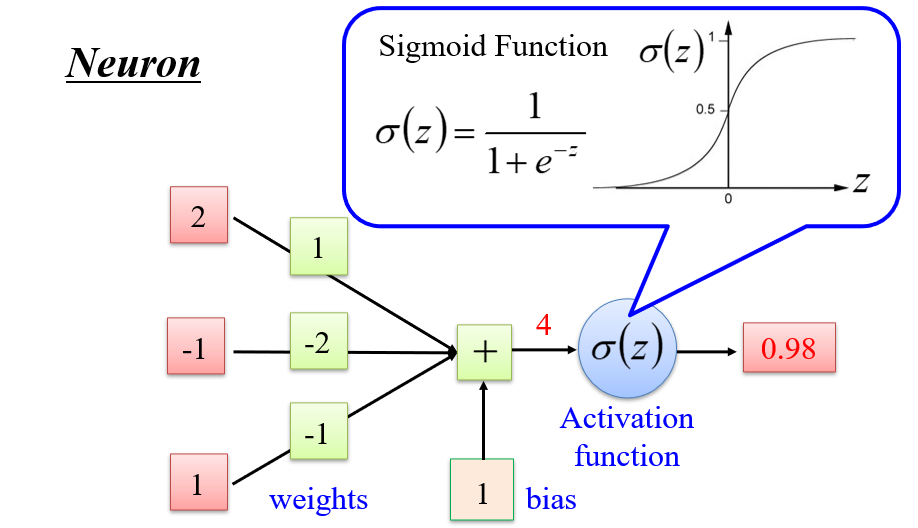
- Sigmoid函数:用于门控,当输入大到某一个值后,输出为最大值
- 是一个归一化函数,将一个比较大的值,变成一个小的值
- 神经元函数:\(\sigma(z)=\sigma(a_1w_1+a_2w_2+...+a_kw_k+b)=\sigma(\vec
a · \vec w)\)
- 输入\(\vec a\)与权重\(\vec w\)越接近,输出越大
- 因此类似于一次
if操作,只不过if的判断条件是学习出来的
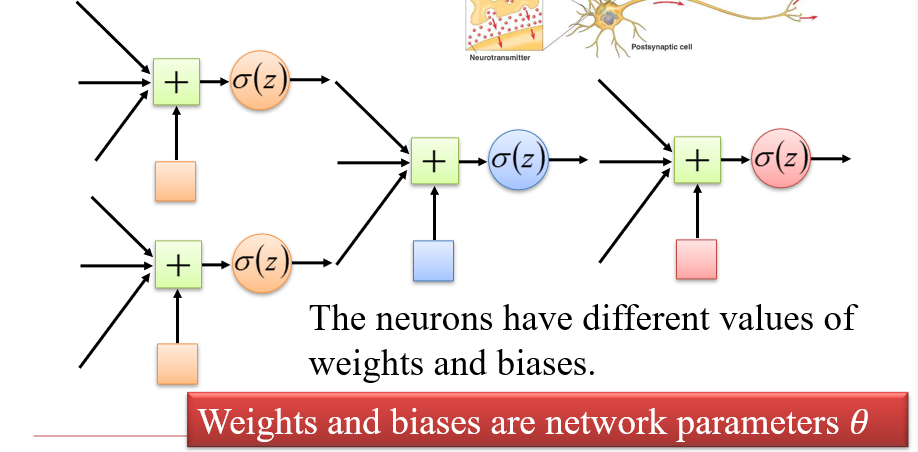
1.2.2 神经网络
将多个神经元相连,组成一个神经网络
- 神经网络的参数
θ:即为所有神经元的全部weights和bias
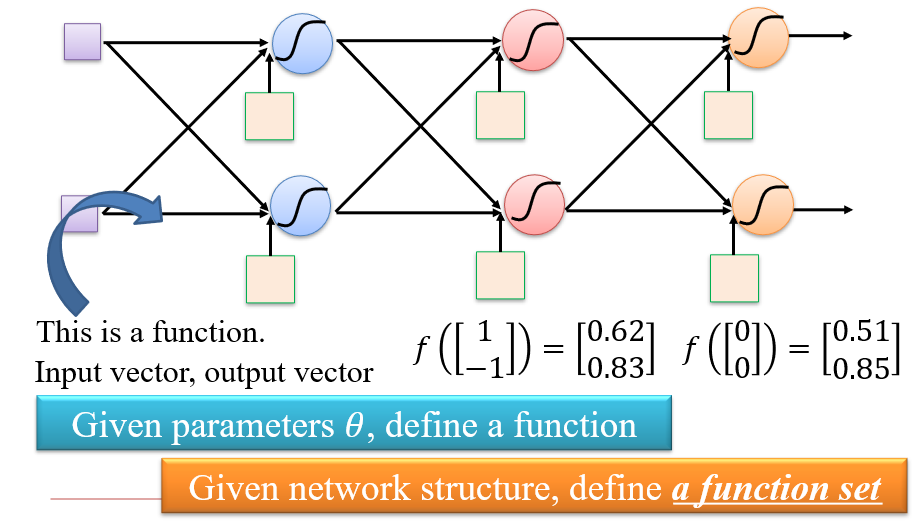
1.2.3 全连接前馈网络 FCFN
Fully Connect Feedforward Network
前一层所有神经元的输出,会输入到后一层的所有神经元上
- 当参数一定时,就是一个确定函数
- 定义了神经网络的结构,也就定义了一个函数集合
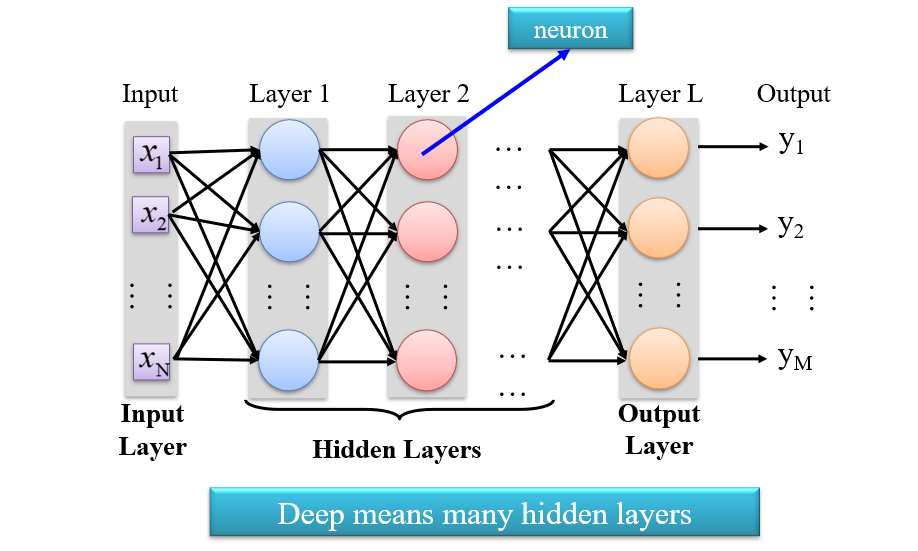
1.2.4 深度学习
FCFN一般分为三个部分:输入层、隐藏层、输出层
- 深度学习:有多个隐藏层
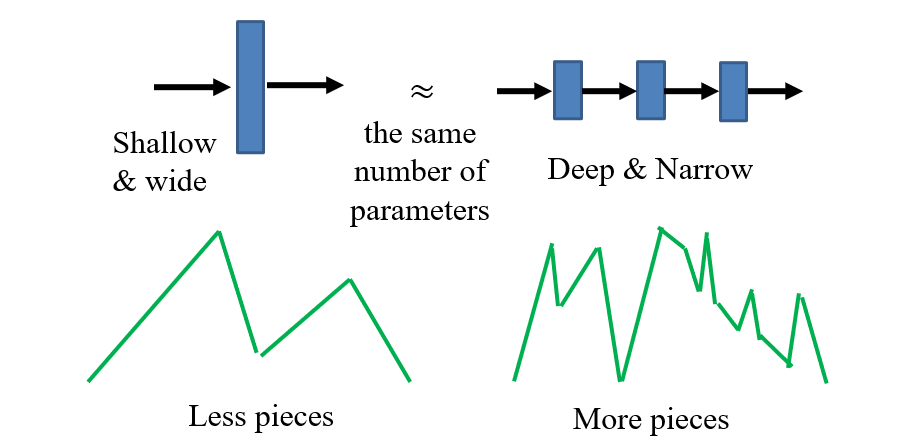
1.2.5 为什么需要深度
- 现在的激活函数:达到阈值后,输出=输入;相当于用多条直线拟合函数图像
- 在参数量相同时,层数越多,拟合能力越强
1.3 设计评价函数
1.3.1 训练数据
训练数据:
- 准备图像及其标签
- 学习目标被定义在训练数据中
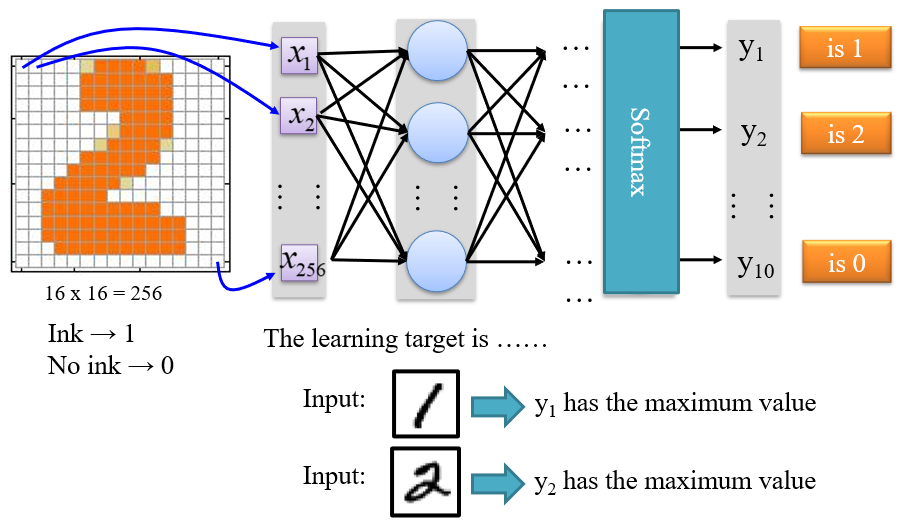
1.3.2 学习目标
- 输入层:将训练数据转化为一维向量
- 输出层:根据目标定义
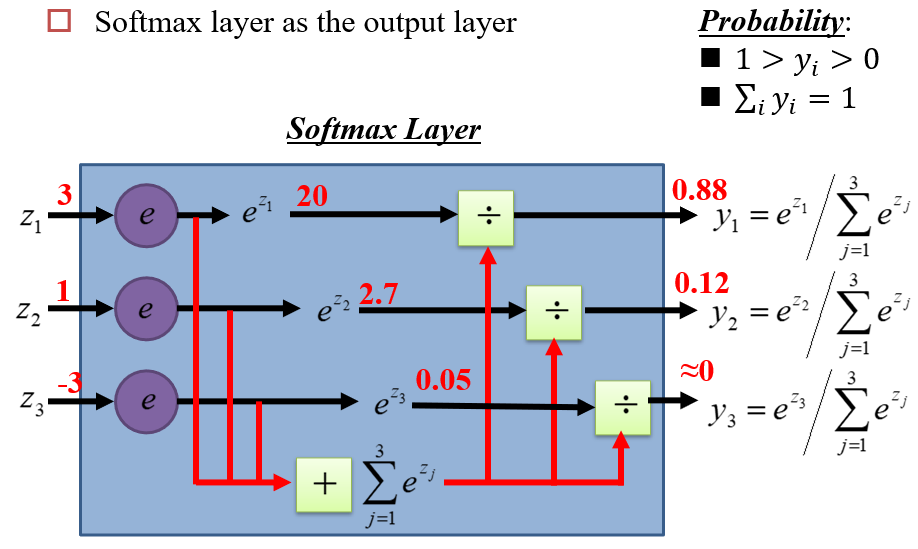
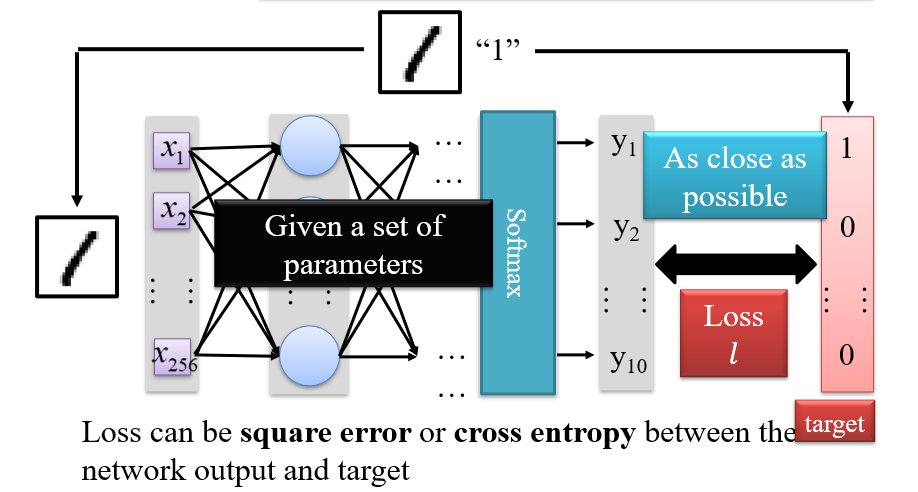
1.3.3 输出层
使用Softmax作为输出层
- 不用max函数,是因为max函数不可导
- 通过Softmax层后,输入的差距会变得更大
1.3.4 损失
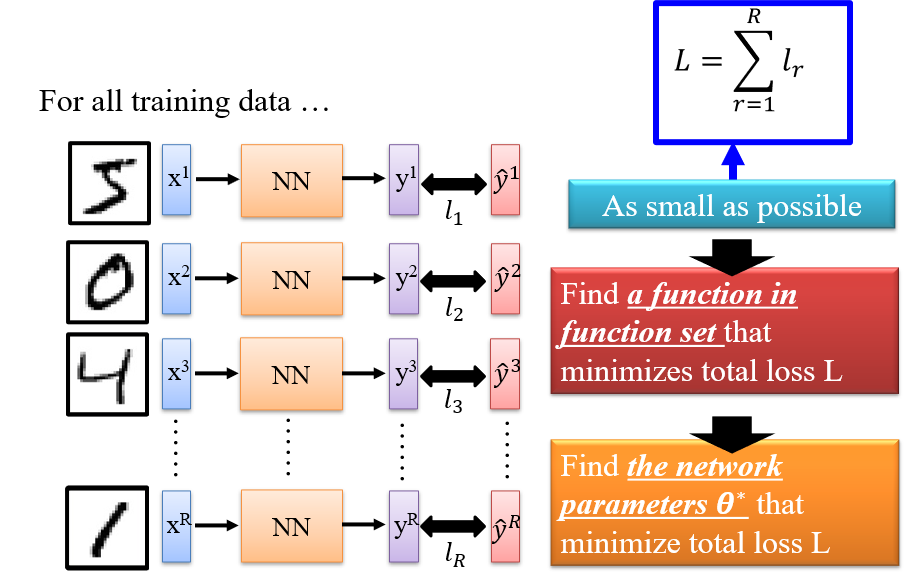
1.3.5 总损失
- 参数确定后,神经网络确定,对于所有输入的输出就一定,总损失
L就一定 - 因此
L是关于参数θ的函数
1.4 找到最优函数
1.4.1 Gradient Descent 梯度下降
L是关于θ的函数,因此可以得到一条L-θ的图像(θ是一个高维变量)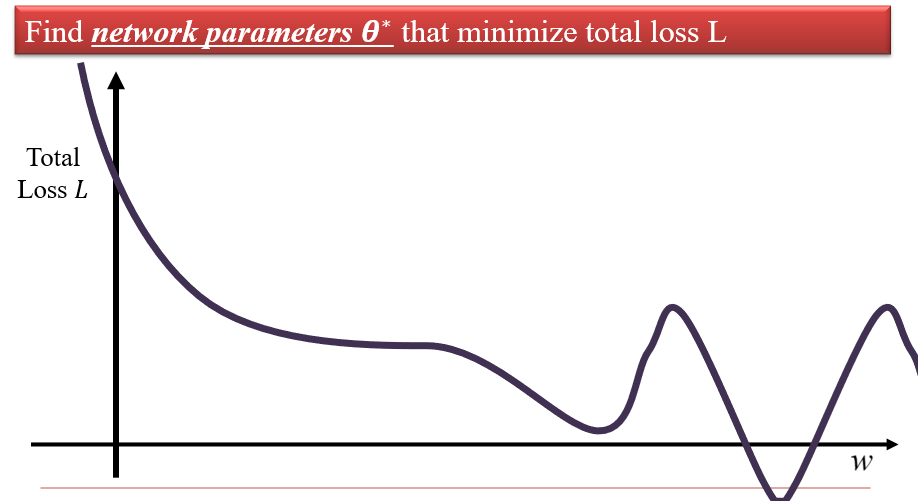
任务是找到一个令
L最小的θ值:求导,但是由于求导的要求过高,因此会求\(\frac{∂L}{∂w}\)- 随机选择
w的一个起始值 - 计算
L关于w的偏导 - 将
w的值更改为\(w-η\frac{∂L}{∂w}\),η称为learning rate,会影响神经网络的训练效率 - 重复2、3,直到\(\frac{∂L}{∂w}\)足够小位置
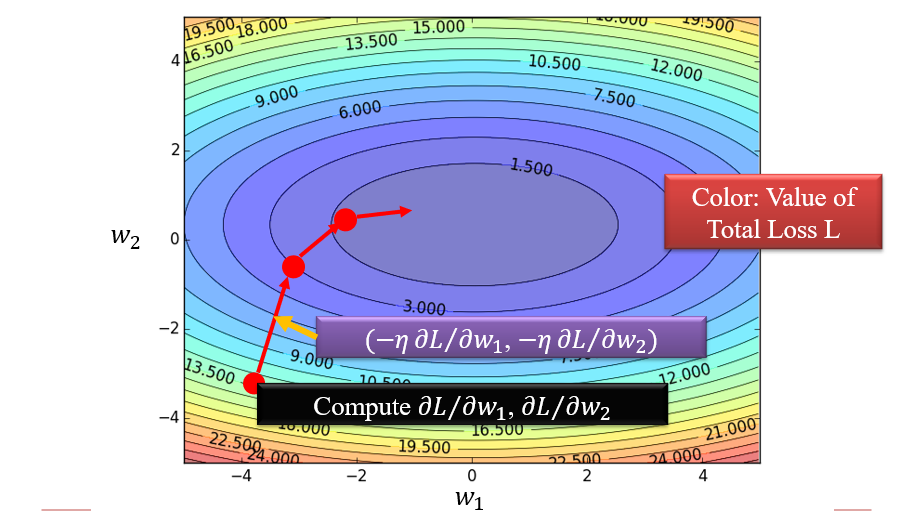
- 随机选择
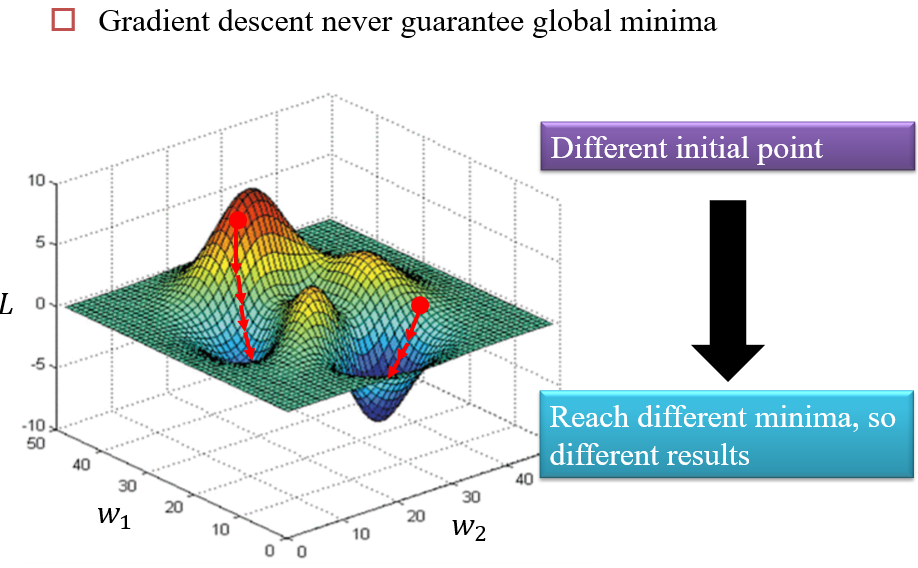
1.4.2 局部最小值
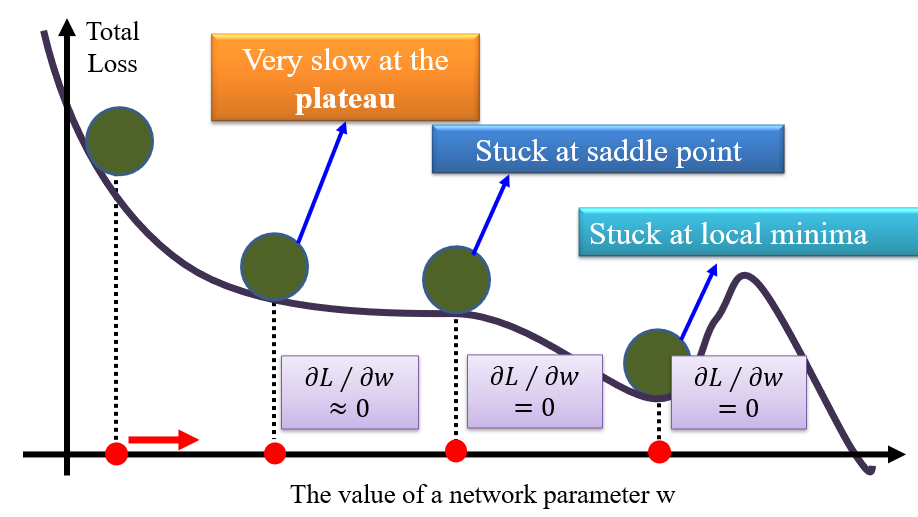
不同的初始点,会得到不同的局部最小值
1.4.3 Backpropagation
- 用于在神经网络中计算\(\frac{∂L}{∂w}\),在当下一般都是自动计算
二、词向量 Word Embeddings
Embedding:高维空间的低维结构
2.1 词语的表示
- 狄拉克函数
- 独热值 one-hot representation:
- 定义一个大向量,该向量对应一个词语
- 大向量的每个位置都表示一个单词,如果该单词出现,则对应位置为1,否则为0
- 缺点:
- 字典的大小要远大于单词的个数
- 单词与单词的独热值是正交的,无法表示同义词语

2.2 将词语降维
- 存储词语的含义,而不是词语本身
- 将相同意思的不同词语,映射到同一个语义上
- 利用几个基础语义,重建词语本身

2.3 词向量 word2vec
通过上下文,确定某个单词的含义
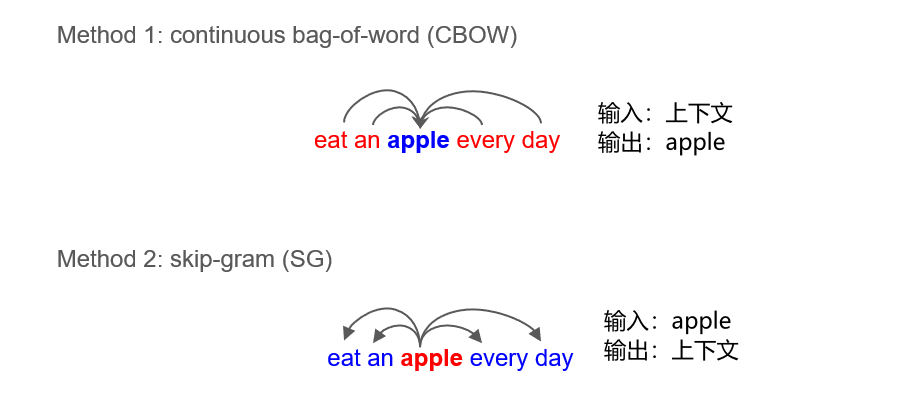
通过学习两个W矩阵,获得词向量
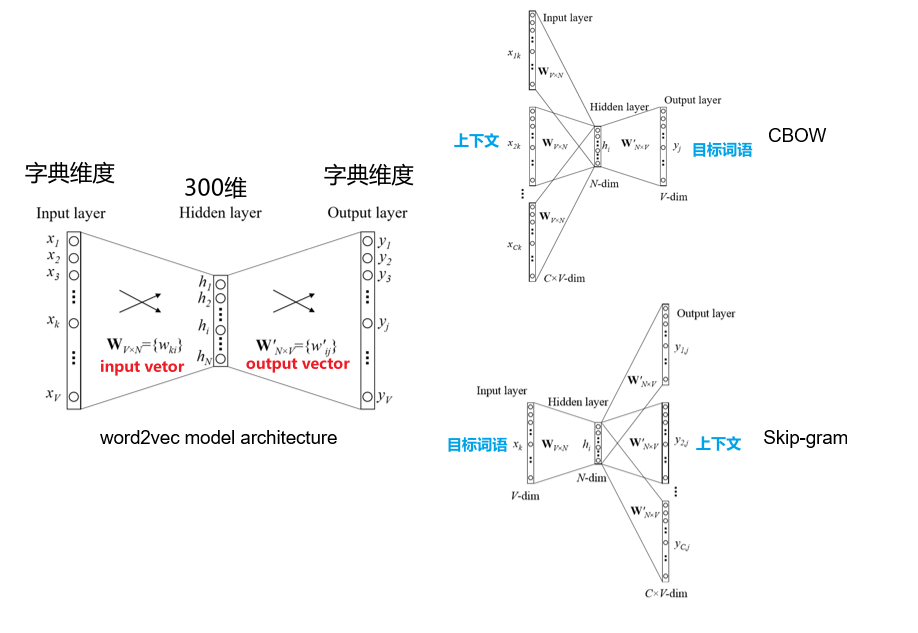
词向量:
input vector,左边矩阵中对应输入的一行
2.4 训练的过程:相当于是一个Softmax
- 训练的过程,相当于就是拉近输入与输出的距离
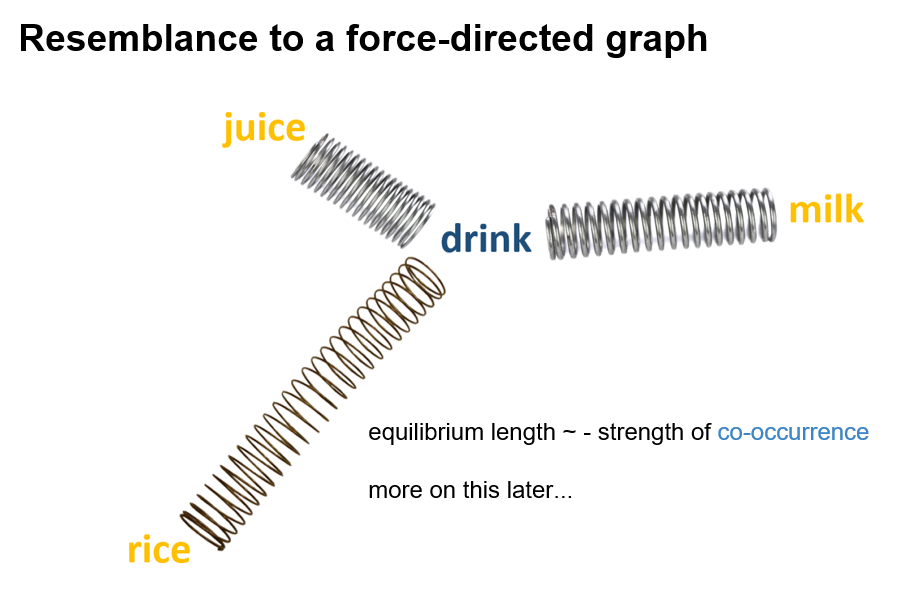
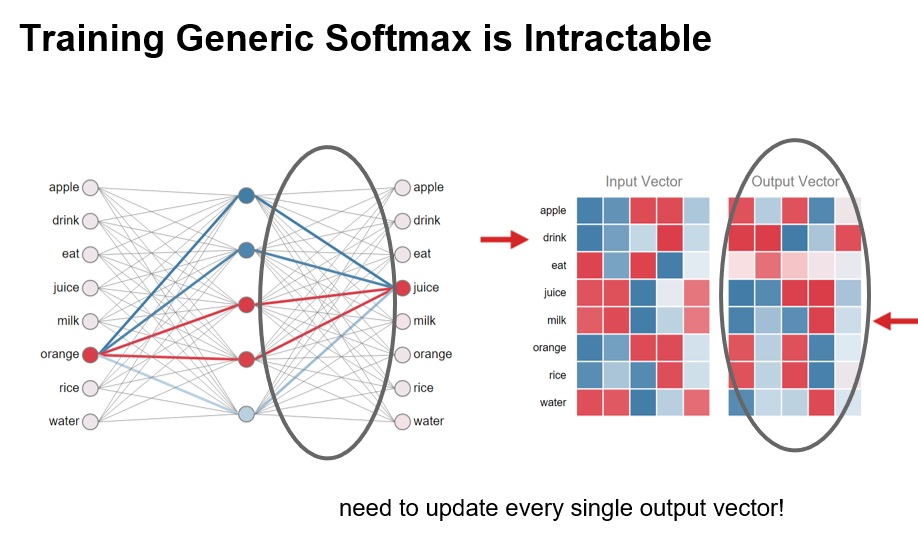
2.5 Hierarchical Softmax
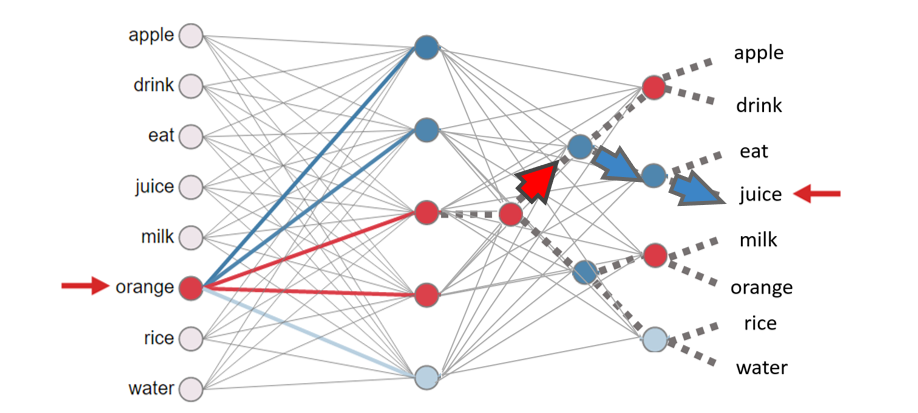
2.6 缺点
- 解决了多词一义,但不能解决一词多义
- 难以判断不同词向量的差异,如各种颜色的上下文基本相同
- 完全忽略了词语的顺序
三、卷积神经网络 CNN
卷积神经网络:Convolutional Neural Networks,常用于图形处理
3.1 为什么需要CNN
在图像识别中,特征点所在的位置在不同的图像中并不相同
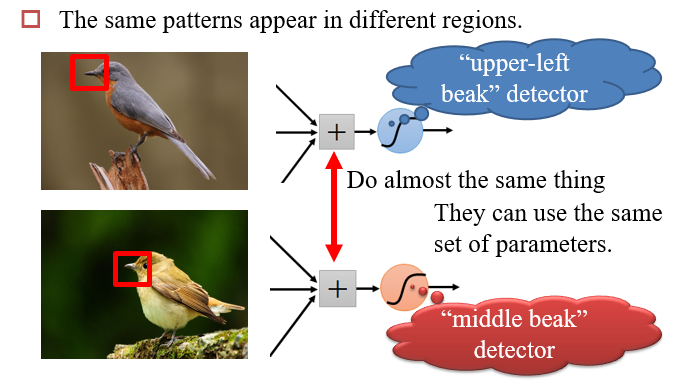
对图像进行下采样,并不影响我们对图像的判断

3.2 CNN的结构
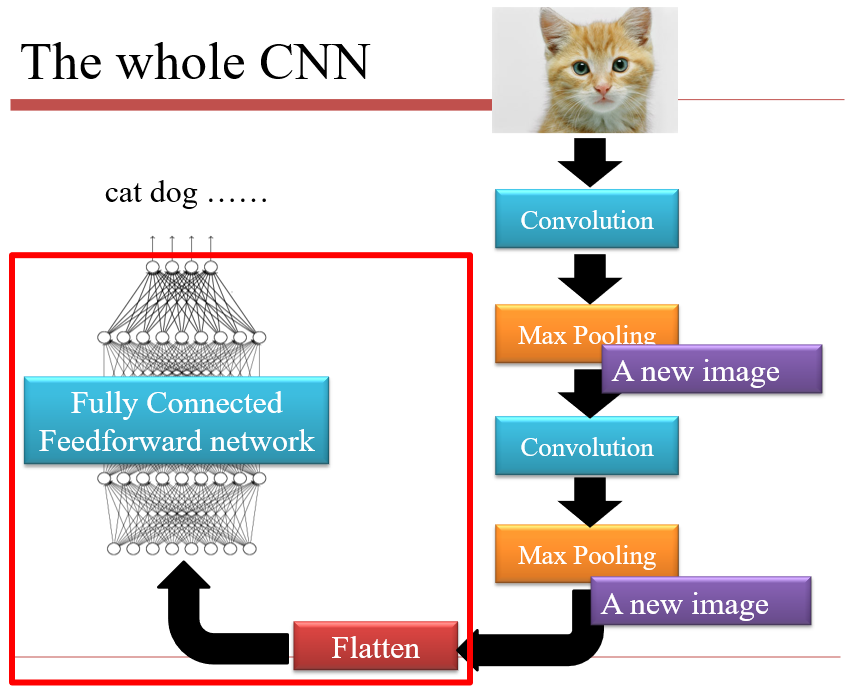
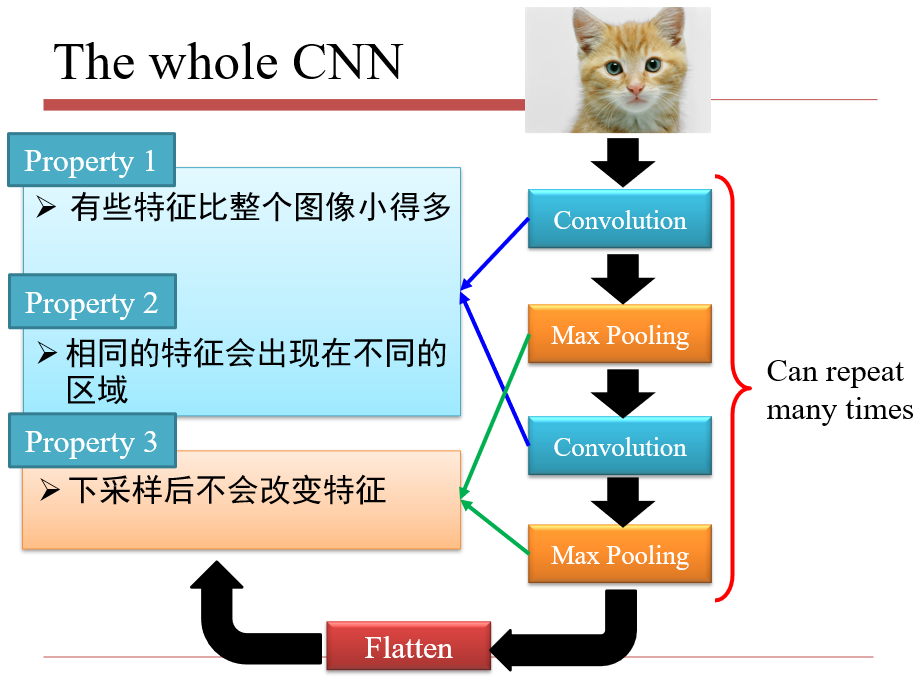
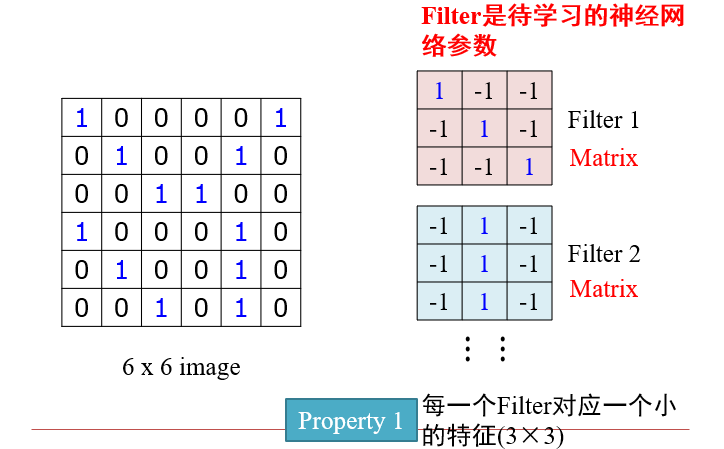
3.2.1 卷积 Convolution
卷积操作可以保持平移不变性:同一特征在不同位置均可检测出来
不能保持翻转不变性:将特征旋转/翻转后,就需要另一个卷积核了
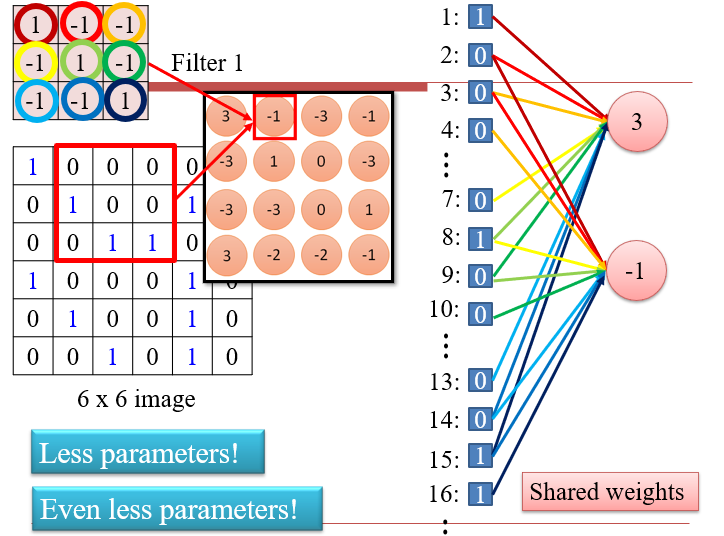
- 每一次的操作,都是两个大小相等的矩阵,逐位相乘再相加
- 与Filter的卷积,实质上是在大图像上,寻找与Filter相似的区域
- 图像的某个区域与Filter越相近,得到的值越大
- stride:每一次移动的长度
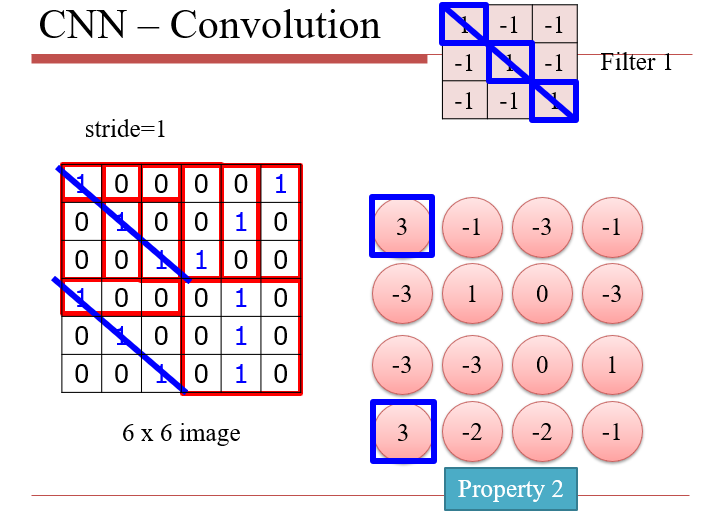
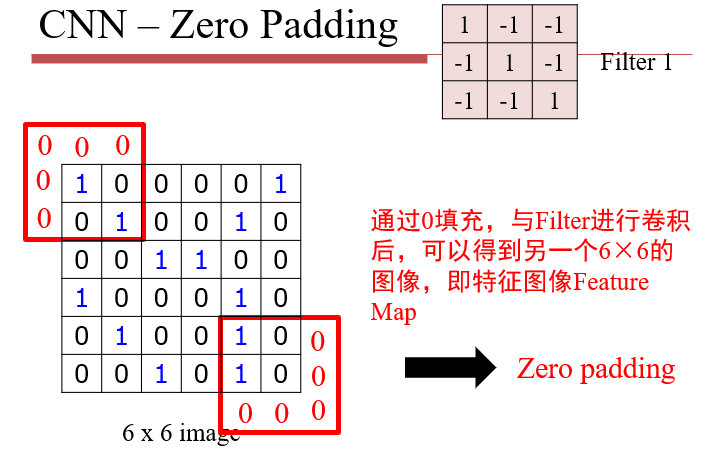
卷积与神经网络的联系:相当于只对图像的一个小区域进行检测,而不是全连接中的整个图像
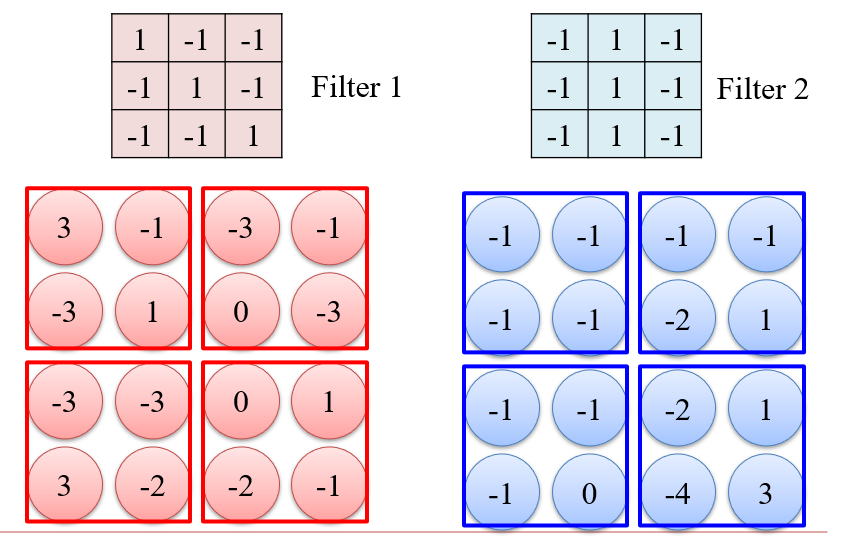
3.2.2 最大池化 Max Pooling
- 实质上就是对图像进行一次下采样,降低计算量
- 将卷积后的图像分为若干个不相交的区域,然后每个区域取最大值
- 最大池化:检测信号的强弱
- 平均池化:检测模式在某个区域是否比较普遍
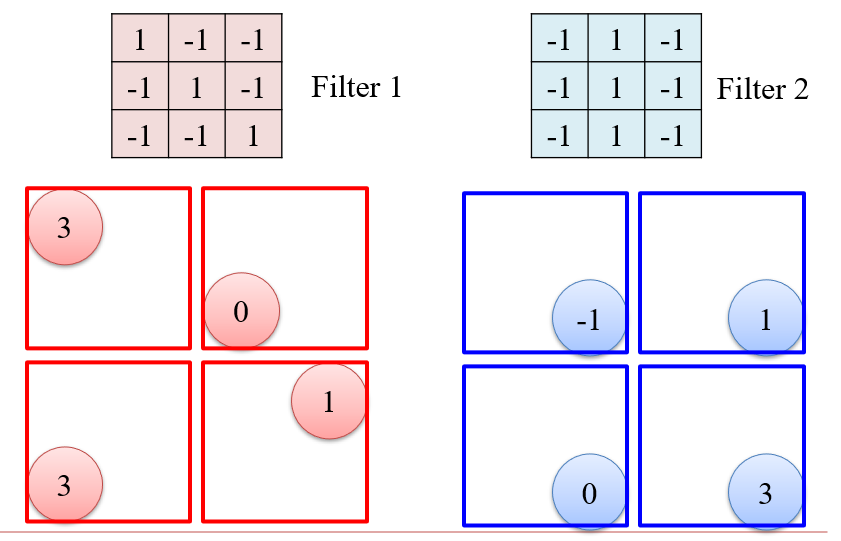
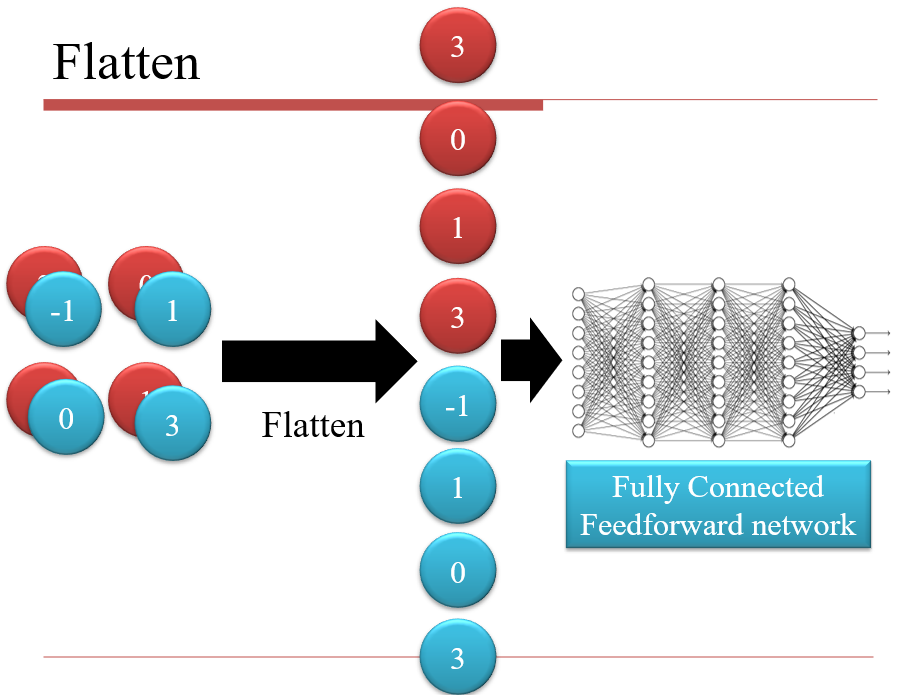
3.2.3 扁平化 Flatten
3.3 CNN变种
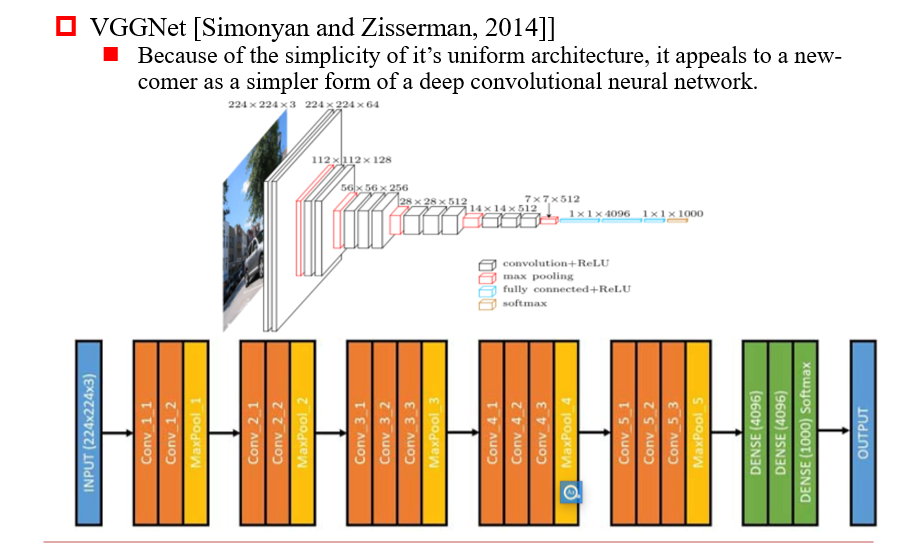
3.3.1 VGGNet
- 在CNN的基础上,变得更深了
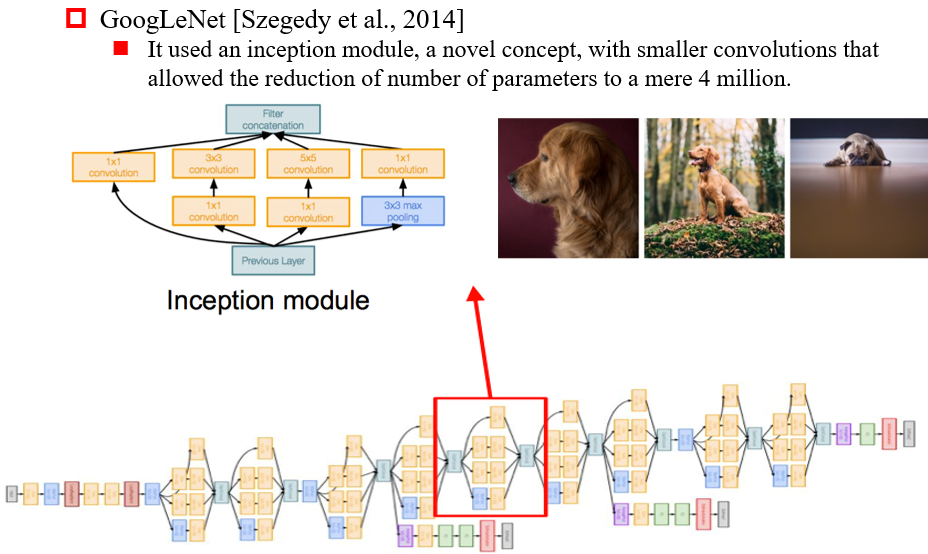
3.3.2 GoogLeNet(Inception)
增加网络的宽度:每一层有多种大小的卷积核
- 防止由于识别得过早,导致没有识别出特征
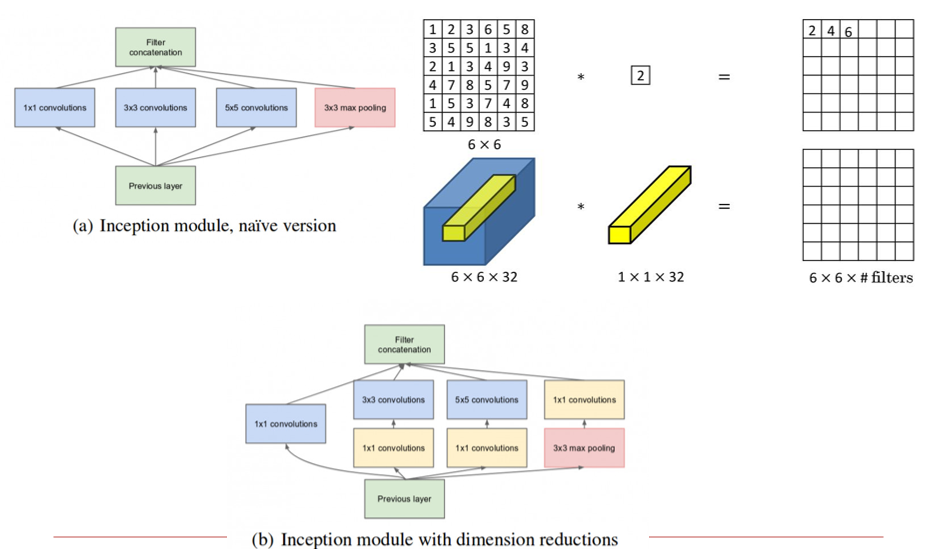
1×1卷积核:
- 将卷积核得到的多张图像,按照权重加和,得到一张图像
- 相当于进行了一次压缩
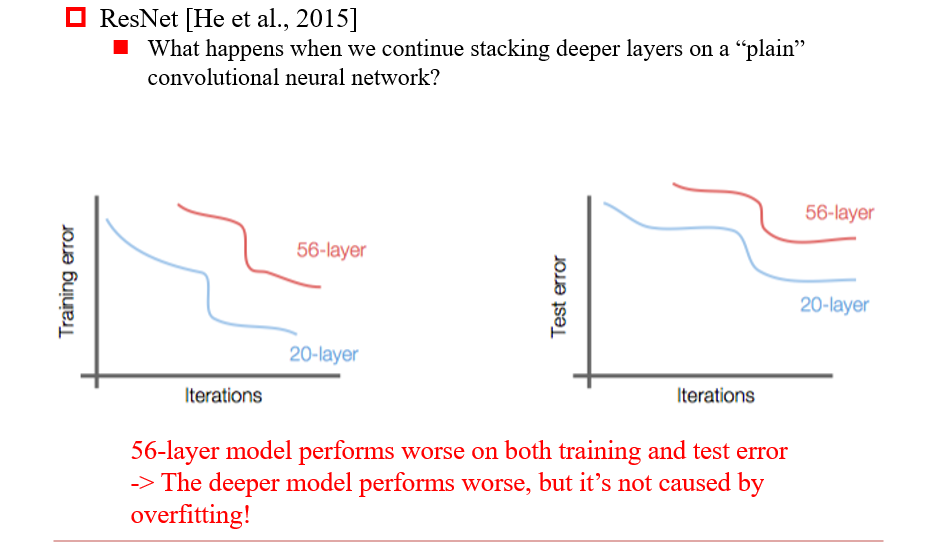
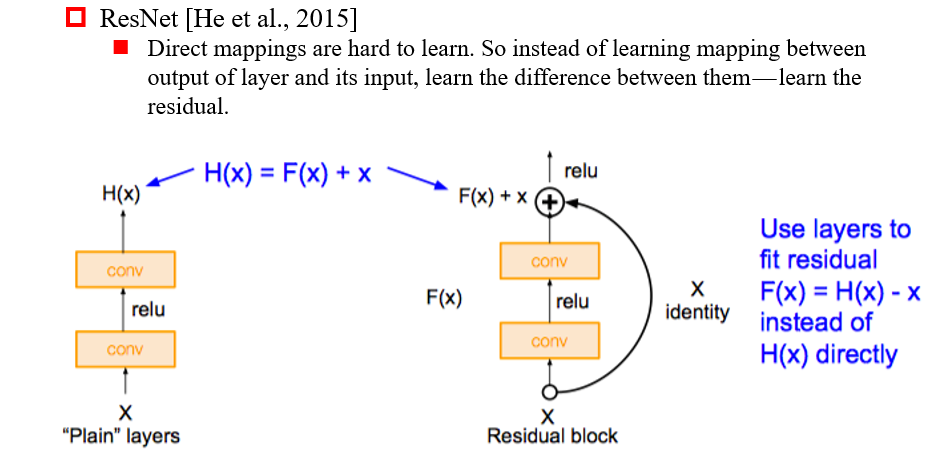
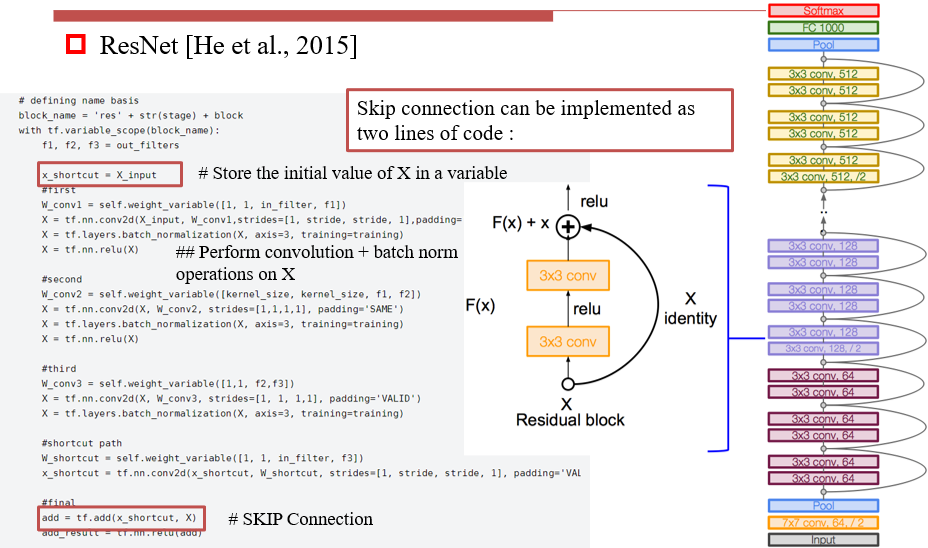
3.3.3 ResNet
- 添加了skip connection:将输入直接送到下一层,缓解了梯度消失的问题
3.4 Convolution
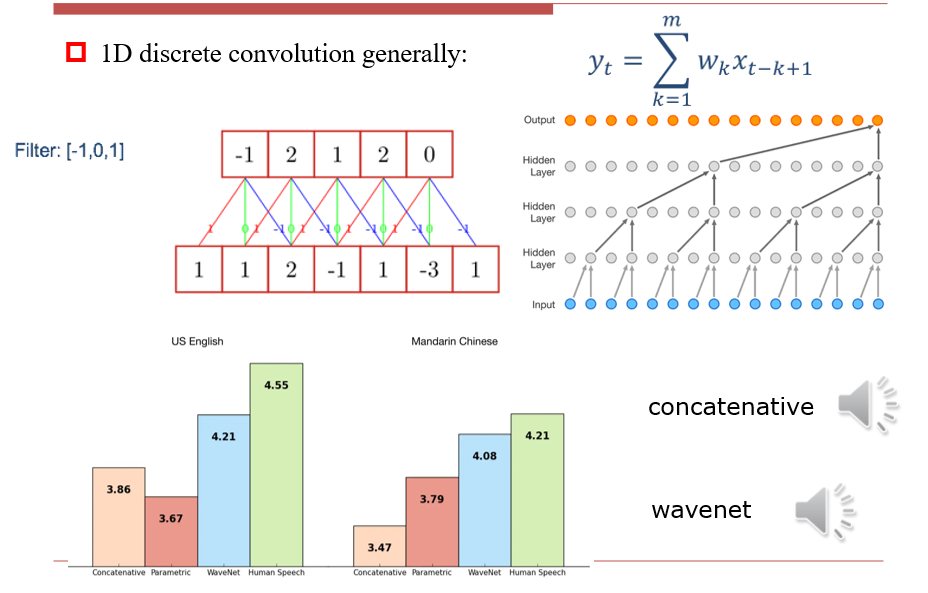
3.4.1 1D Convolution
- 本质上在做滑动窗口
3.4.2 2D Convolution
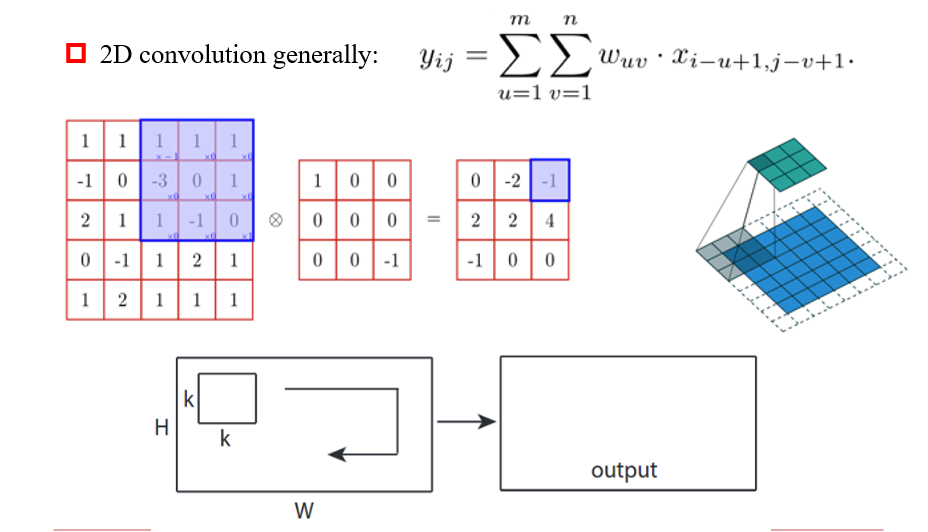
3.4.3 3D Convolution
将3D分为多个通道,每个通道进行2D Convolution
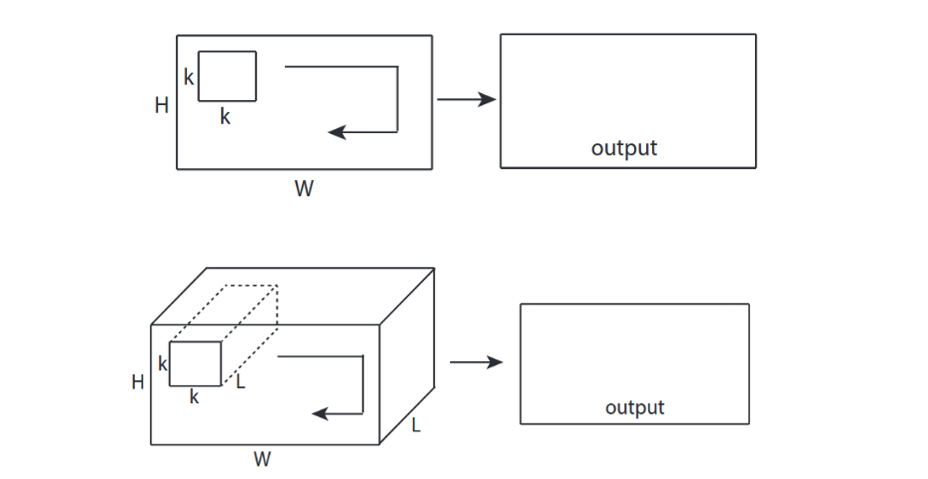
使用3D卷积核进行计算
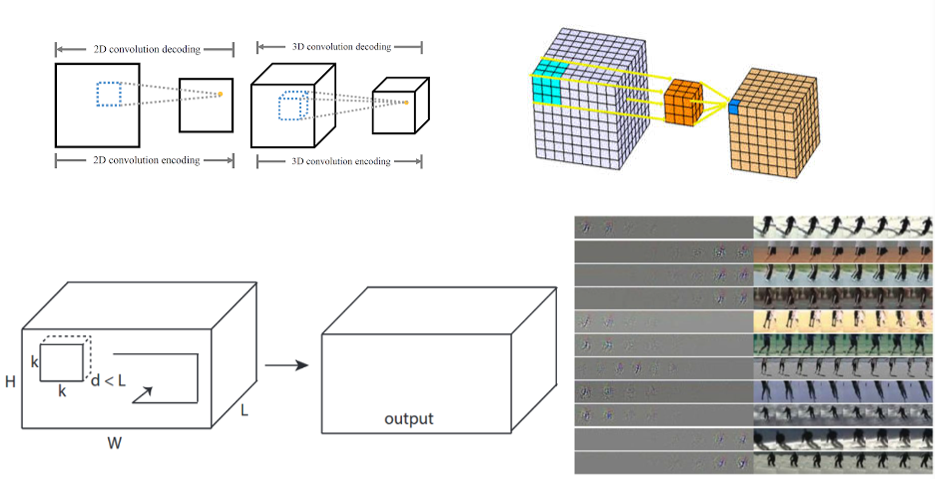
3.4.4 图卷积
3.4.5 球卷积
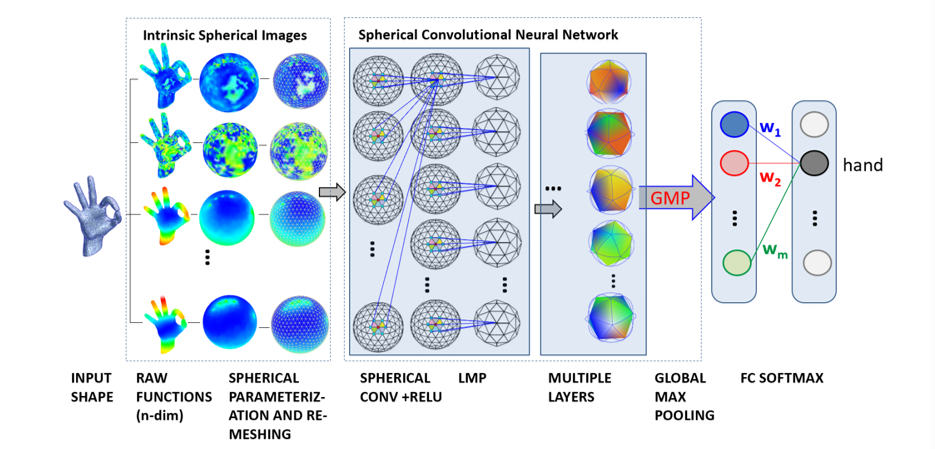
3.4.6 转置卷积/逆卷积
把小图像变大:上采样
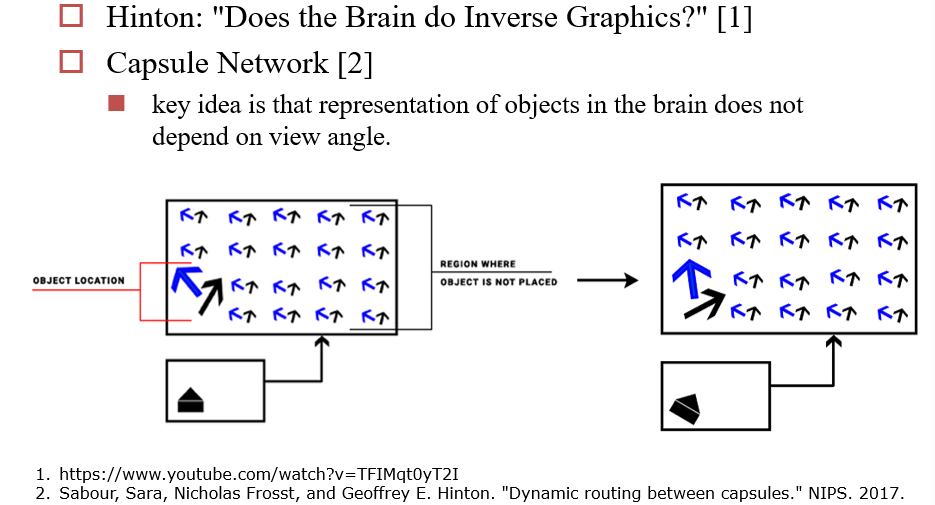
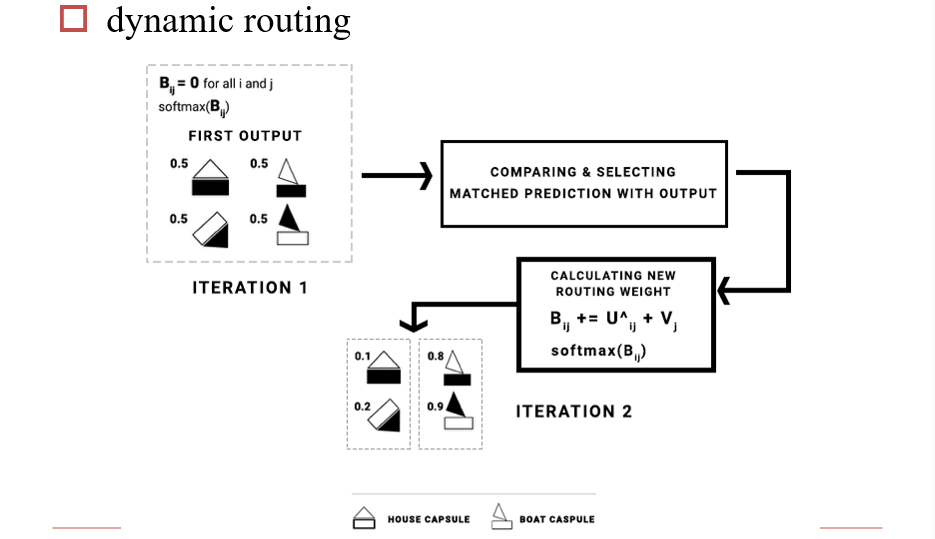
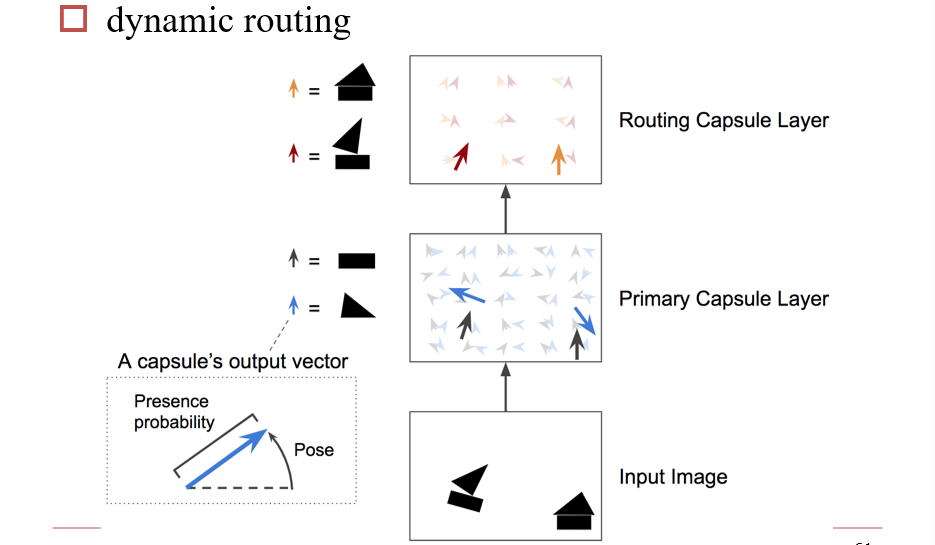
3.4.7 胶囊网络
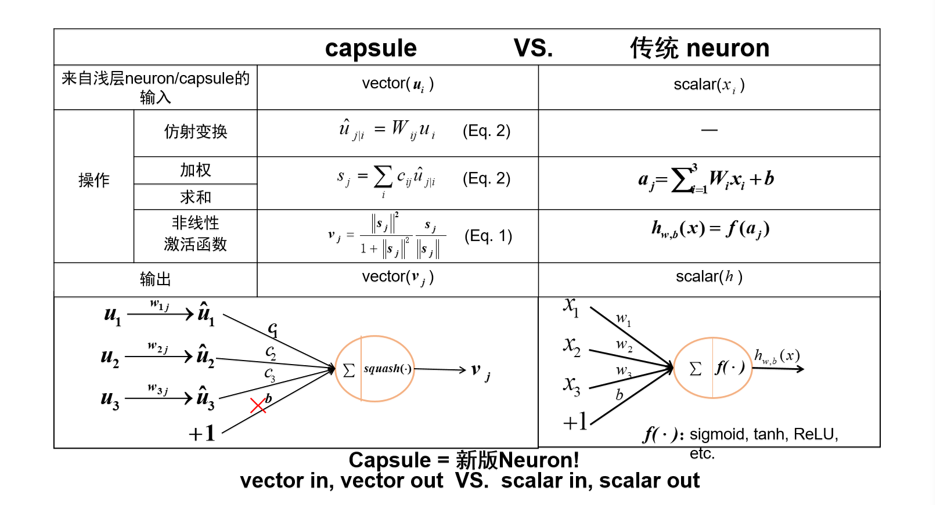
通过动态路由,在使用时仍要通过一定的规则,计算参数
3.5 NLP中的CNN
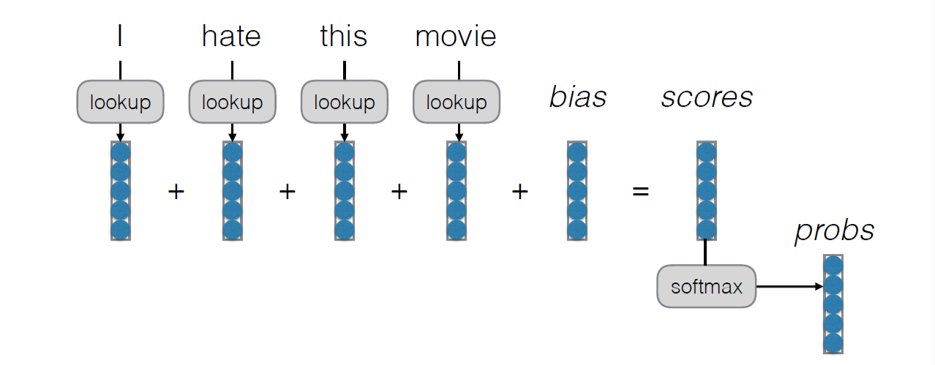
3.5.1 Bag of Words
- 识别一个句子
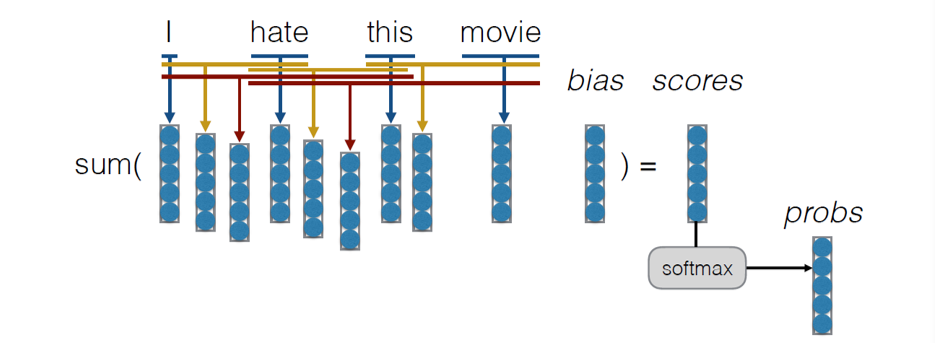
3.5.2 Bag of n-grams
- 将句子的语序也考虑进去
3.5.3 NLP中的CNN
3.5.3.1 Stride
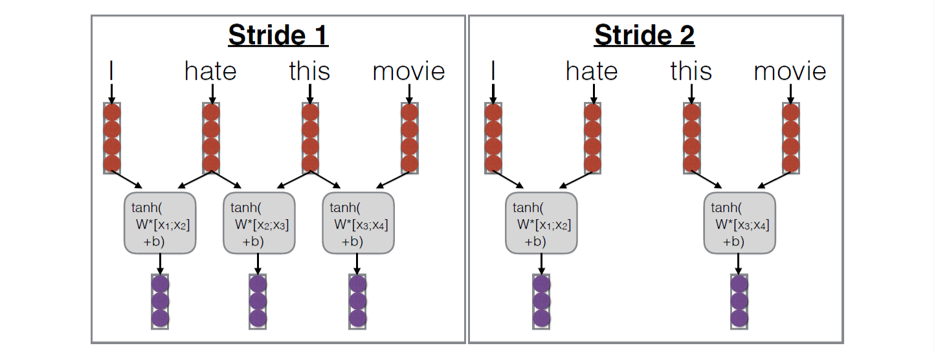
3.5.3.2 Pooling

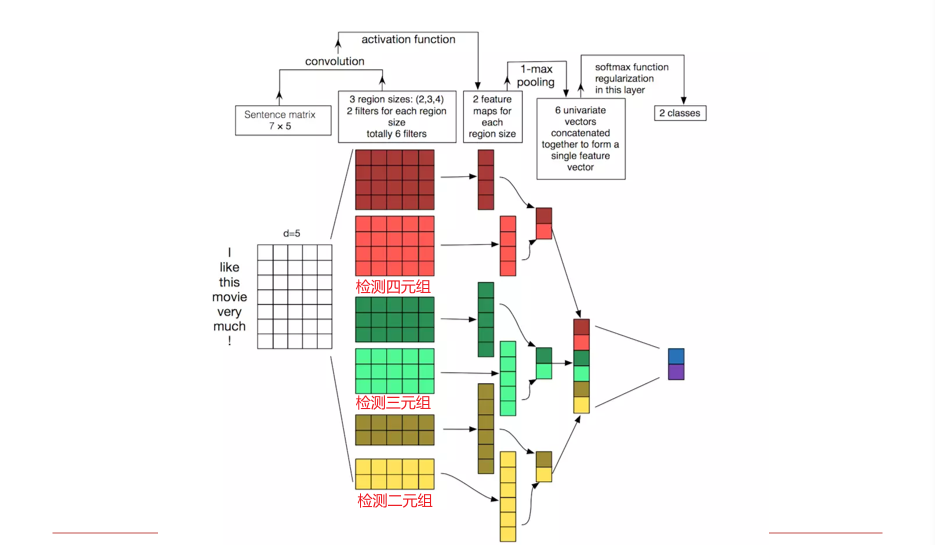
3.5.3.3 示例
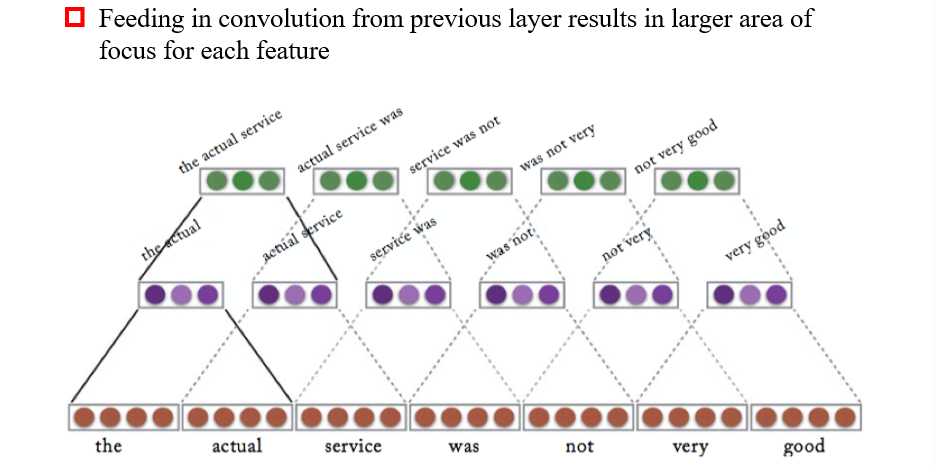
3.5.3.4 Stacked Convolution
3.5.3.5 Dilated Convolution 膨胀卷积
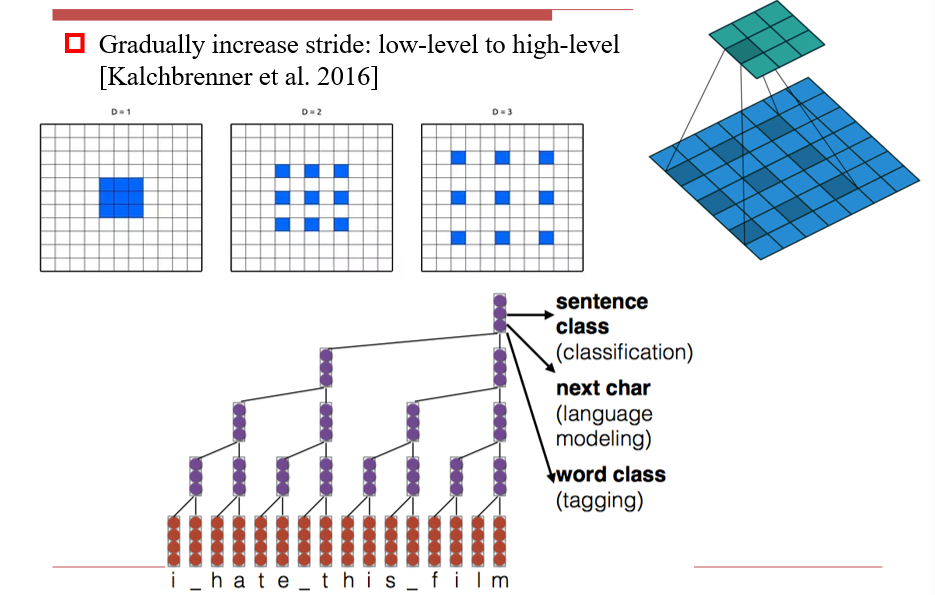
3.5.3.6 Structured Convolution 结构卷积
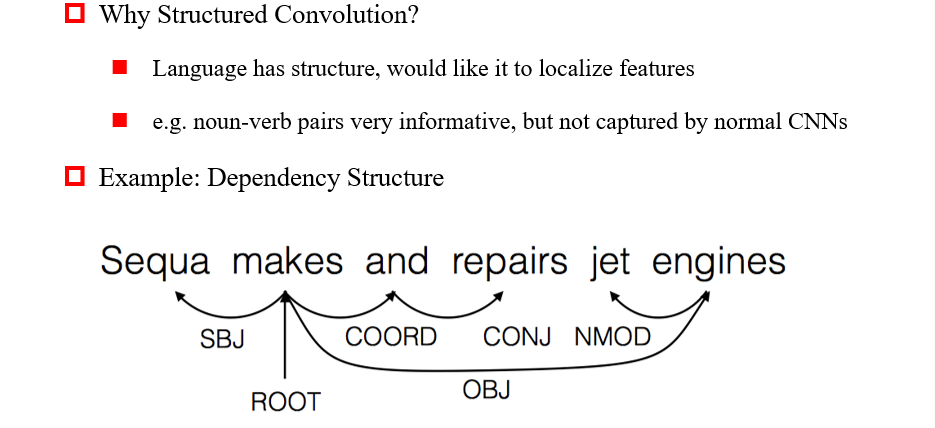
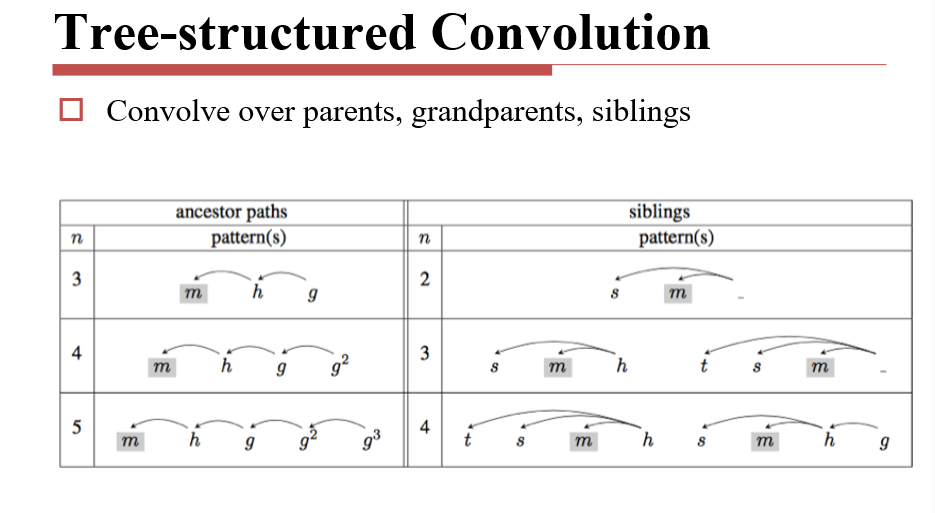
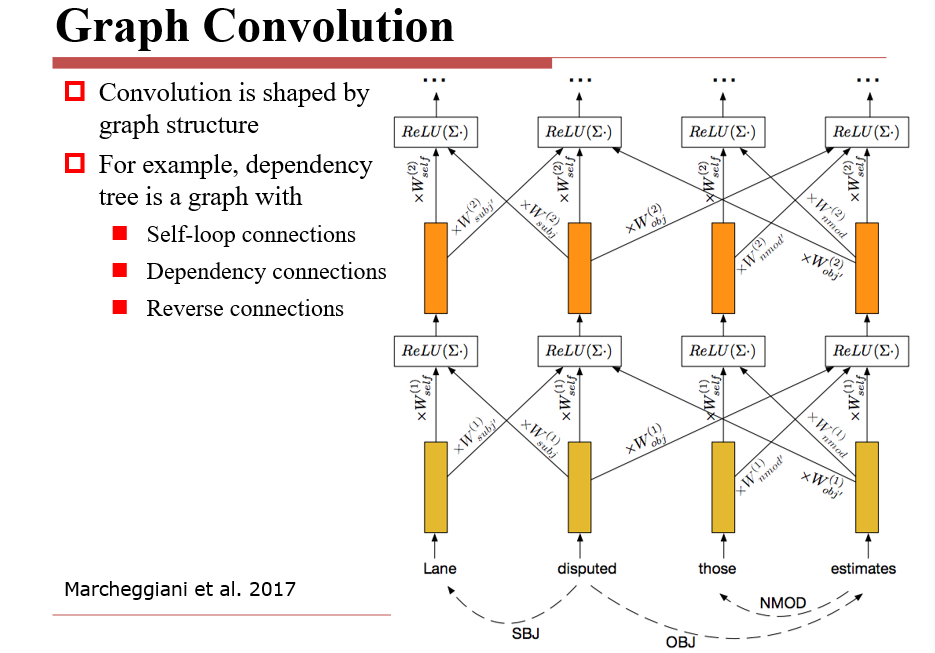
四、循环神经网络 RNN
Recurrent Neural Networks,可以看作有一定记忆能力的神经网络
4.1 RNN
4.1.1 RNN
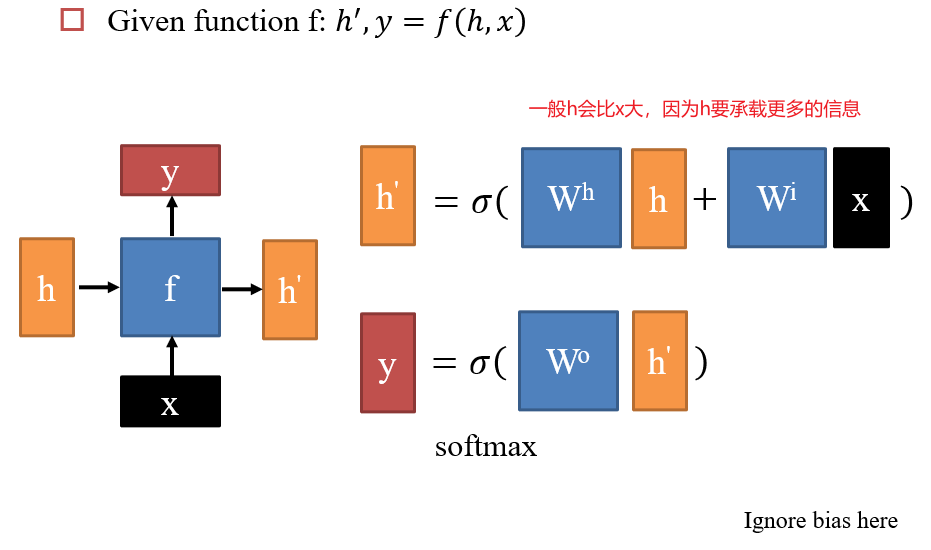
- 某一个时刻
t的输出y2,与当前时刻的输入x2、上一个时刻的输入有关x1,需要通过一个存储h1保留上一时刻的信息 f即为神经网络函数- 在每一时刻,
h,x,y,均变化,但f不变
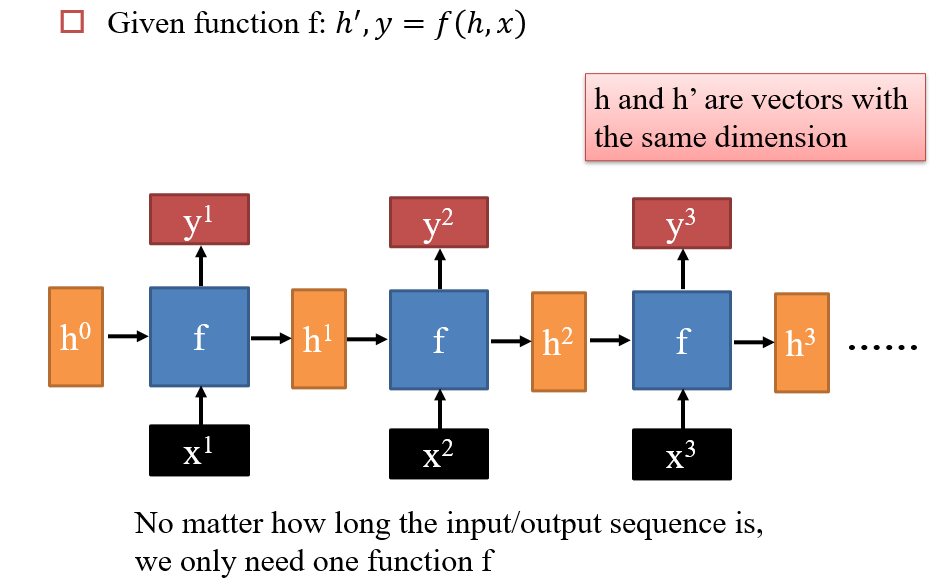
4.1.2 Deep RNN
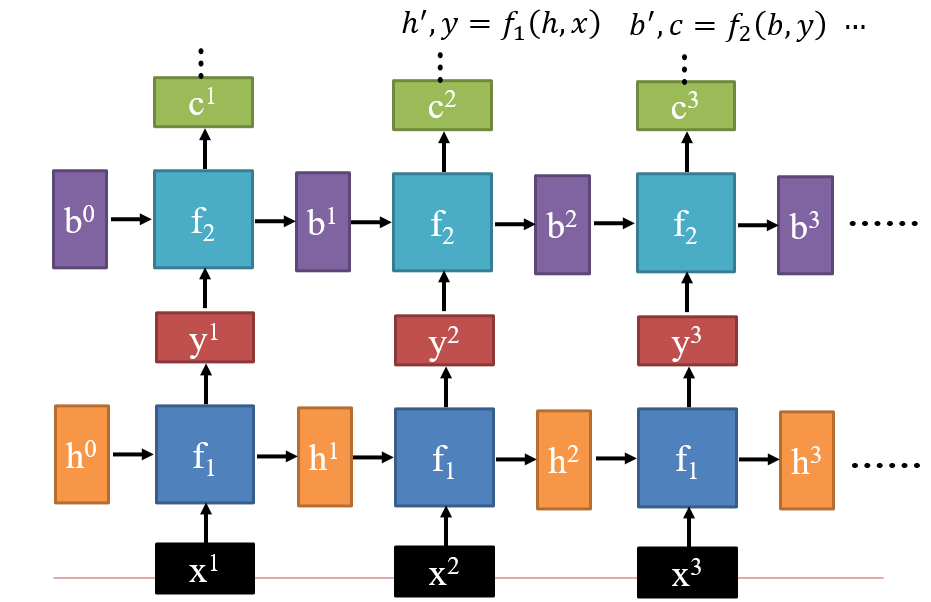
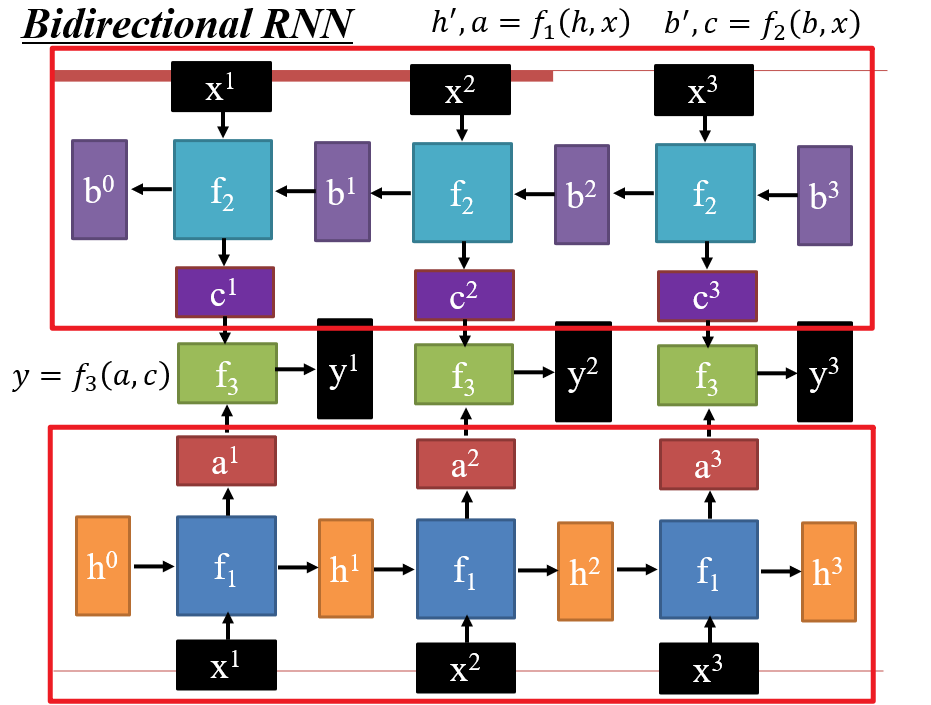
4.1.3 双向RNN
- 通常用于编码阶段
- 既需要某个词的含义,也需要某个词的上下文
4.1.4 Naive RNN
最基础的RNN
训练难:神经网络学习时
- 如果在
yn处存在损失,则会将损失一步一步传回h0处 - 实际中,会将RNN展开为一个很深的神经网络,只不过每个部分的参数是共享的
- 由于深度过深,会存在梯度消失问题
- 由于参数共享,最后的输出相当于
f(xn,f(...f(x2,f(x1,h0))),会产生梯度爆炸问题:- 类似于变量在指数上,输入变化一点,输出会发生巨大变化
- 会导致梯度墙现象:在某些地方,w稍微变化一点,L会变化非常多,而在其它地方,w变化很多,L也不会变得非常大
- 在最初训练时,L对于w的变化很小,导致learning rate非常大,从而非常快的撞向梯度墙,导致在上一时刻时,导数还很小,下一时刻,导数会变得非常大,从而导致训练失败
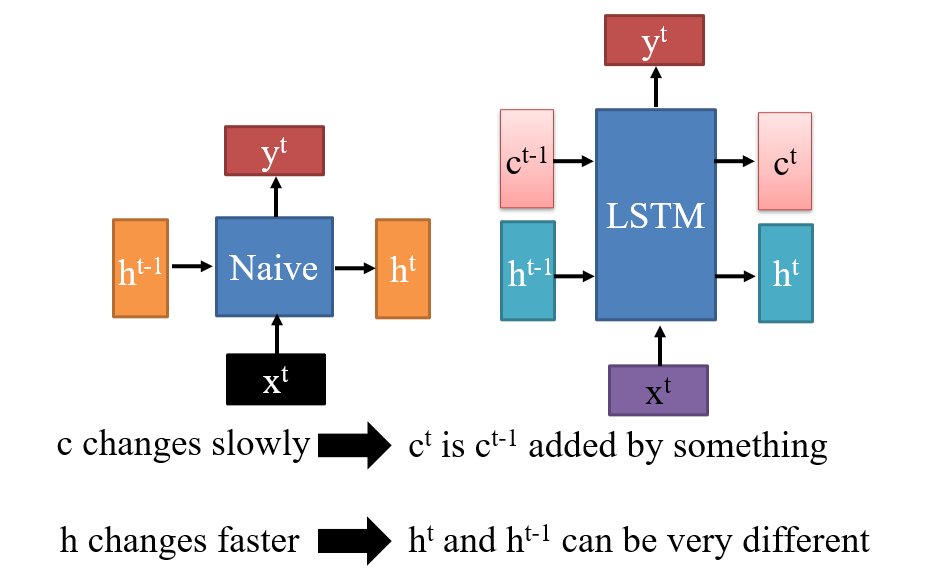
4.2 LSTM
一般说RNN指的即为LSTM
4.2.1 LSTM算法
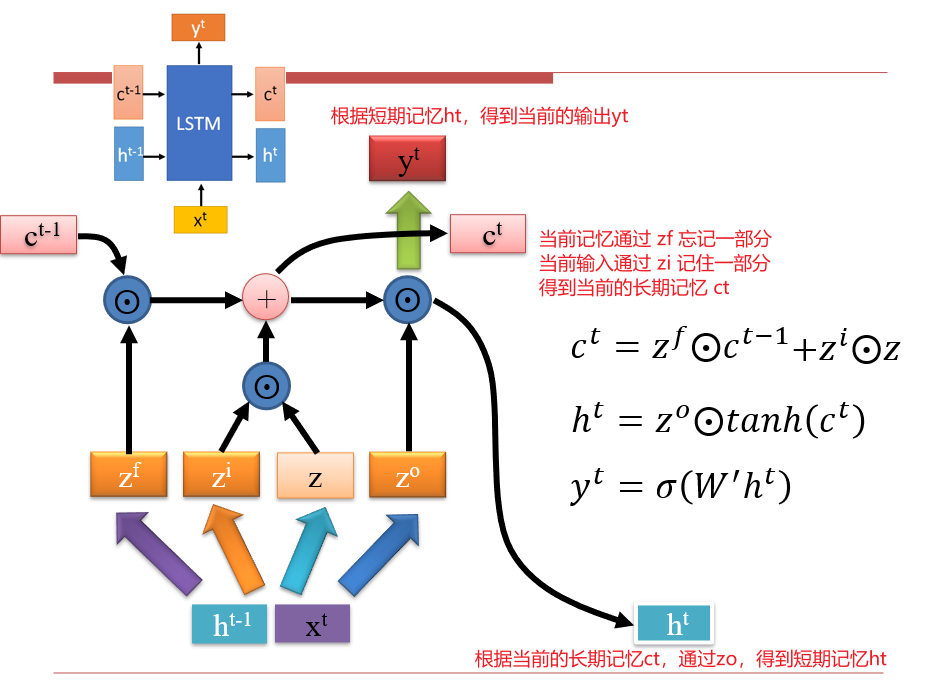
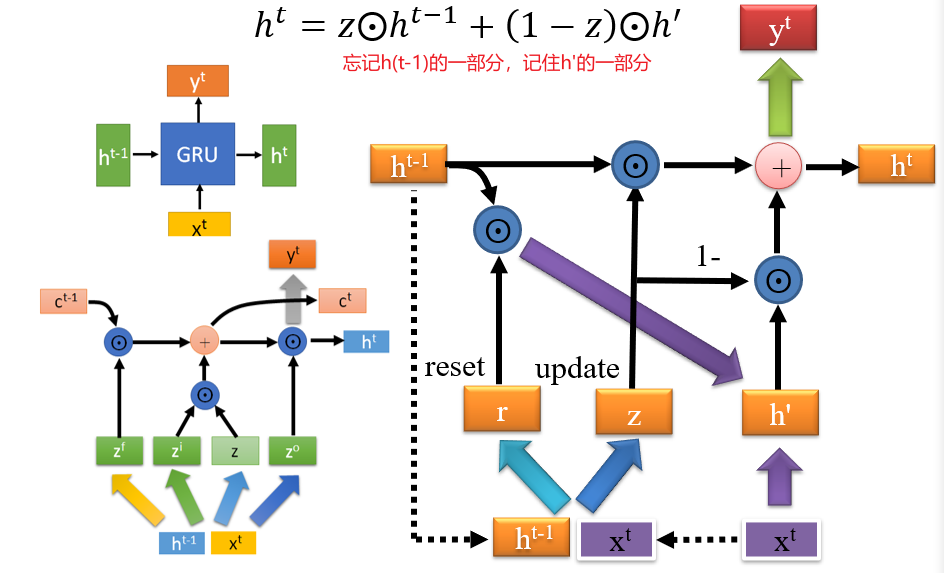
解决遗忘问题:h的变化通常会很大,导致记忆不稳定
h的变化是乘法,c的变化是加法- 因此,用
h表示瞬时记忆,c表示长期记忆
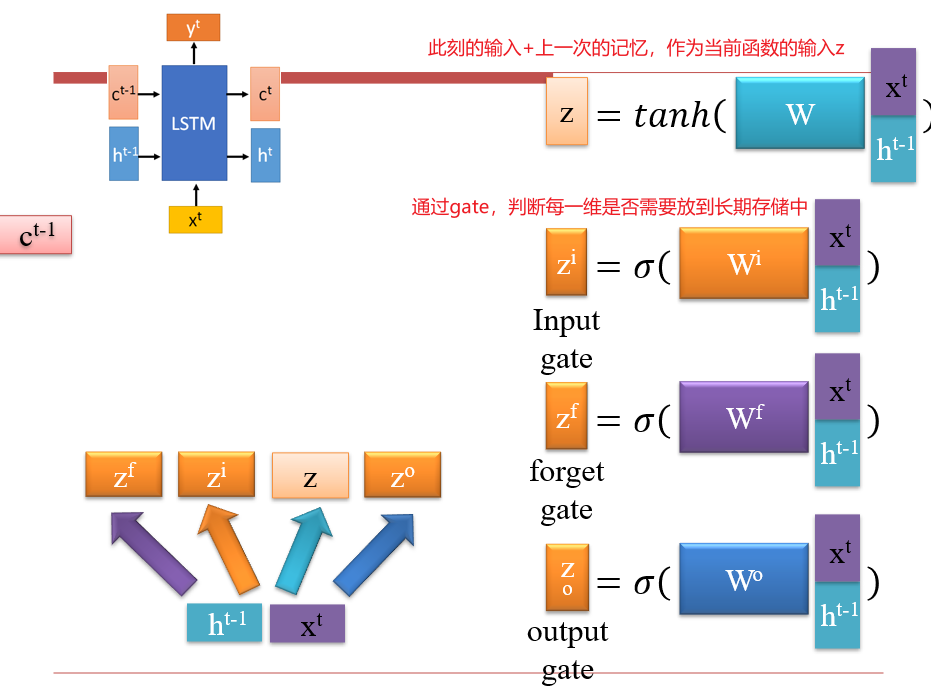
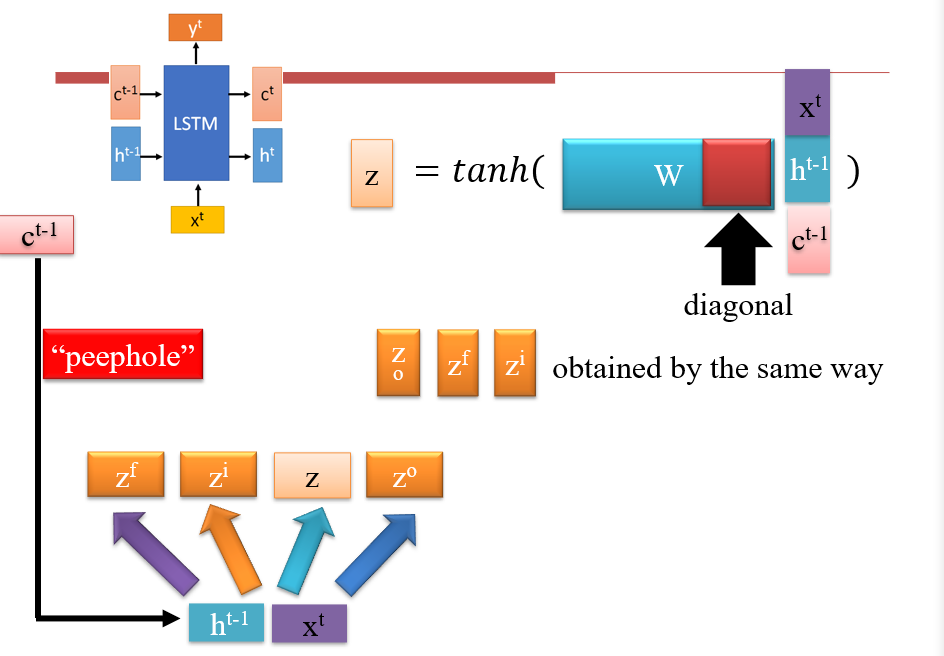
peephole:可以将长期记忆ct当作输入送入网络,但是对其进行计算时,通常只会乘一个对角阵
LSTM的每个cell
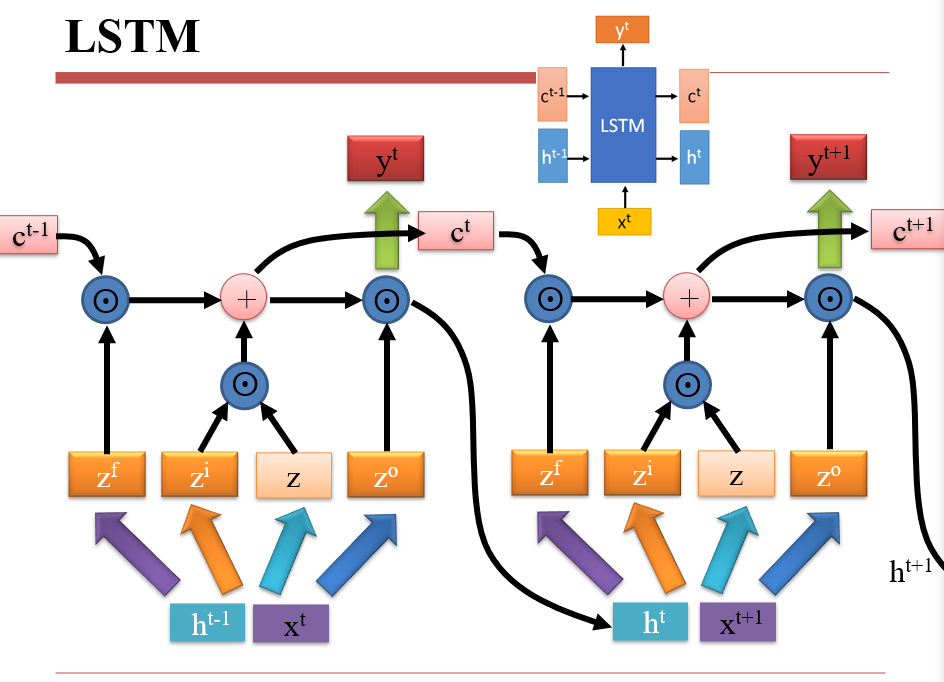
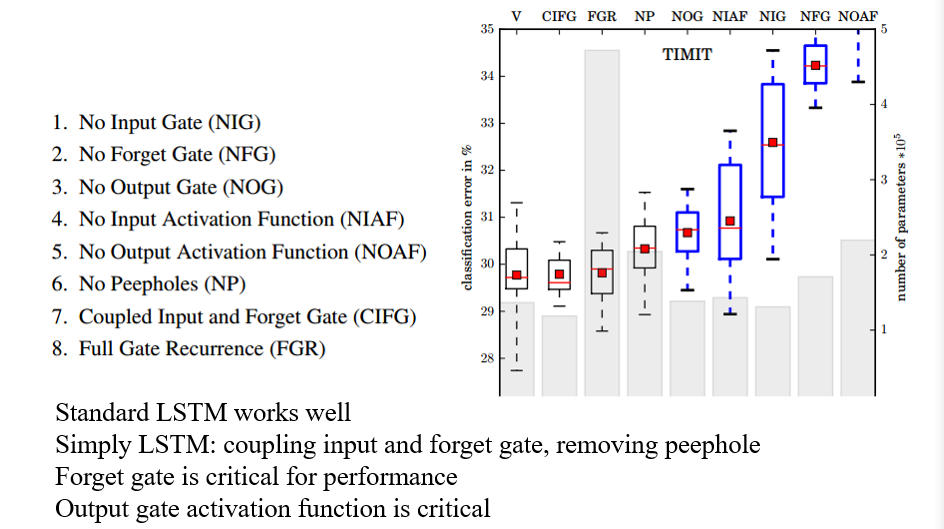
4.2.2 对LSTM不同参数的研究
4.2.3 GRU
4.3 NLP中的RNN
NLP充满了序列化的数据
- 一篇文章中的句子、一个句子中的单词、一个单词中的字母
RNN善于进行长距离依赖

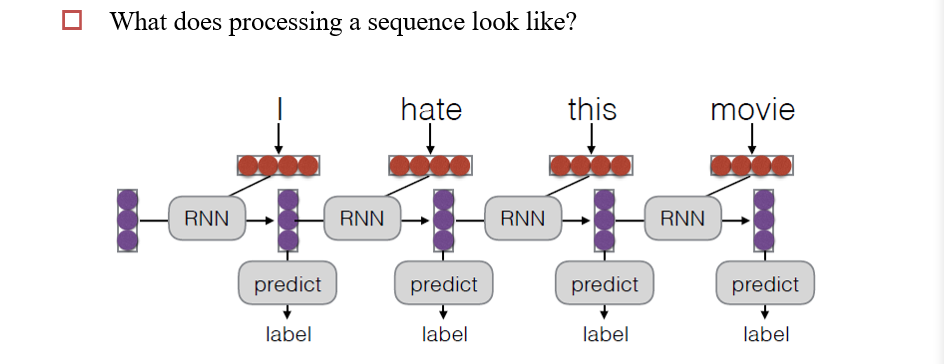
4.3.1 RNN加工一个序列
- 每一时刻,吃进去一个词向量,然后根据上一时刻的内容,输出label
4.3.2 RNN既可以做编码器,也可以做解码器
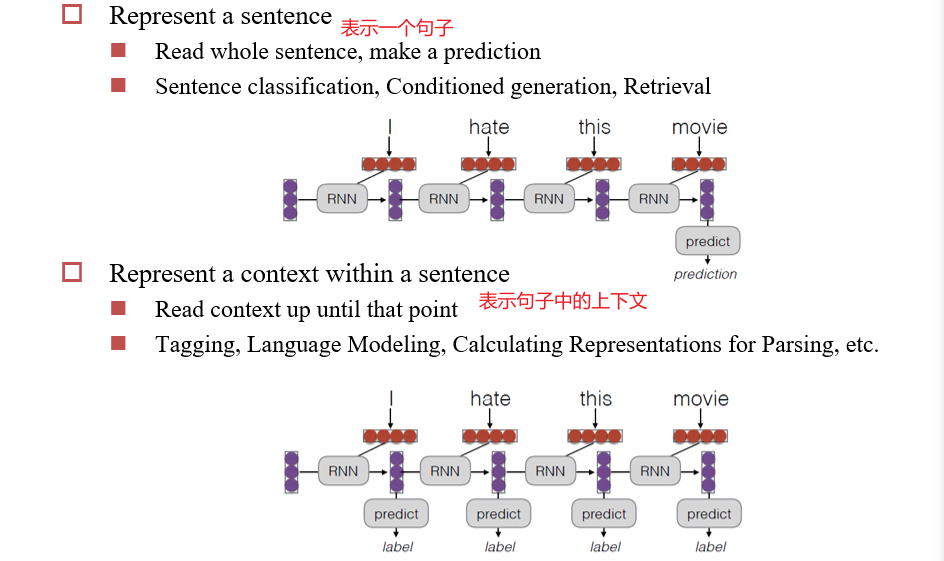
4.3.3 Encoder-decoder模型
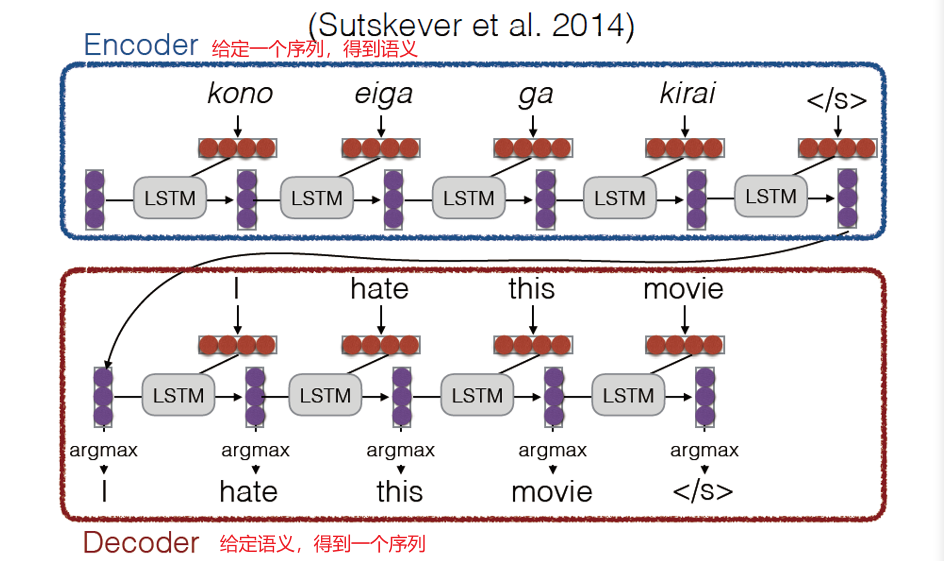
4.4 Attention 注意力
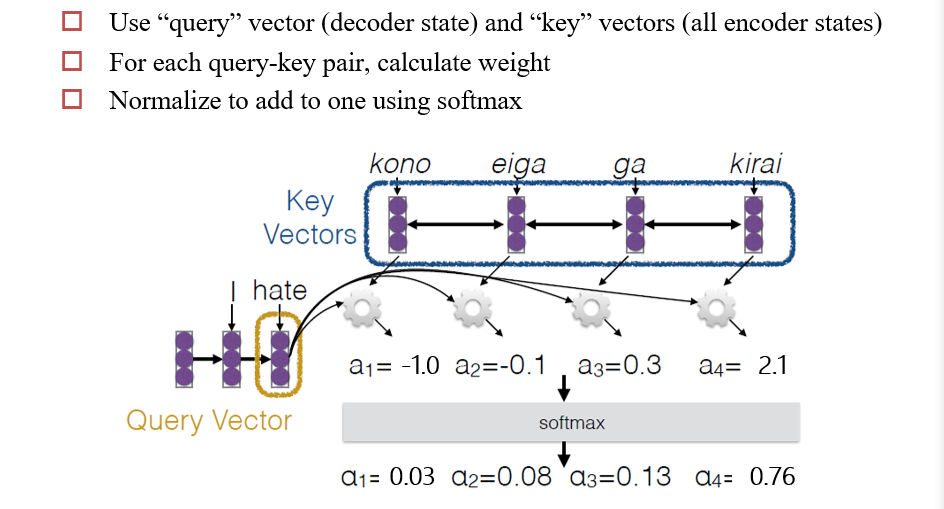
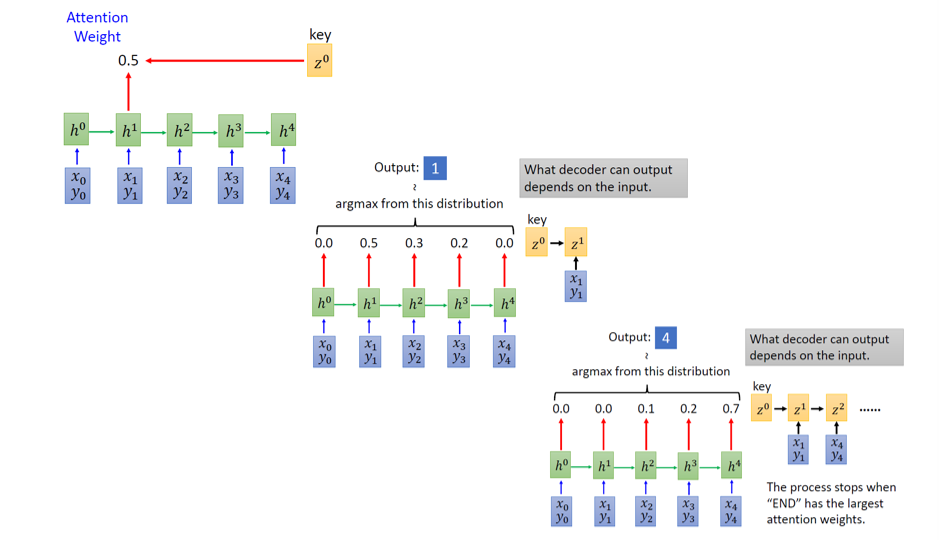
4.4.1 计算注意力
- decoder的某个状态得到的输出query
vector,与encoder中的所有状态的词向量
ki点乘,然后再进行一次softmax,得到一个attention scoreai - 用
ai与对应的ki进行数乘,然后再相加,得到一个注意力向量 - 然后可以用这个注意力向量进行后续操作
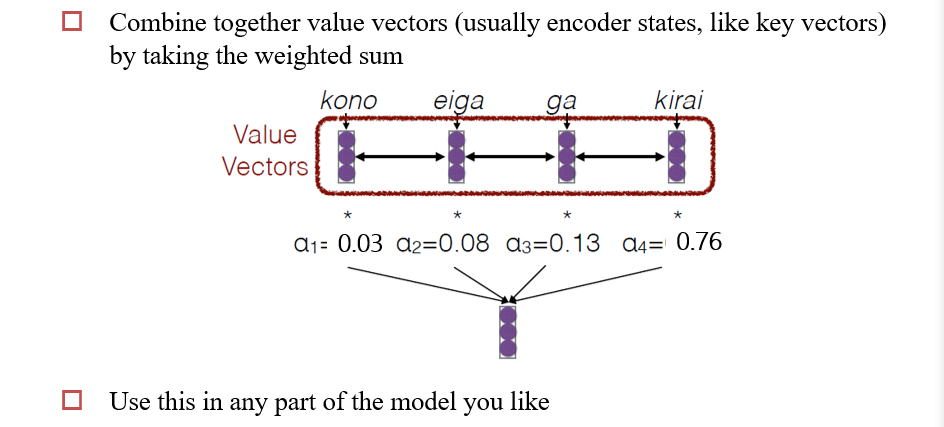
4.4.2 注意力得分函数

4.4.3 Attention的用途
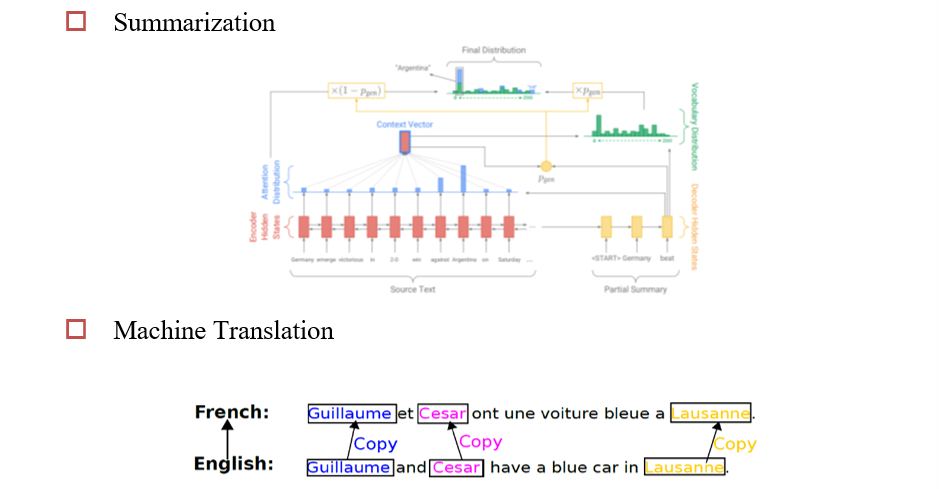
- copy机制:直接从上下文中,将某个单词拷贝到语义库
- 关注前置单词(输入、输出)
- 关注多模态输入(图像、语言)
- 关注多种输入源
4.4.4 Hierarchical Structure
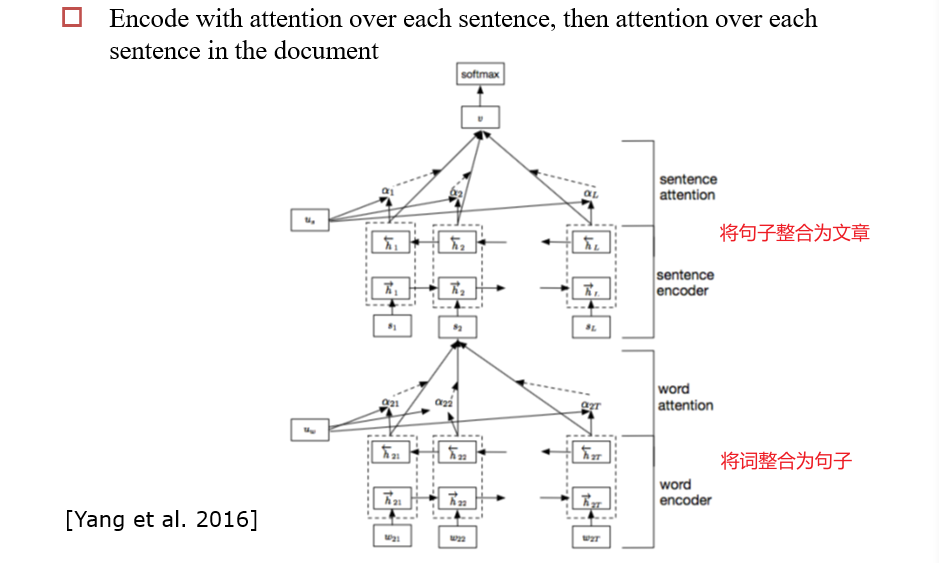
4.4.5 Hard Attention

4.5 Pointer Network
4.5.1 使用注意力做选择问题
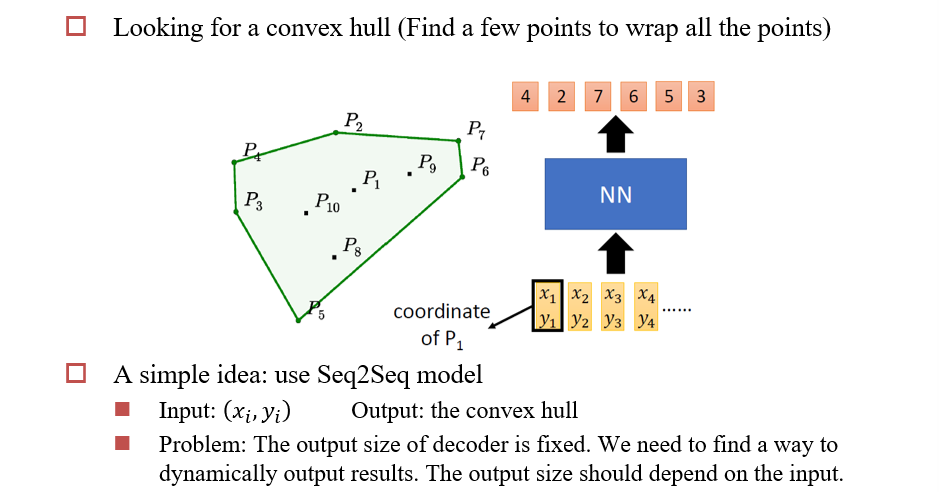
- 输出是输入的一个子集
- 可以使用注意力进行选择问题
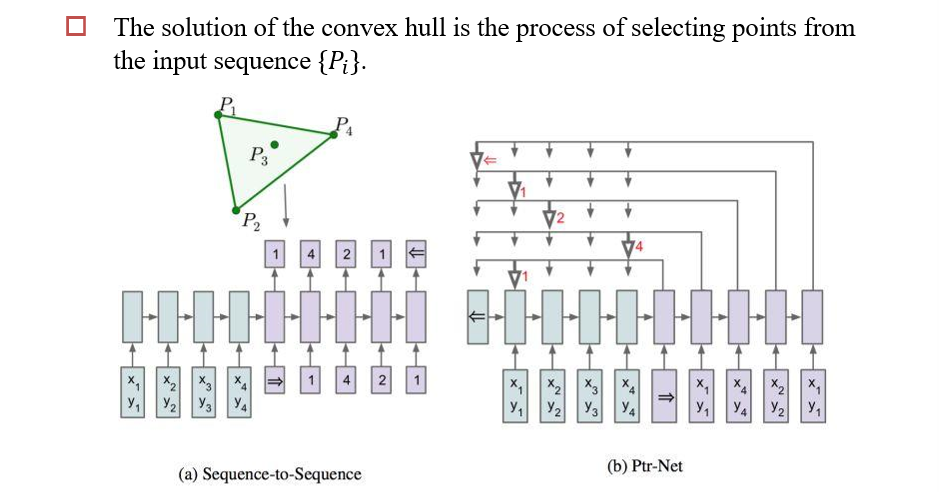
4.5.2 Copy机制
4.6 Attention and Augmented RNN
4.6.1 NTM:Neural Turing Machines
RNN是图灵完全的,理论上可以用来模拟任何函数,当然也可以模拟任何程序的功能
通过注意力,实现NTM的寻址、读写
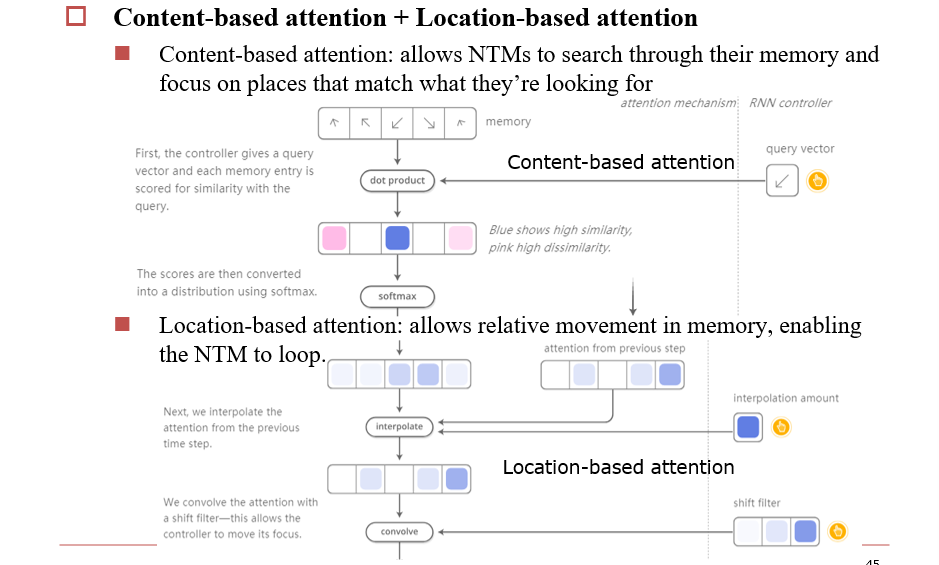
4.6.2 DNC:Differentiable Neural Computer
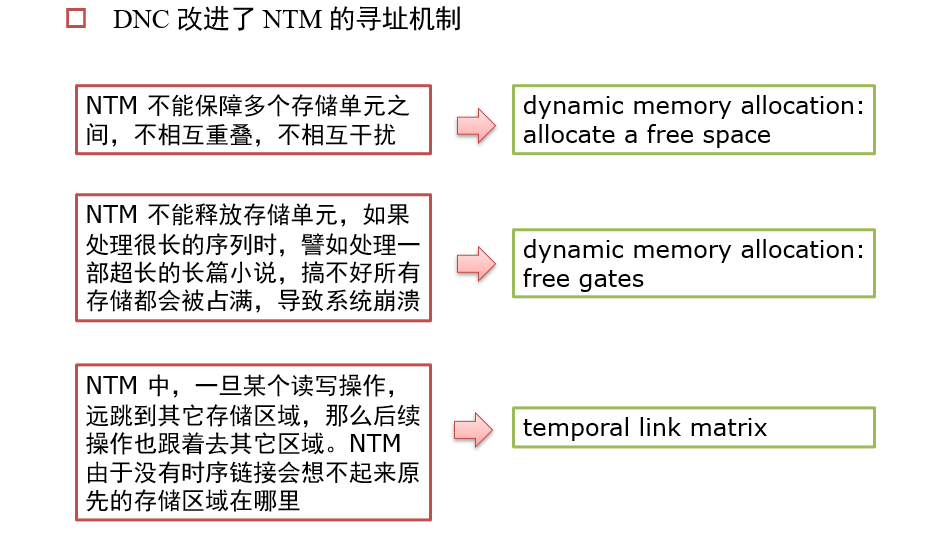
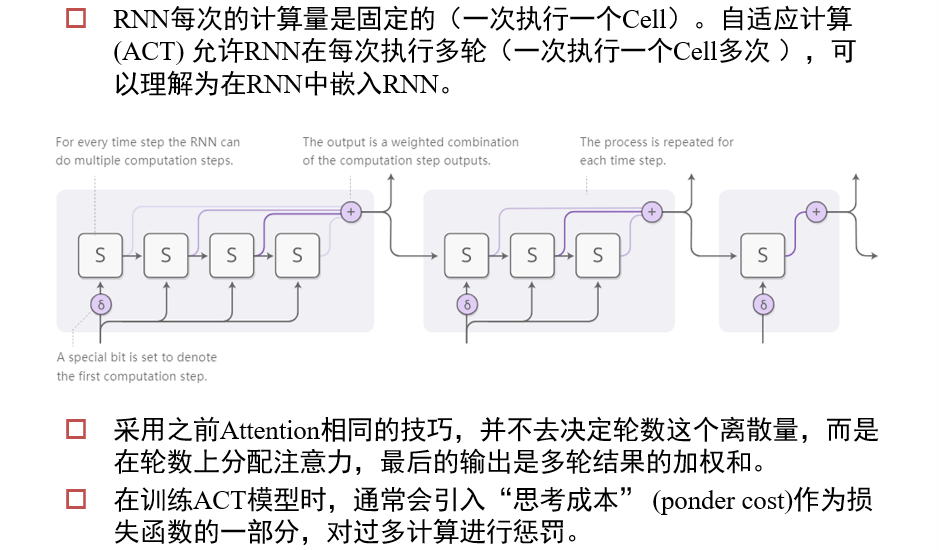
4.6.4 ACT:Adaptive Computation Time
让神经网络的结构,根据具体问题而改变
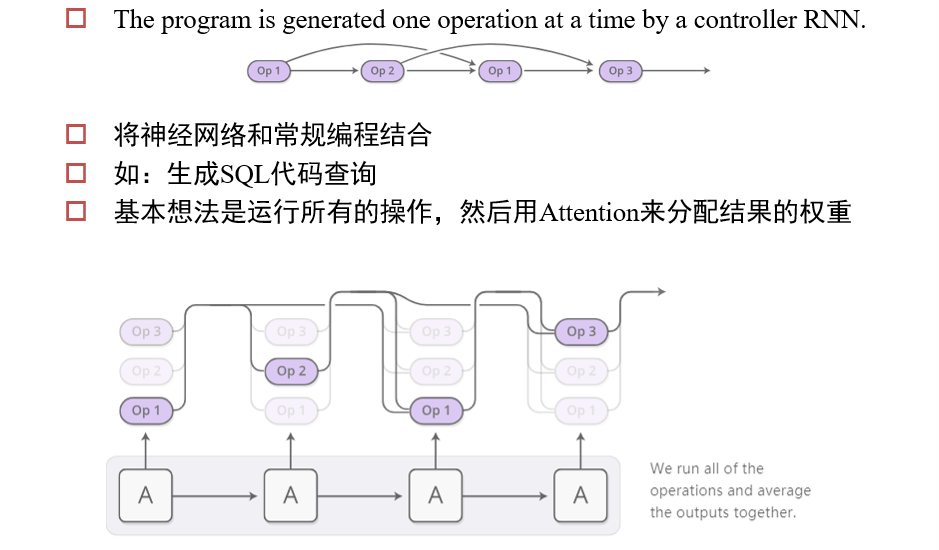
4.6.5 Neural Programmer
让神经网络学会编程、计算
五、生成模型、语言生成
5.1 生成模型 Generative Models
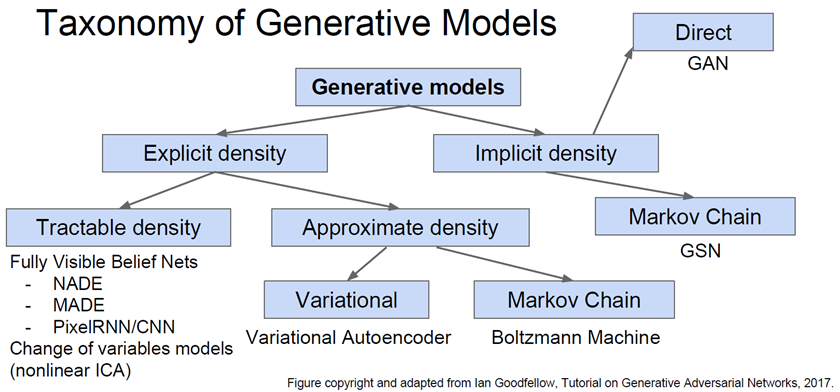
5.1.1 高斯混合模型 GMM:Gaussian Mixture Models
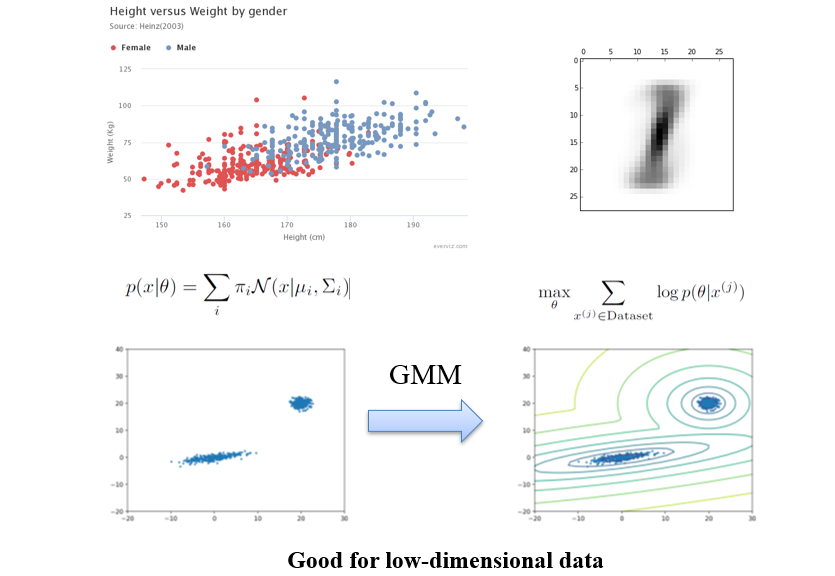
5.1.2 流形假设 Manifold Assumption
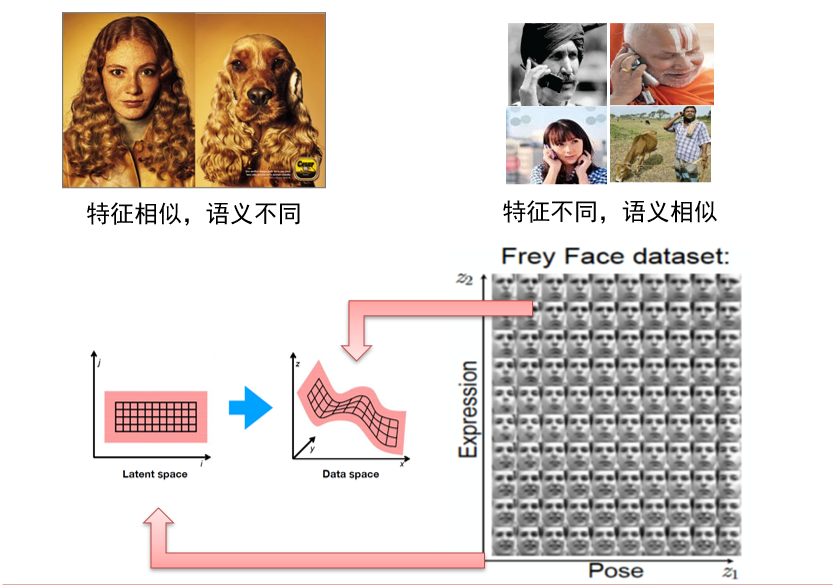
5.1.3 Auto-Encoder
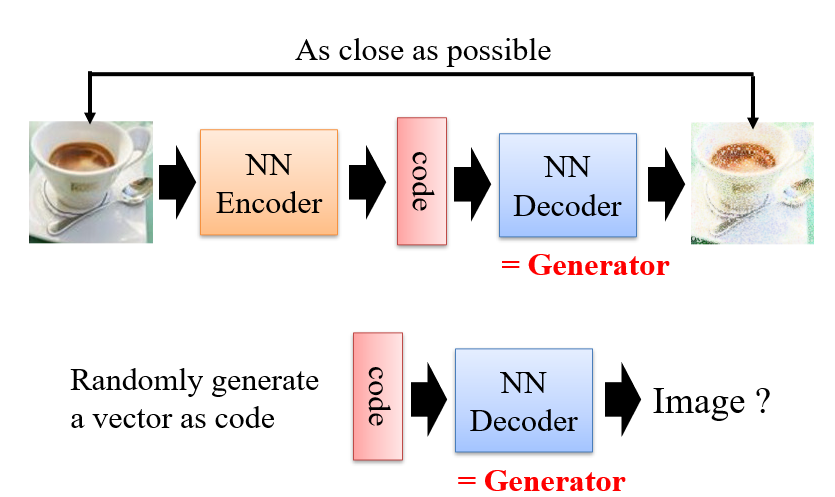
训练时:要求Decoder的输出与Encoder的输入相同
- 此时,可以得到两个模型:Encoder、Decoder
- 而Decoder就可以作为Generator使用
- code即为这个模型中的流形
5.1.3.1 Generator
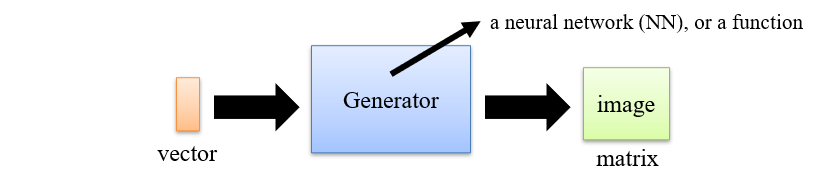
- 一个神经网络,输入是一个vector,输出是一个图像
- 期望vector中的每一维控制不同的特征
- 但实际上vector的每一维之间是紧密耦合的,需要进行解耦操作才可以实现预期效果
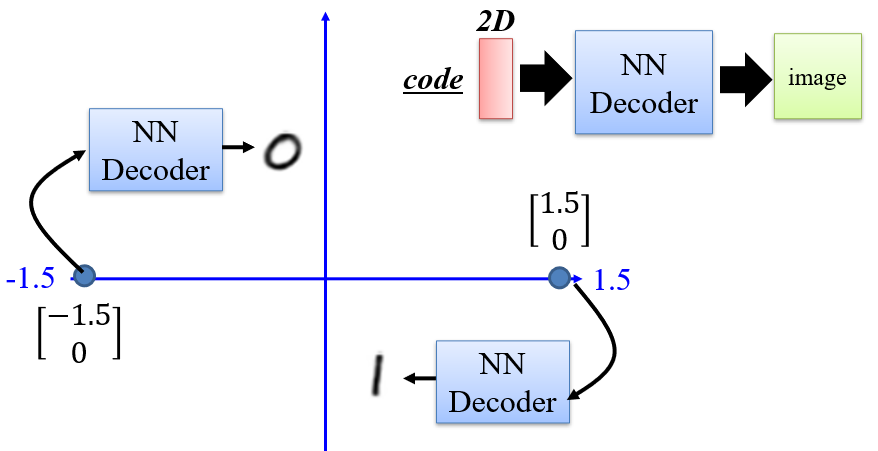
code为2维时,训练出的模型
通过对code进行差值然后得到输出,可以判断模型是否学习到了某些知识,而不是仅仅通过记忆

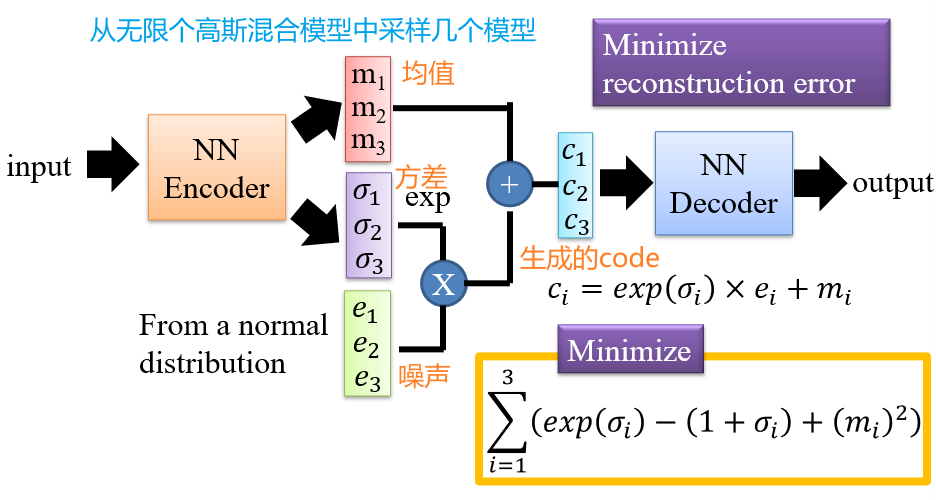
5.1.4 Variational AutoEncoders
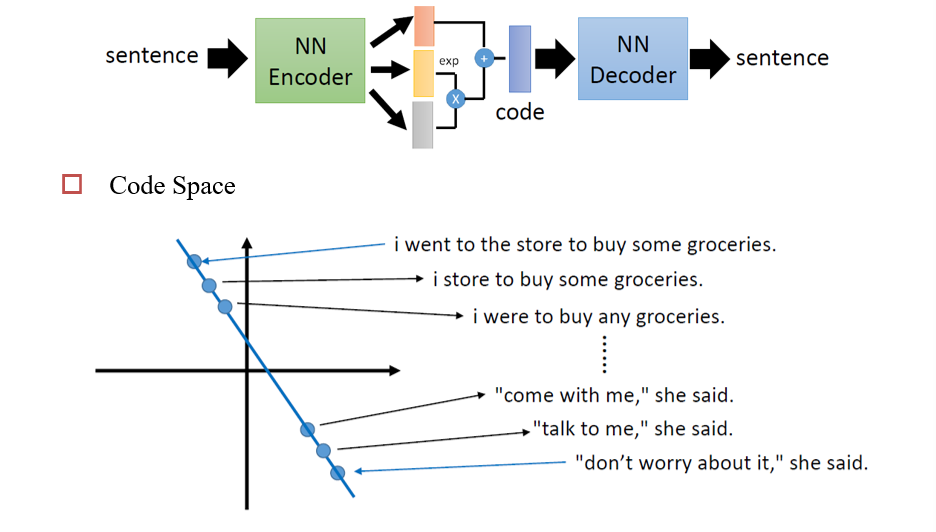
5.1.6 Flow-based Deep Generative Models
- Inverse是Flow的逆操作
- 将一个图像分为两半,下半根据上半打乱
- 然后再翻转
- 重复12步,可以得到一个模糊后的图像
- 通过原图、模糊后的图像、模糊的过程,可以训练出Inverse
- 只要能够训练出来Inverse,那么任给一个高斯模糊后的图像,一定能生成其原图像

5.1.7 PixelRNN、PixelCNN
- 用编码器,做解码器的工作

5.2 自然语言生成 NLG
5.2.1 语言模型
Language Modeling 语言建模:给定历史单词\(y_1,...y_{t-1}\),生成下一个单词\(y_t\)
- 实质上是一个概率密度函数\(P(y_t|y_1,...,y_{t-1})\),表示\(y_t\)可能是该词的概率
- 生成这个概率密度函数的系统,被称为Language Model
- 如果这个系统是一个RNN,则称为RNN-LM
Conditional Language Modeling 传统语言建模:给定历史单词\(y_1,...y_{t-1}\),和一些其他输入\(x\),生成下一个单词\(y_t\)
- 概率密度函数\(P(y_t|y_1,...,y_{t-1}|x)\)
5.2.2 训练RNN-LM
- 在训练时,如果上一步生成了一个错误的结果,则需要将其抛弃掉,将正确的结果送给下一步
- 称为Teacher Forcing
- 当实际数据与训练数据差距很大时,会导致模型崩溃
- 实际上,会在训练一段时间后,再次训练时,一定的概率将生成的结果直接送到下一步
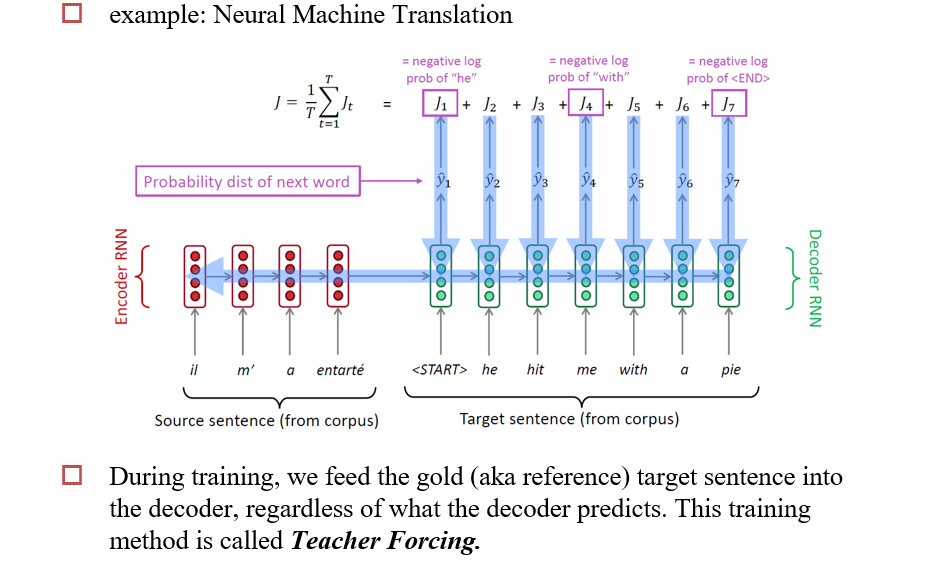
5.2.3 生成句子
已经有了模型\(P(Y|X)\),如何使用这个模型生成一个句子?
- Sampling:根据概率密度函数,生成一个随机的句子
- Argmax:生成一个具有最大可能性的句子
Ancestral Sampling:
- 一个接一个的随机生成单词
- 只需要一个明确的对\(P(X)\)的采样方法
Greedy Search:
- 一个接一个的,每次选择概率最大的单词
- 存在的问题:
- 会经常优先生成一些简单的的单词
- 会优先生成常用的单词
5.2.3.1 基于采样的decoding

5.2.3.2 Beam Search
- 同时保留几个比较好的结果,作为输出

确定一个最优的 beam size k


5.2.3.3 Softmax Temperature

5.2.4 Decoding算法总结

5.3 评估 Evaluation
5.3.1 Human Evaluation
- 是否重复?是否流畅?排序是多少?

5.3.2 BLEU
- Reference:翻译的准确结果
- System:系统生成的结果

5.3.3 METEOR

5.3.4 Perplexity
- 计算单词在不做生成的情况下的困惑程度
- 优点:自然解决多参考问
- 缺点:不考虑解码或实际生成输出
- 对于有很多歧义的问题可能是合理的

5.3.5 Unconditional Generation

六、机器翻译 & Transformer
6.1 统计机器翻译SMT
Statistical Machine Translation
设给定中文句子x,要翻译为英文句子y,则需要找到令P(y|x)最大的y
利用贝叶斯公式可得:P(x,y) = P(x|y)×P(y) = P(y|x)×P(x)
由于P(x)在x给定时是定值,因此我们只需要令P(x|y)×P(y)最大即可
P(y):先验,表示给定英文句子y,这是一个合法的英文句子的概率,很容易就能训练出来
P(x|y):似然函数,表示给定英文句子y,翻译为中文句子x的概率
首先,需要大量的平行语料进行训练,即由人翻译的中文<=>英文
添加一个隐变量a(alignment),计算当x,y给定时,对应的P(x,a|y)
alignment类似与attention
可以是一对多:
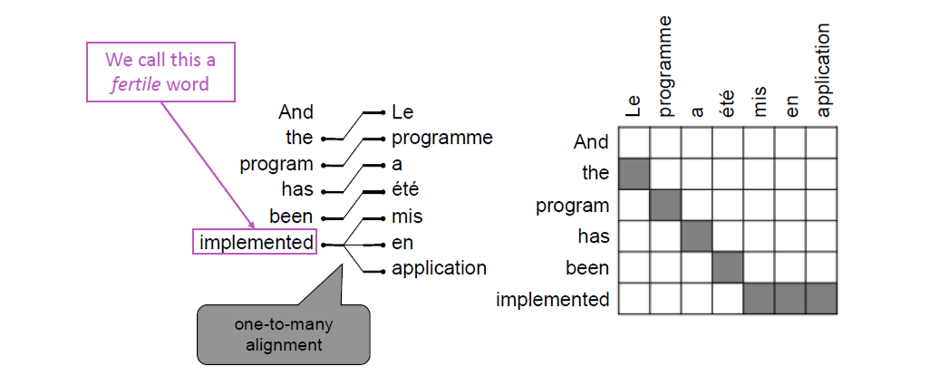
可以是多对一:
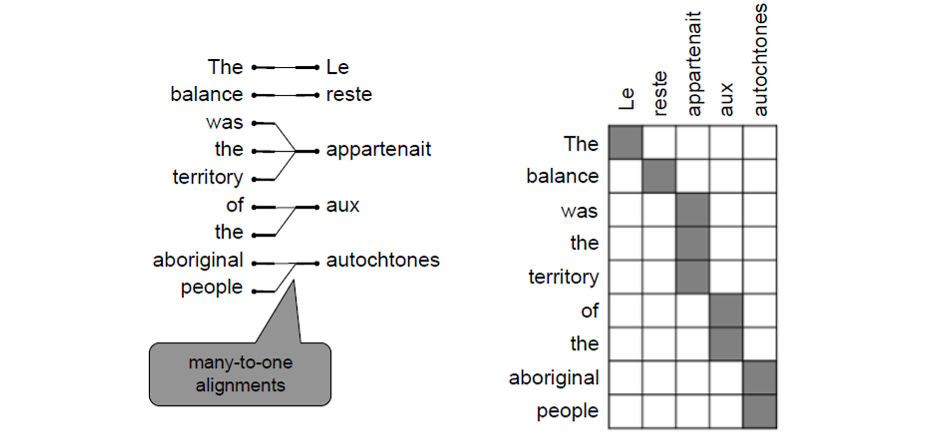
可以是多对多:
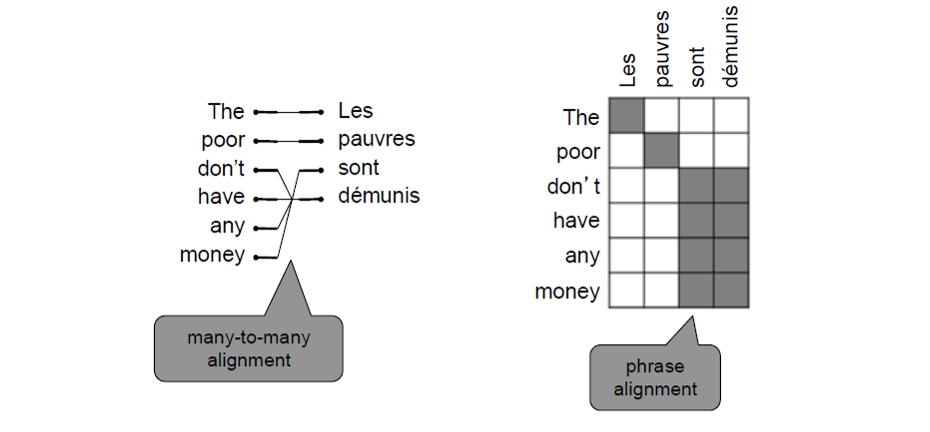
6.2 神经网络机器翻译NMT
Sequence-To-Sequence model (NIPS 2014)
- 直接对P(Y|X)进行建模
- 翻译不需要显式定义alignment
- 缺点:所有信息包含在了内部状态之中,解释性差,长句子的翻译效果很差
Attention Model
- 通过访问所有encoder的状态,降低了长句子翻译的缺点
6.2.1 V1:Encoder-Decoder
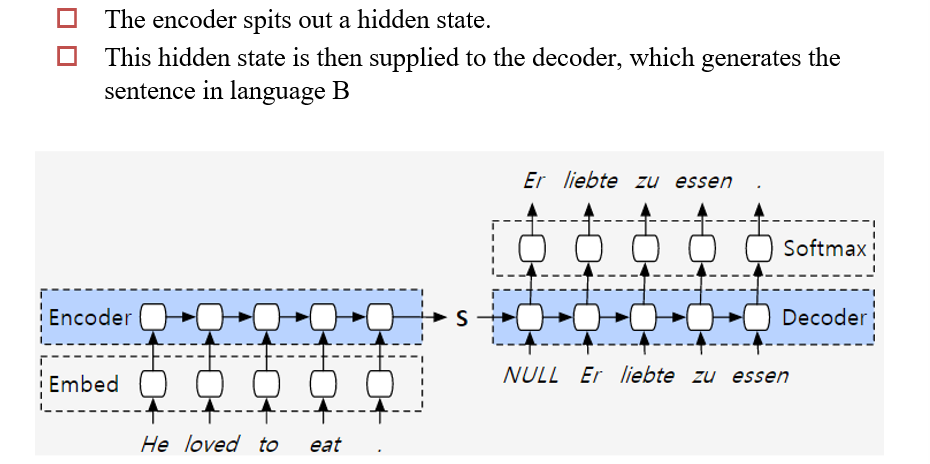
6.2.2 V2:基于Attention的Encoder-Decoder
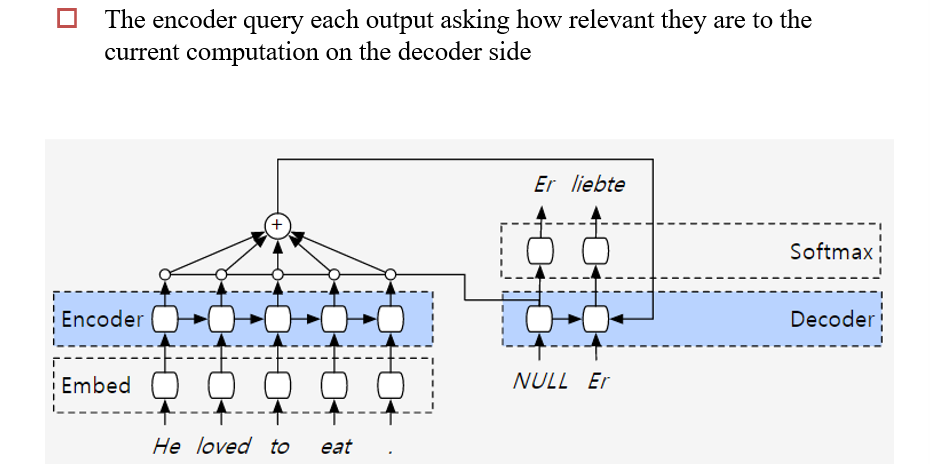
6.2.3 V3:双向Encoder
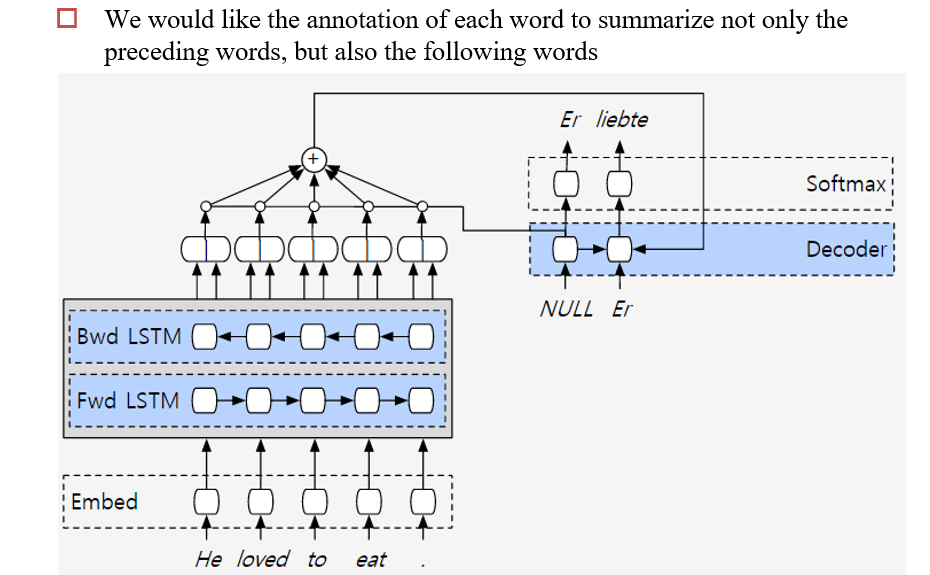
6.2.4 V4:深度学习
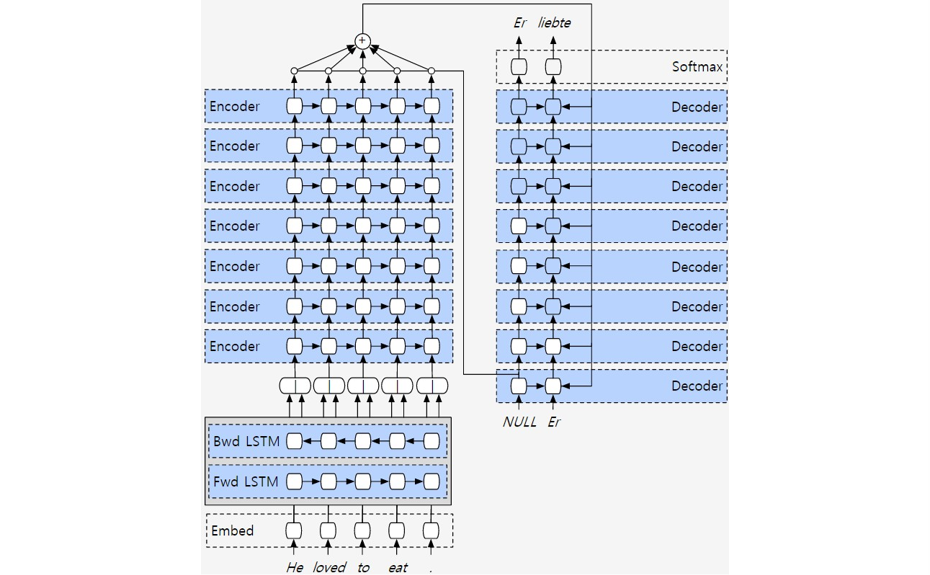
6.2.5 V5:并行优化
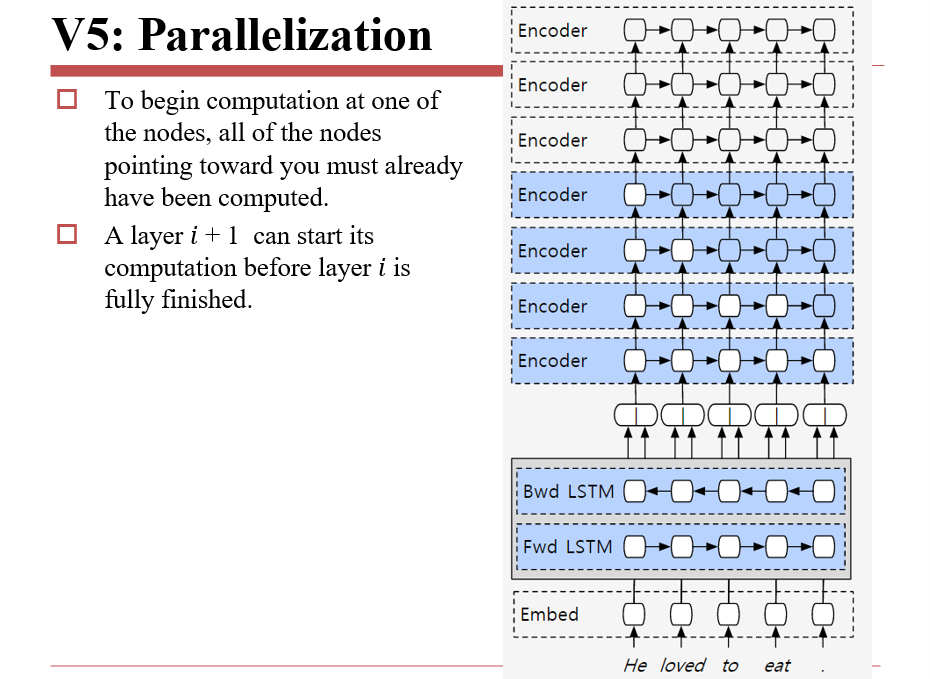
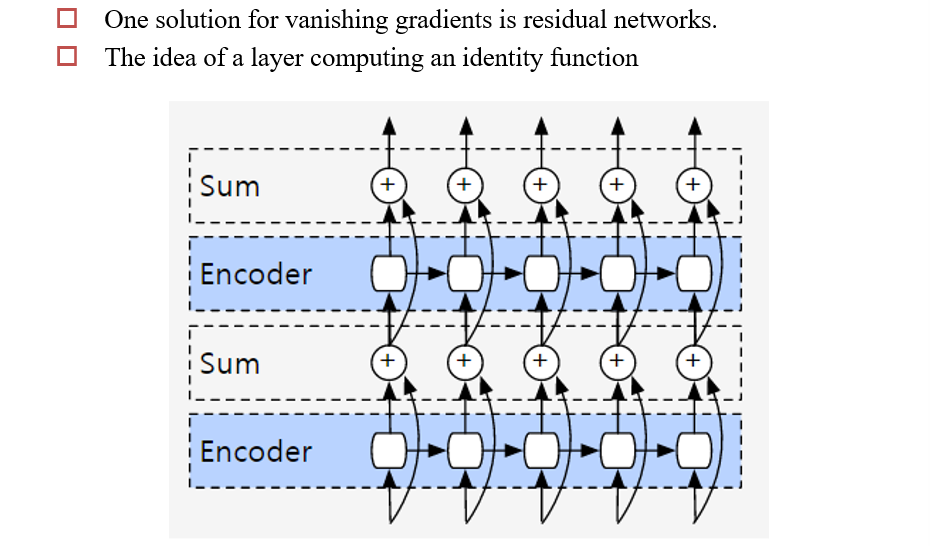
6.2.6 V6:Residuals are the new hotness
6.3 NMT的近代发展
6.3.1 Multilingual Model
训练时,对每一个语料,添加一个标签,表示要翻译成哪种语言

Zero-Shot翻译:
- 翻译时需要将日文翻译为韩文,但是训练数据并没有对应的语料
- 有日文到英文的翻译,有英文到韩文的翻译
- 相当于把英语作为一个桥梁
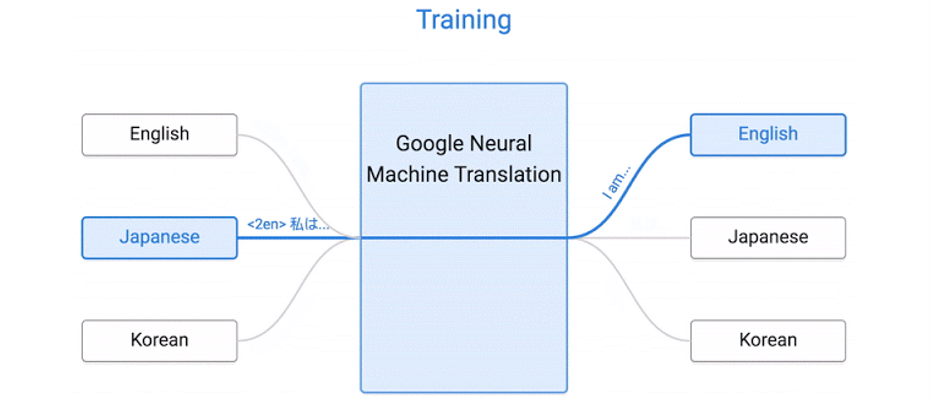
6.3.2 Code-Switching
可以将两种语言混合在一起,进行翻译

6.3.3 Big Picture
训练的结构图
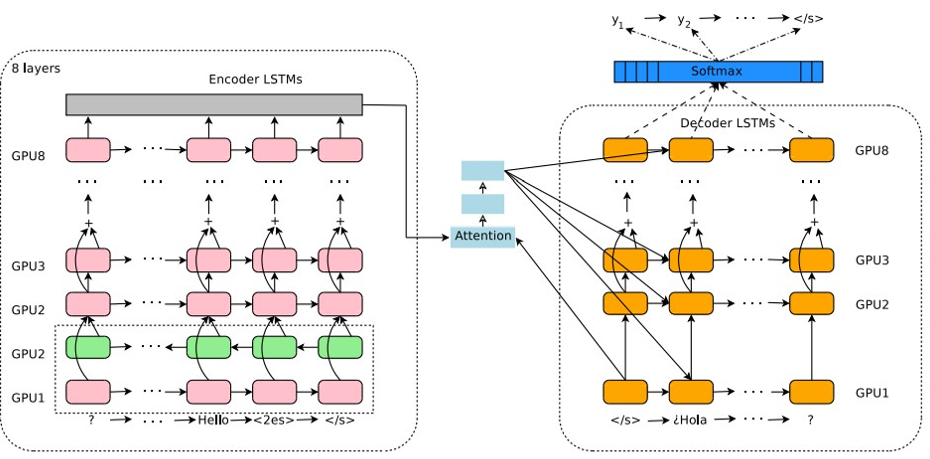
6.3.4 Unsupervised MT
当平行语料比较少的时候,可以使用这种方法
- 用两个编码器,分别学习两种语言,对应到两种语义空间
- 找到一些锚点,将两个语义空间拉近(如一些已经翻译好的句子对应的语义空间)
- 最后,将两个语义空间对齐
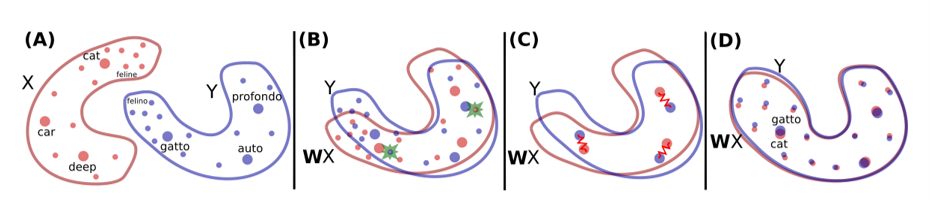
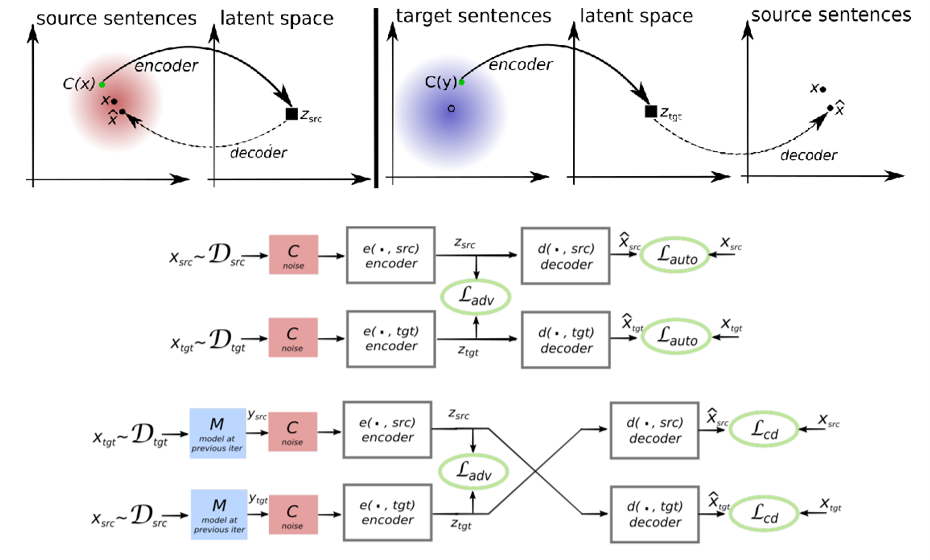
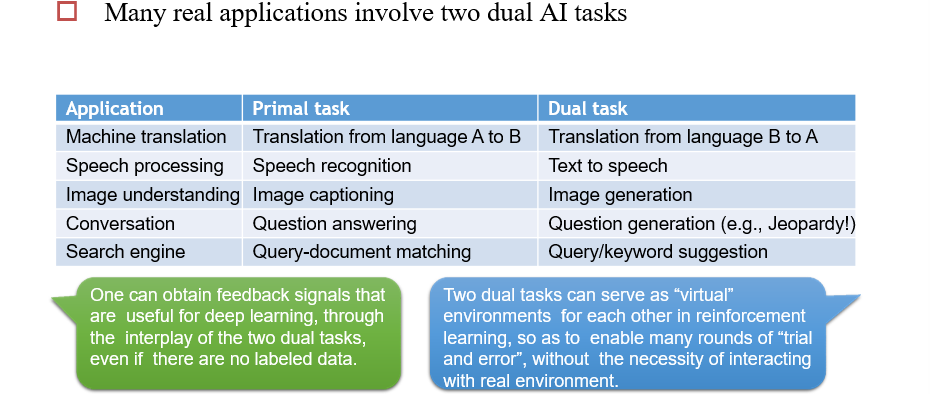
6.3.5 对偶学习 Dual Learning
在没有平行语料的时候,可以使用该方法
- 一个模型负责将X翻译成Y,另一个模型负责将Y翻译为X
- 至少其中一个模型比较强
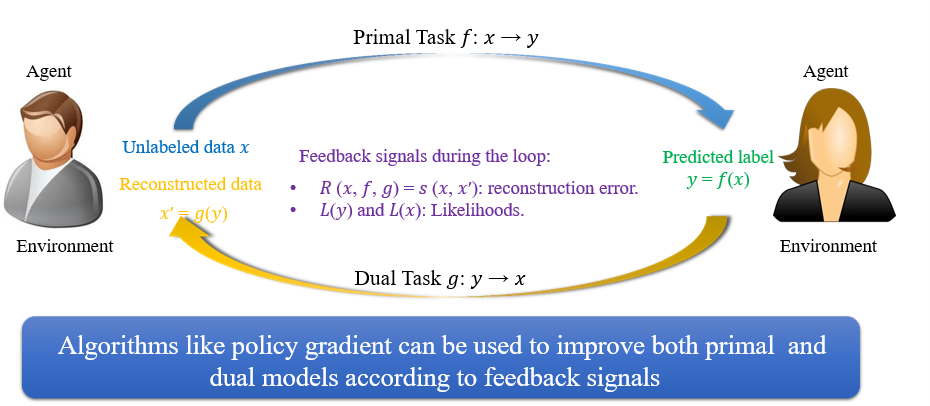
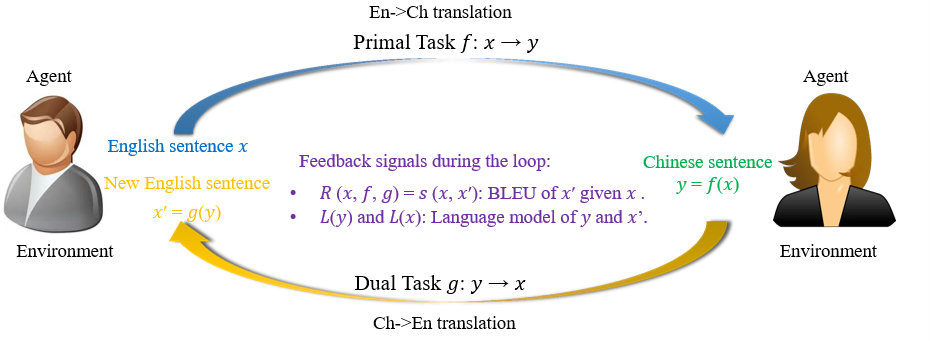
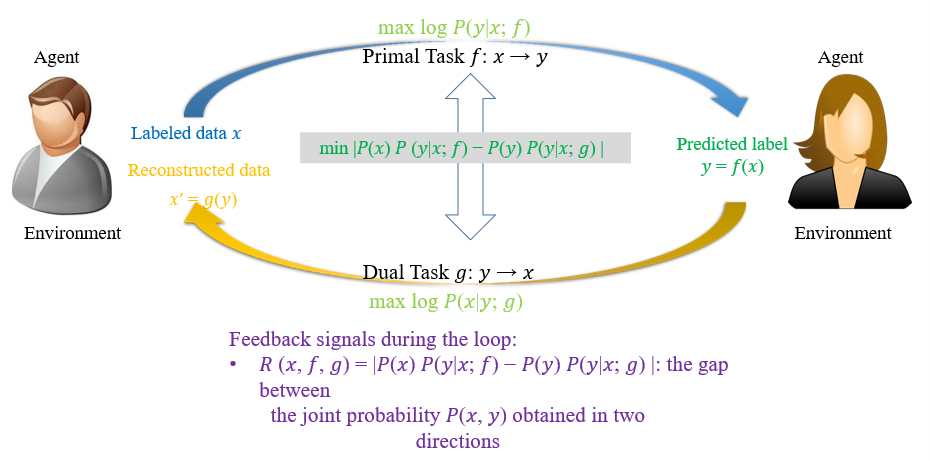
两个模型可以互相做评价,将损失定义为两者的差值
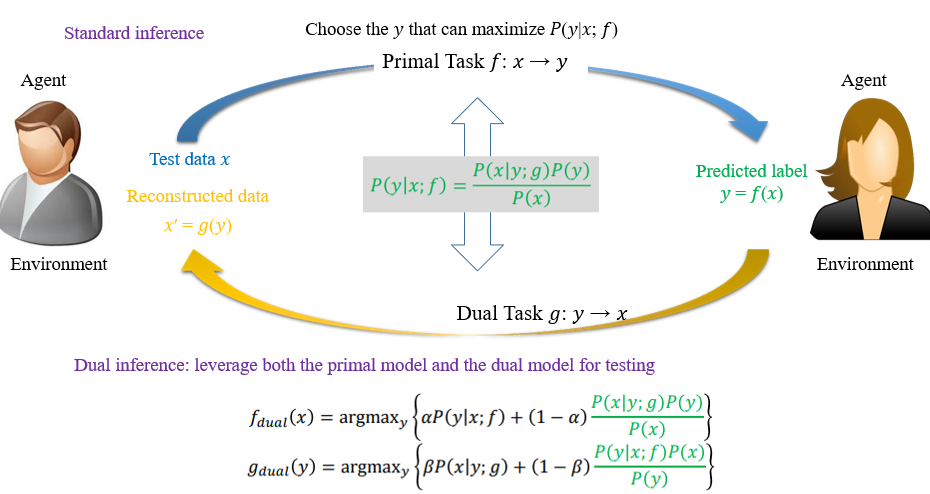
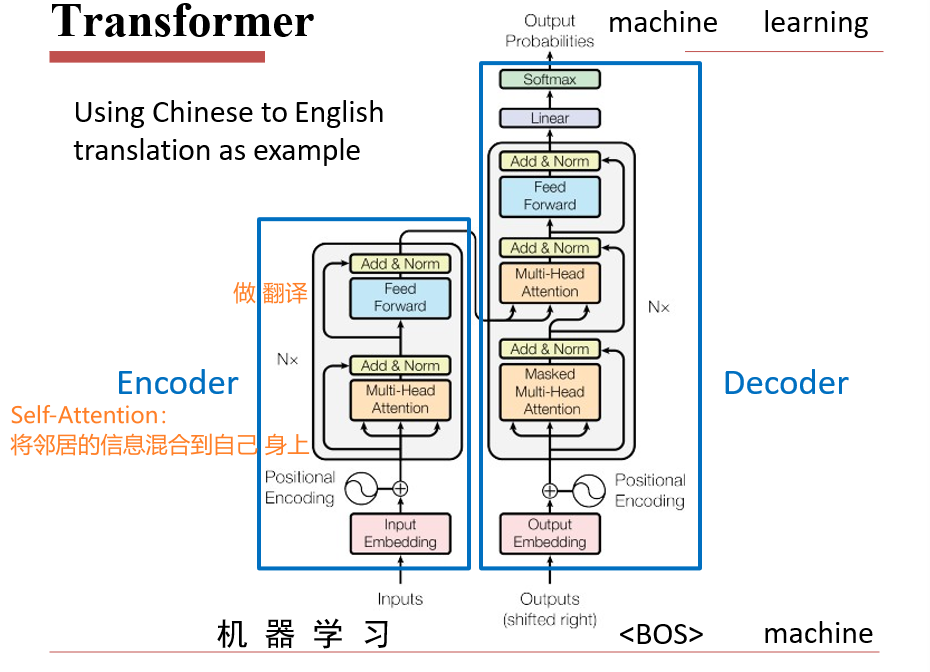
6.4 Transformer
6.4.1 Sequence
- RNN对于长序列较好,但是无法并行计算
- CNN可以并行计算,但是长序列就不行了
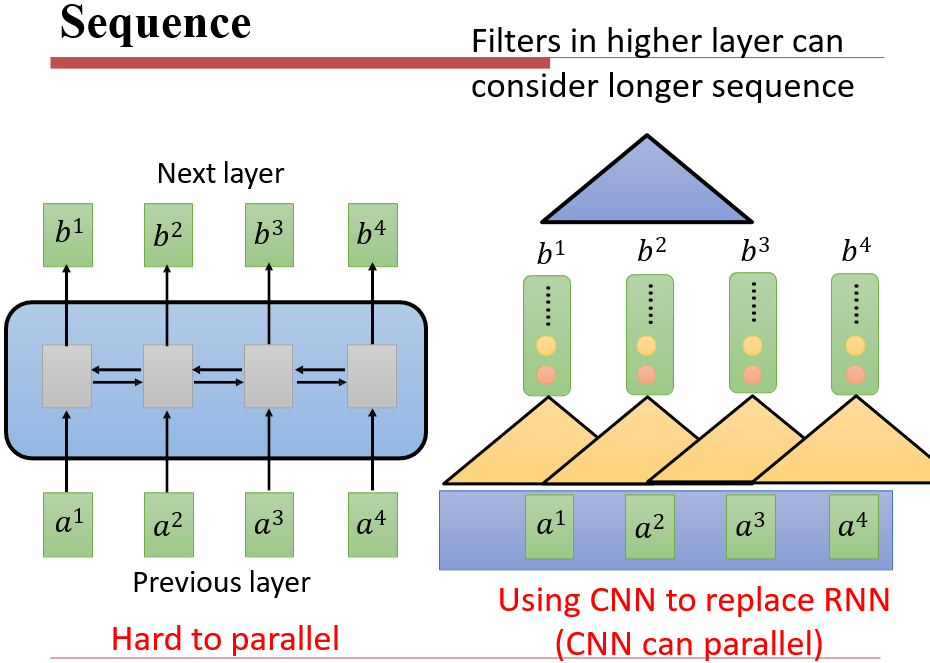
- 将RNN的模型隐藏起来,我们需要的实际上就是给定一段输入,返回一段输出
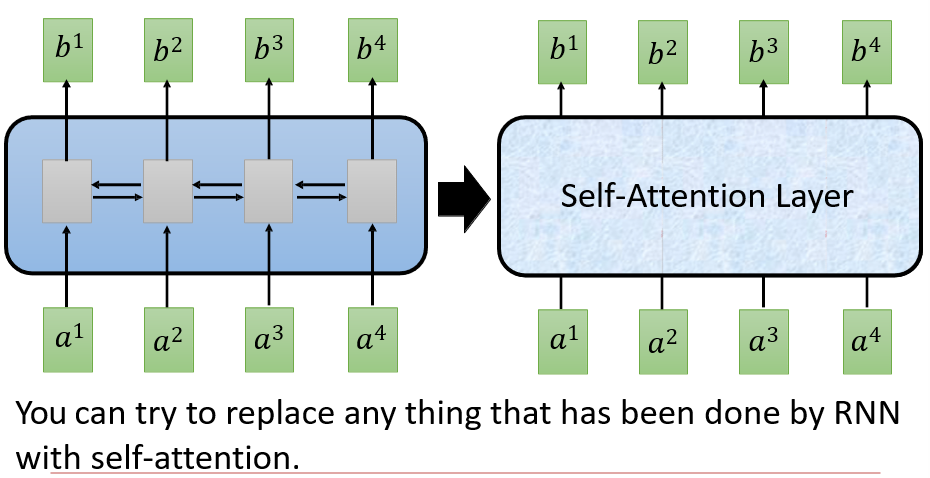
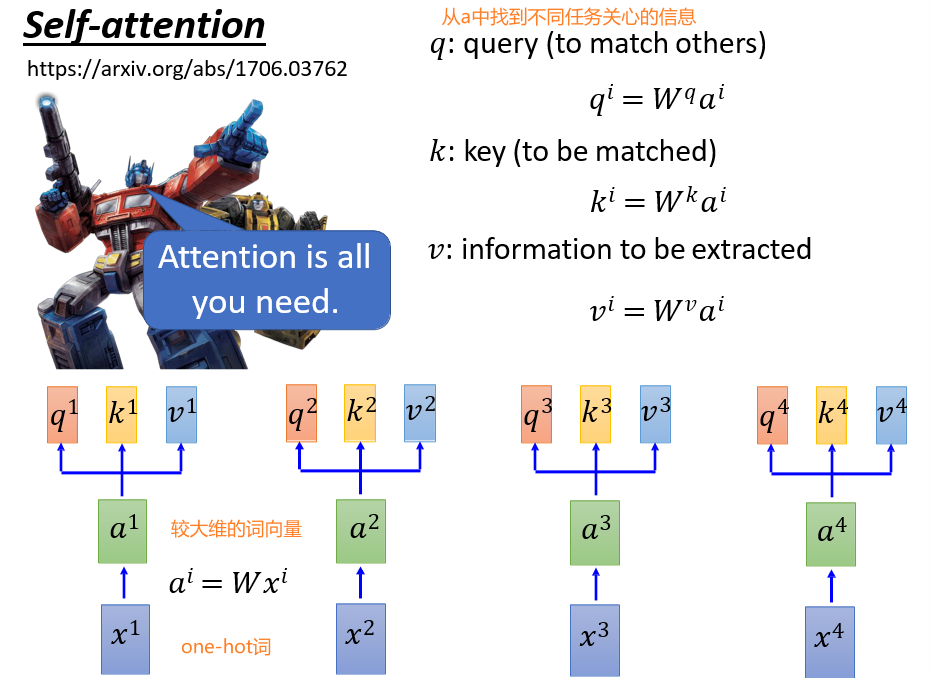
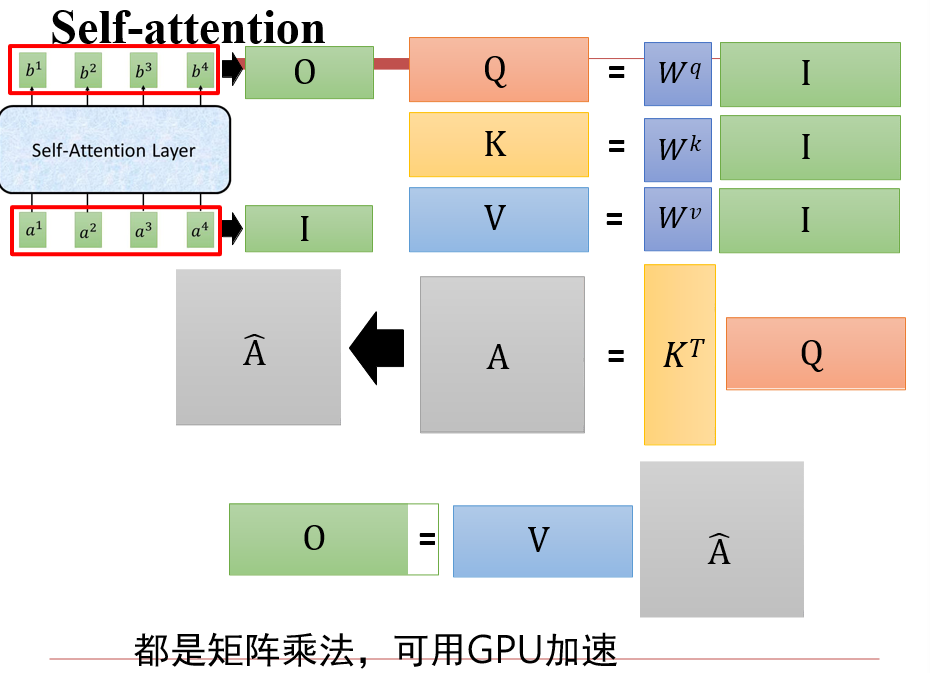
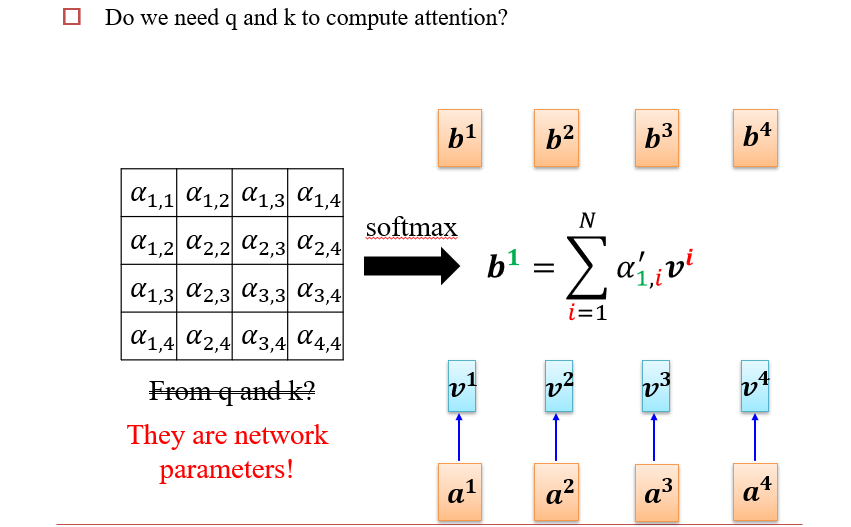
6.4.2 Self-Attention
- 注意力:用query查询key,将v返回
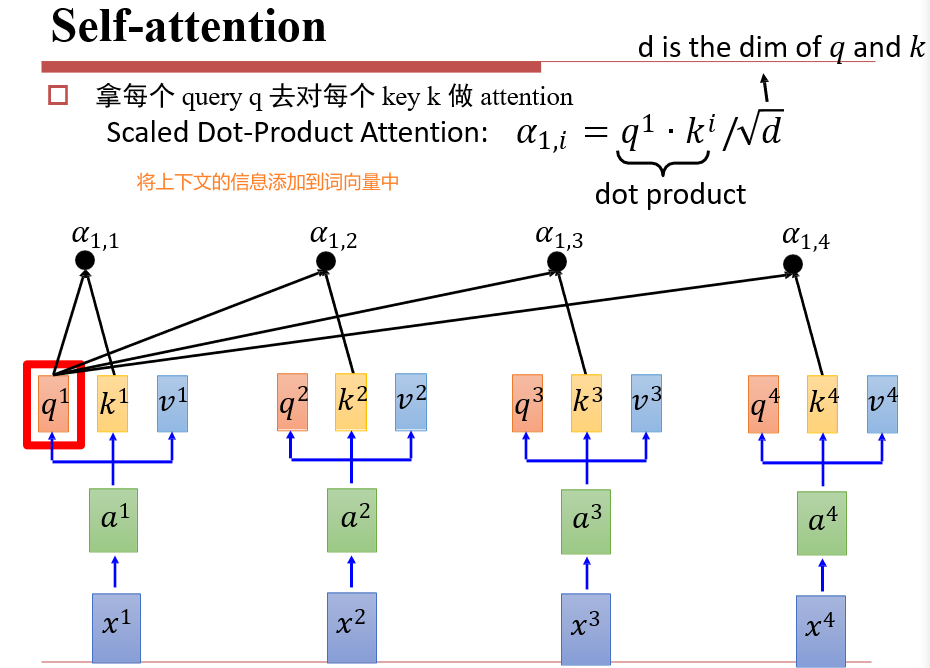
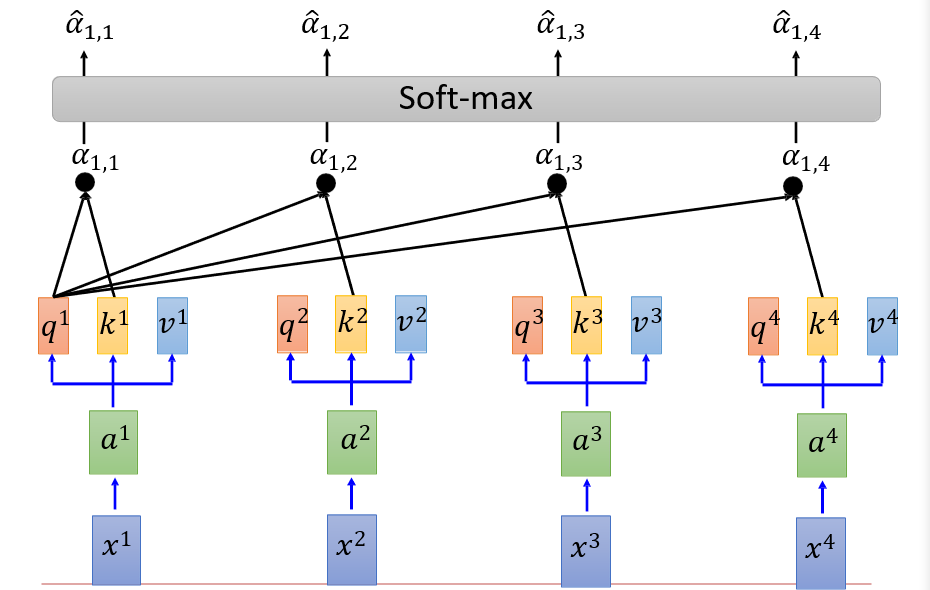
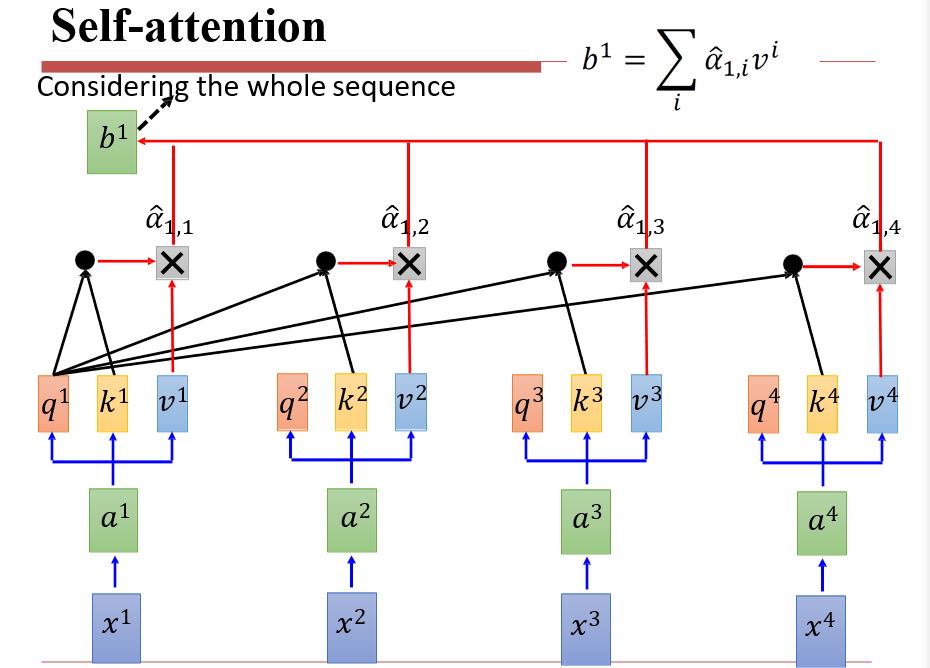
此时,我们对每一个ai,都输出了一个bi
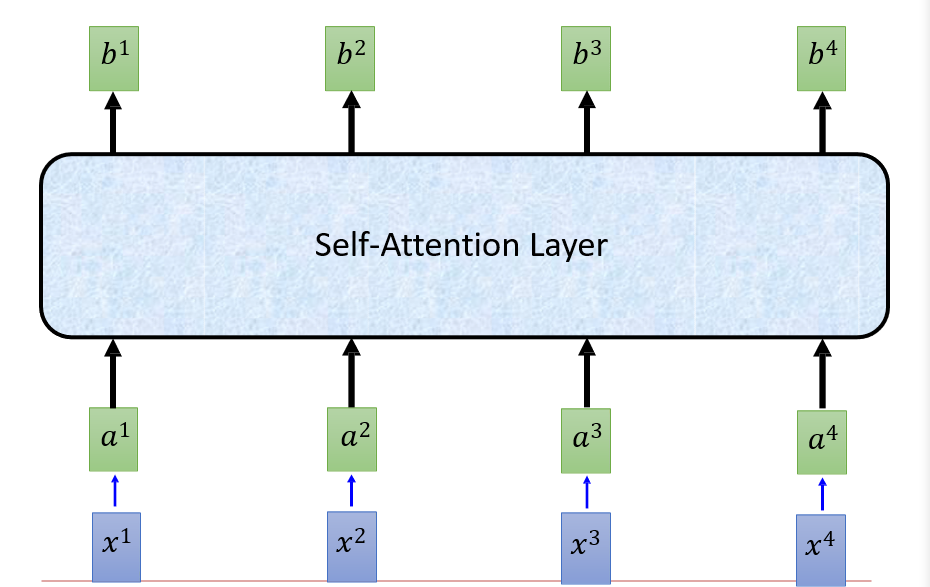
可以并行计算了
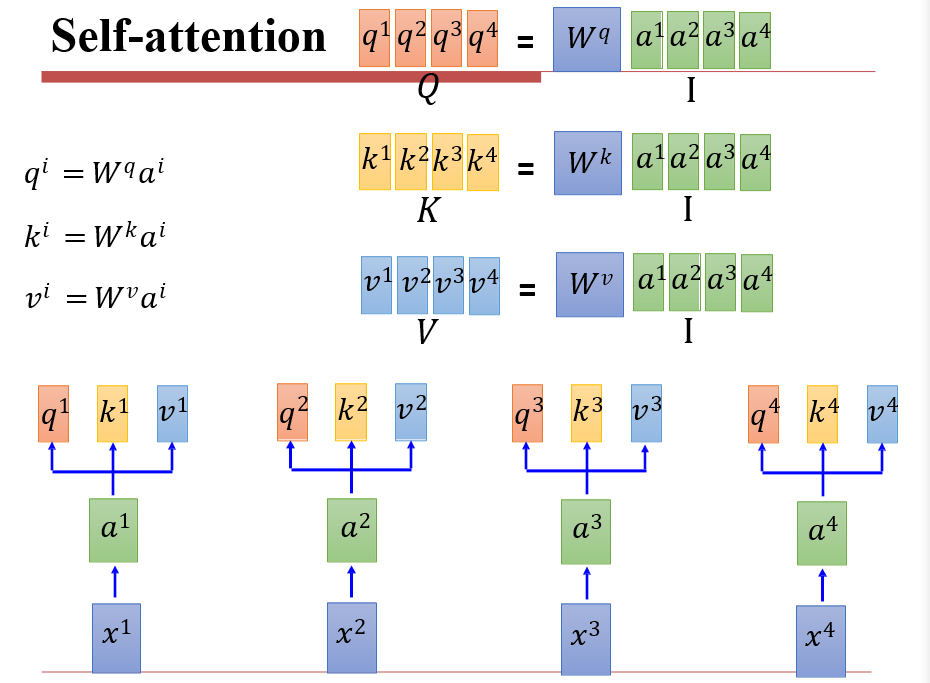
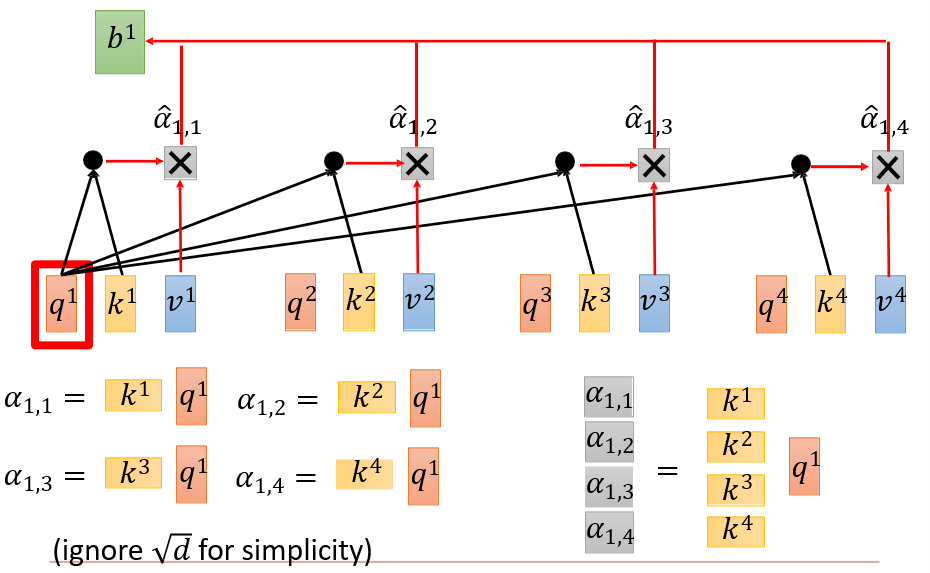
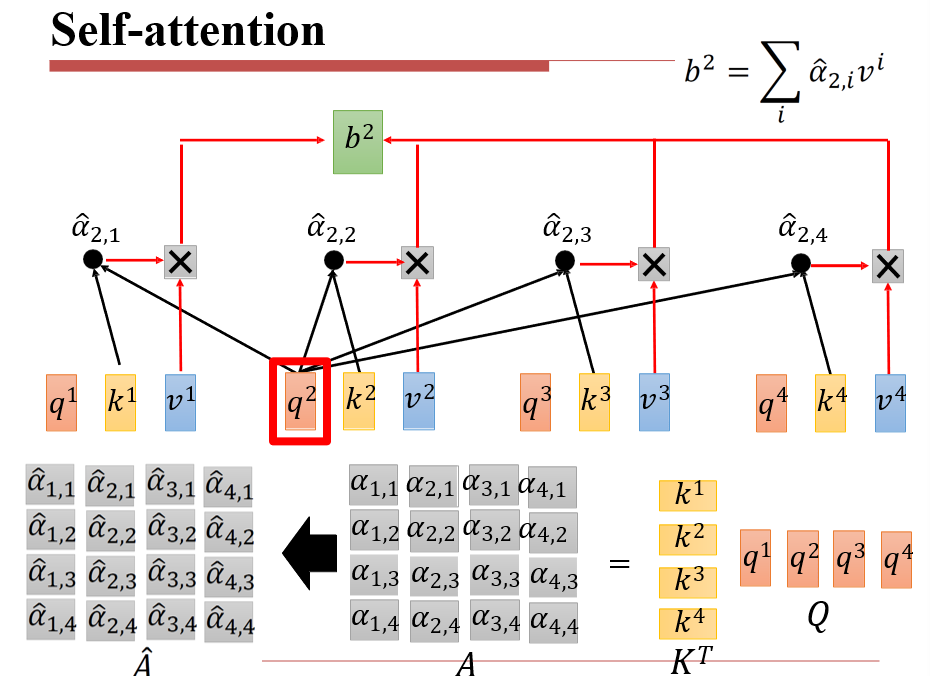
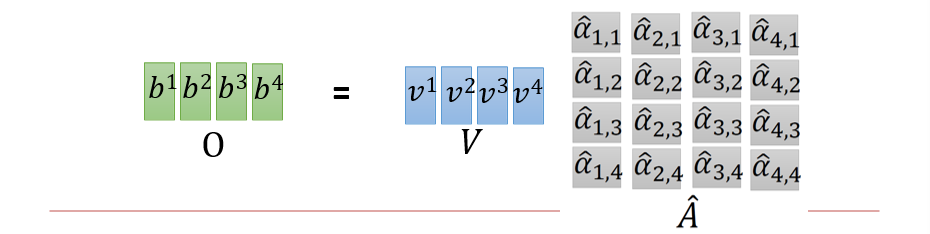
整个操作过程
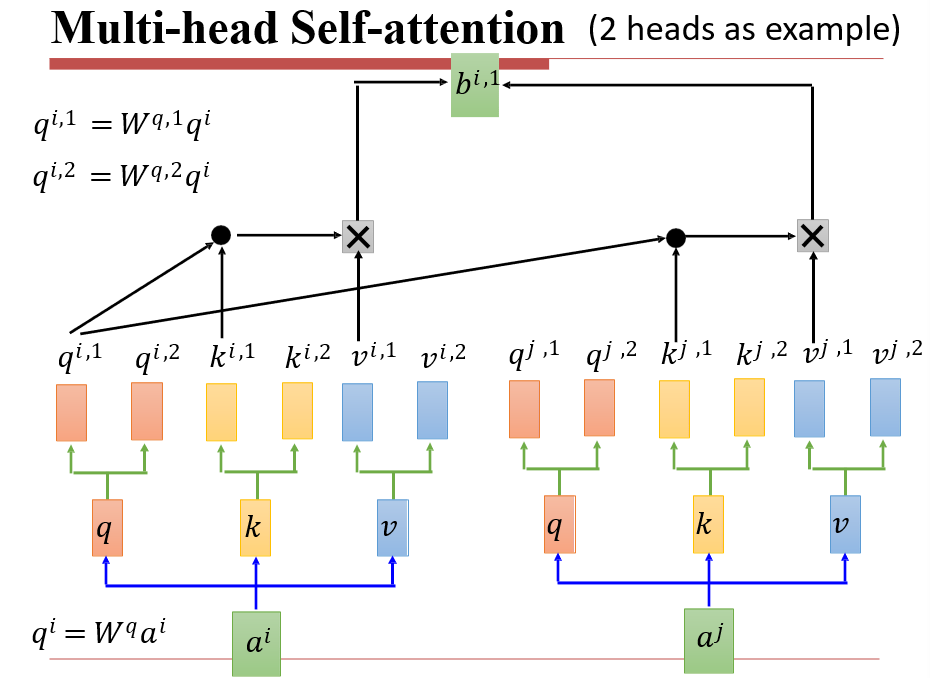
6.4.3 Multi-head Self-Attention
将得到的qkv矩阵分为两个,再进行操作
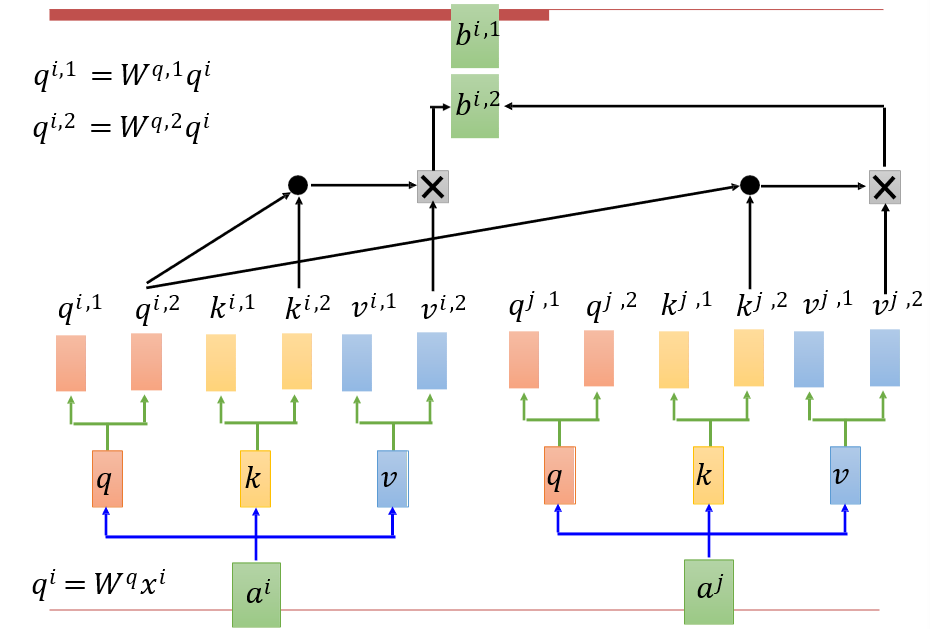
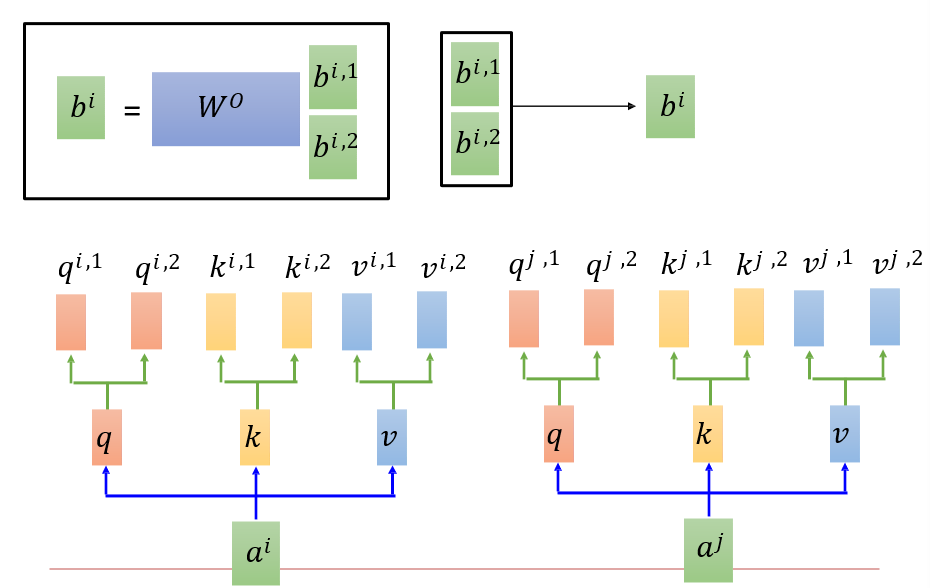
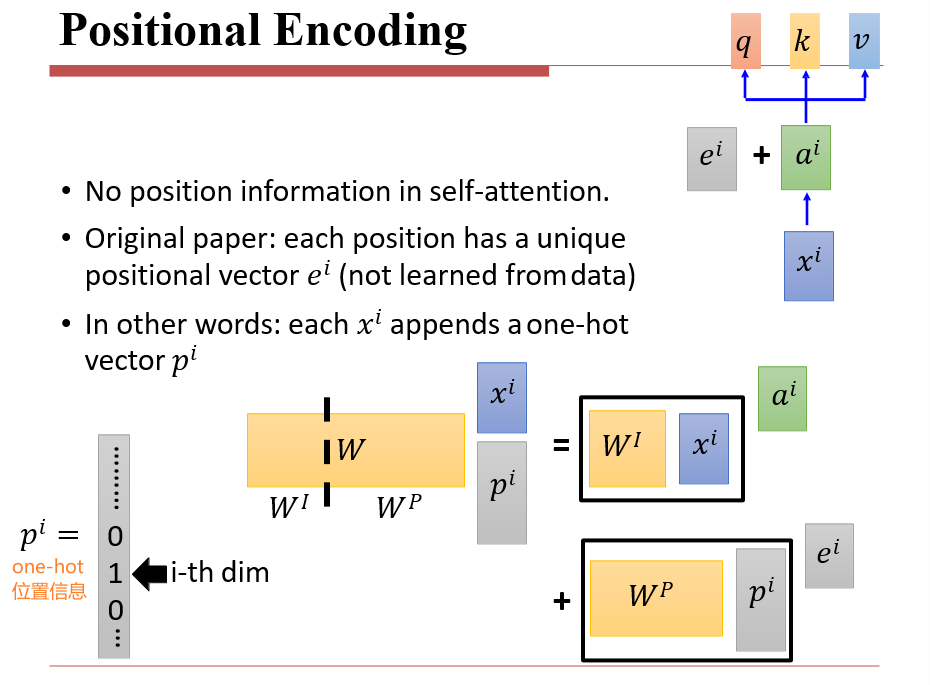
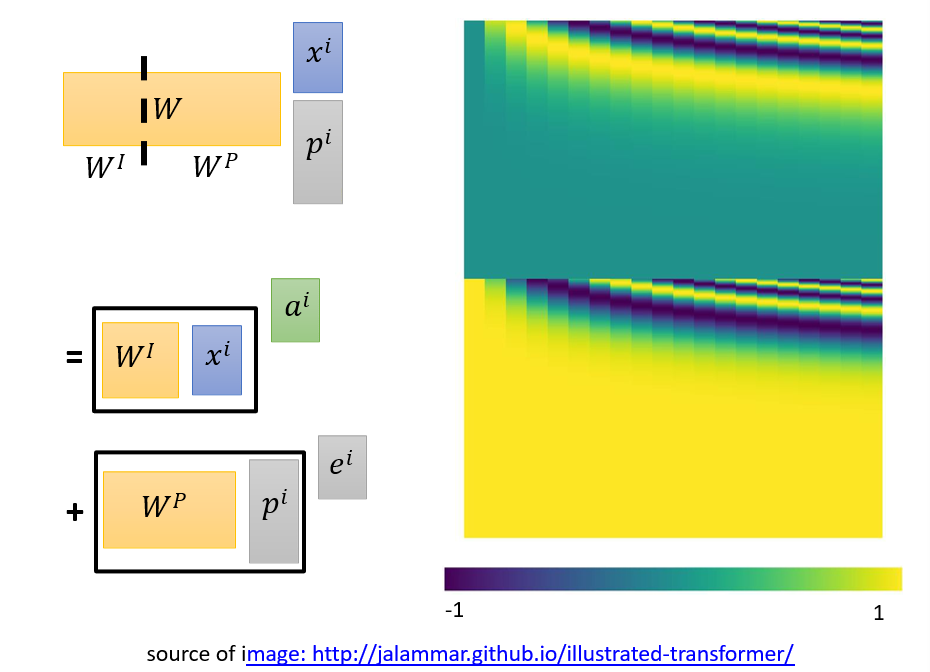
6.4.4 Positional Encoding
- 自注意力的缺点:没有顺序信息,ai可以任意更改顺序,只需要将bi更改对应顺序即可
- 位置编码:在词向量ai的基础上添加位置信息ei
- 既要求表示绝对位置,也要表示相对位置
6.4.5 Transform
- Decoder只能一个词一个词吐出来,无法并行
- 实际上只有Encoder变快了
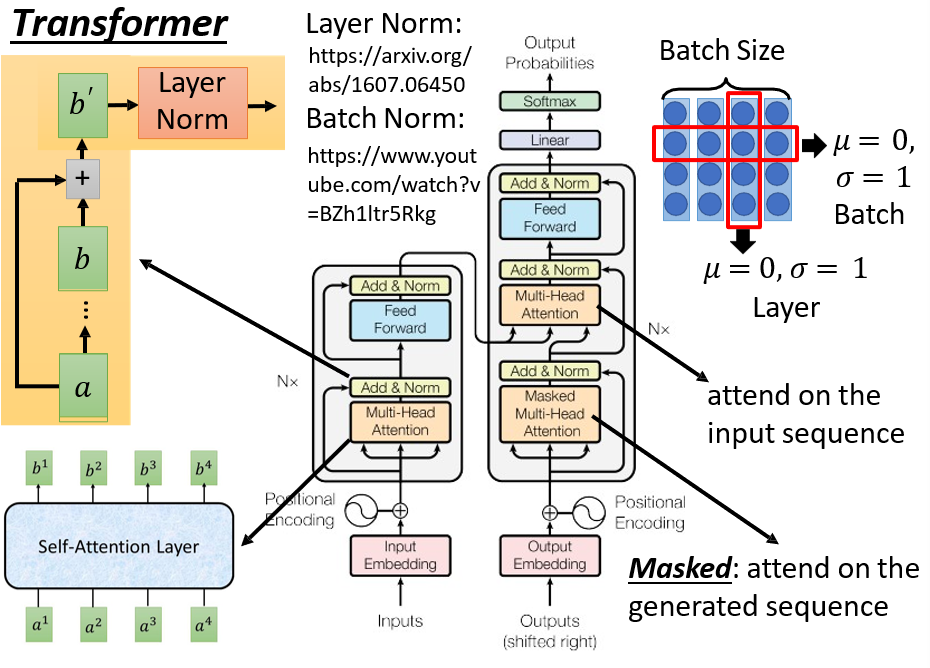
七、预训练模型:BERT和它的参数
预训练:体现在模型参数的初始值上
- 直接对目标任务进行训练,可能会因为数据不够而导致得不到好的效果
- 通过对预训练任务进行训练,调整模型的参数,然后再针对目标任务的数据进行训练即可
- 预训练任务与目标任务有一定的联系,但通常是两种任务
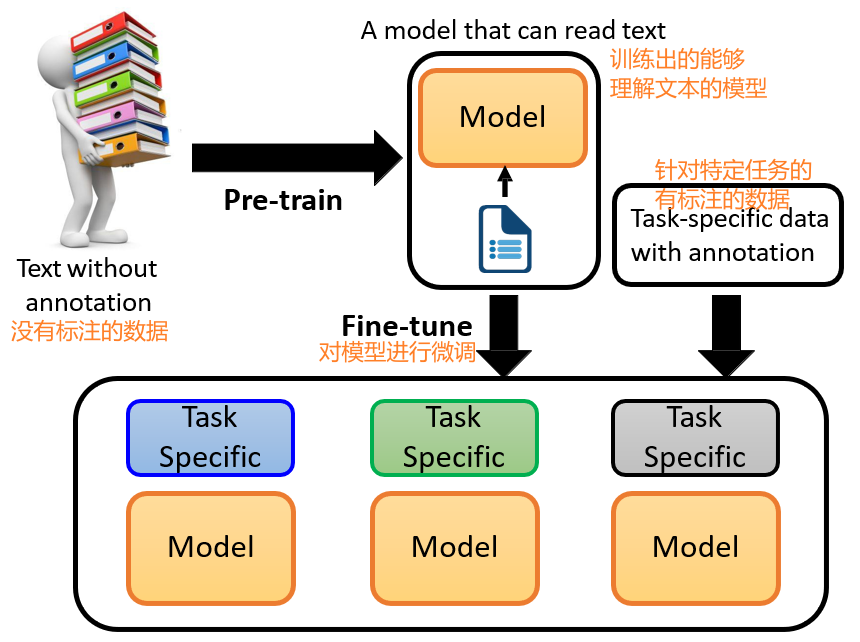
7.1 什么是预训练模型
- 词向量Word2Vec:本质是将高维向量进行低维投影,解决了一义多词的问题
- 训练时,需要一个字典×词向量维度的矩阵
- 使用时,相当于进行了一次查表操作
- 上下文相关的词向量Contextualized Word Embedding:将单词与上下文联系在一起,作为输入
- 预训练模型很多都是计算的词向量模型的变种
7.2 如何使用预训练模型:fine-tune
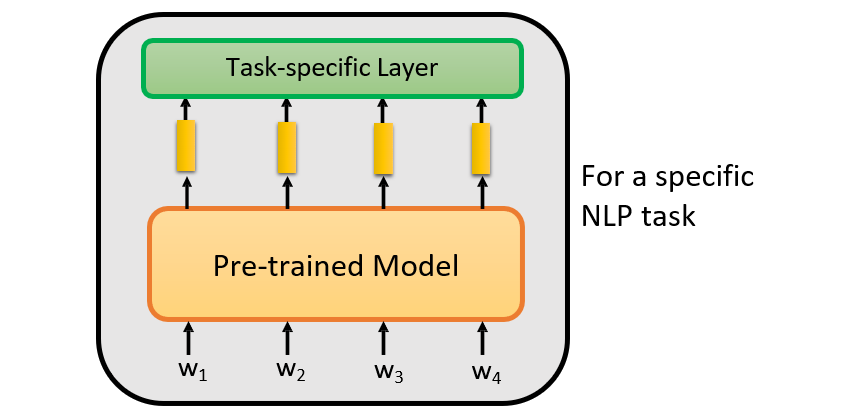
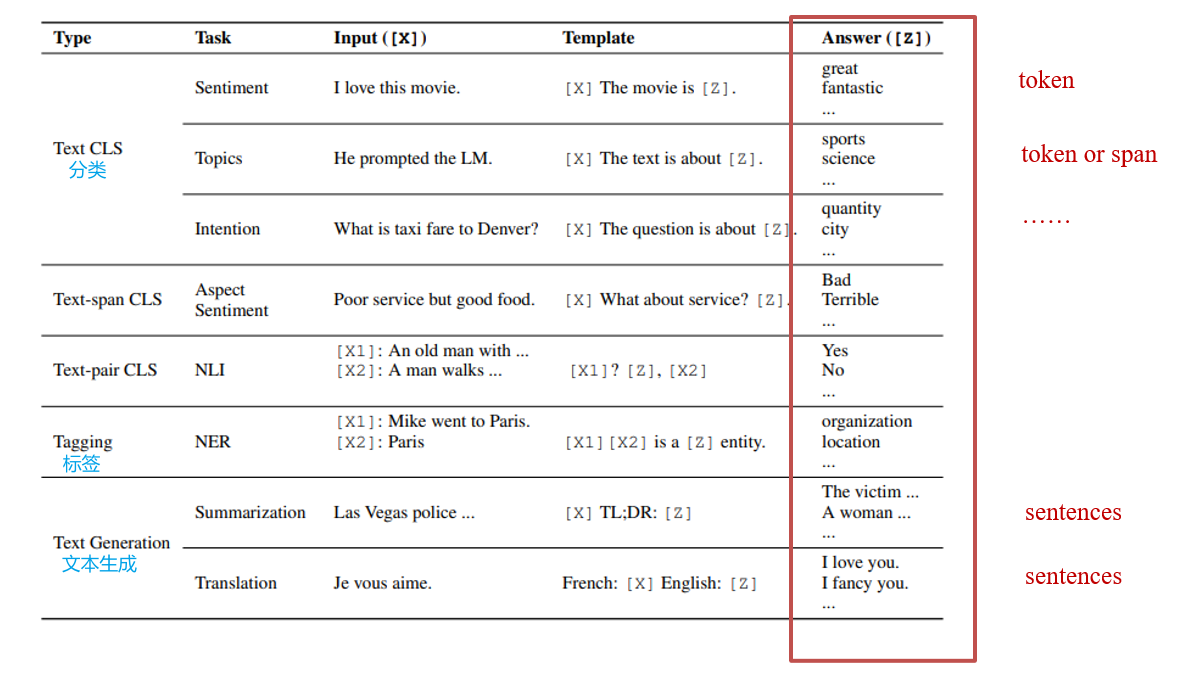
7.2.1 NLP的常见任务
- 输入:一个句子、多个句子
- 输出:分类、每个token的分类(如专有名词的类别)、从输入中取特定的部分(概括文章主旨)、句子(对话系统、风格转化、翻译)
7.2.1.1 输入:多个句子
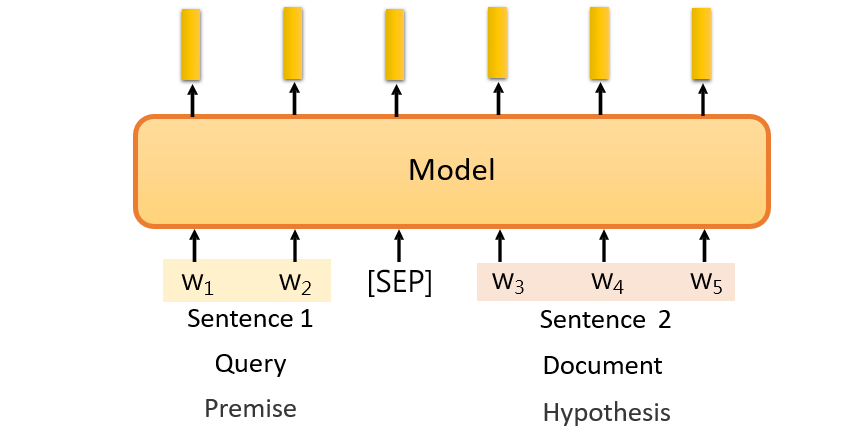
7.2.1.2 输出:分类
- 输入中添加一个特定的token
[CLS] [CLS]对应的输出,即为最后的分类信息
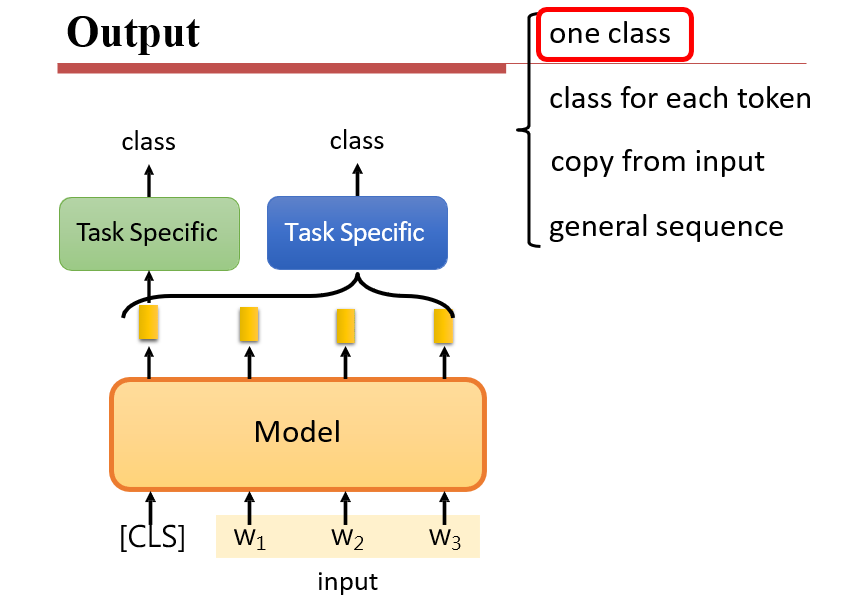
7.2.1.3 输出:每个词的分类
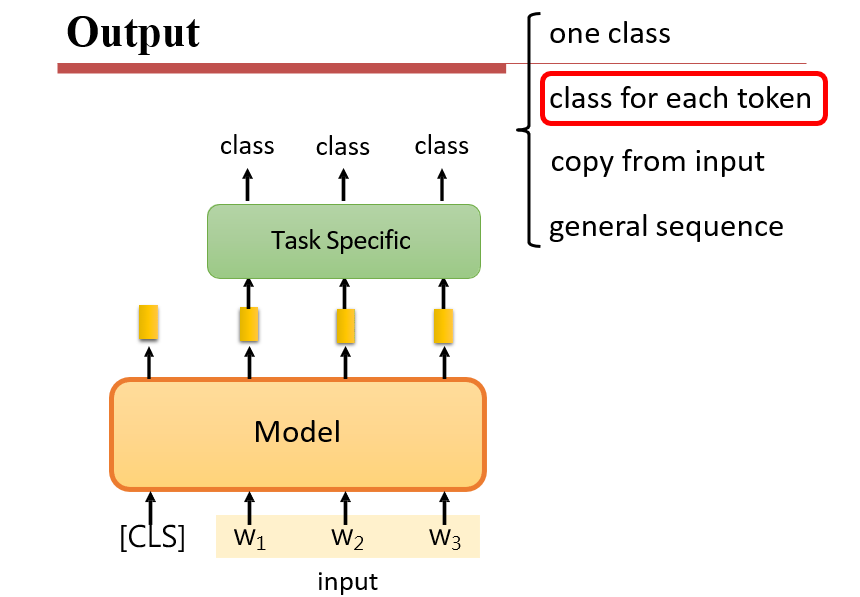
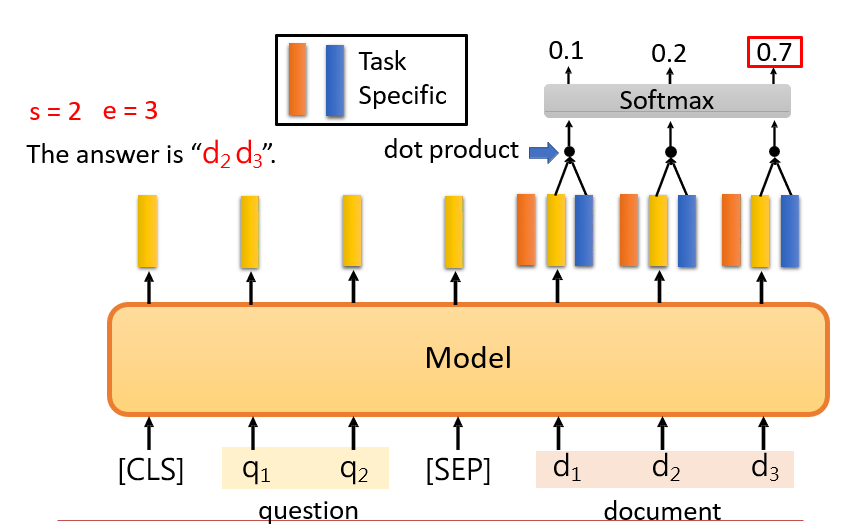
7.2.1.4 输出:从输入中取特定的部分
- 将question作为一个向量,与document中的单词计算注意力
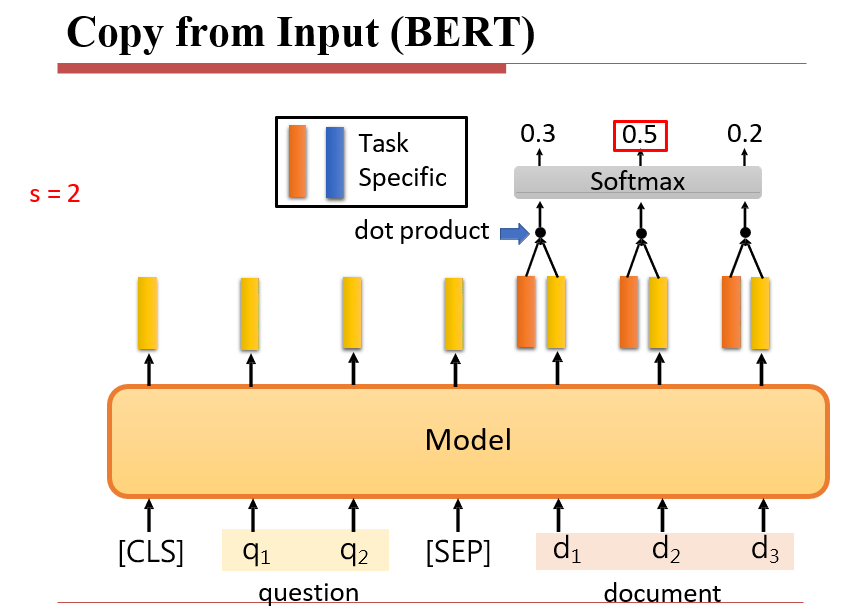
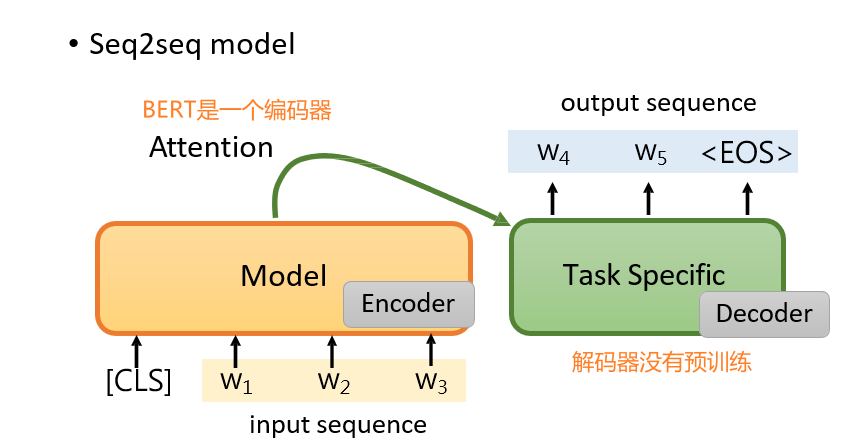
7.2.1.5 输出:另一个序列
方法一:
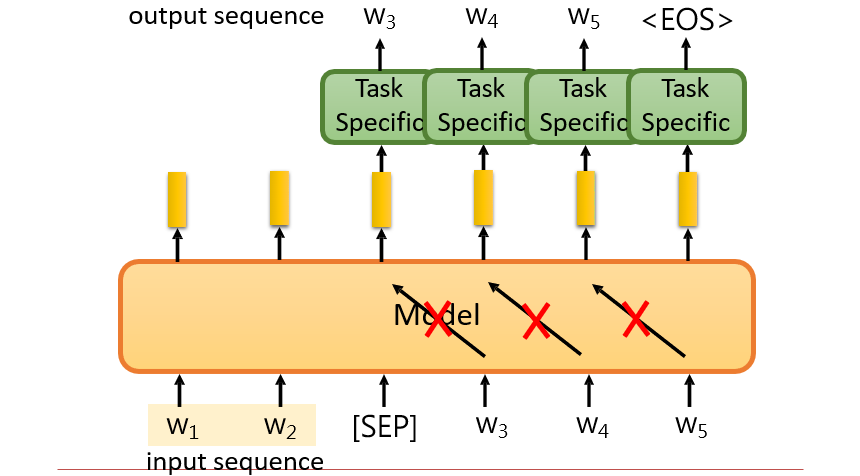
方法二:前面一部分做编码器,后面一部分做解码器,中间添加一个特殊字符
[SEP]需要有机制防止"偷看"
7.2.2 微调预训练模型 fine-tune
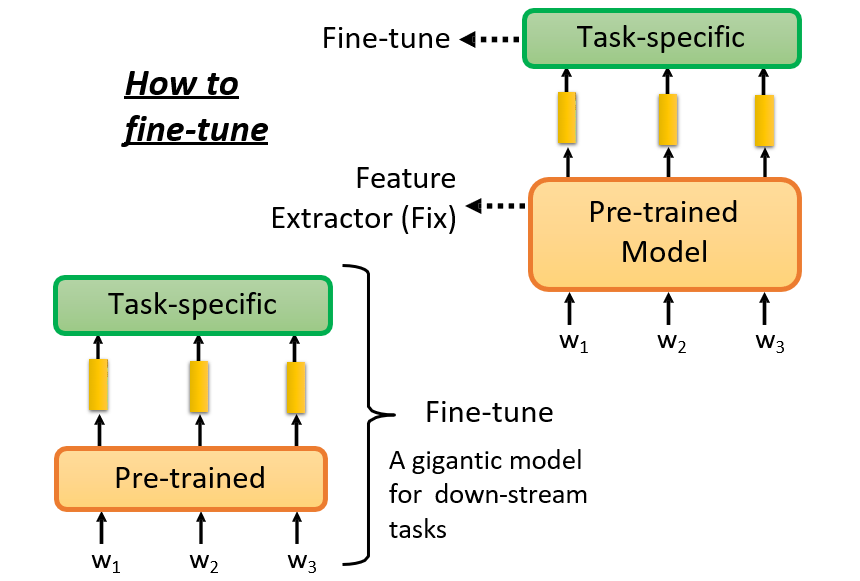
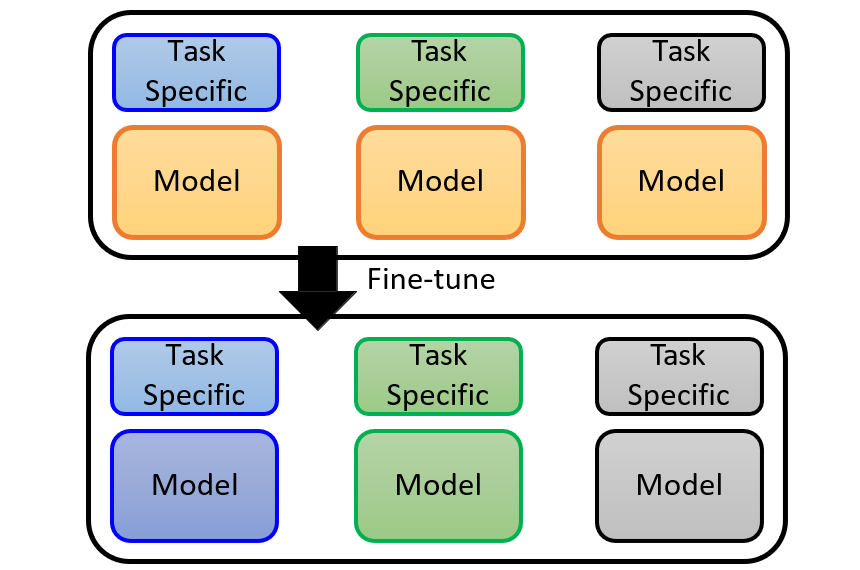
7.2.2.1 直接对模型进行微调
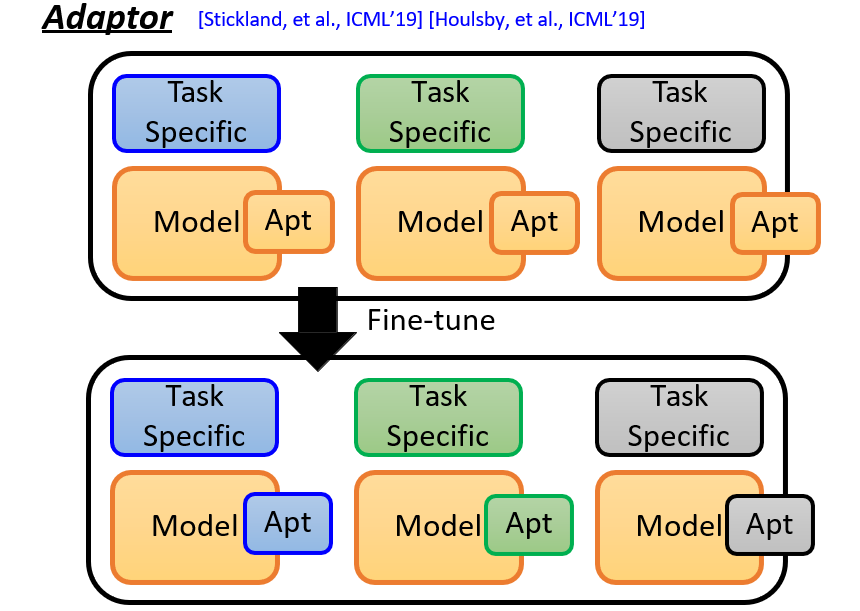
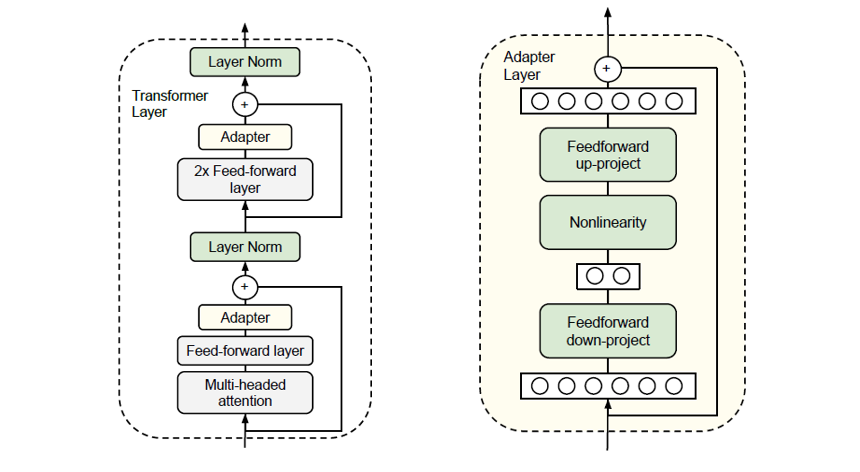
7.2.2.2 在模型上面添加一个可变部分 Adaptor
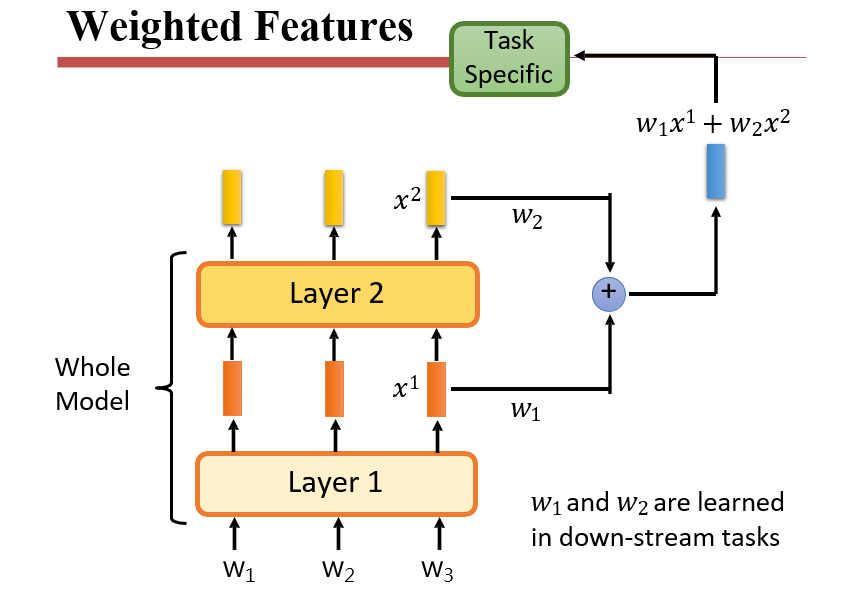
7.2.2.3 调整参数的权重
- Weighted
Features:学习一系列的权重,将每层的输出按权重组合起来,作为最后的输出
- 如ELMo,它会训练出三个vector,一个是原本的vector,一个包含了之前的单词信息,一个包含了之后的单词信息。
- 实际输出时,学习权重,将三个vector拼起来
7.3 如何得到预训练模型
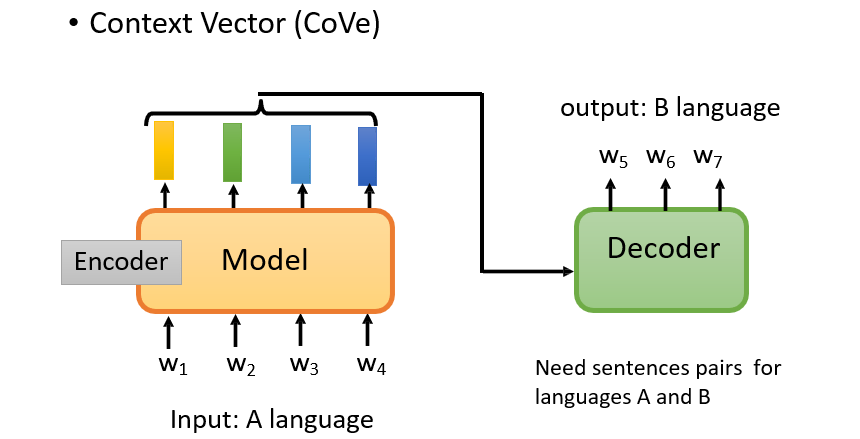
7.3.1 通过机器翻译进行Pre-training
Context Vector:CoVe
- 不能通过句子分类进行预训练:因为句子分类只需要句子中出现某些特定的组合即可分类,并不能用到所有的词
- 而翻译需要句子中每个词的含义,进行一一对应
- 问题:需要有一个Decoder,并且需要有配对的数据
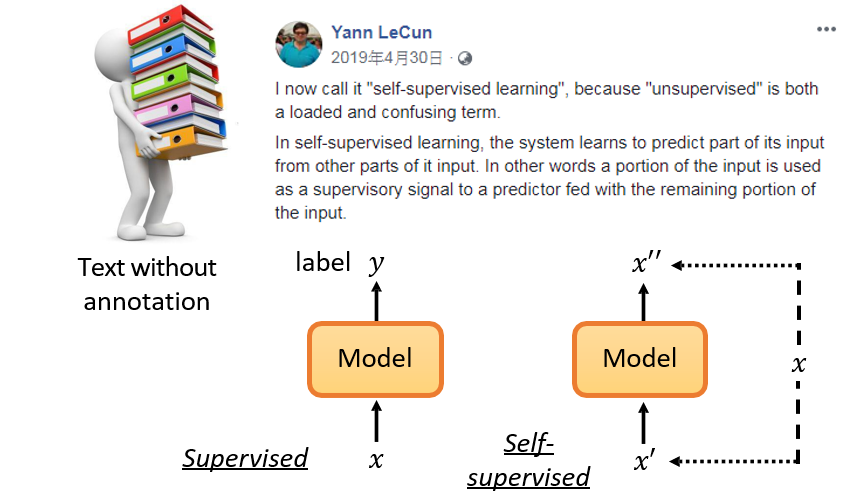
7.3.2 自监督学习 Self-supervised Learning
- 监督 <=> 标签
- 词向量的训练需要监督,但是标签是机器自己标记的,并不需要人去标记
- 自监督:从数据中拆出一部分,作为标签,监督另一部分的数据
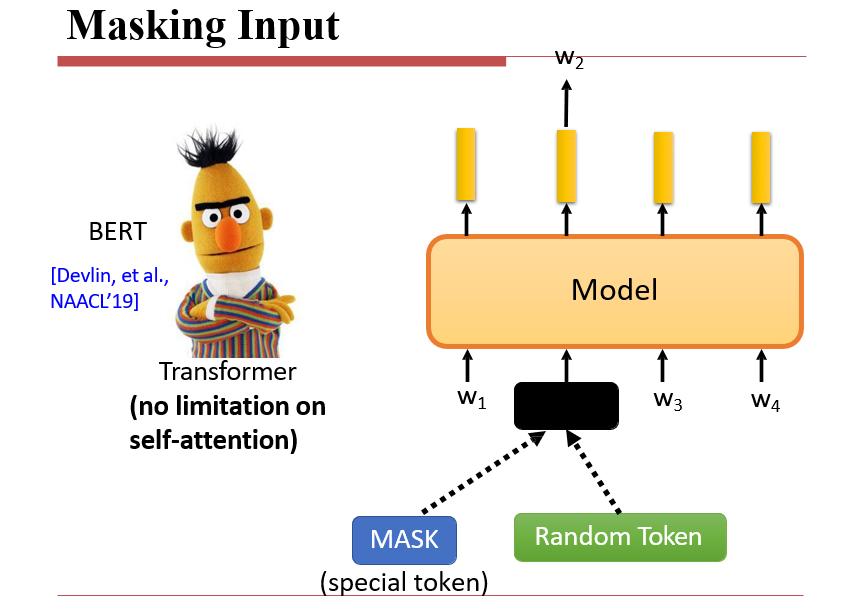
7.3.3 如何让一部分的数据作为监督信号:Masking Input
BERT
- 将某个token掩盖掉,让模型还原这个词
- 带还原的词就是监督信号
- 有时不是直接mask掉某个token,而是将这个token换为另一个token

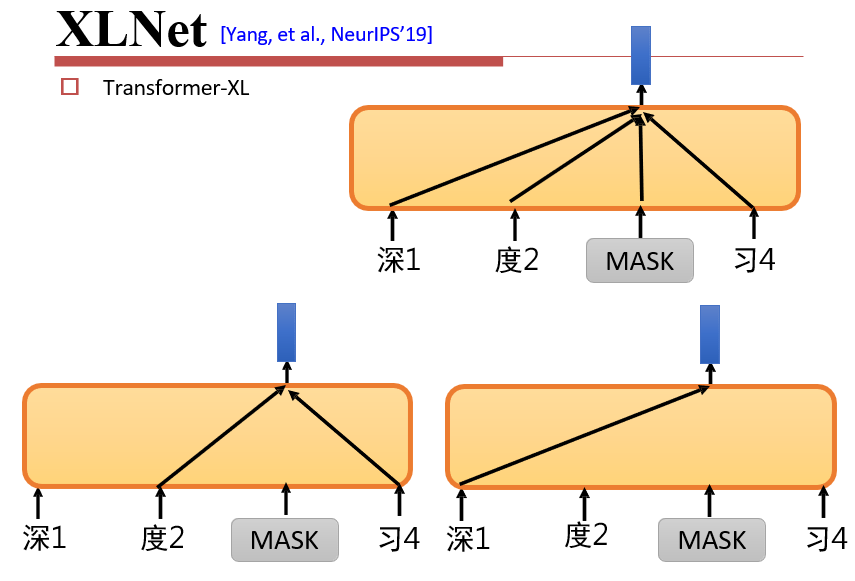
7.3.4 XLNet
随机将某些传递边删除
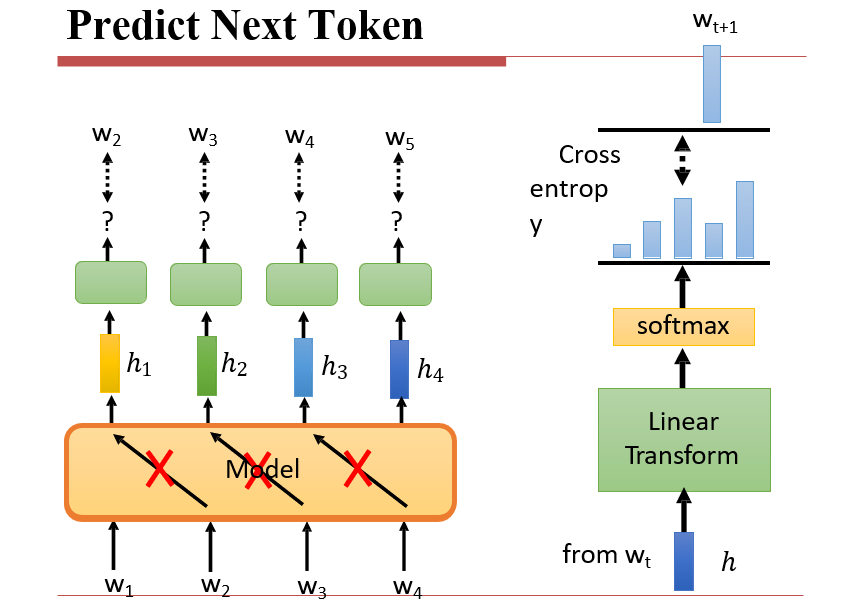
7.3.5 预测下一个token
用Transformer的编码器预测下一个token
- 因此输入的时候会将输入w1与输出w2同时送进去
- 因此需要在模型的传递时,不让w2影响w1的输出,防止模型选择直接将w2输出
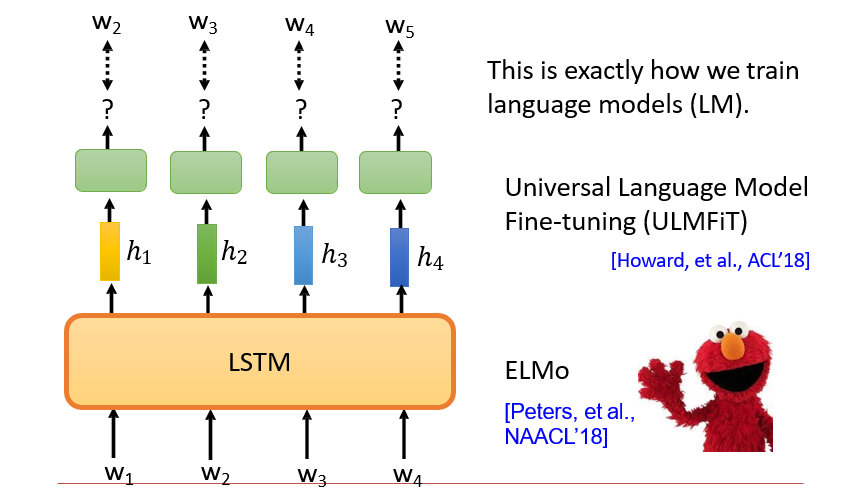
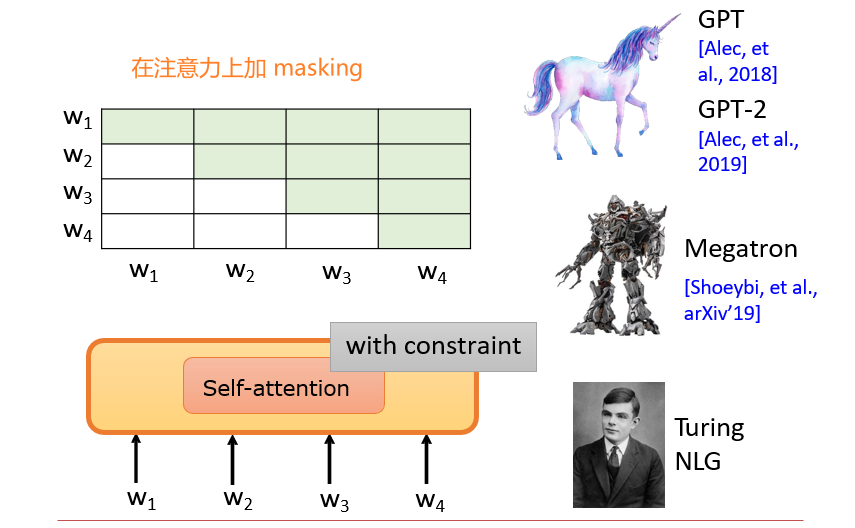
7.3.6 用BERT编码器做生成任务
MASS / BART
- 输入的x是带噪音的
- 要求输出正确的x
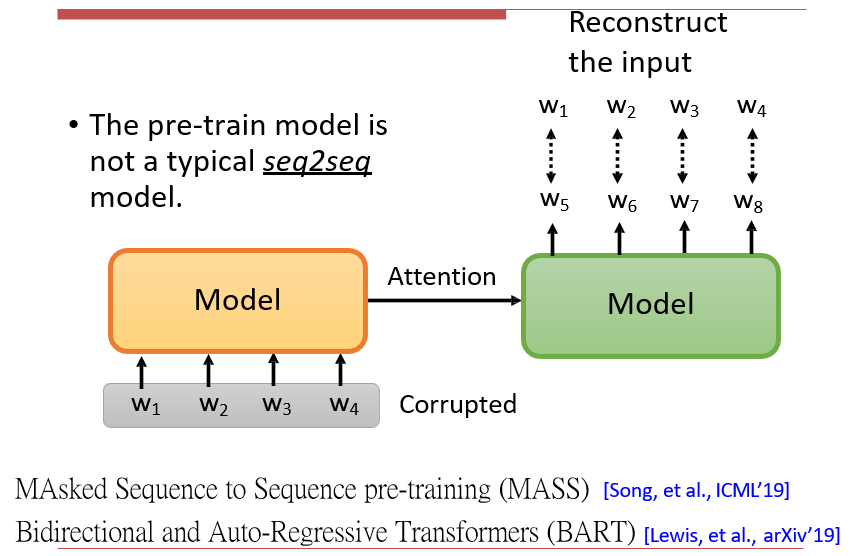
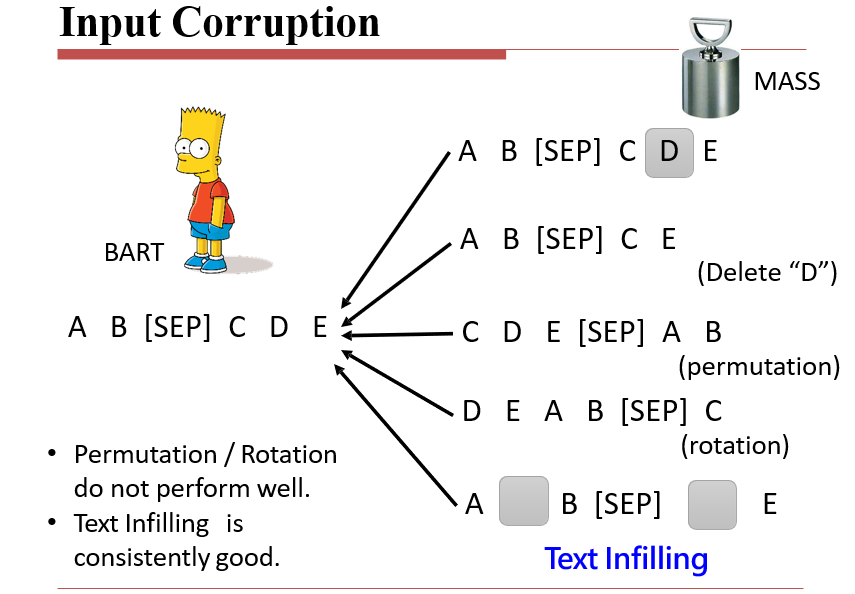
MASS:
- 将某个token遮盖住
BART:5种方法破坏输入
- 将某个token遮盖住
- 删除某个token
- permutation:将输入和输出交换
- rotation:将输出的某些部分放到输入里面
- text infilling:删除某些token并用mask替代他们
翻译时,由于结果是同时输出的,因此可能会出现"哈好"、"你喽"之类的错误输出
- 将第一次输出的结果,放入模型中进行评估,将错误的词进行mask,然后再放入BERT中进行生成
- 重复这一过程,直到结果较好
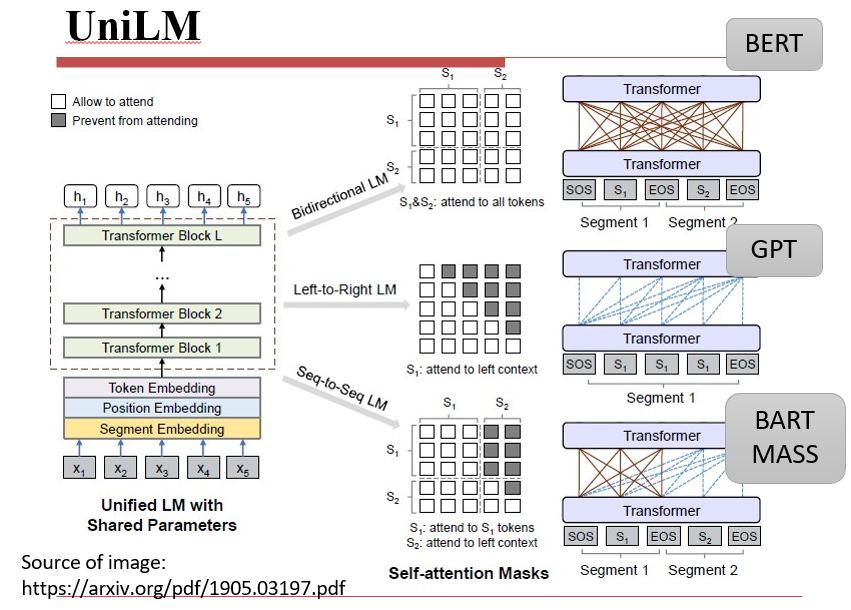
7.3.7 UniLM
用一个模型将BERT、GPT、BART/MASS结合起来
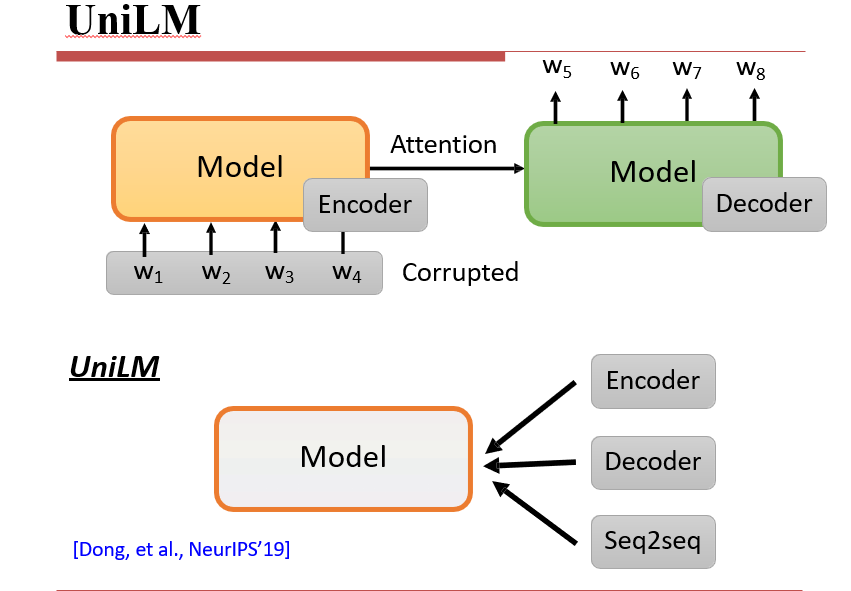
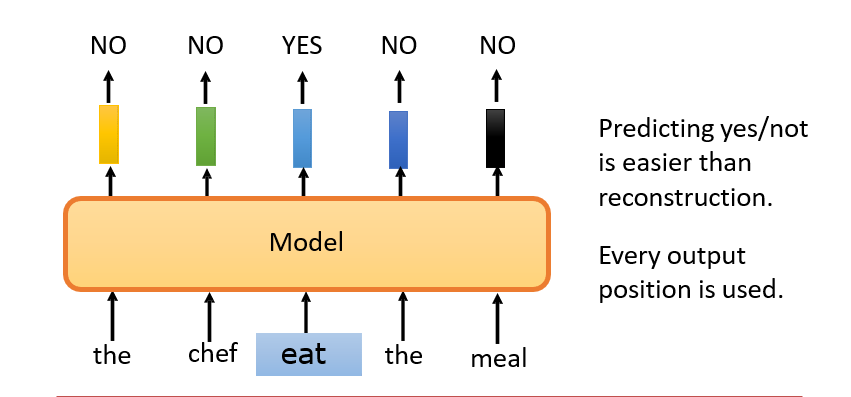
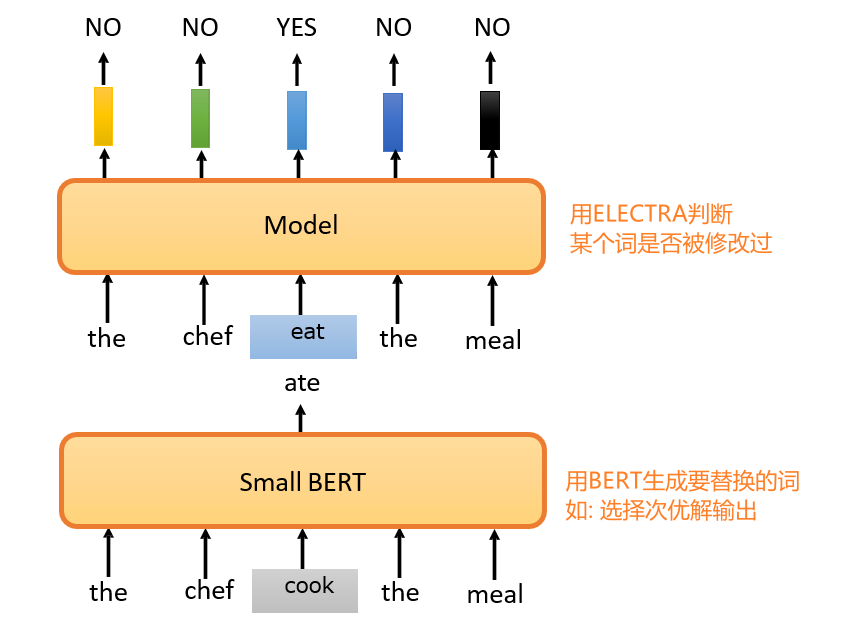
7.3.8 ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA)
判断输入中的某个词是否被修改过
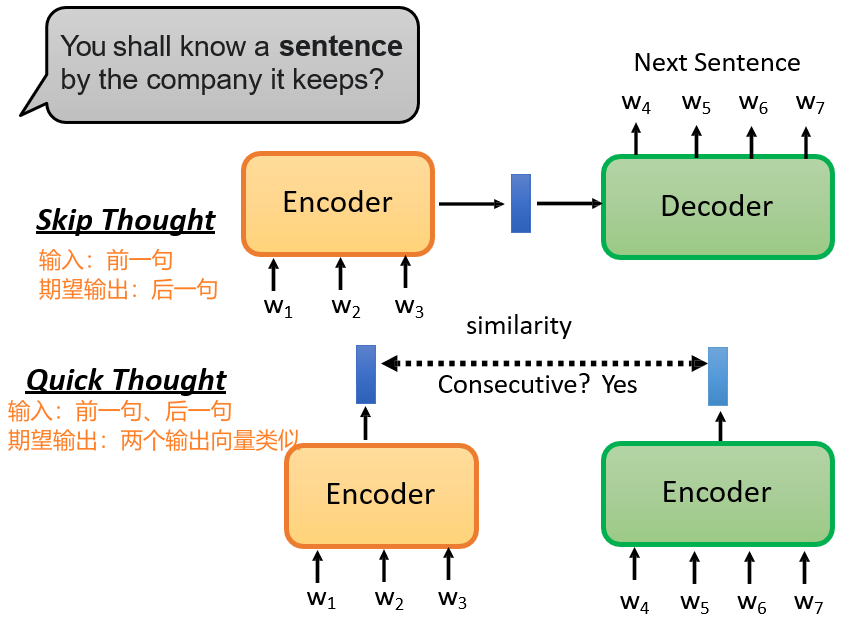
7.3.9 Sentence Level
进行语句级别的预训练
7.4 BERT的变种
7.4.1 ALBERT
减小BERT的参数
将词向量先做降维,在用的时候再升维,存储只存储降维后的向量
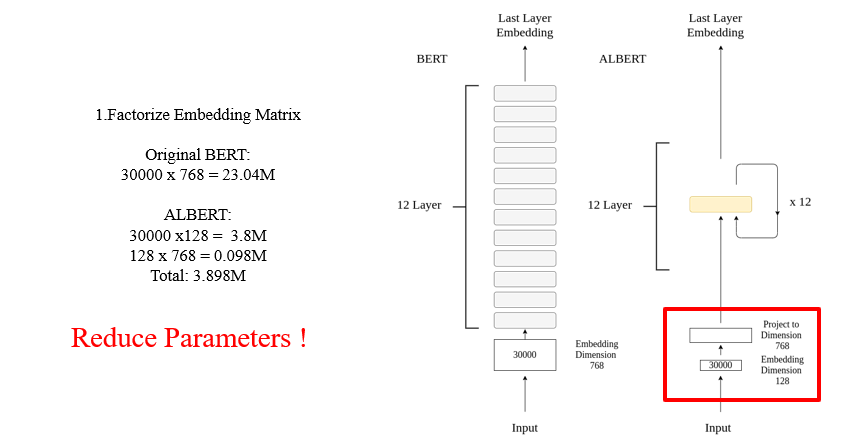
不同层之间共享参数
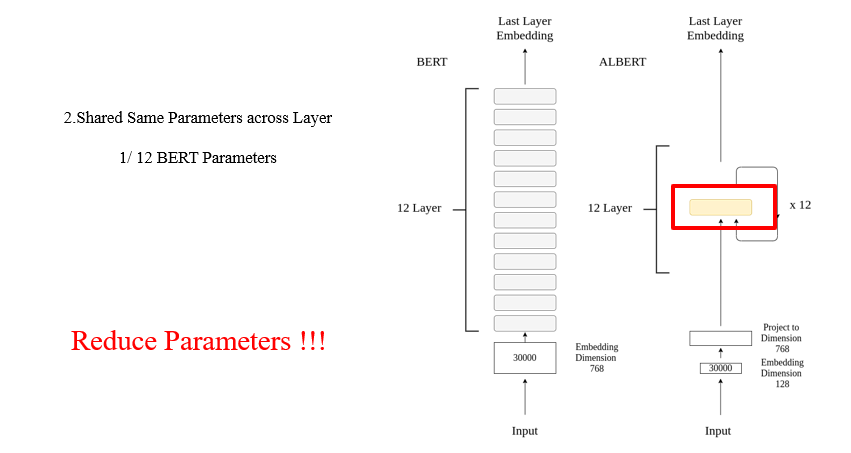
语句级别的预训练任务:判断句子的顺序

八、使用高效Transformer建模长句子
文档级别的语言建模
8.1 Transformer-XL
Transformer-XL : Truncated BPTT + Transformer
- 将文章分解为一块一块的
- 每一层均可以向前看一步
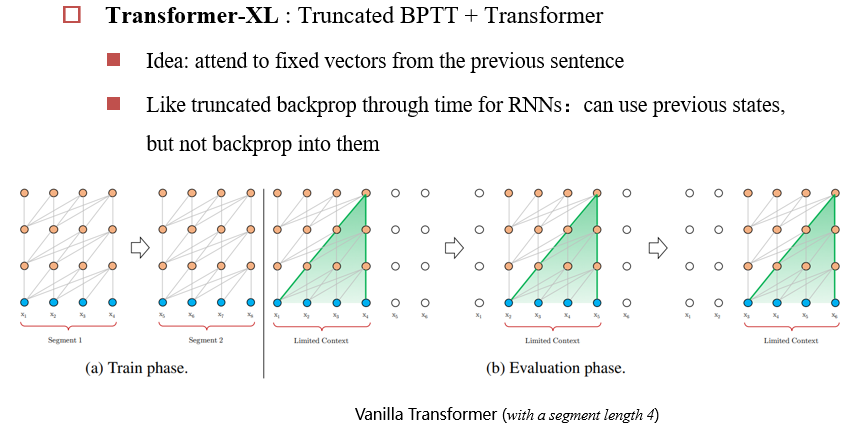
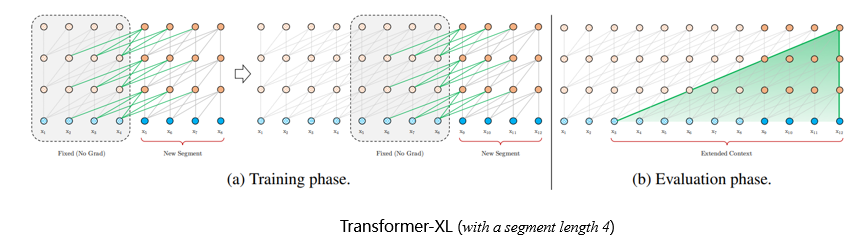
8.2 优化Self-attention
设句子的长度为N,则注意力计算需要进行N*N次,因为每个词均需要对所有剩下的次进行一次自注意力判断
Transformer的快与慢:当显存足够时,计算是很快的;当显存不足时,需要使用很多方法模拟显存足够的情况。类似于C中的大整数乘法需要用一个数组模拟
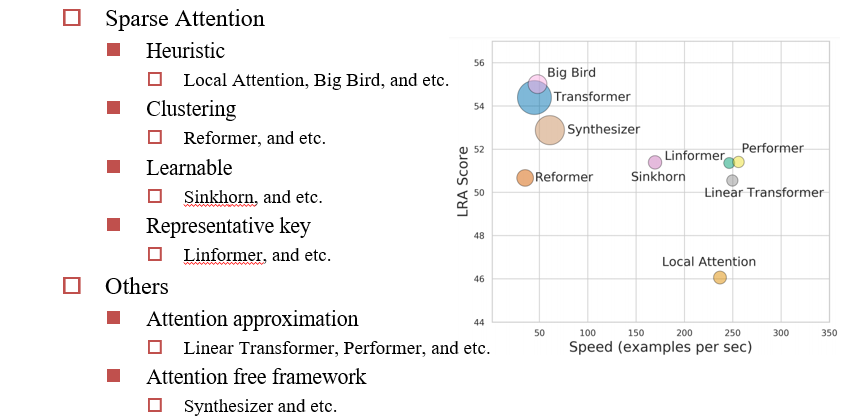
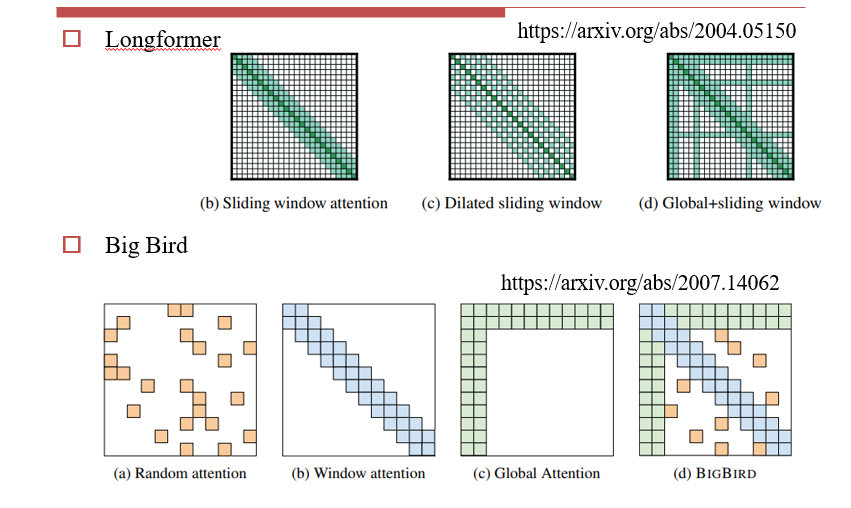
8.2.1 Sparse Attention:少算一部分
8.2.1.1 Heuristic:启发式的,设计计算方法以减少计算量
Local Attention:设置window size,每个词只能看到与它相邻的词
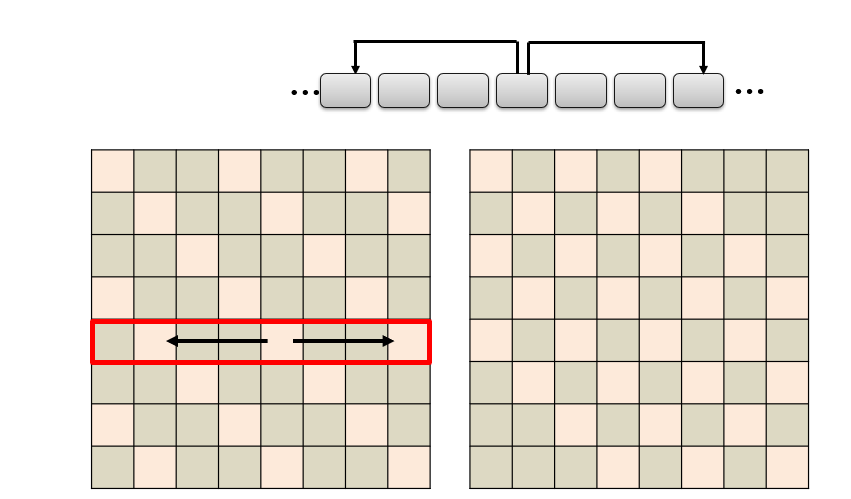
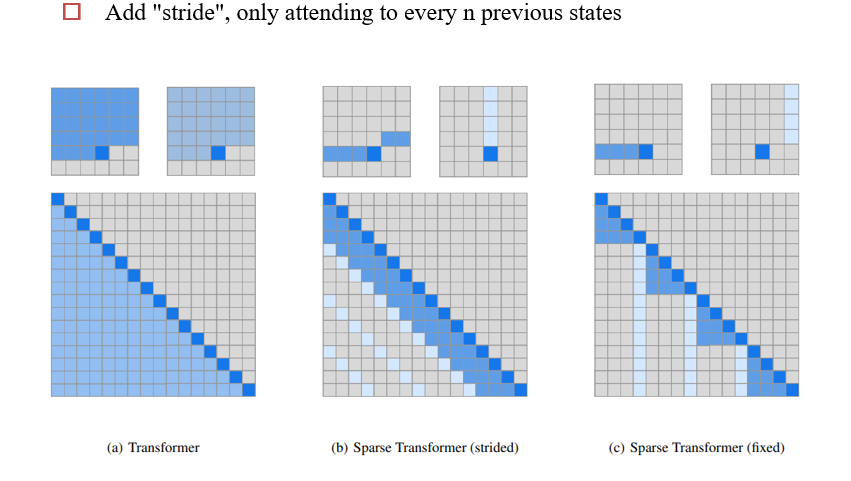
Stride Attention:跳着做自注意力
Global Attention:每个词均与Global计算自注意力
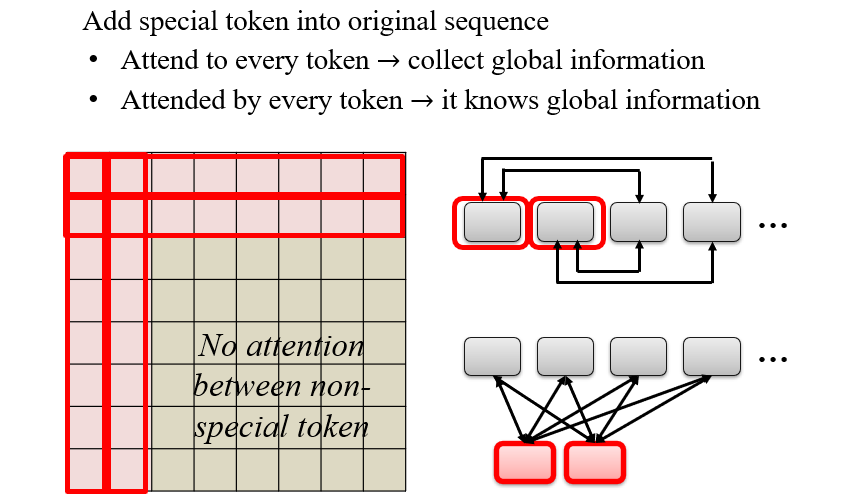
其他方法:
Sparse Transformers
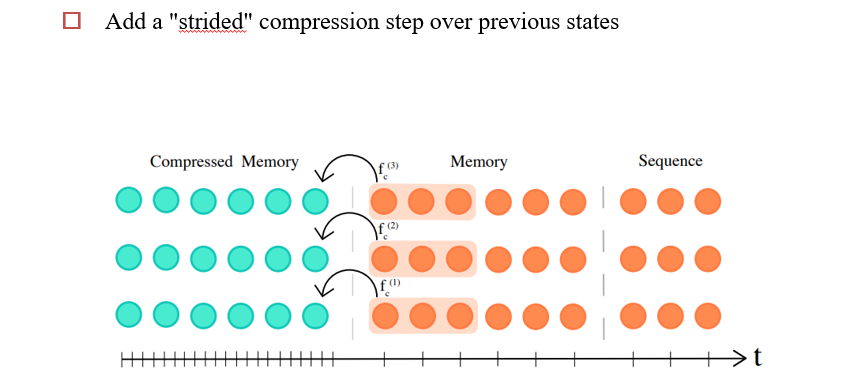
Compressive Transformers
Adaptive Span Transformers
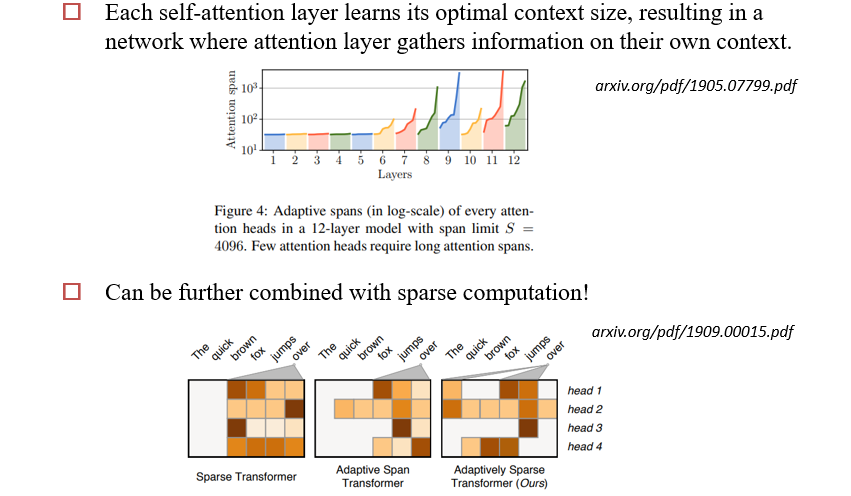
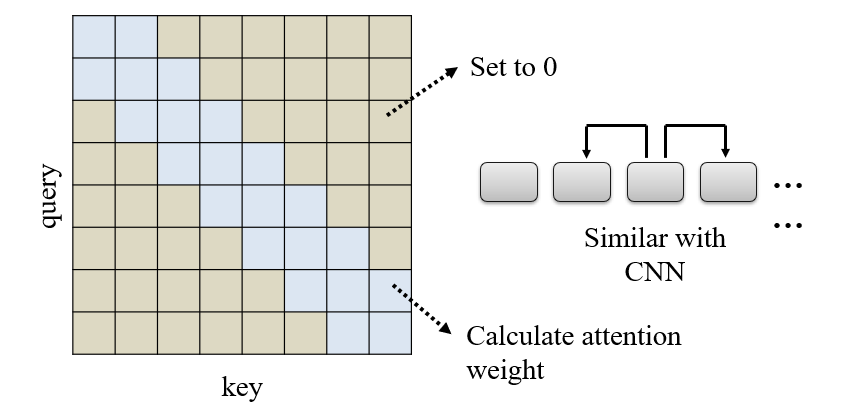
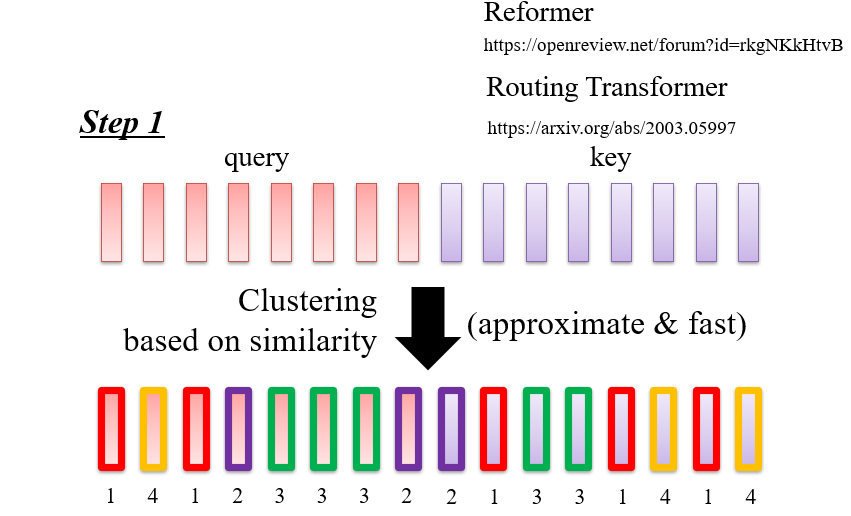
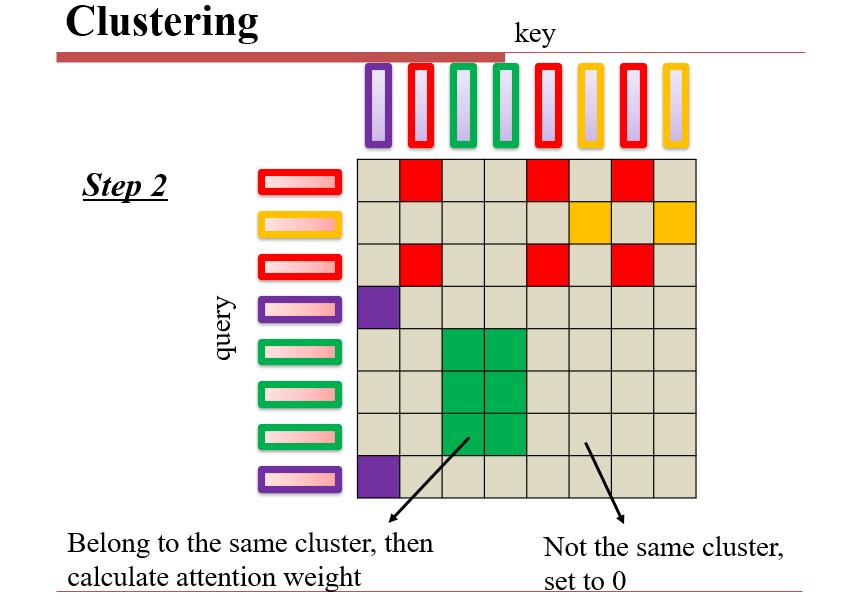
8.2.1.2 Clustering:聚类
如:Reformer
估计自注意力的计算结果,只考虑结果较大的部分,较小的部分直接设成0
- 当query和key比较像的时候,attention比较大
- 因此可以先做聚类,分为几个类,然后在类内进行自注意力计算
- LSH:学习一个Hash函数,让长得像的东西离得比较近
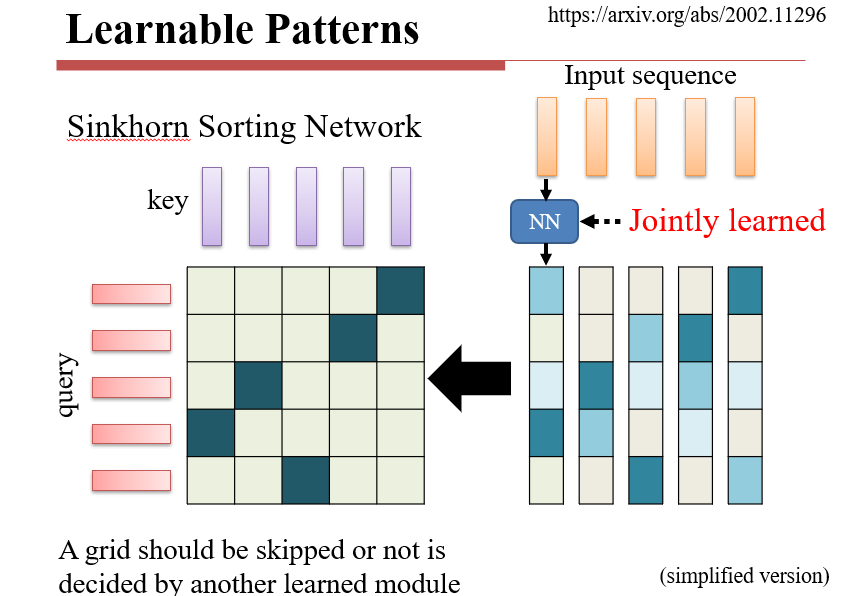
8.2.1.3 Learnable:
如:Sinkhorn
- 按照query,把key按照相关性排序,排序的结果就是自注意力的结果
- 需要学习一个排序函数,函数是一个神经网络
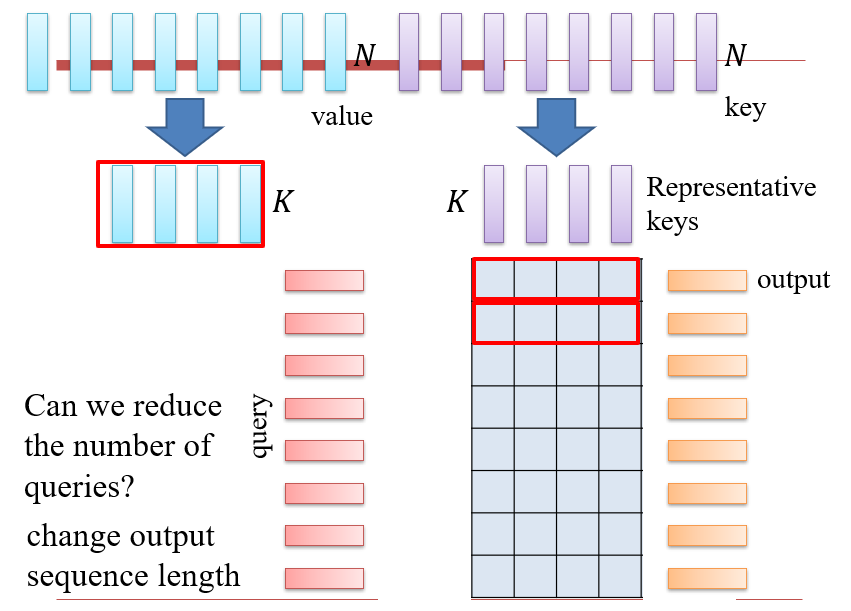
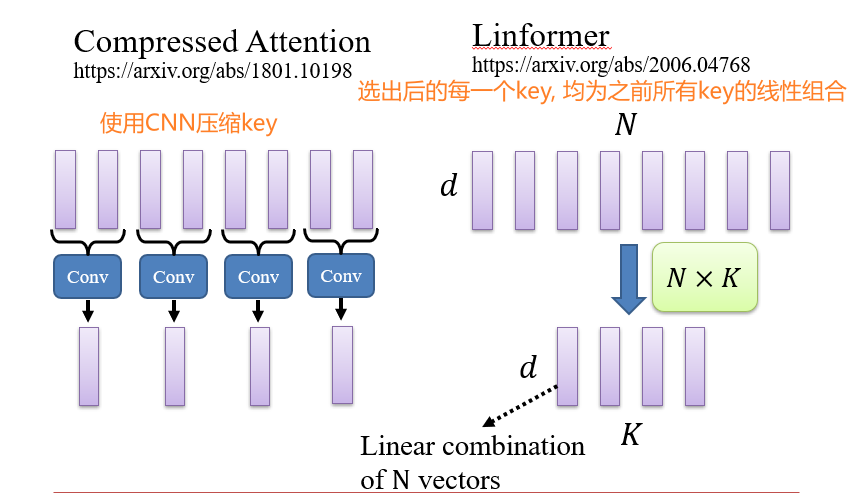
8.2.1.4 Representative key
如:Linformer
- 注意力矩阵是一个低秩的矩阵,有很多冗余信息
- query只和有代表性的key进行注意力计算
8.2.2 Attention Approximation
注意力的计算方法:本质上是矩阵乘法,而矩阵乘法满足结合律,可以先计算V×KT
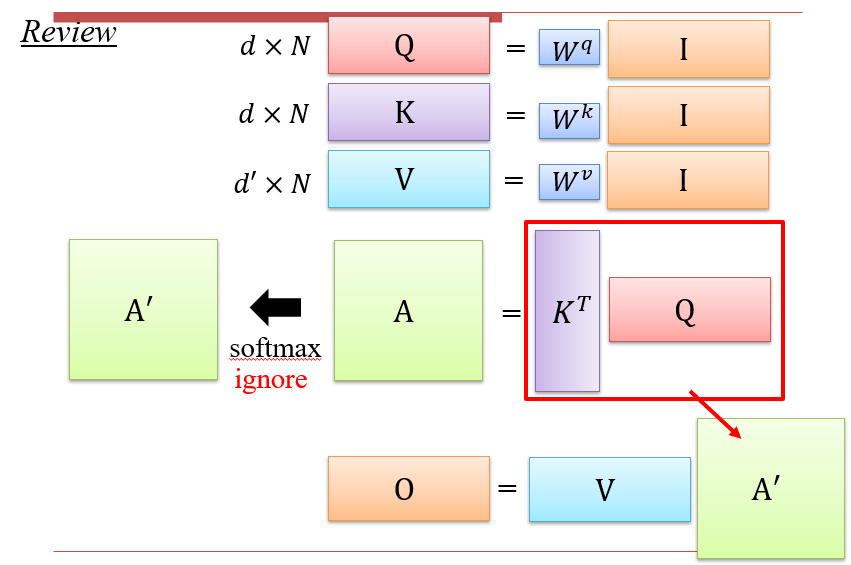
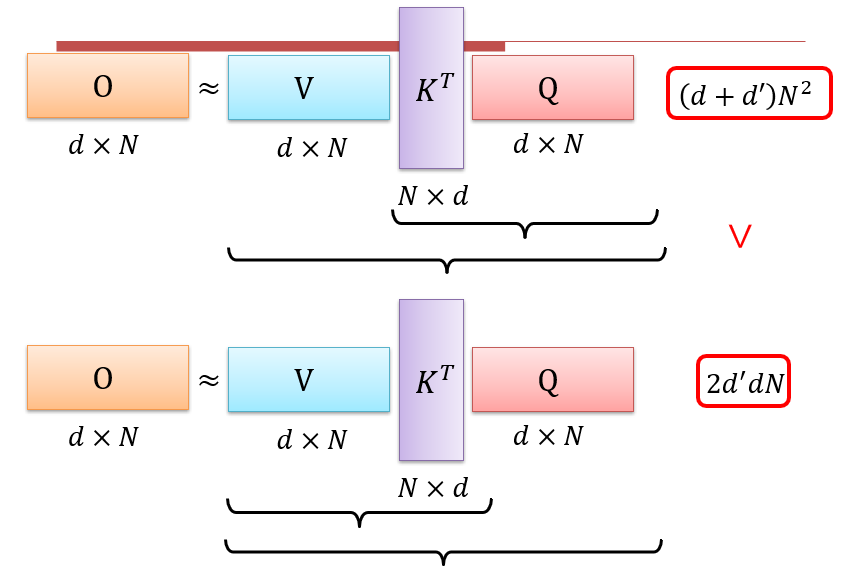
但是由于中间有一步softmax,实际上是不能直接这样计算的
- 需要找到一个函数Φ,使得Φ(K×Q)=Φ(K)×Φ(Q):等变函数
- 用神经网络拟合这个函数

Low-rank Approximation
- 选出代表性的K和Q,计算注意力,用计算出的结果重建剩下的KQ计算结果
- 如已知Q1 * K5,Q4 * K1,Q1 * K1,可以重建出Q4 * K5

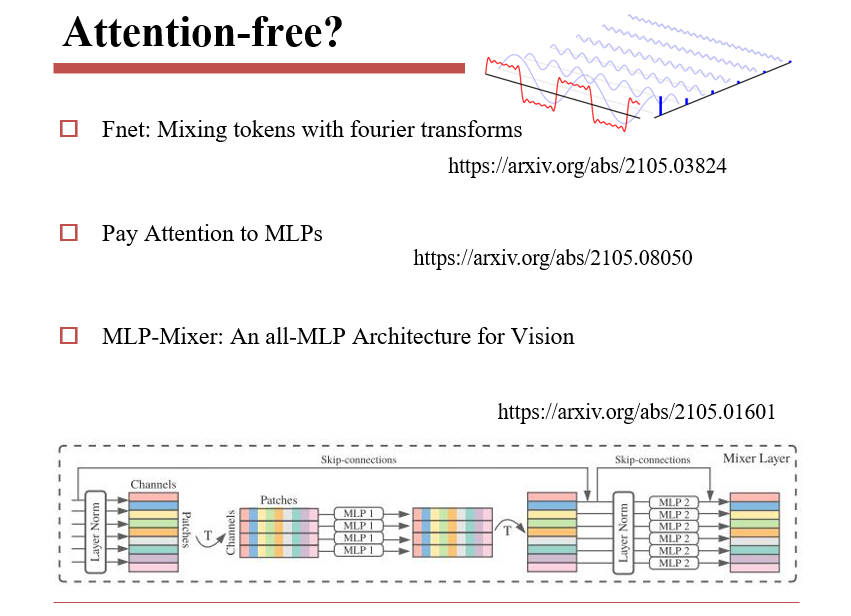
8.2.3 Attention free
8.2.3.1 Synthesizer
将attention score作为待学习的参数,固定下来,而不是每次重新计算
8.2.3.2 其他Attention-free方法
8.3 如何评估文档模型
- Perplexity:
- 计算模型生成整个句子的概率
- 加log之后,可以变为生成整个句子每个单词的期望,由于概率均为负数,需要加一个负号
- 缺点:如果预测错高频词,则惩罚很大,从而会忽略掉低频词的贡献
- sentence scrambling
- 将整个文档打乱,让模型对句子进行排序
- Final sentence prediction
- 给定一个故事,让模型预测故事的结尾
- Final word prediction
- 给定一个文章,让模型预测文章的主题
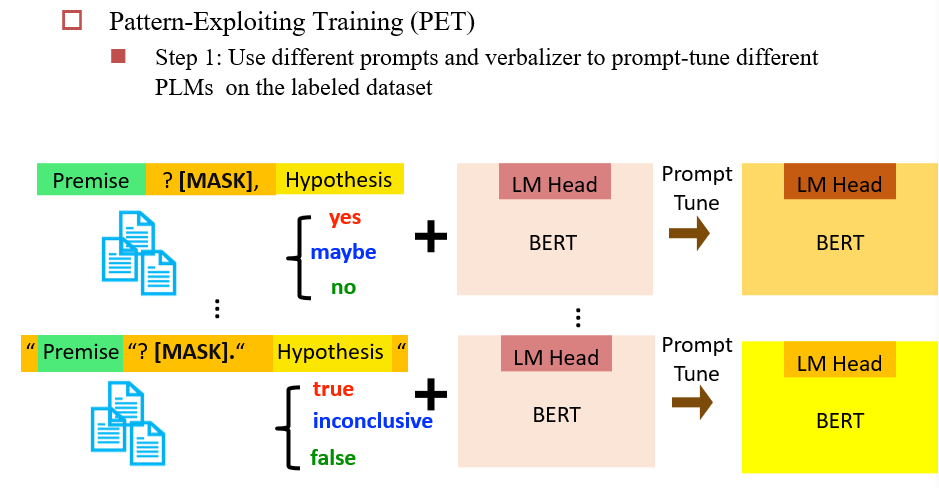
九、Prompting and Data-Efficient Fine-tuning for Pretrained LMs
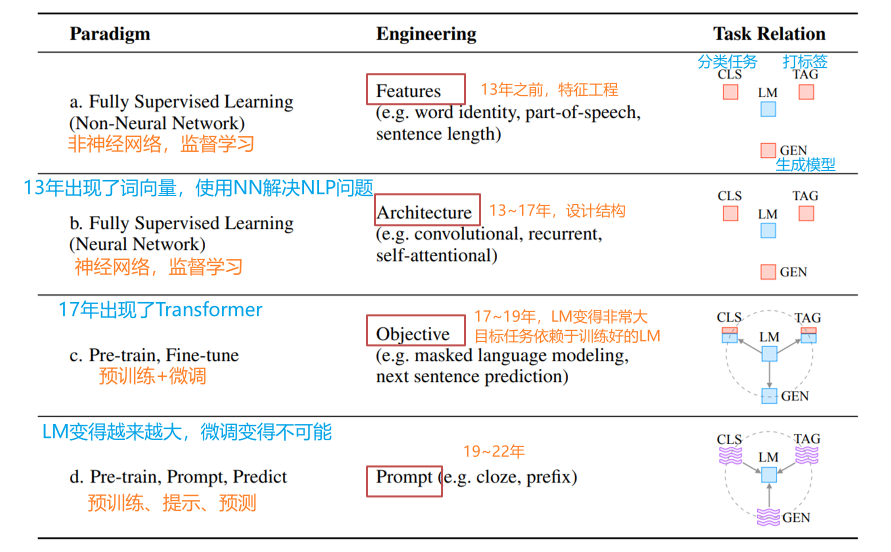
NLP技术发展的四个阶段
Prompt Engineering 特点:
- NLP任务完全依赖于预训练语言模型LM
- 不对LM进行调整,而是输入不同的提示Prompt,让它执行不同的任务
- 需要设计比较好的Prompt
Prompt Engineering 的过程:
- 设计prompt template
- 选择语言模型
- 将输出映射到想要的结果中
- 多Prompt映射
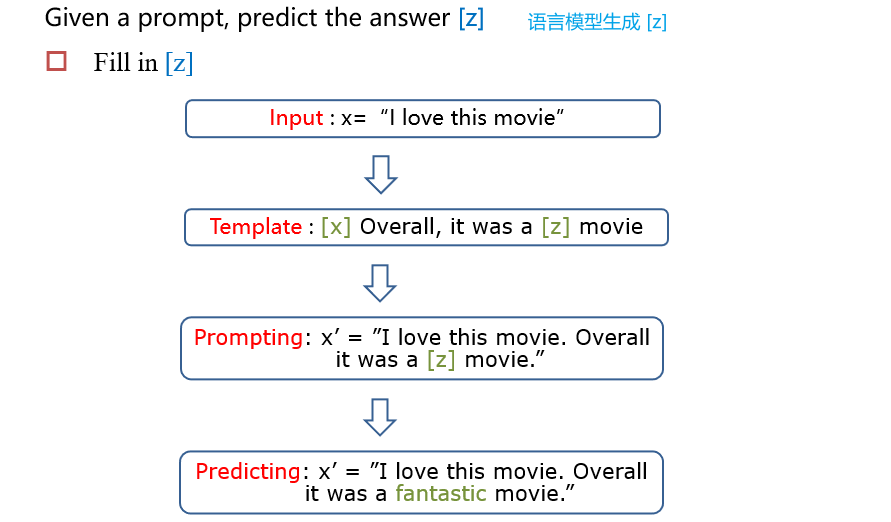
示例:情感分类

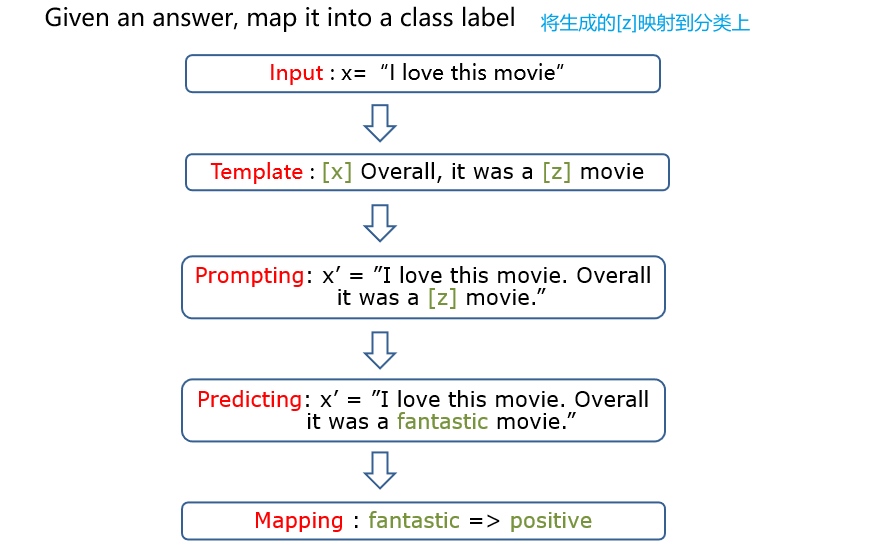
9.1 选择预训练模型
9.1.1 预训练模型的类型
- 生成式模型:GPT
- 遮罩式模型:BERT,RoBERTa
- Prefix模型:UniLM,UniLM2
- Encoder-Decoder:T5,MASS,BART
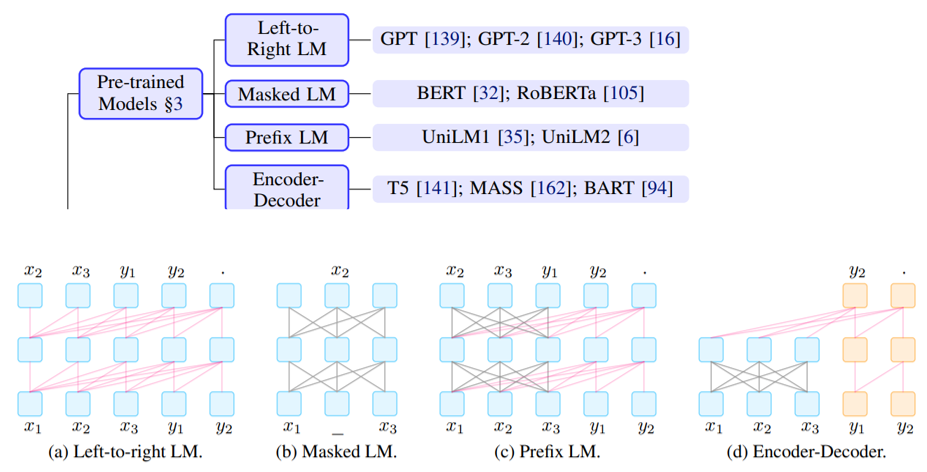
9.1.2 根据目标任务选择语言模型
- 遮罩式模型:目标输出非常简单,通常只有一个token
- Prefix LM / Encoder-Decoder:基于生成的信息抽取和问答

9.1.3 设计合适的prompt template
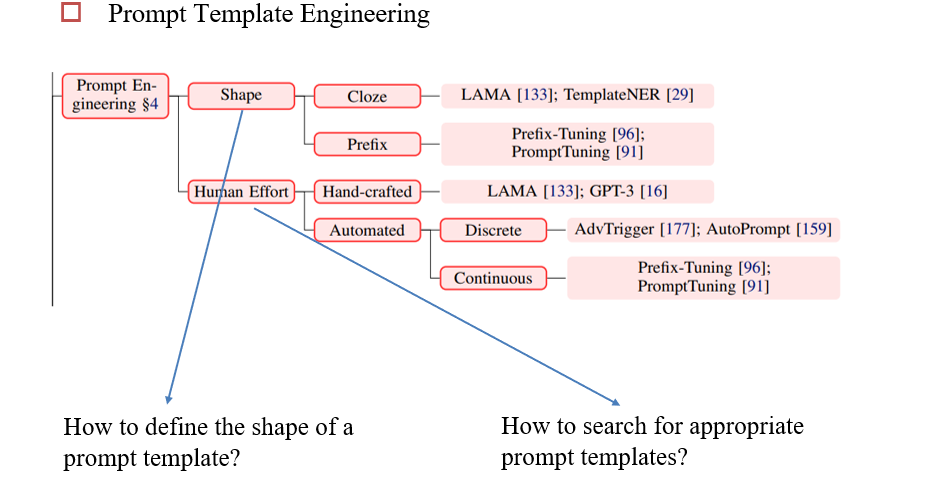
根据提示的形式分类:
Cloze提示:在文本中间挖空

Prefix提示:提示是答案的前缀

根据设计者:
Hand-Crafted:人工设计
Automated Search:自动设计
在离散空间内搜索:词空间
Prompt Mining:启发式方法生成prompt
- Middle-word
Prompts:已知两个词之间有关系,用这两个词对所有输入做过滤,他们之间出现的所有句子,可能会表示这两个词之间的联系,如[姚明]
出生在[上海] - Dependency-based Prompts:在语法树上找这两个词之间的关系
- Middle-word
Prompts:已知两个词之间有关系,用这两个词对所有输入做过滤,他们之间出现的所有句子,可能会表示这两个词之间的联系,如[姚明]
Prompt Paraphrasing
Gradient-based Search:基于梯度的搜索。给定输入x和预期输出y,随机填进prompt,如果没有得到y,则将梯度回传,根据梯度修改prompt
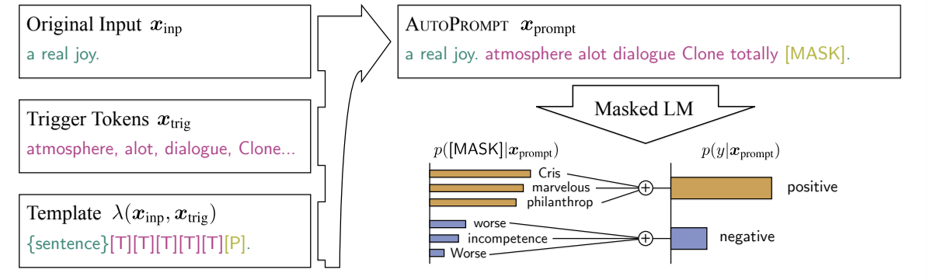
在连续空间内搜索:向量空间
9.1.4 将LM的输出映射到目标任务的输出上
人工设计:
- Unconstrained Space:不对词典进行约束
- Constrained Space:只保留某些词对答案有贡献
自动搜索:(离散空间)

9.1.5 多提示学习
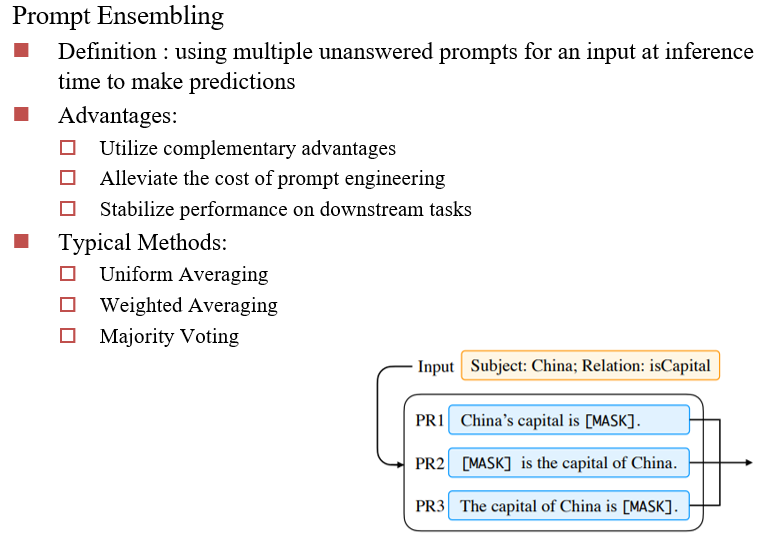
Prompt Ensembling:设计多个类似的提示,将结果集成起来
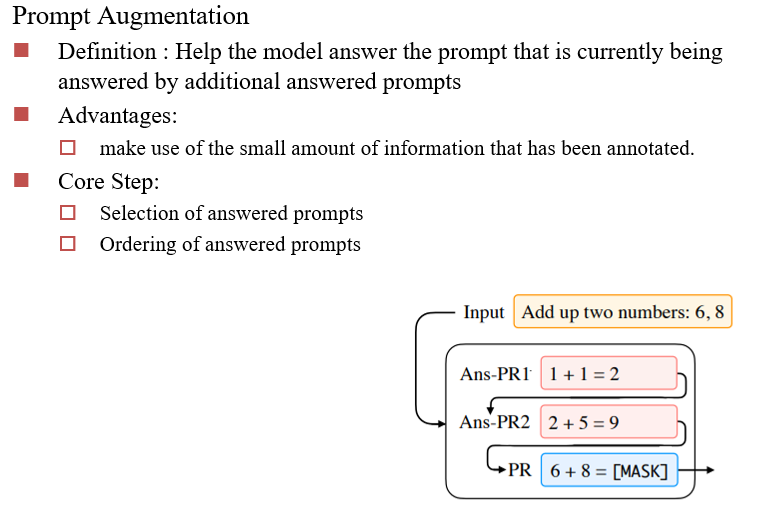
Prompt Augmentation:提示增强,先给几个成功的例子,然后再提问
- 核心步骤:成功例子的选择、顺序
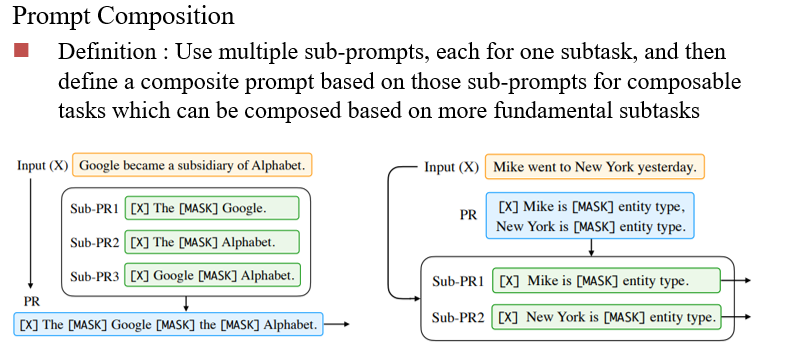
Prompt Composition:将多个问题组合起来一起问
Prompt Decomposition:问题过于复杂时,将问题分解为多个子问题

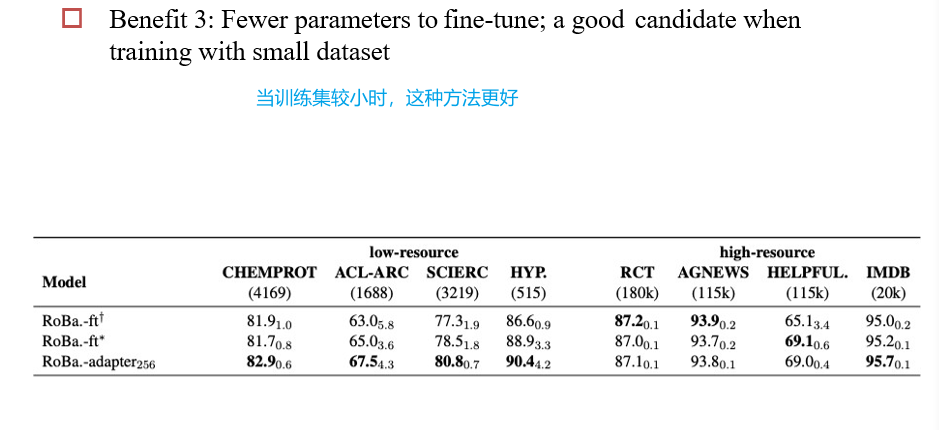
9.2 Data-Efficient Fine-tuning
Fine-tuning的过程:对每一层的参数进行修改
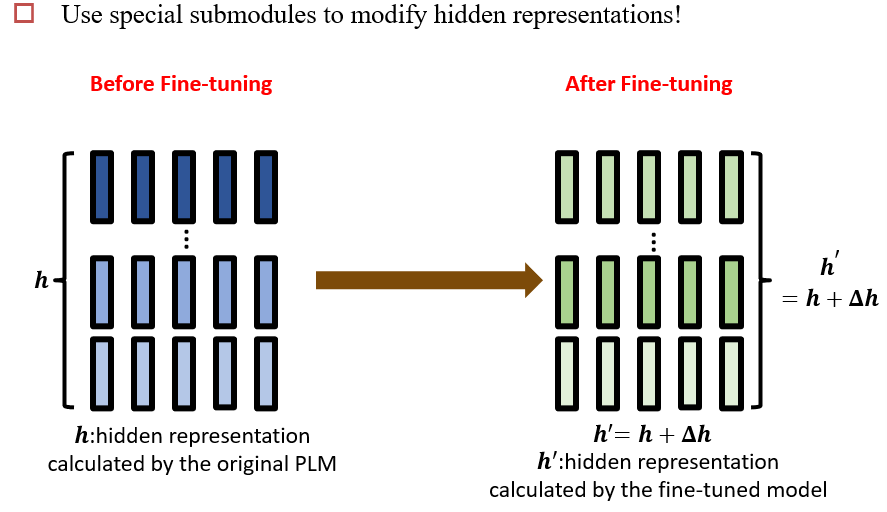
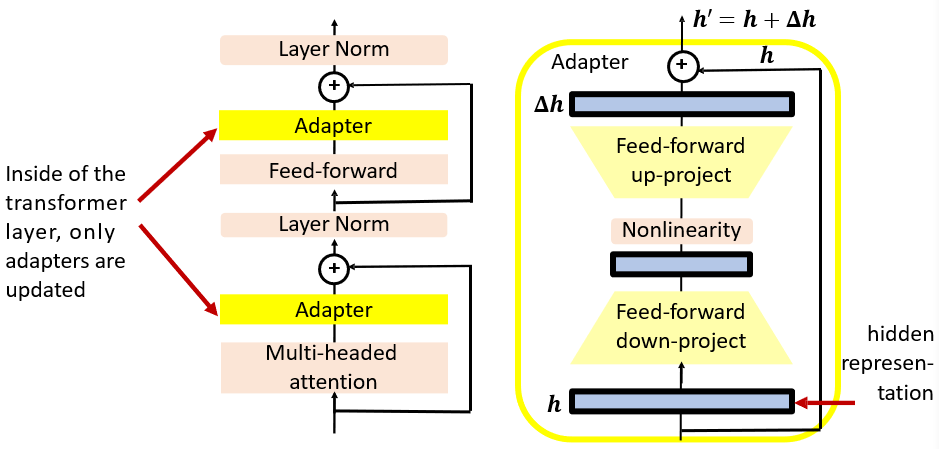
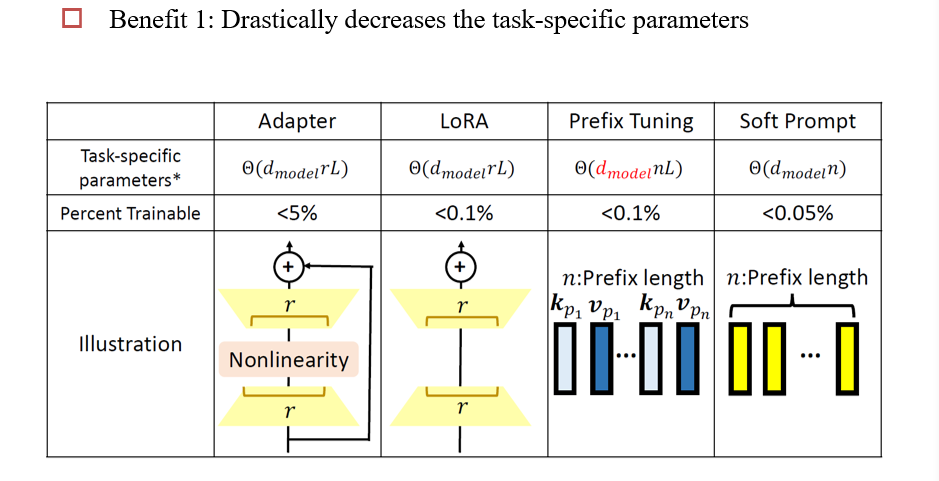
9.2.1 Adapter
在模型中添加进一个Adapter层,微调时只改Adapter
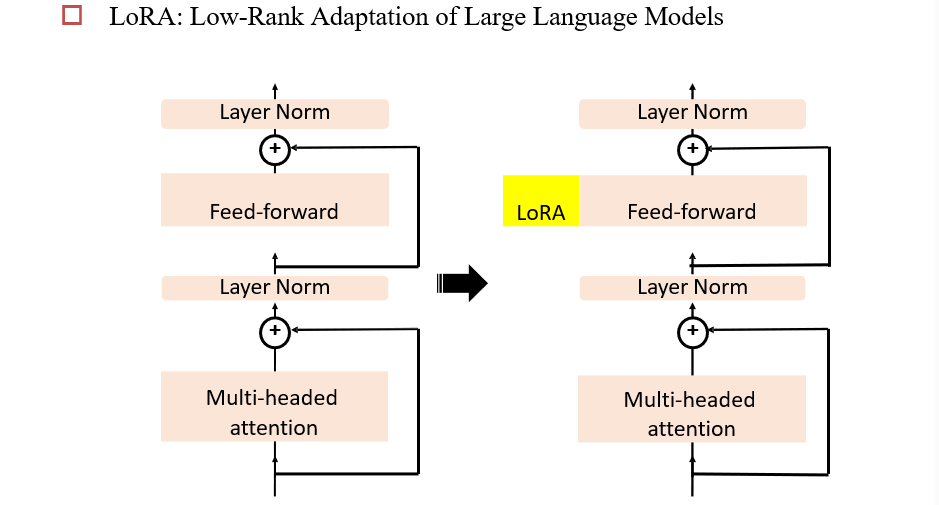
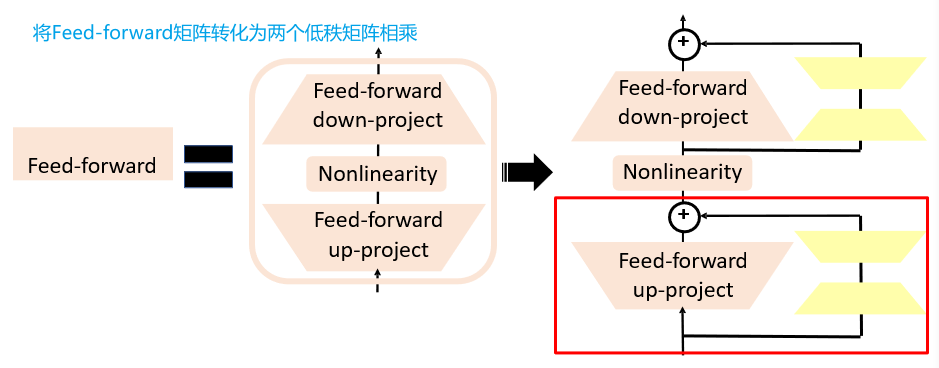
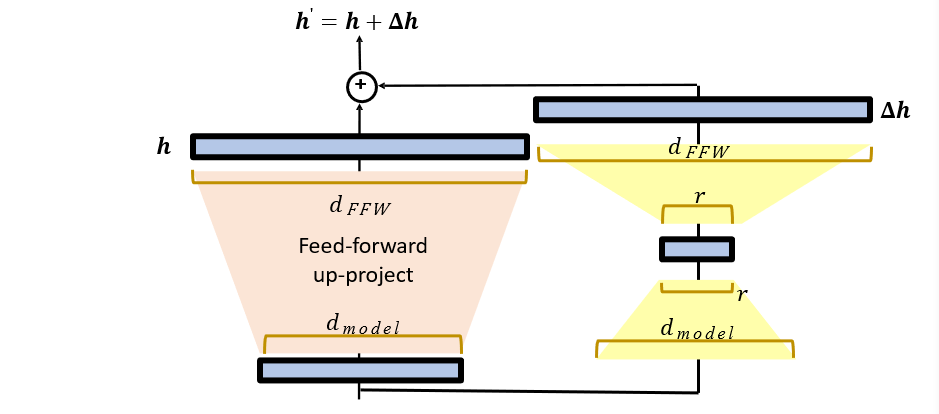
9.2.2 LoRA
在旁路中添加一个残差部分
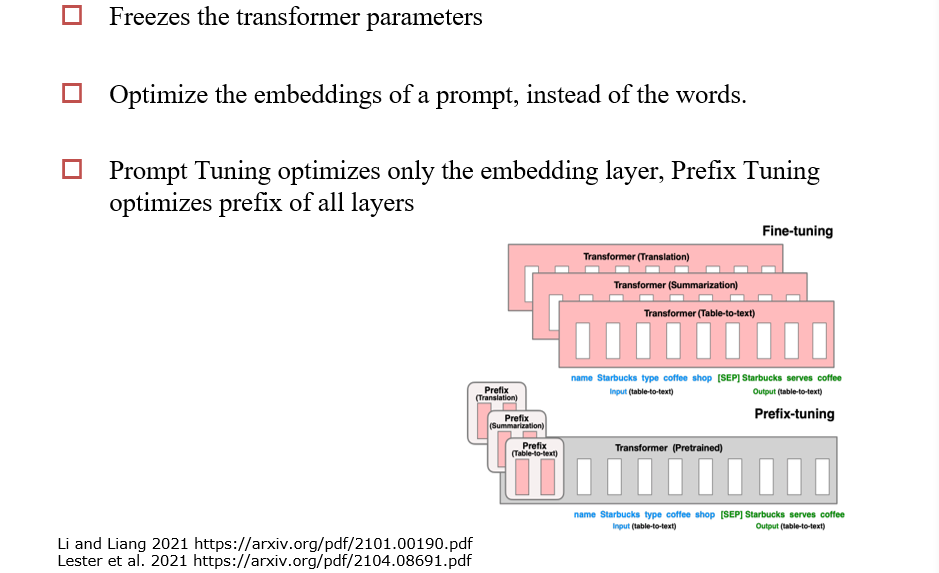
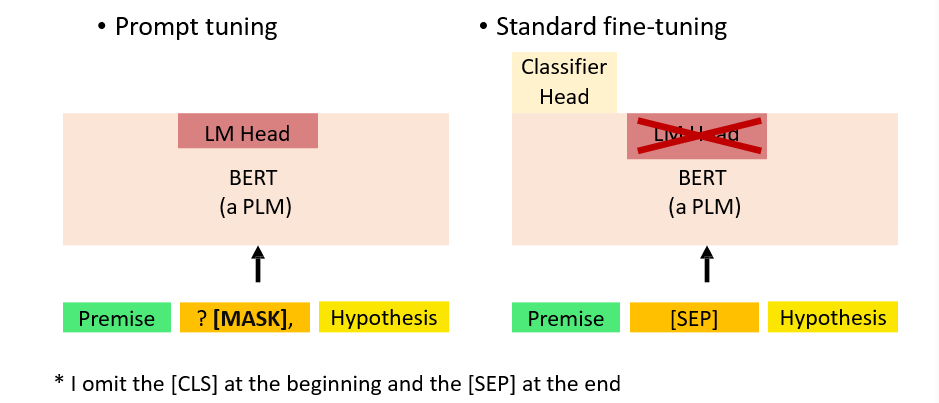
9.2.3 Prefix/Prompt Tuning
Prompt Tuning:只修改输入的提示
Prefix Tuning:相当于模型的每一层都有一个提示需要被调
9.2.4 不同方法的比较
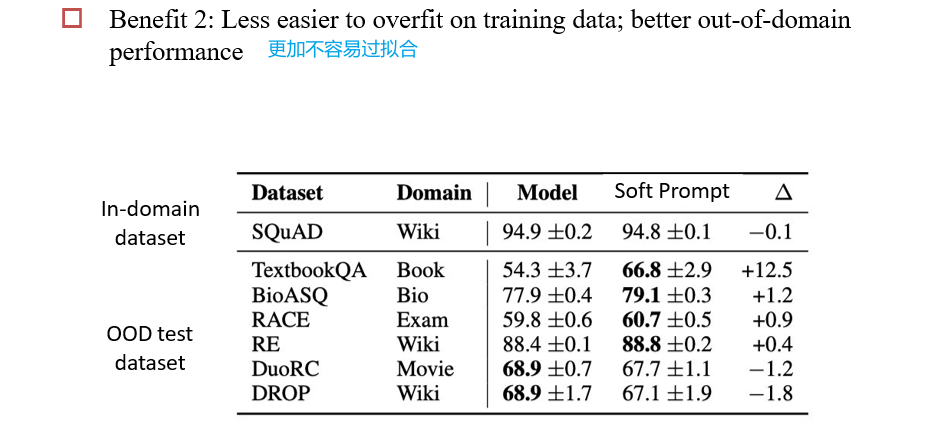
9.3 Early Exit
在每一层添加一个分类器,可以在中间就停止计算:在精度不变的情况下减小计算量
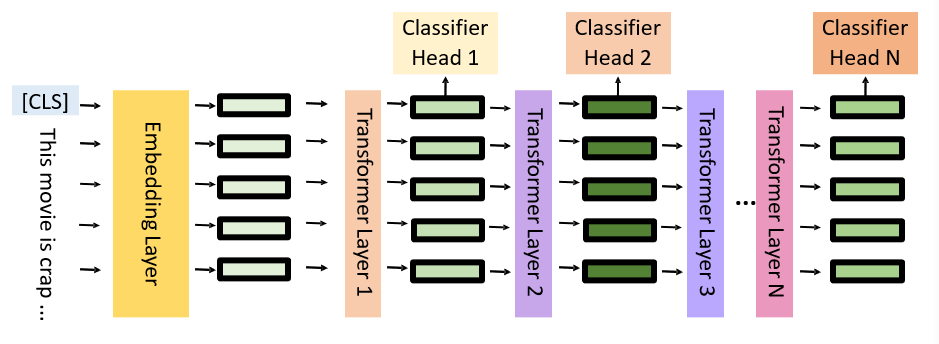
9.4 训练策略
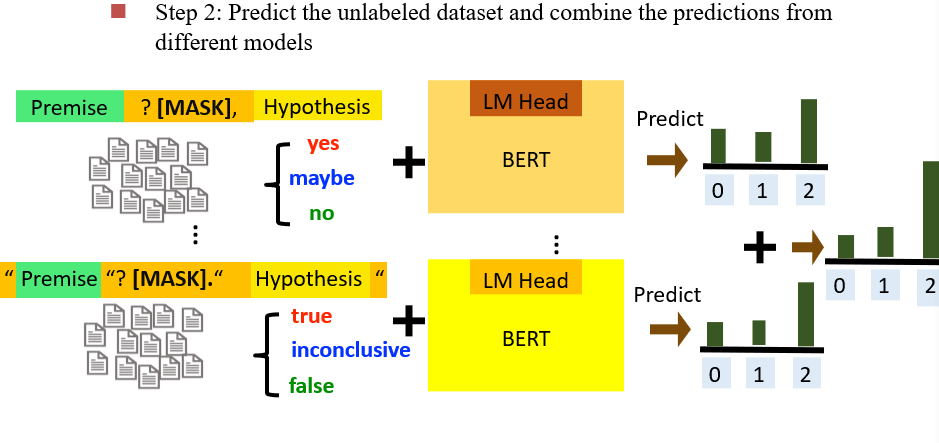
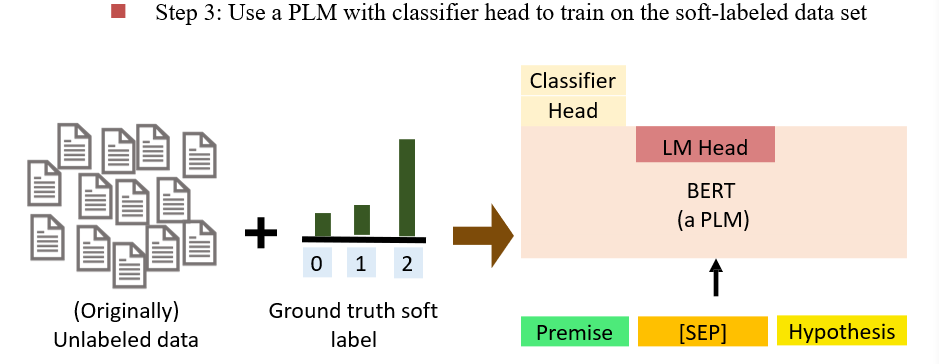
9.5 半监督学习
有大量的数据,但是只有一部分有标签,让语言模型对数据打上标签
9.6 如何选择策略

十、深度强化学习 Reinforcement Learning
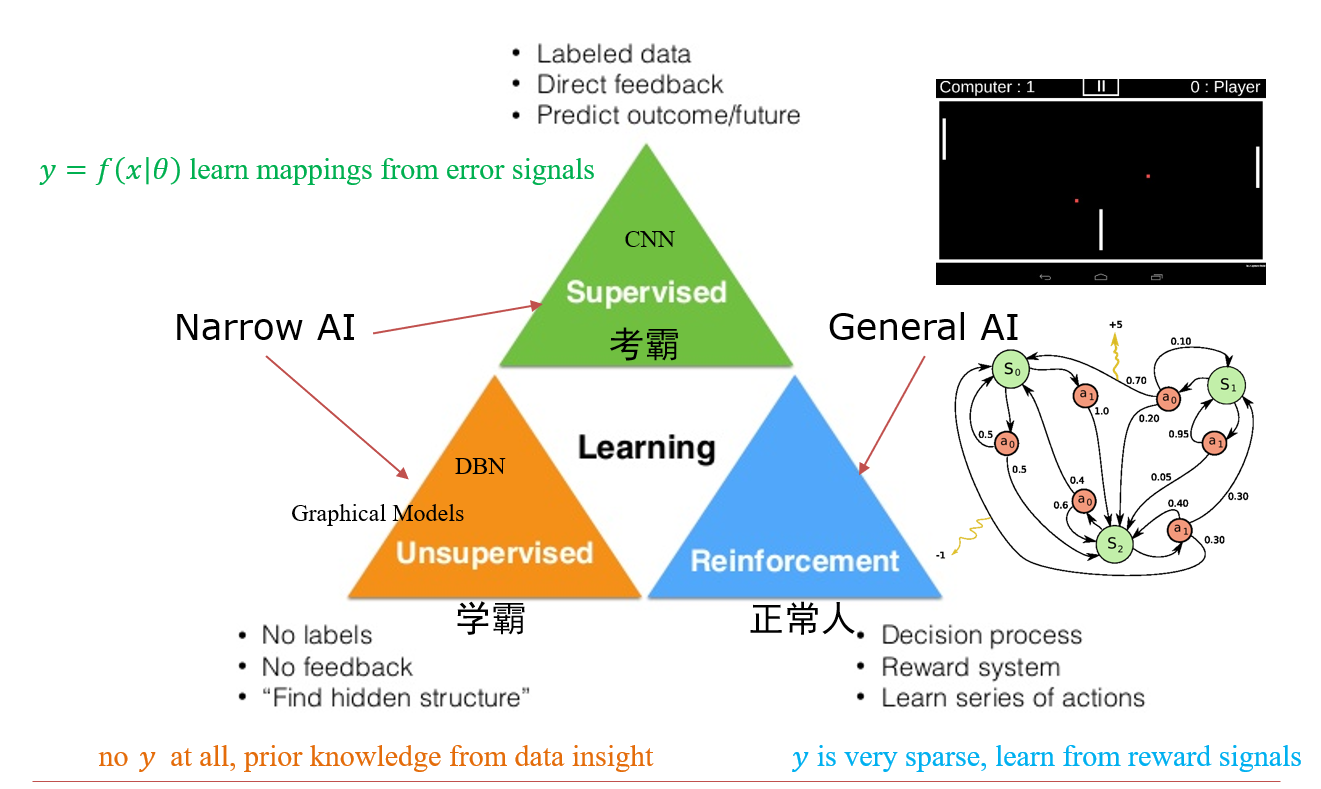
Reinforcement:
- 针对Decision Process
- 计算很长一段时间后,才能获得reward,根据reward反思decision process
10.1 强化学习简介
个体在环境基于的奖励或惩罚的刺激Reward下,逐步形成对刺激的预期,产生能获得最大利益的习惯性为Actions
- 经验Experience:一系列的observation、action、reward,\(o_1,r_1,a_1,...,a_{t-1},o_t,r_t\)
- 状态State:experience的总结,\(s_t=f(o_1,r_1,a_1,...,a_{t-1},o_t,r_t)\)
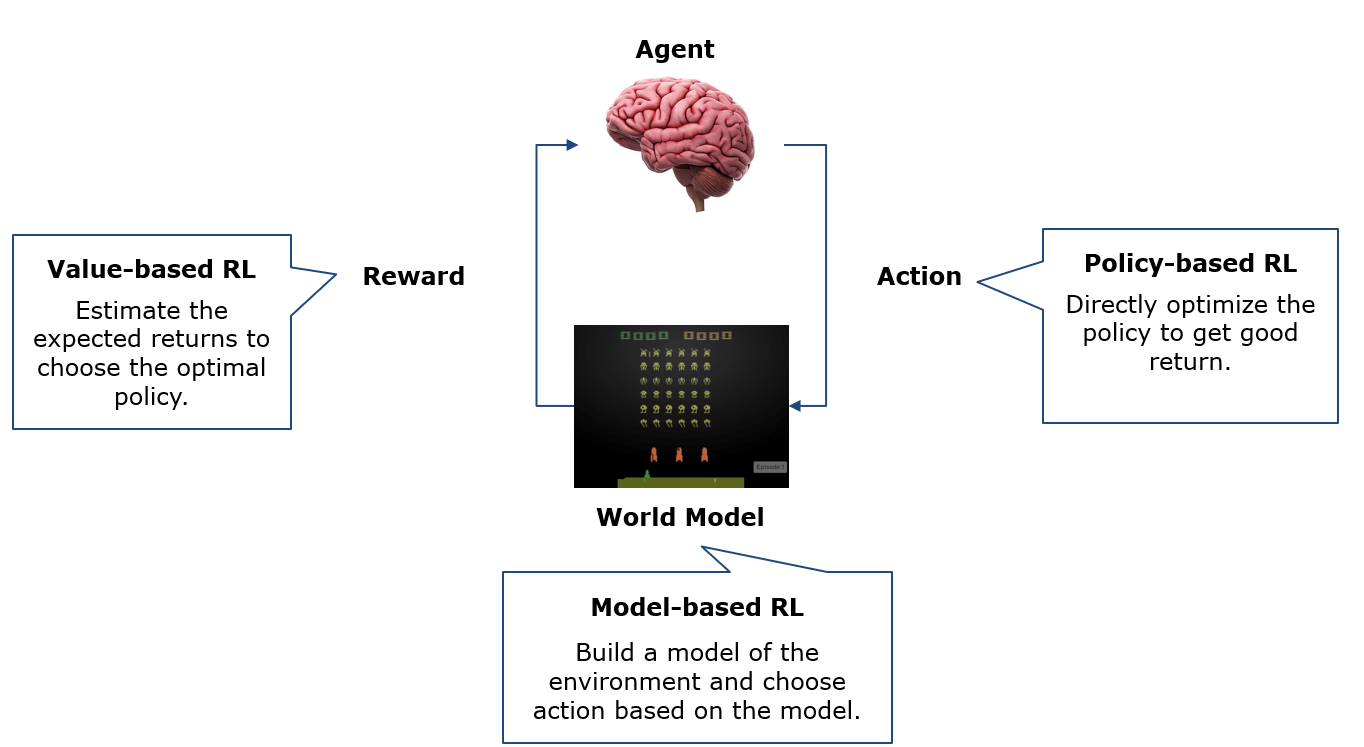
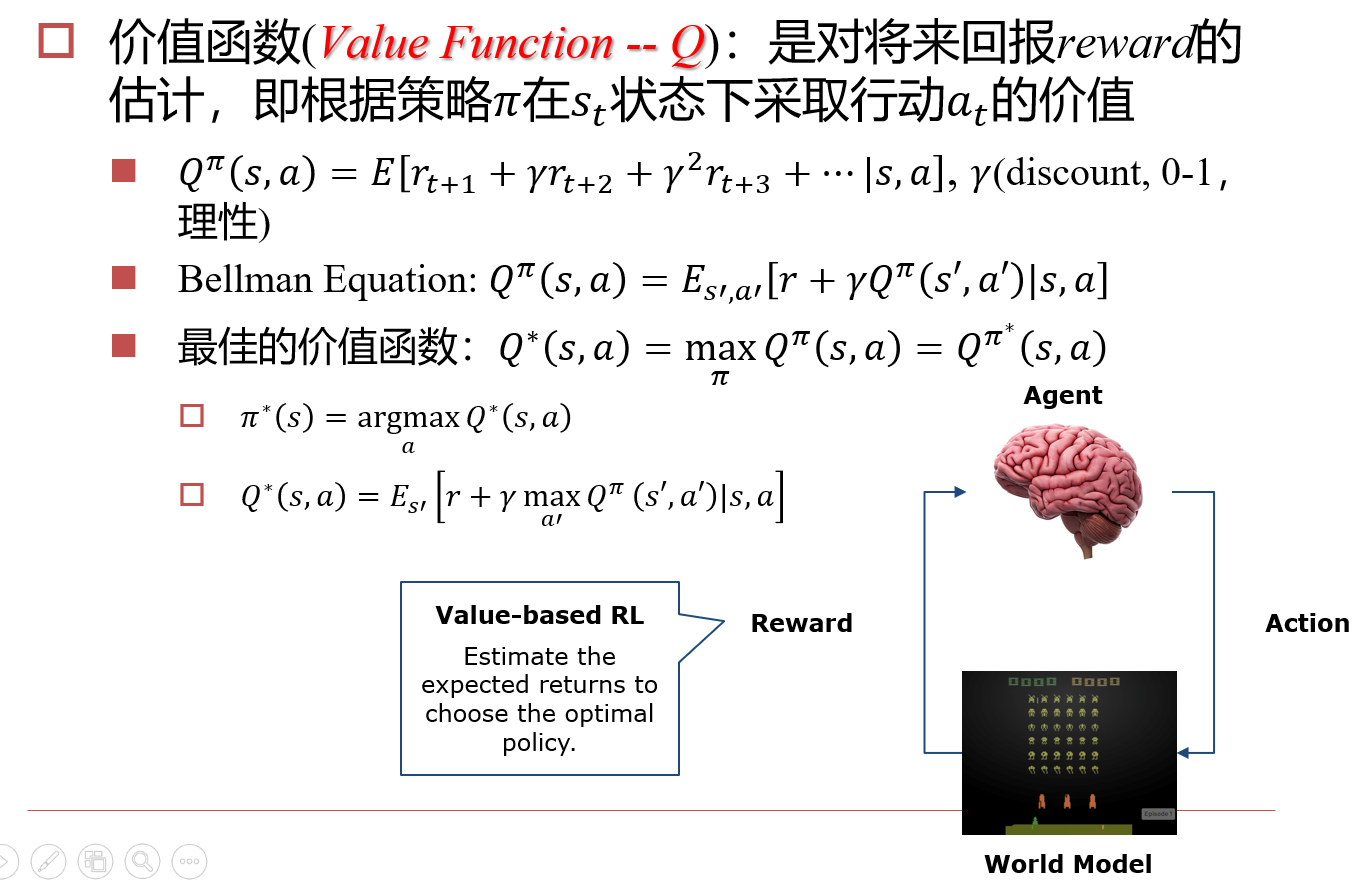
10.2 Value-based RL
10.2.1 Q-Learning
- 策略\(\pi\):即Agent
- \(r_{t+i}\):经过i个时间后,期望得到的回报
- \(\gamma\):理性,用于控制未来的期望回报对当前价值判断的影响,一般取值为\([0,1]\)
Value迭代:可以通过蒙特卡洛搜索的方式实现迭代
- 随机生成一个策略
- 然后根据策略模拟对局,根据实际得到的Reward更新策略

10.2.2 深度强化学习
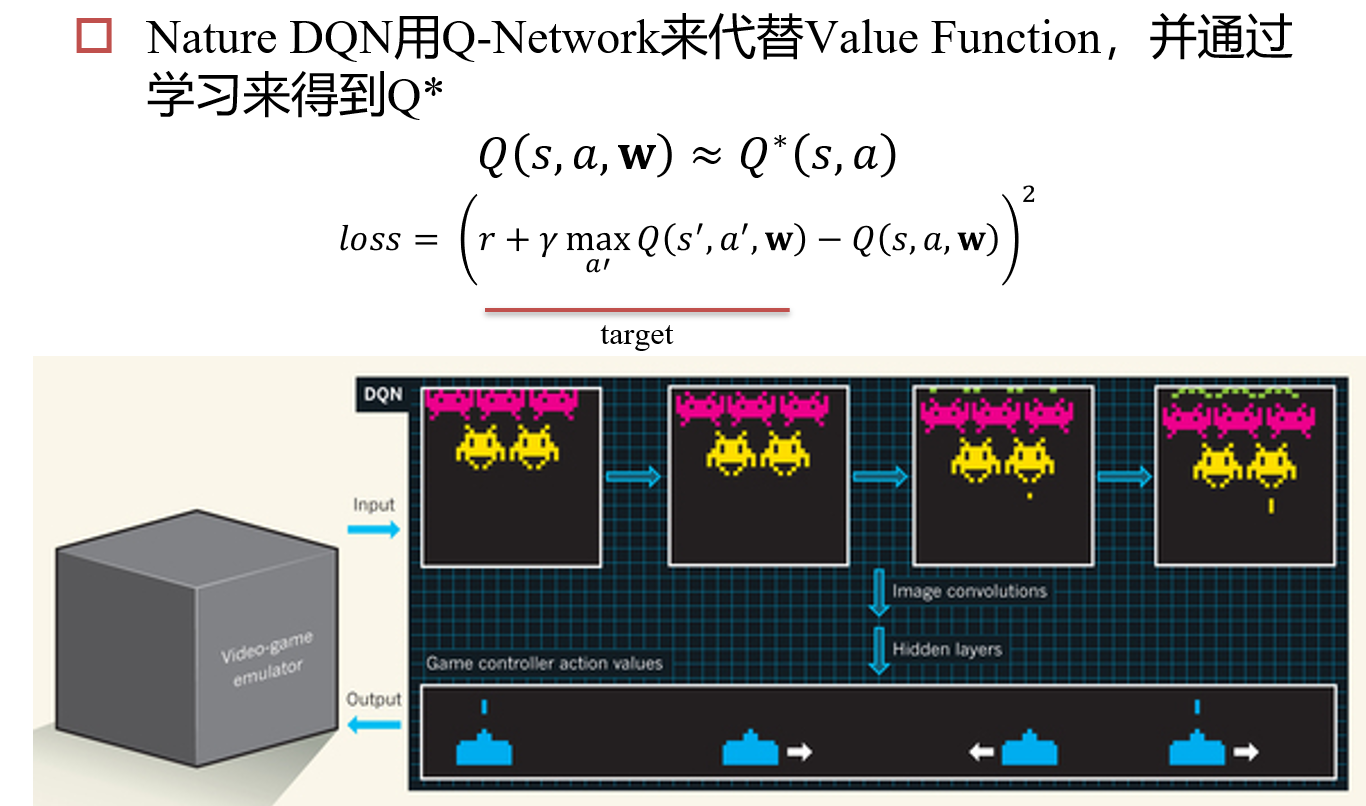

- 反向传播算法失败:借鉴RNN的思想,修改hidden
- 图像差异小:Experience Reply,每次随机传入几帧,而不是传入游戏的连续画面

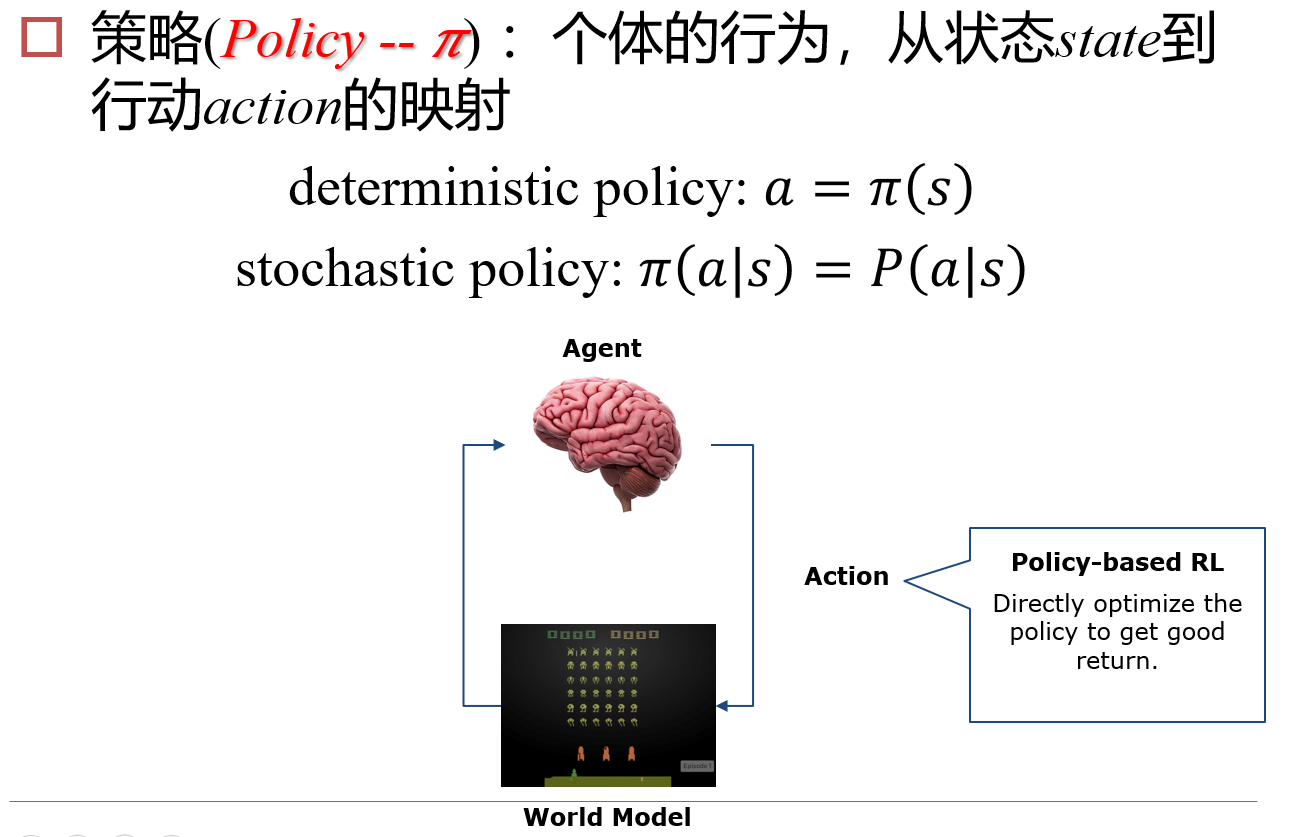
10.3 Policy-Based RL
10.3.1 机器人走迷宫带来的启发
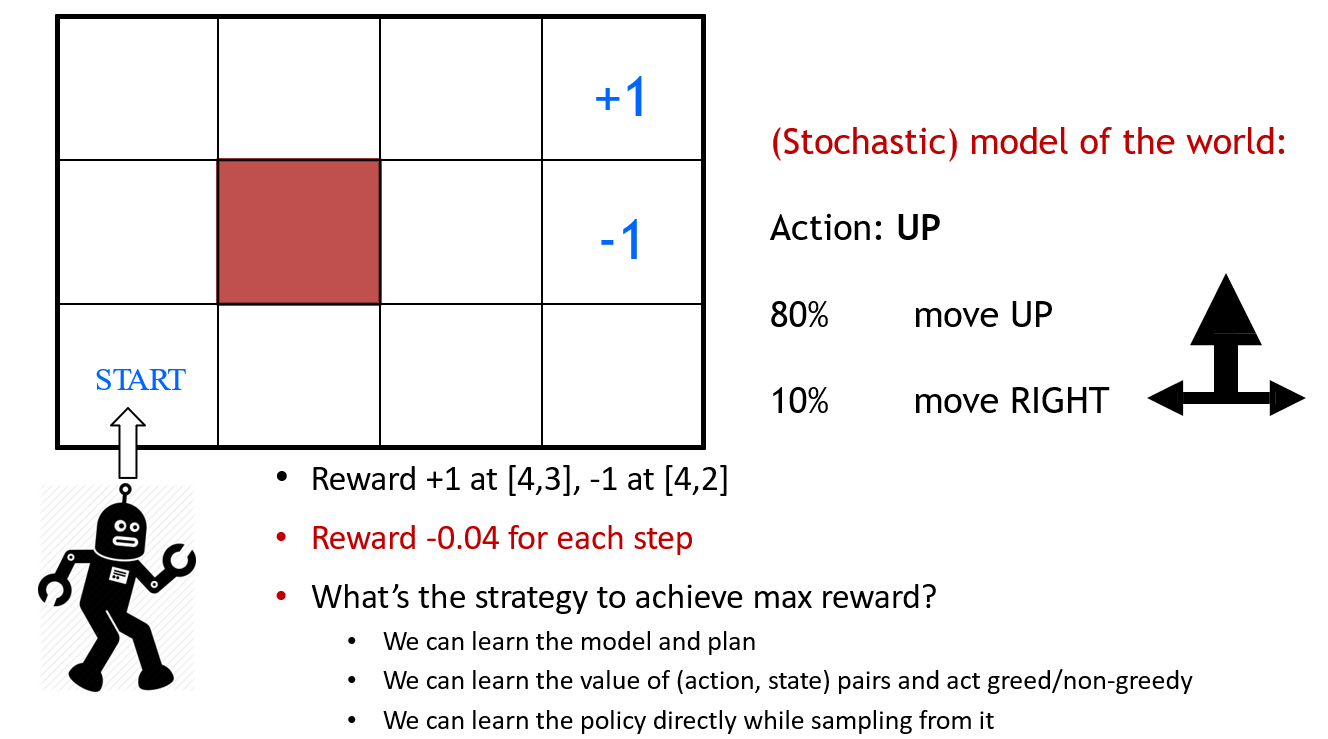
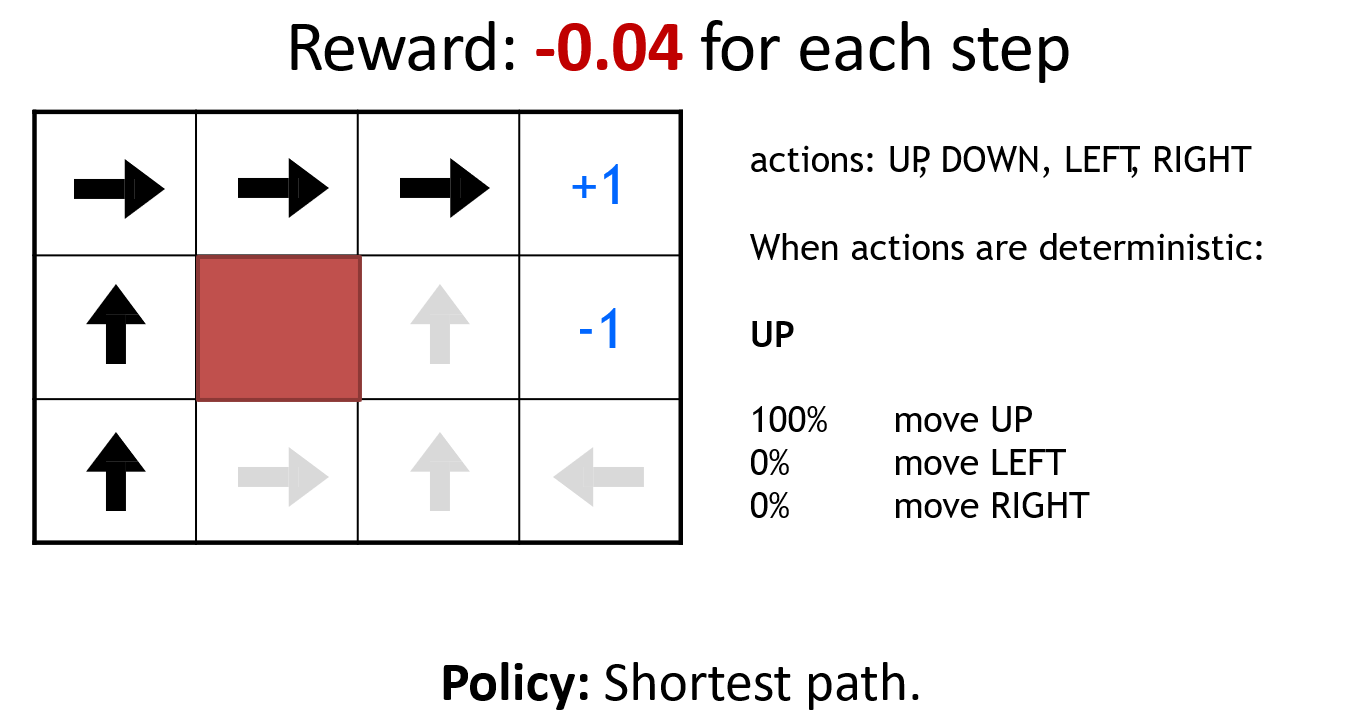
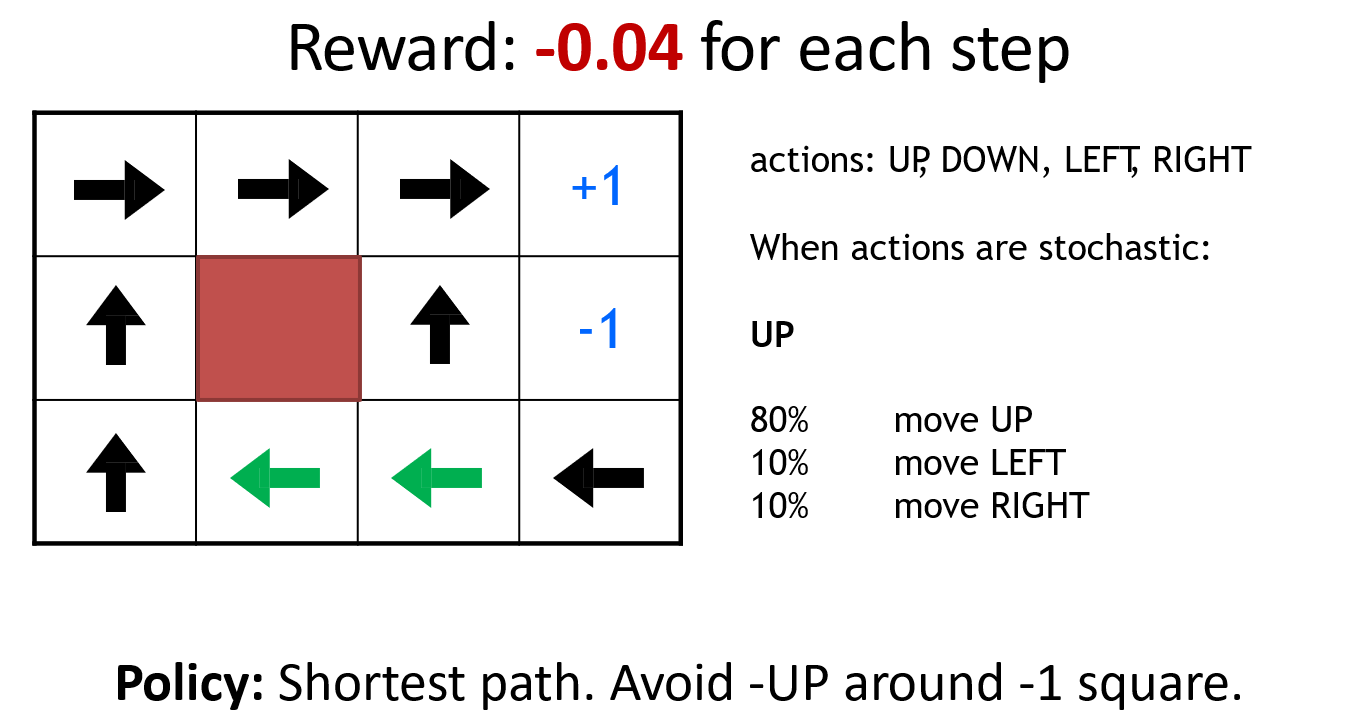
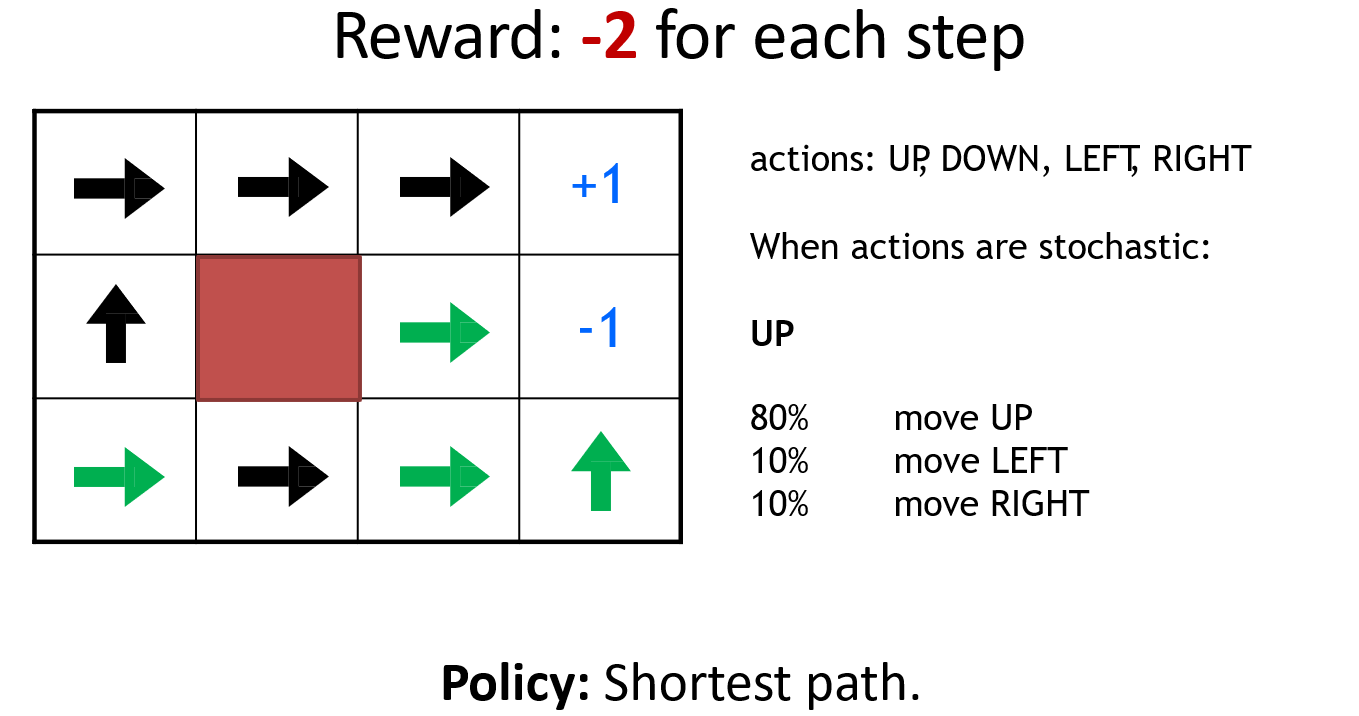
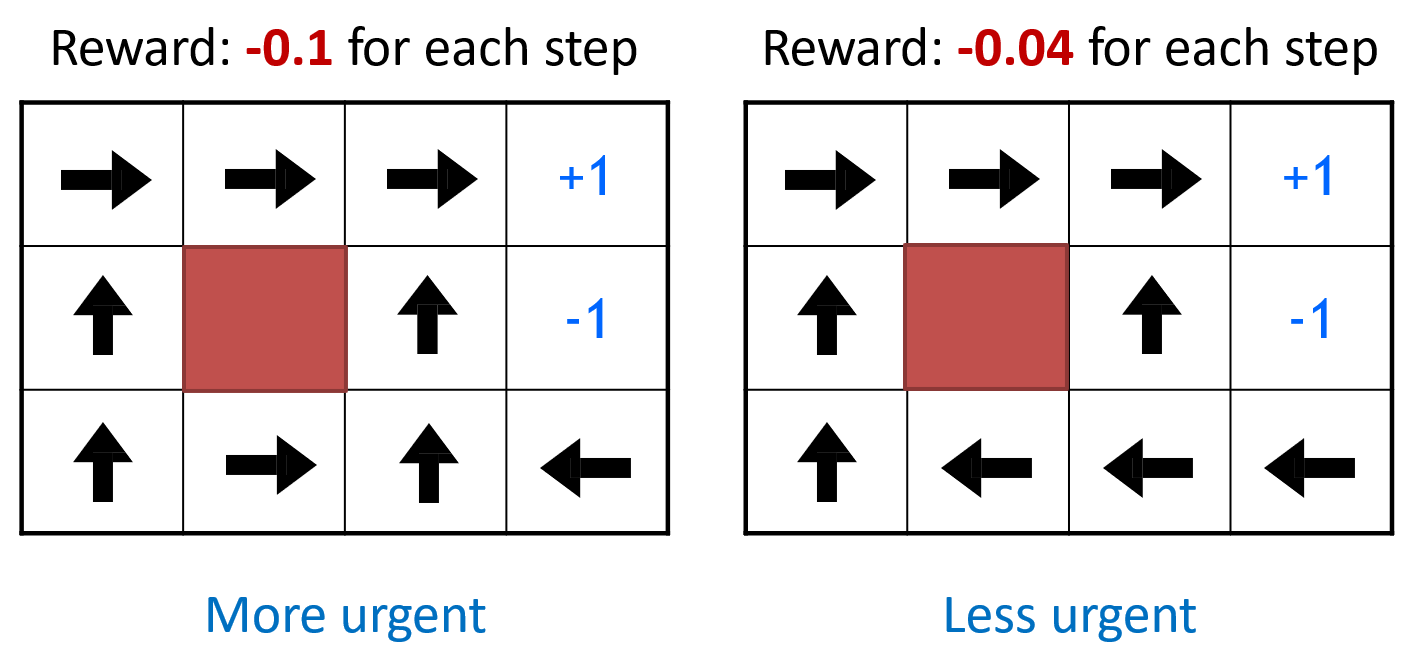
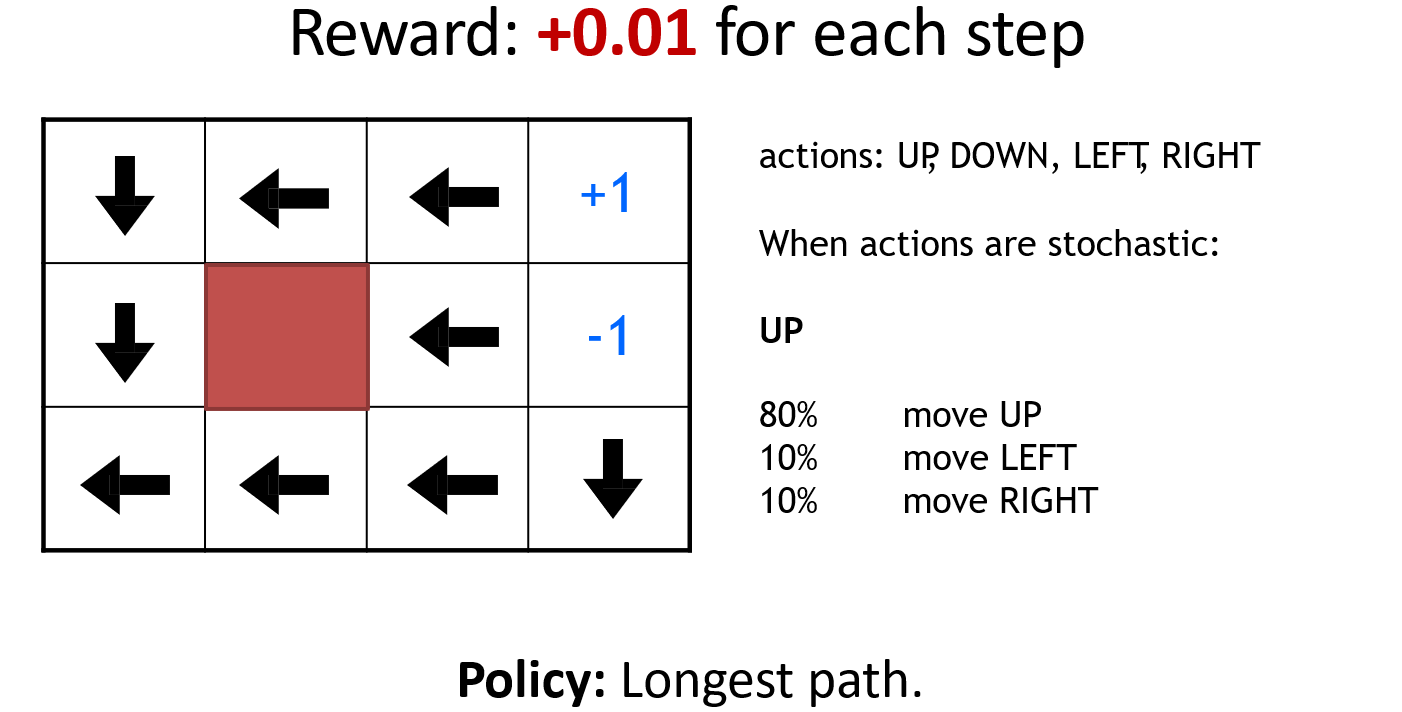
以机器人走迷宫为例,图示为模型训练结束后,在该点的策略,得到的启发如下
- Environment对最优策略有很大的影响
- Reward structure对最优策略有很大的影响
10.3.2 神经网络 => Actor
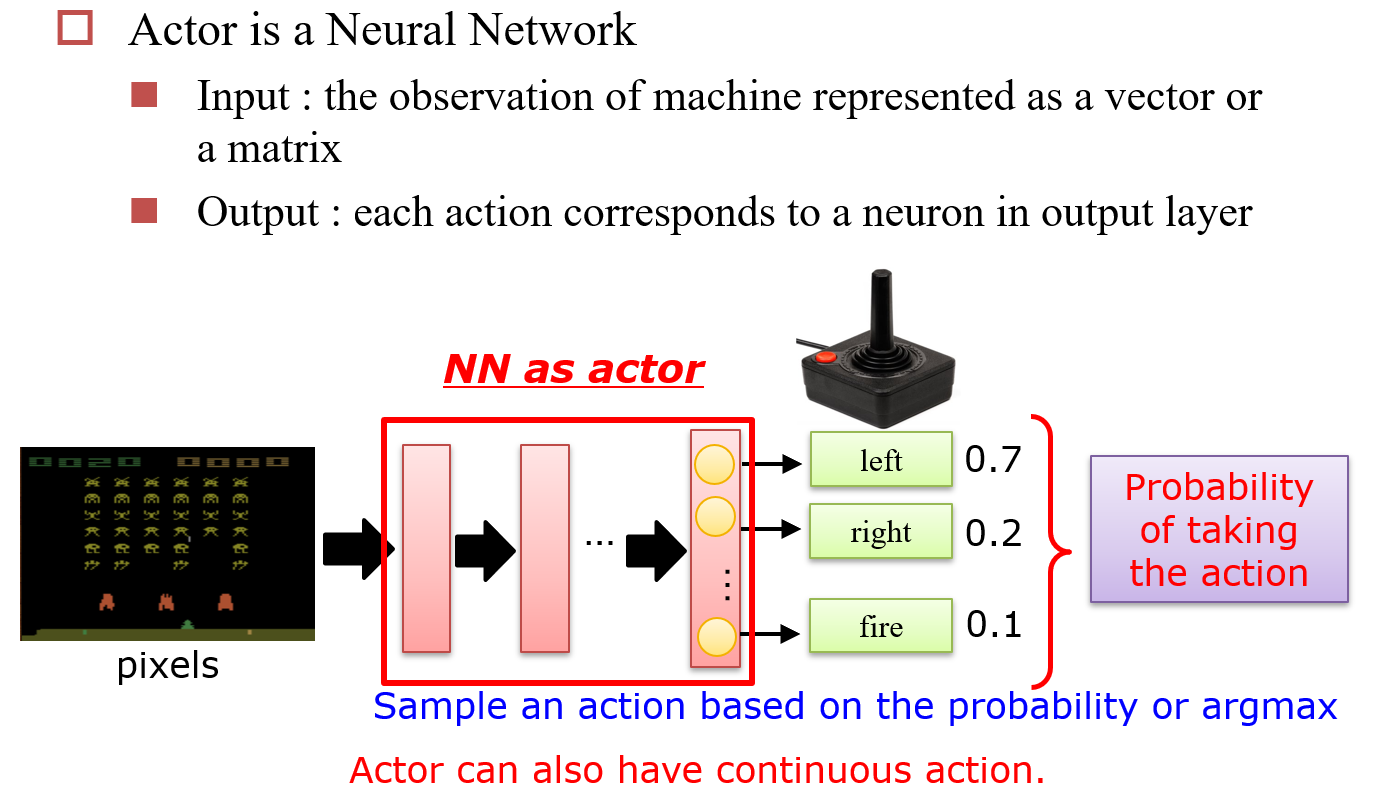
每次选择时,按照已知概率进行选择,如果得到了Reward,则提升该选择的概率


10.4 Value+Policy
Asynchronous Advantage Actor-Critic (A3C)
10.4.1 Critic
Critic也是一个神经网络,给定一个actor \(\pi\),它会评价这个actor的表现如何

10.4.2 如何计算\(V^\pi(s)\)
使用蒙特卡洛搜索算法:Monte-Carlo,MC
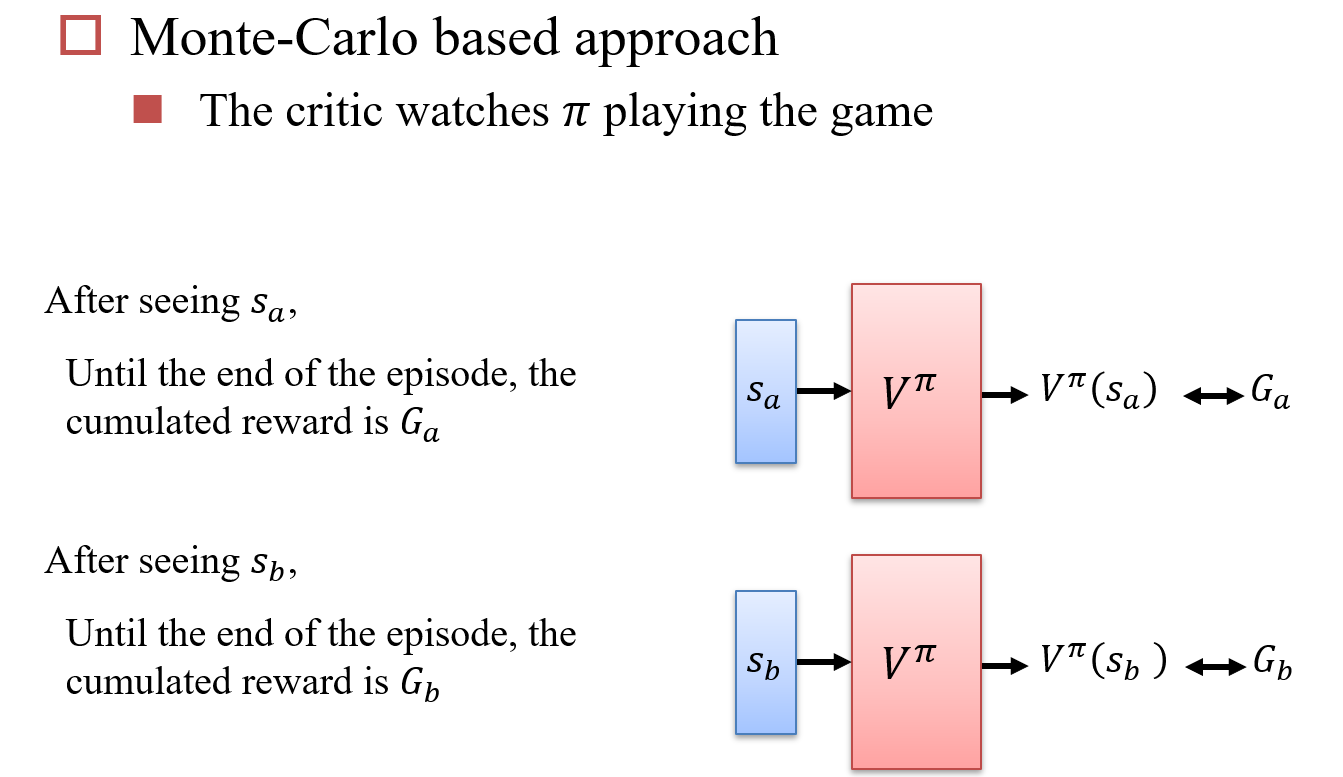
直接评估两个状态的差值:Temporal-Difference,TD
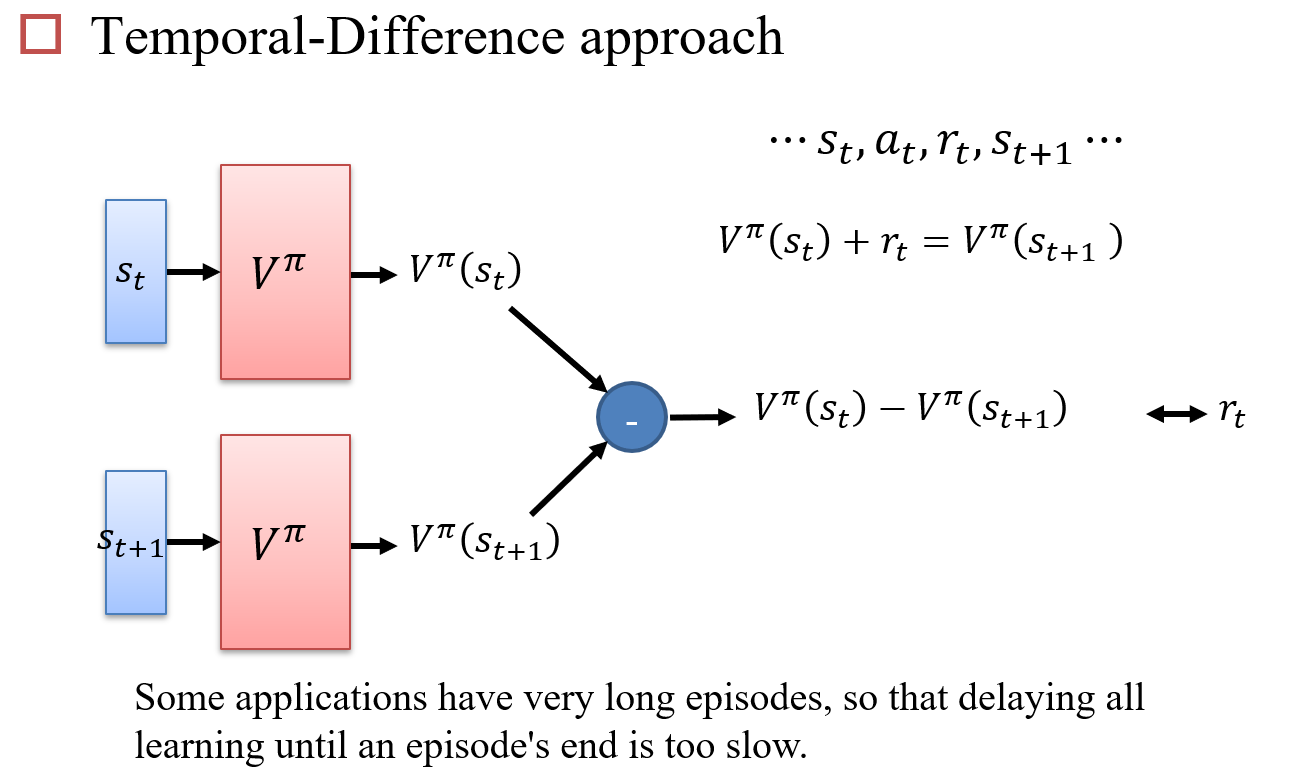
示例:MC vs TD

10.5 Model-based RL
输入:当前state
输出:预测下一时刻的state
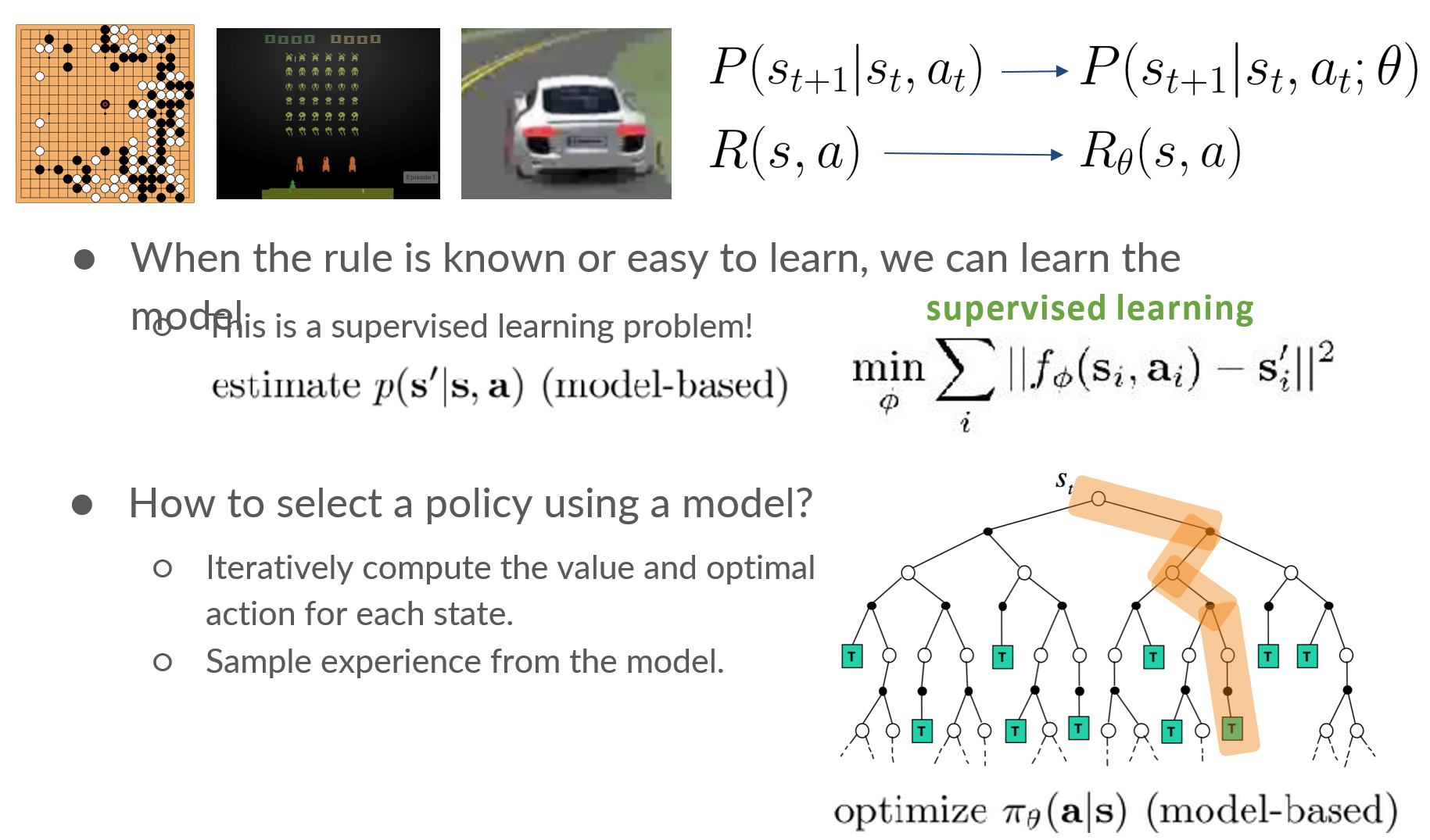
Model-Based的优点:
- 更容易收集reward
- 更容易迁移到其他任务
- 只需要很少的supervised data
Model-Based的缺点:
- 不能优化task的表示
- 有时比学习一个policy更难
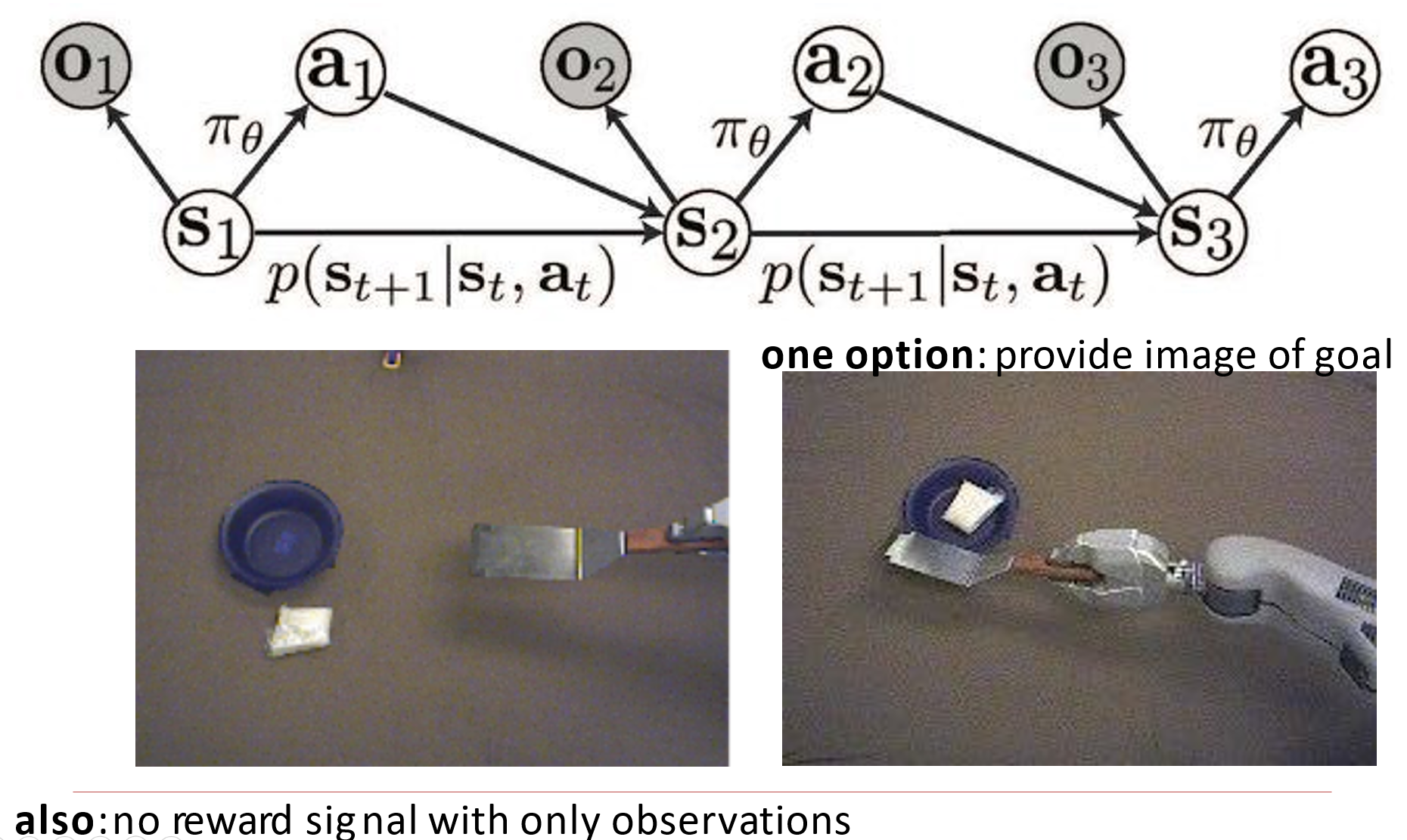
10.6 Imitation Learning
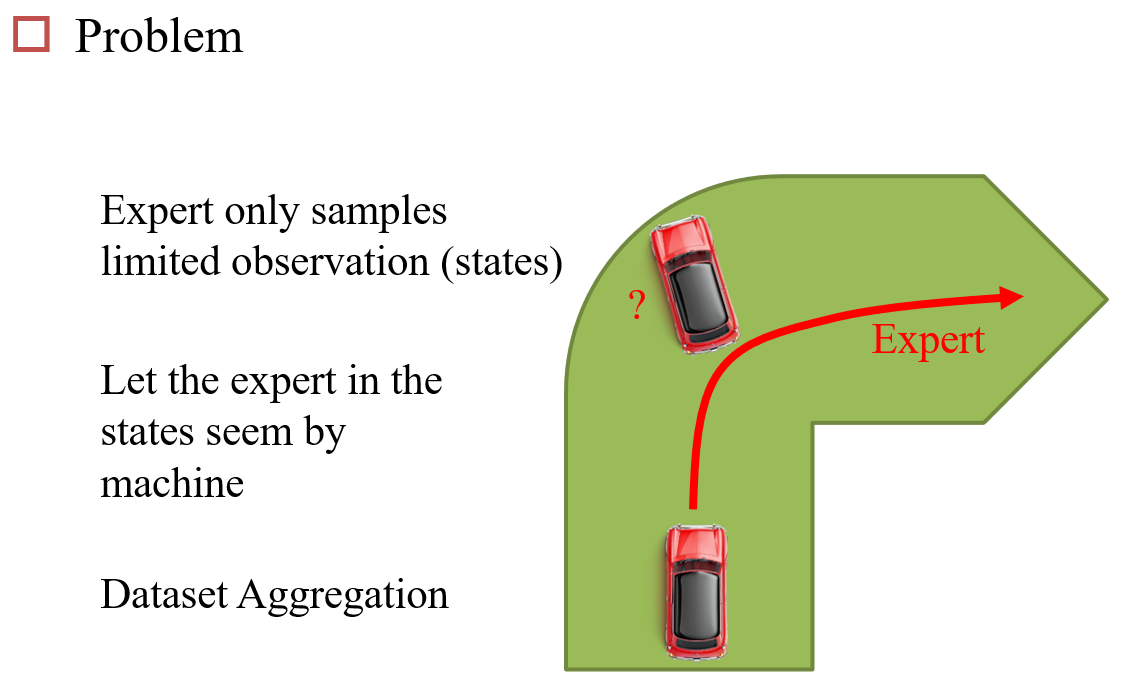
有时候很难定义哪一种操作是更优的,如开车前往目的地,一个直接到达了目的地,另一个歪歪扭扭的到达了目的地,在到达目的地这个任务上,两者表现无法产生差异。因此需要一个第三方的标注/模型,告诉当前模型哪一种选择更优
10.6.1 Behavior Cloning
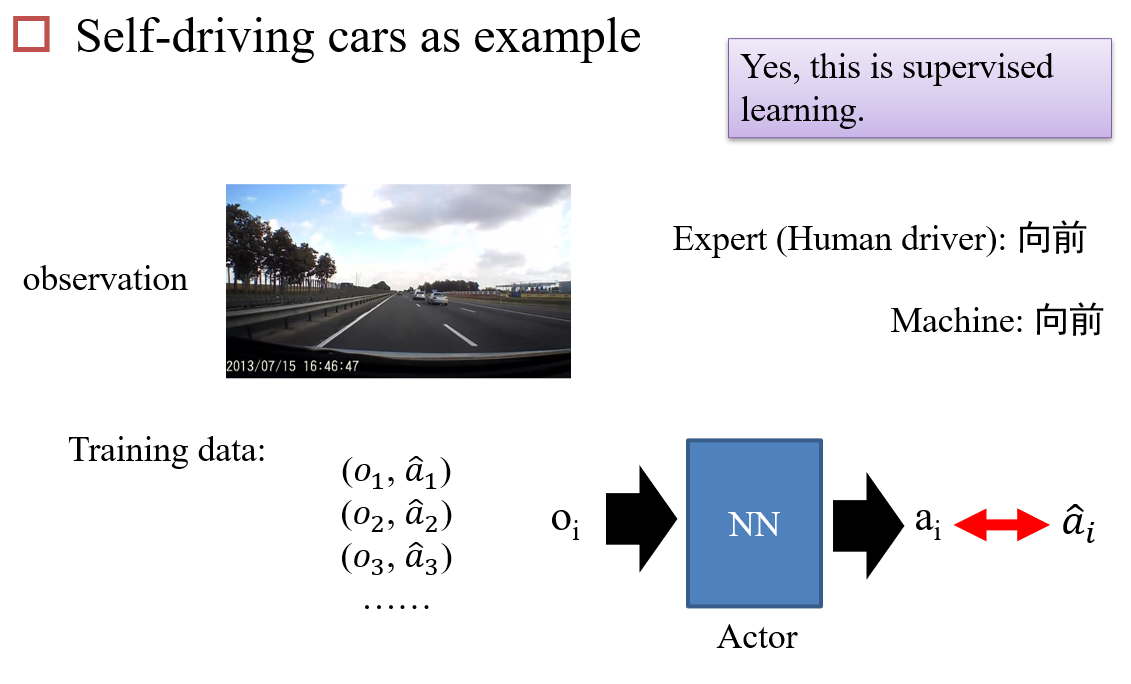
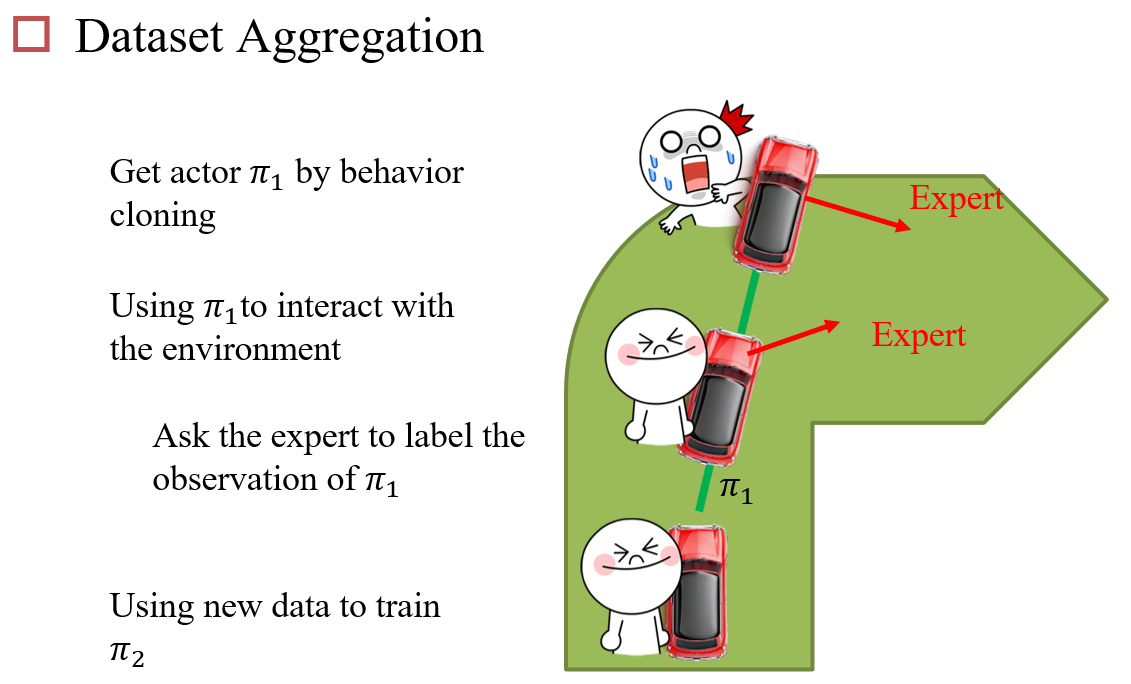
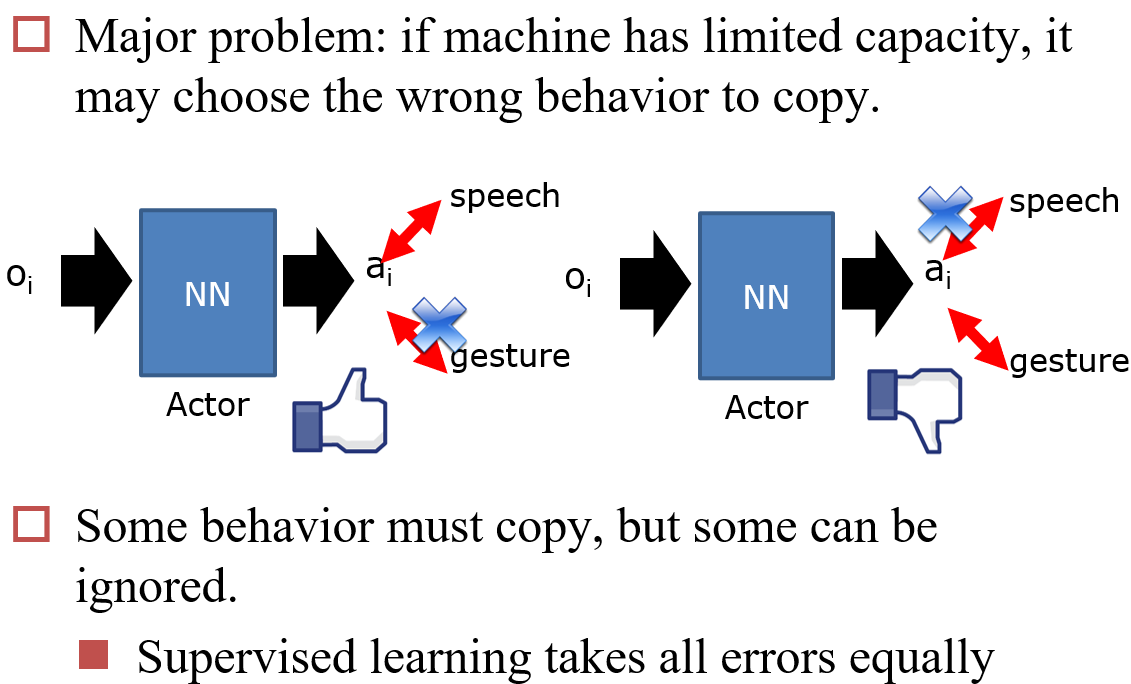
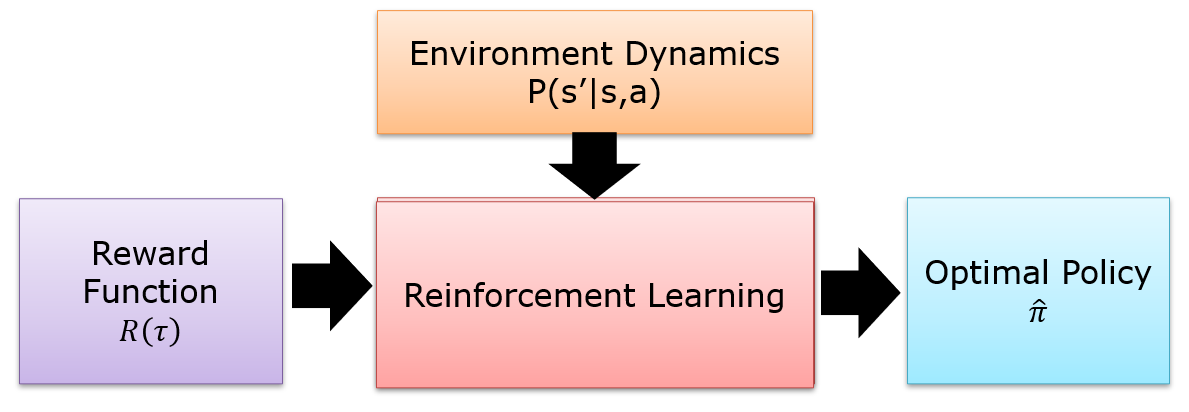
10.6.2 Inverse Reinforcement Learning
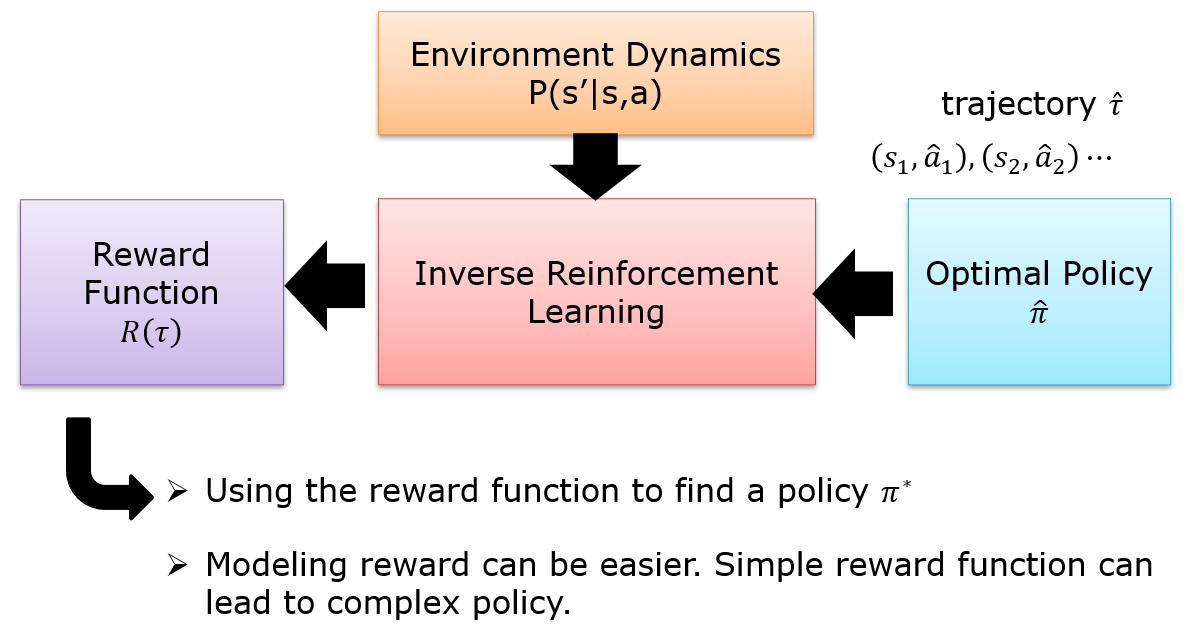


十二、图神经网络
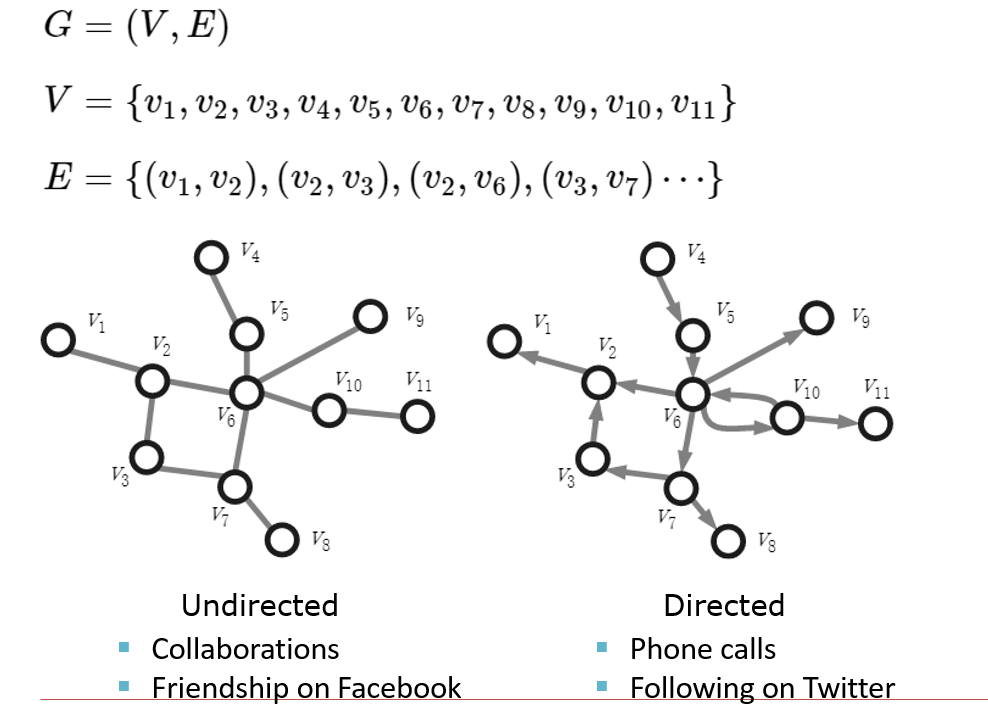
12.1 基础图论
12.1.1 图的稀疏表达
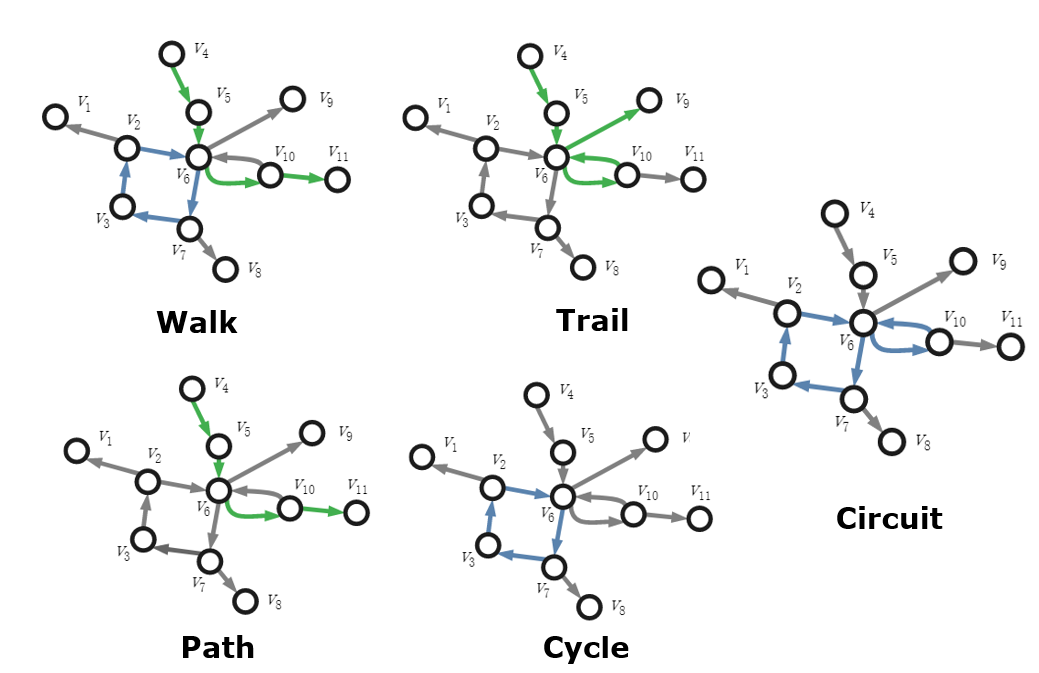
12.1.2 图上的操作
- Walk:从一个节点开始,走到另一个节点
- Path:不存在回头路的Walk
- Trail:存在回头路的Walk
- Cycle:Path的头尾相同
- Cricuit:多个Cycle的集合
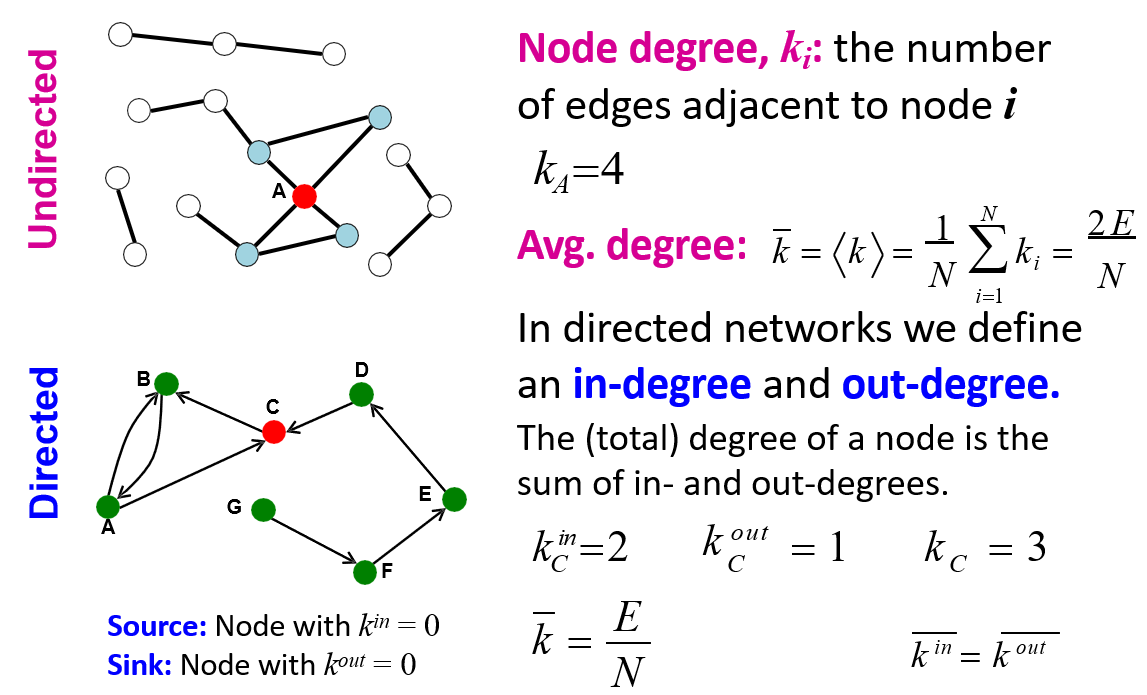
12.1.3 节点的度
12.1.4 邻接矩阵
- 对于无向图来说,邻接矩阵是对称的
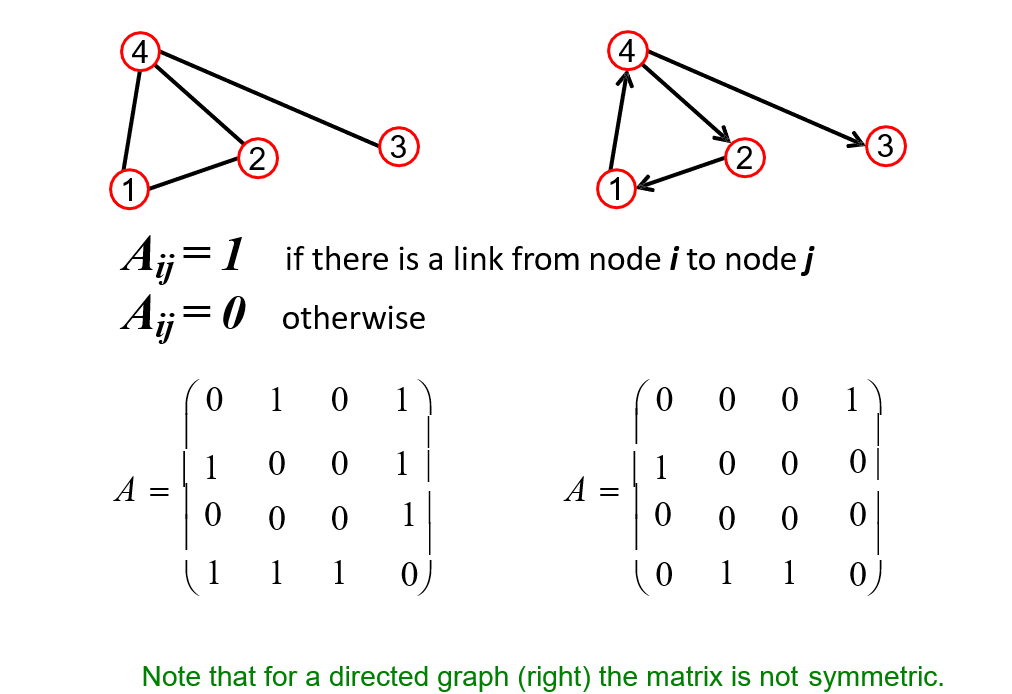
12.1.5 二分图 Bipartite Graph

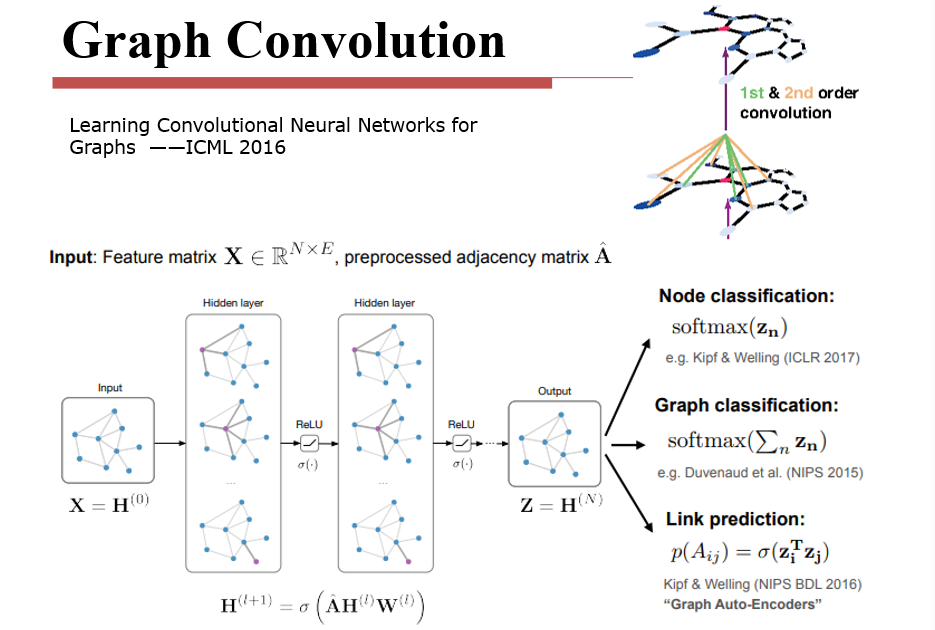
12.2 图神经网络 GNN
Graph Neural Networks
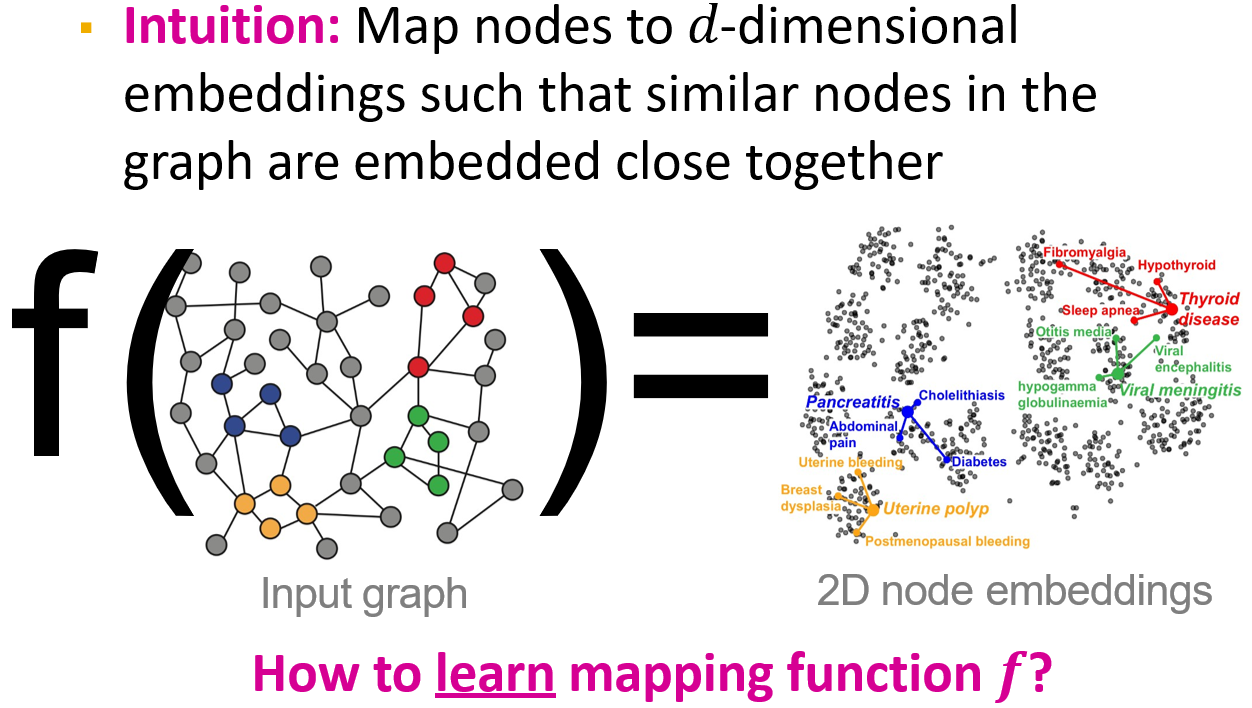
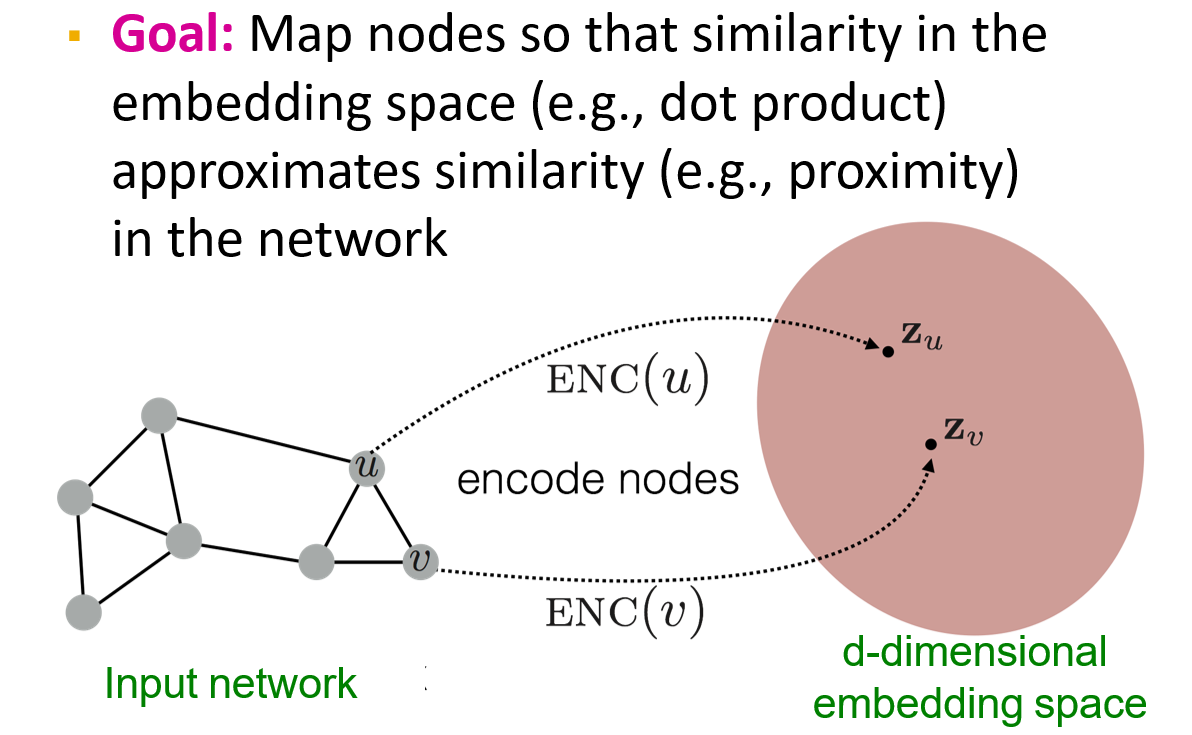
12.2.1 Node Embeddings
学习一个映射函数,将图映射为向量表达
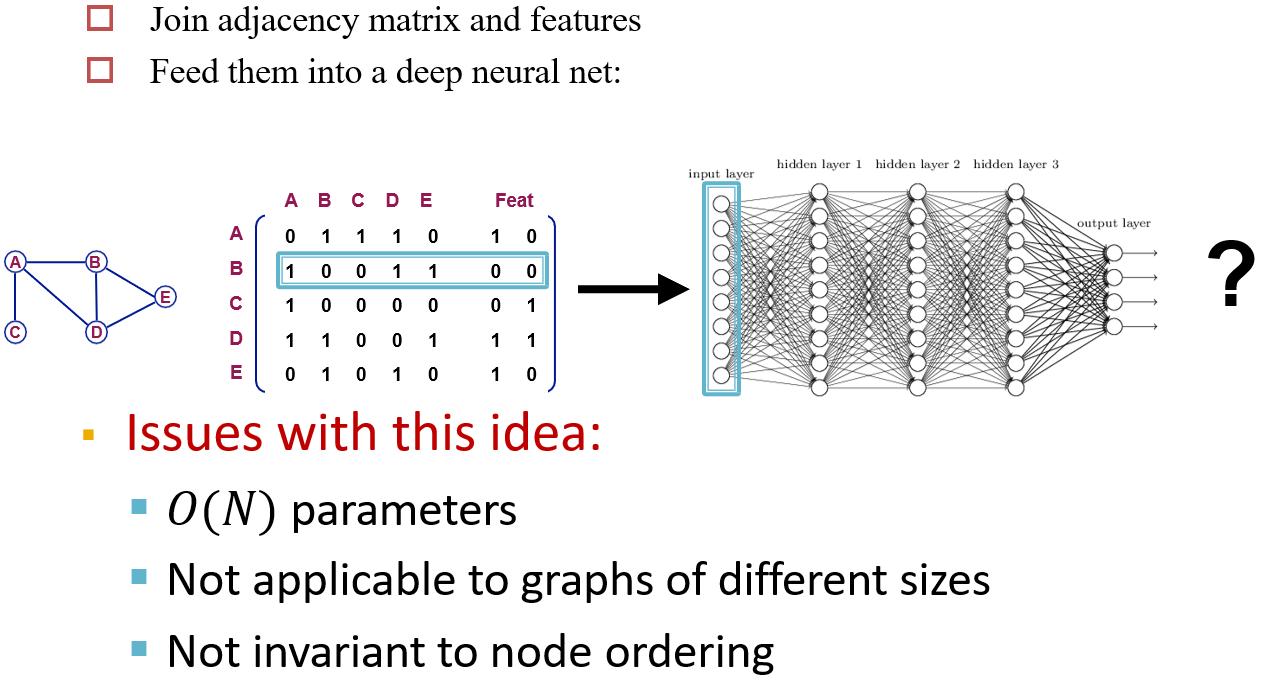
12.2.2 Naive Approach
- 将邻接矩阵和节点的特征组合到一起
- 如果节点不存在特征,则通过编码设置节点的特征
缺点:
- 输入较大
- 限制输入的维度
- 顺序也被视为了一种特征
12.3 图卷积网络 GCN
Graph Convolutional Networks
12.3.1 图卷积操作
将邻居的信息加权,添加到自己的特征中
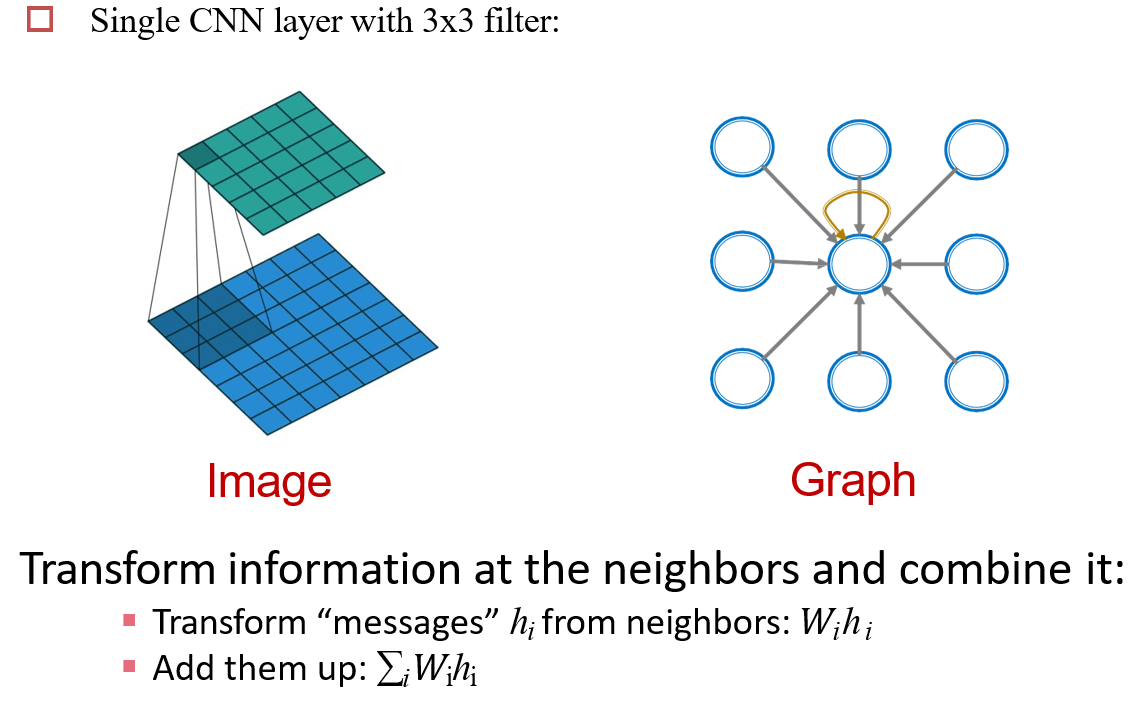
12.3.2 相关定义

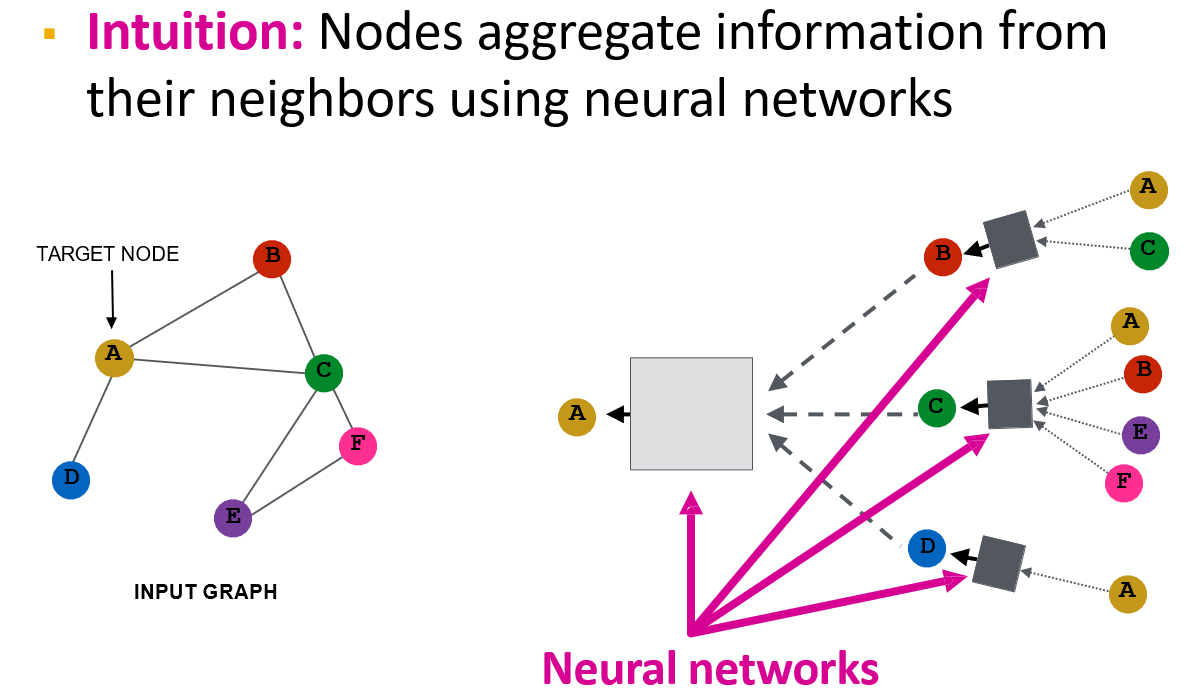
12.3.3 Idea:聚合邻居的信息
- 将邻居的信息,加权聚合到当前节点中
- 多次卷积时,相当于扩大了感受野
- 如第二次卷积时,添加了邻居的邻居的信息
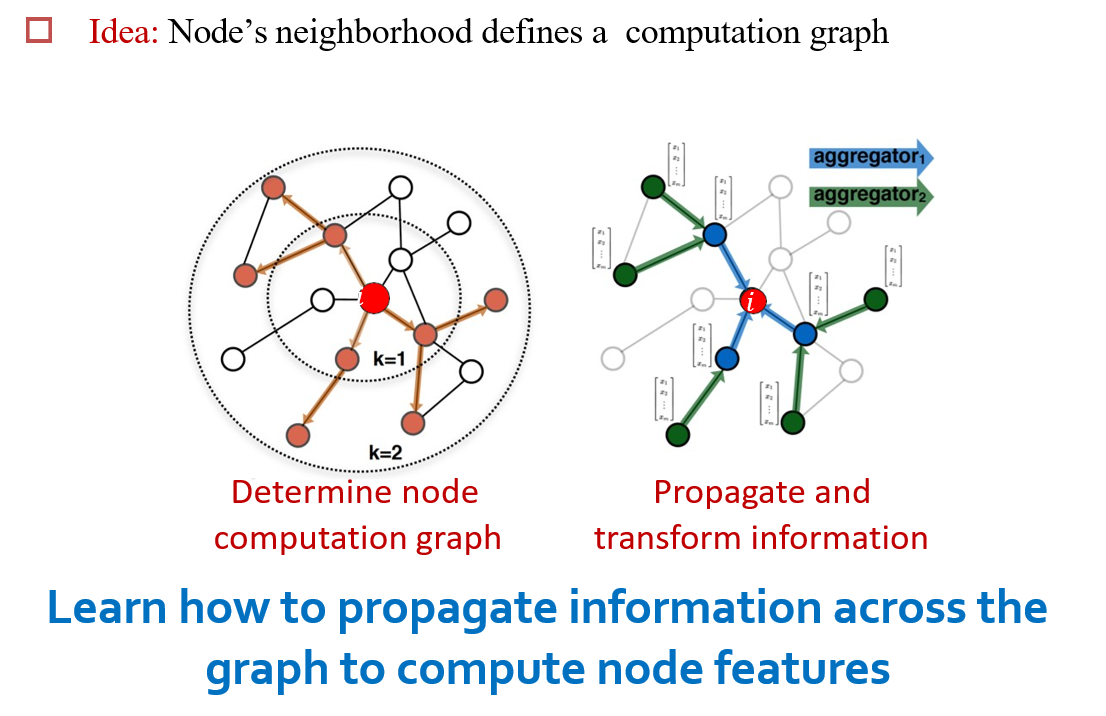
- 每一个节点都要生成一个计算图
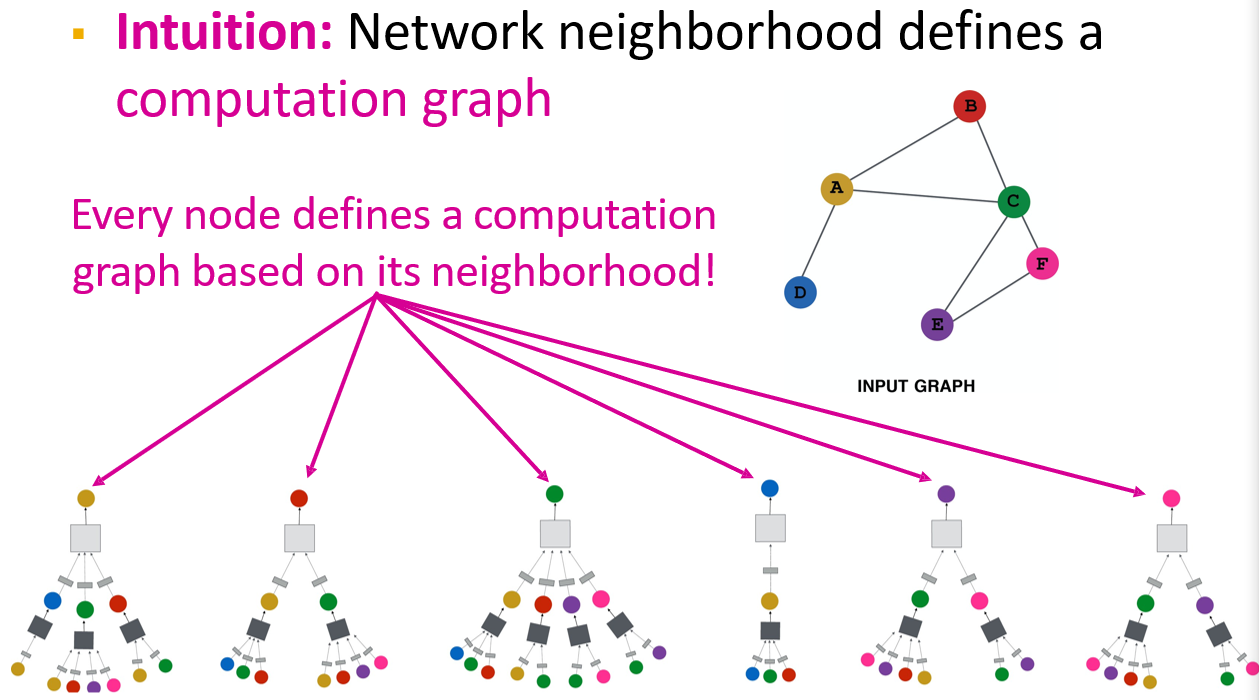
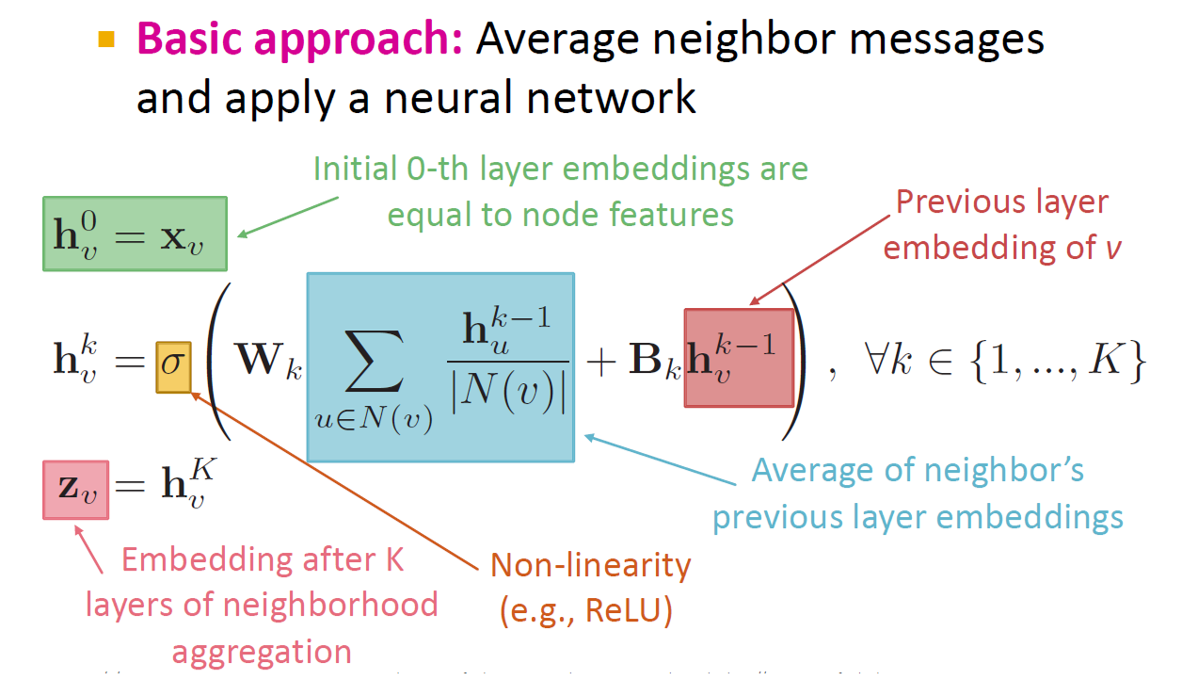
- 计算方法:每次将邻居的信息加权,然后加上自己的信息,过一个激活函数,得到\(h_v^k\)
12.3.4 无监督训练

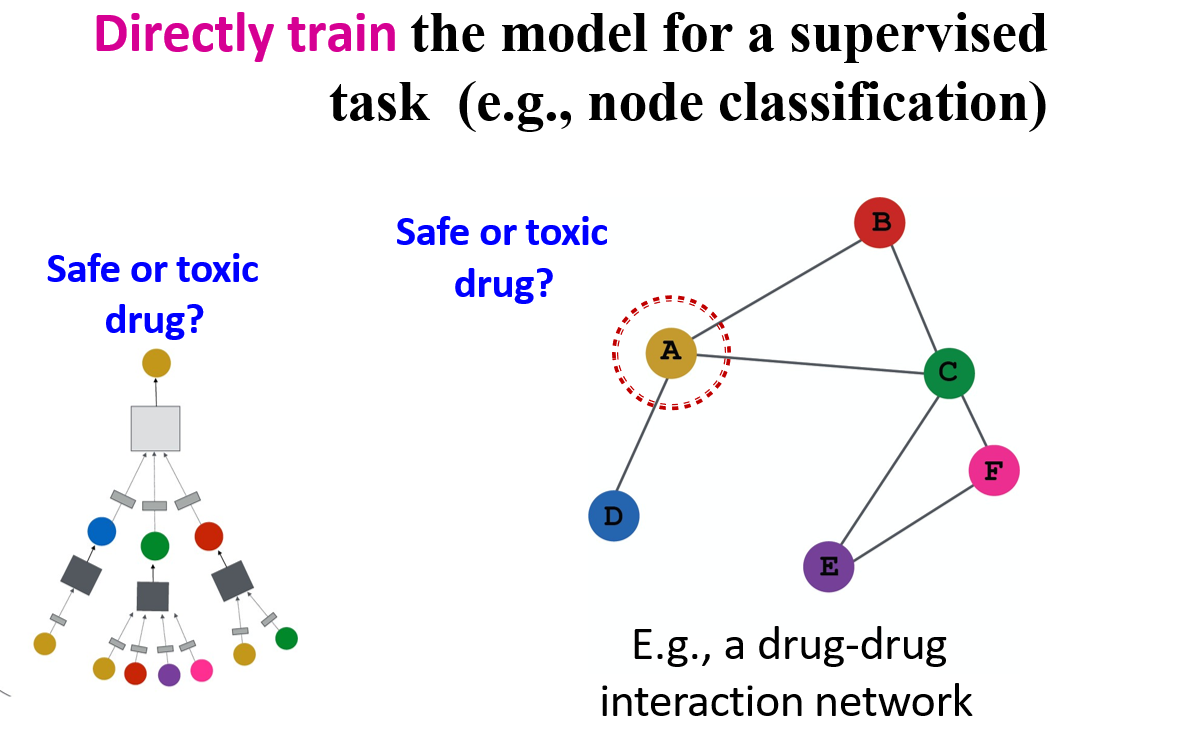
12.3.5 有监督训练
12.3.6 模型的设计
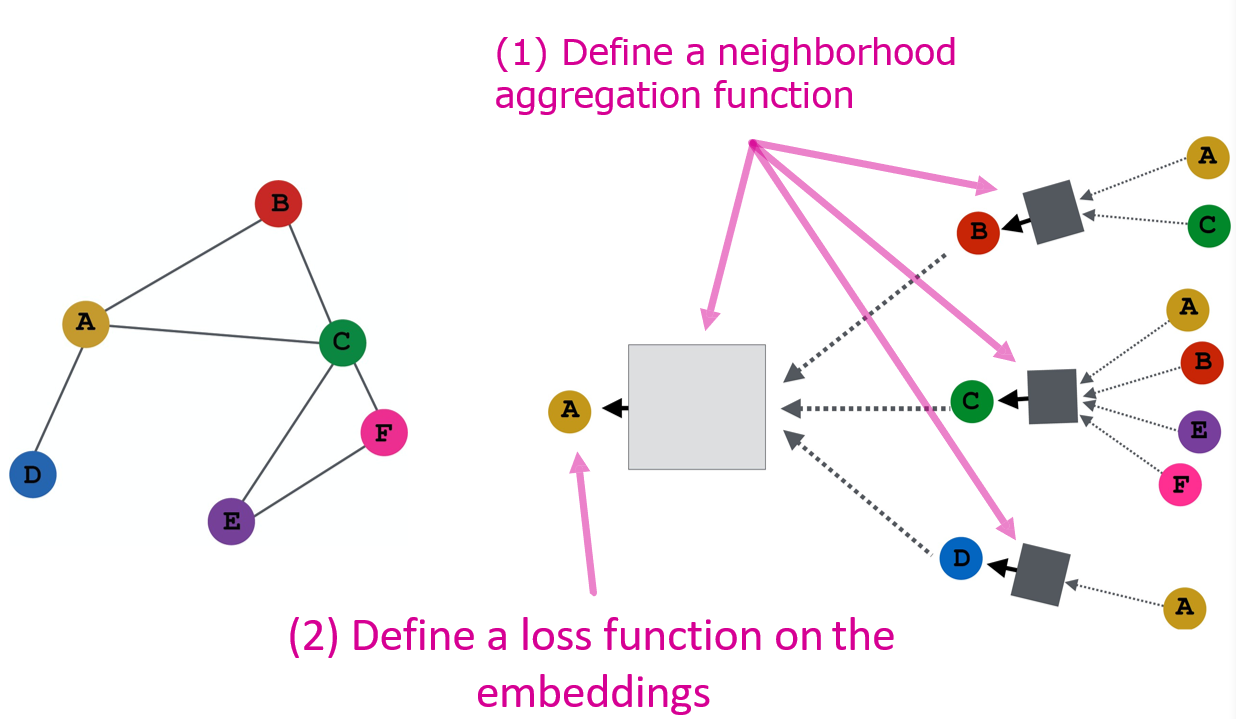
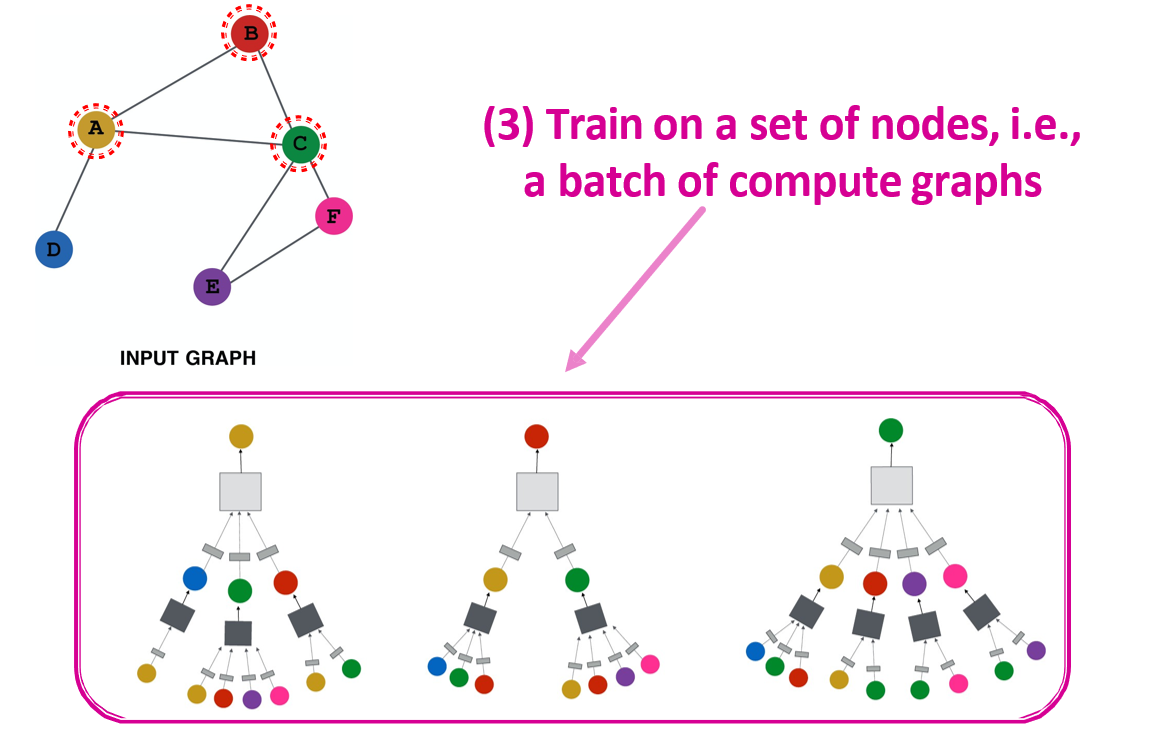
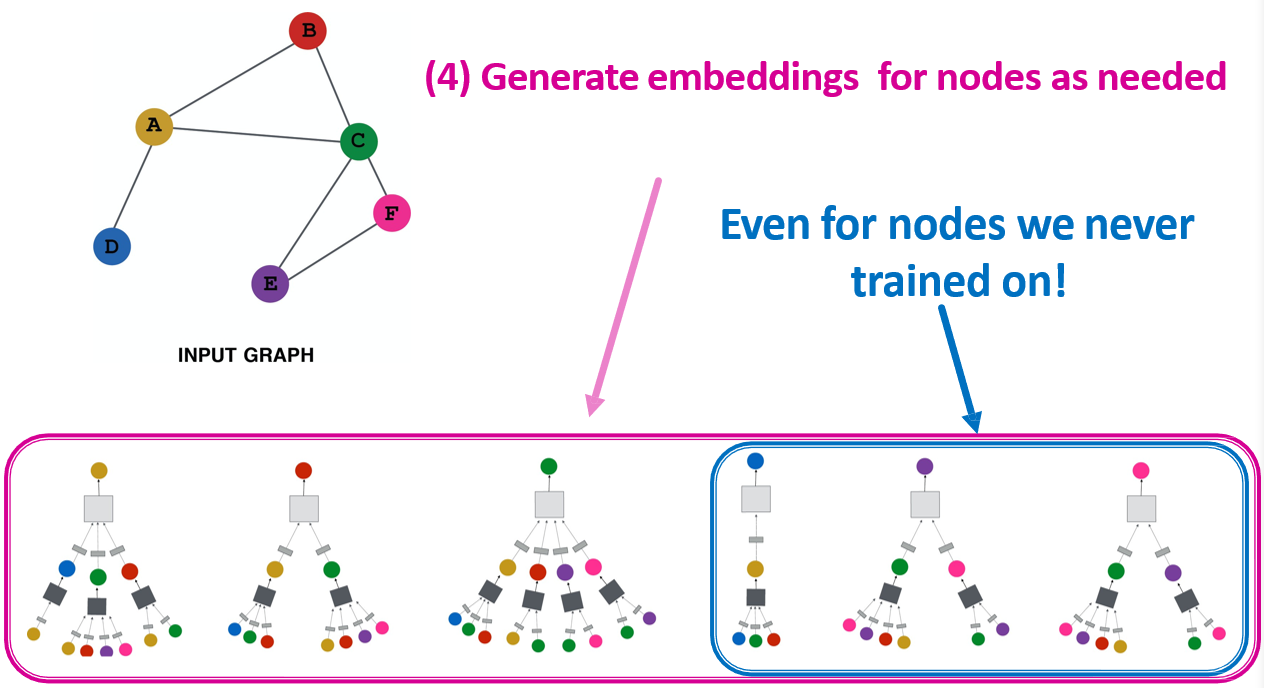
- 由于只学习了投影操作,因此可以很容易的新增一个节点,使用相同方式计算该节点的特征
- 由于参数变化会导致所有节点的特征变化,因此训练和推理的成本都很大
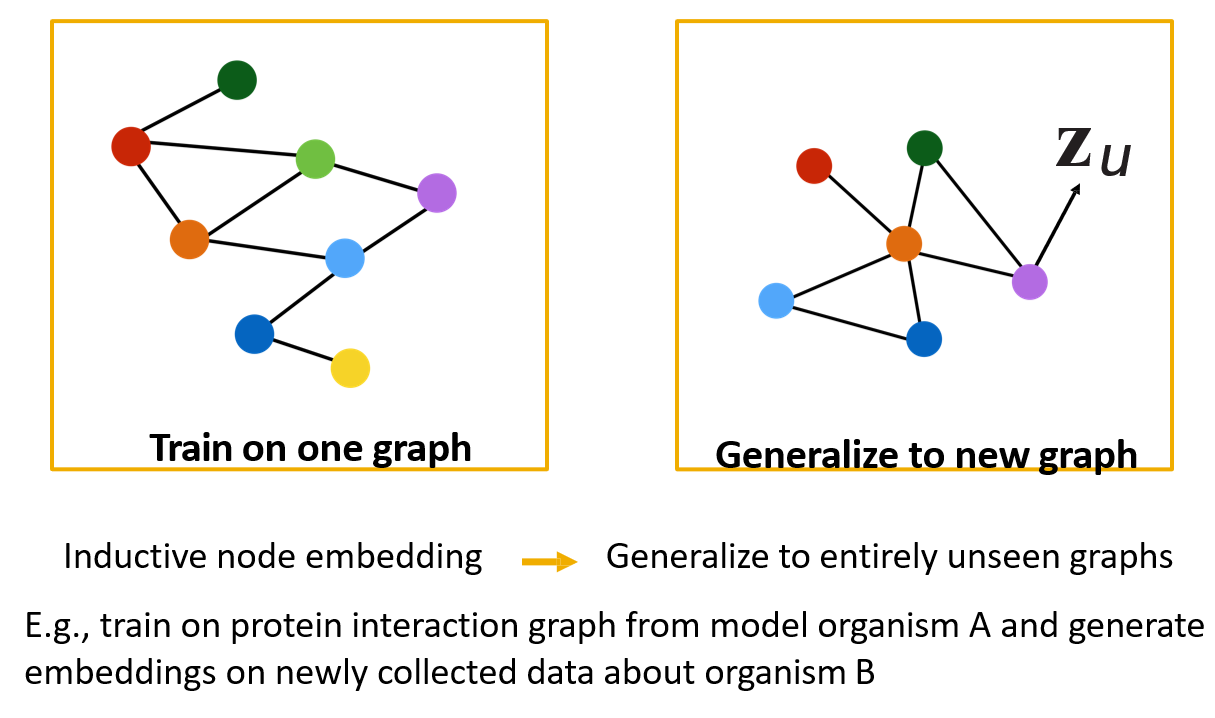

12.4 Spectral-based GNN
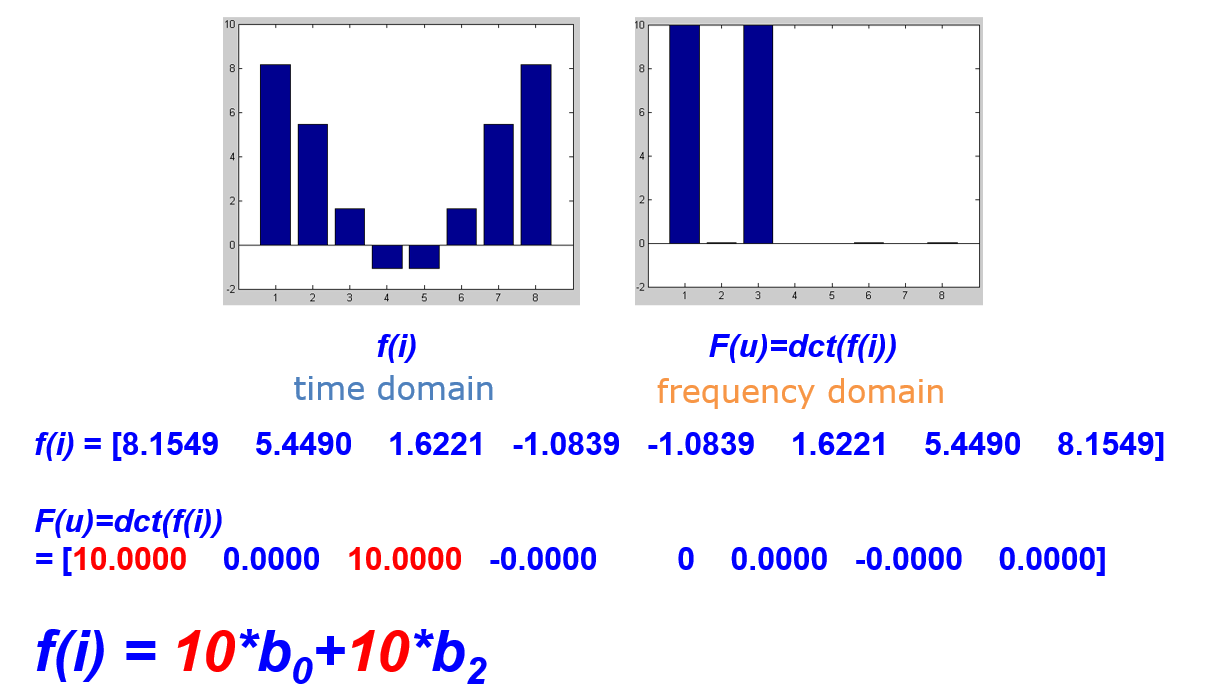
12.4.1 变换编码
- 将一个波形,分解为若干个已知波形的组合
- 只需要记录该波形在每个波形分量上的强度即可
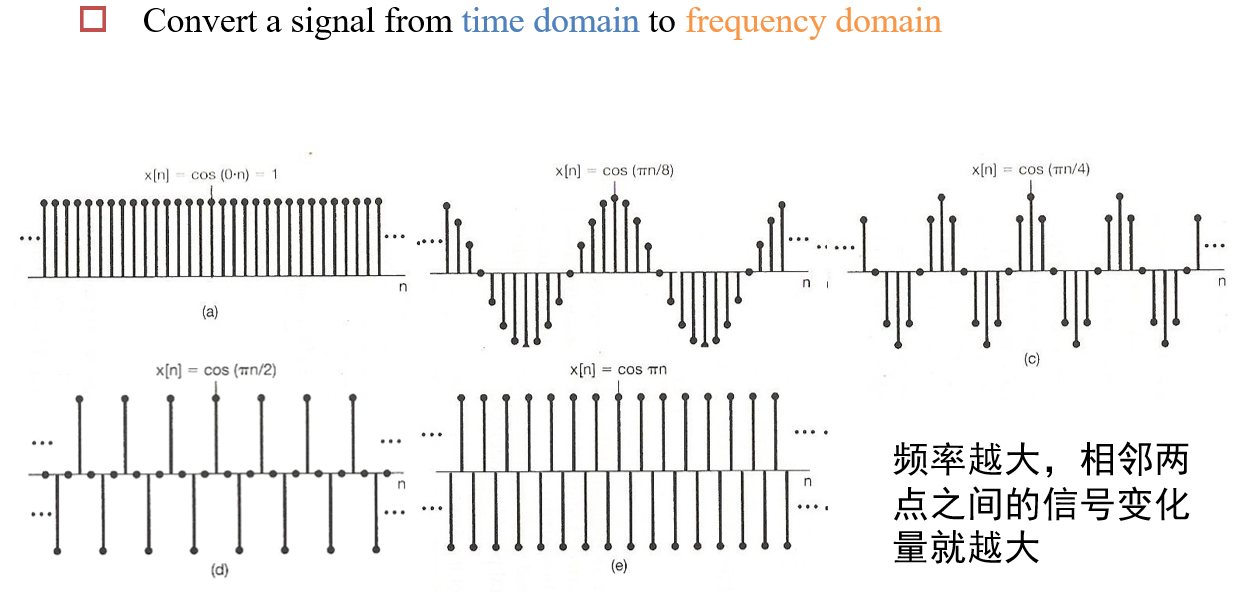
12.4.2 卷积定理
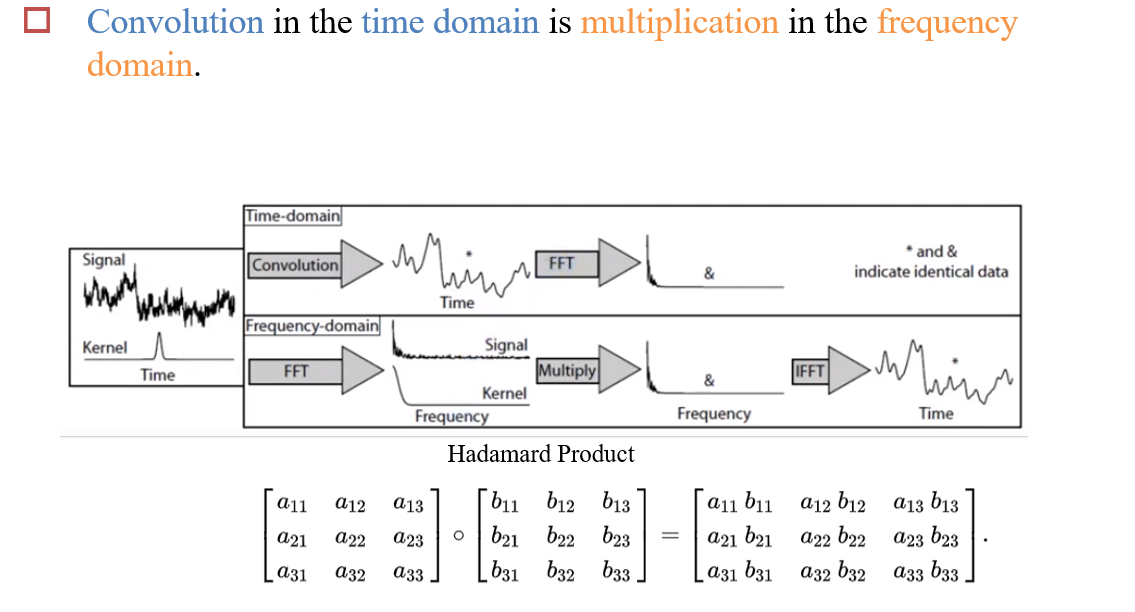
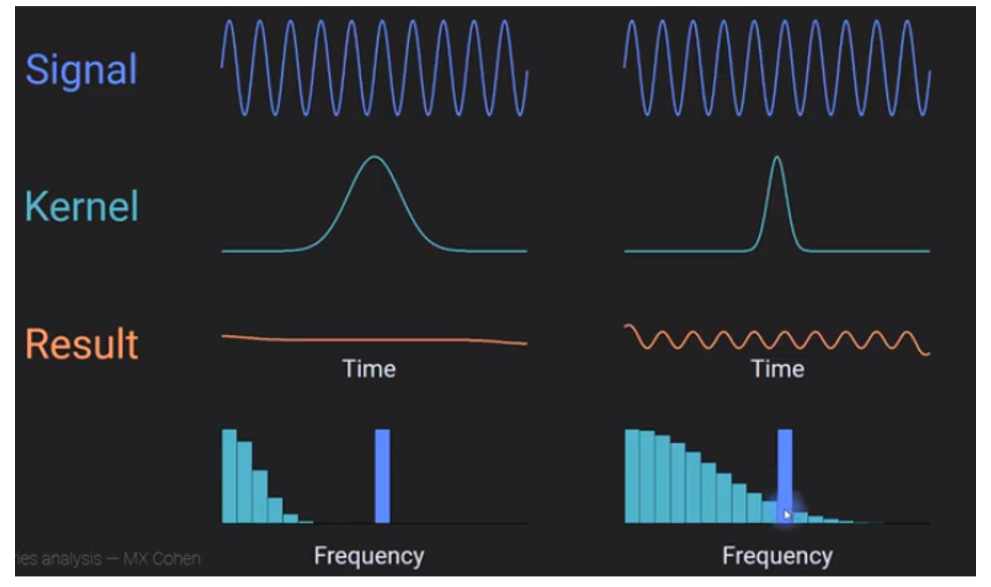
- 时域上的卷积 <=> 频域上的乘积(逐位相乘)
- 因此计算卷积时,可以将原图像和卷积核先进行FFT变换转换为频率空间,然后再将结果进行乘积,得到两者进行卷积操作后的频率空间表示
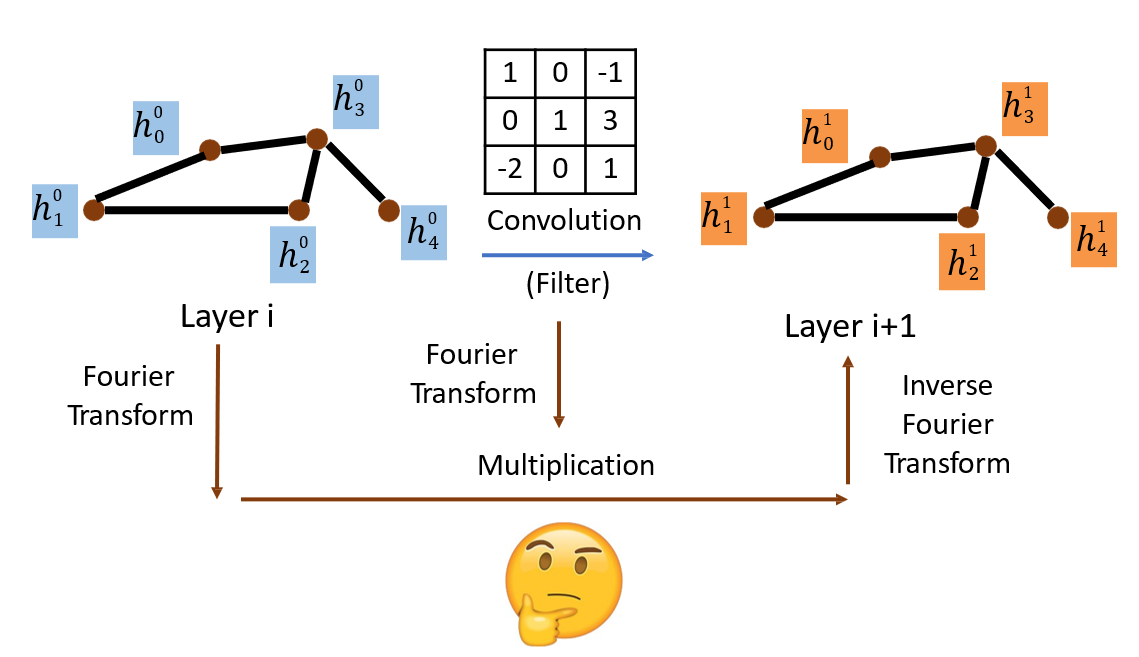
12.4.3 Spectral-Based Convolution
- 对图、卷积核分别进行傅里叶变换,然后相乘,最后再进行一次逆傅里叶变换,得到图和卷积核的卷积结果
12.4.4 Spectral Graph Theory
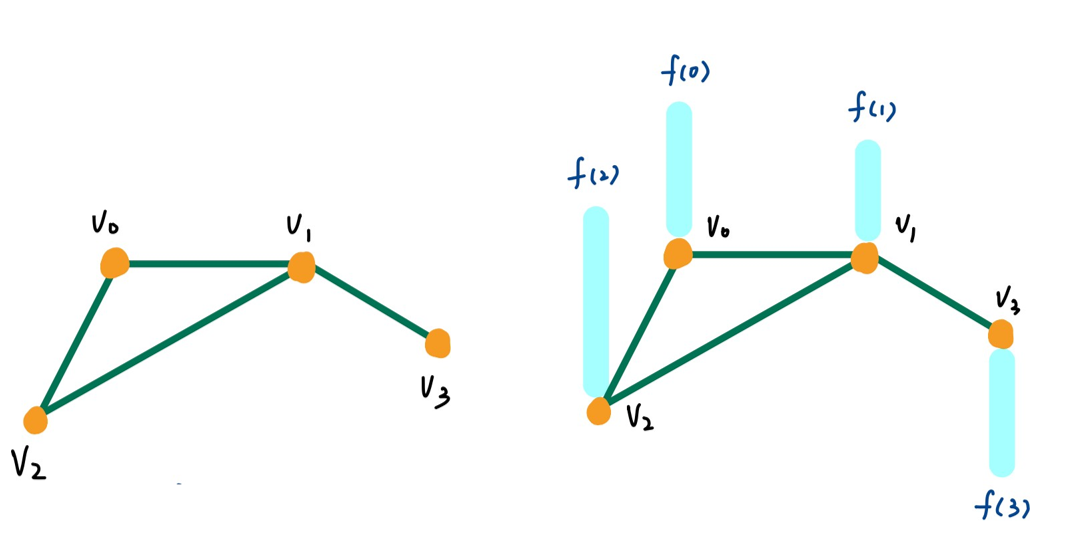
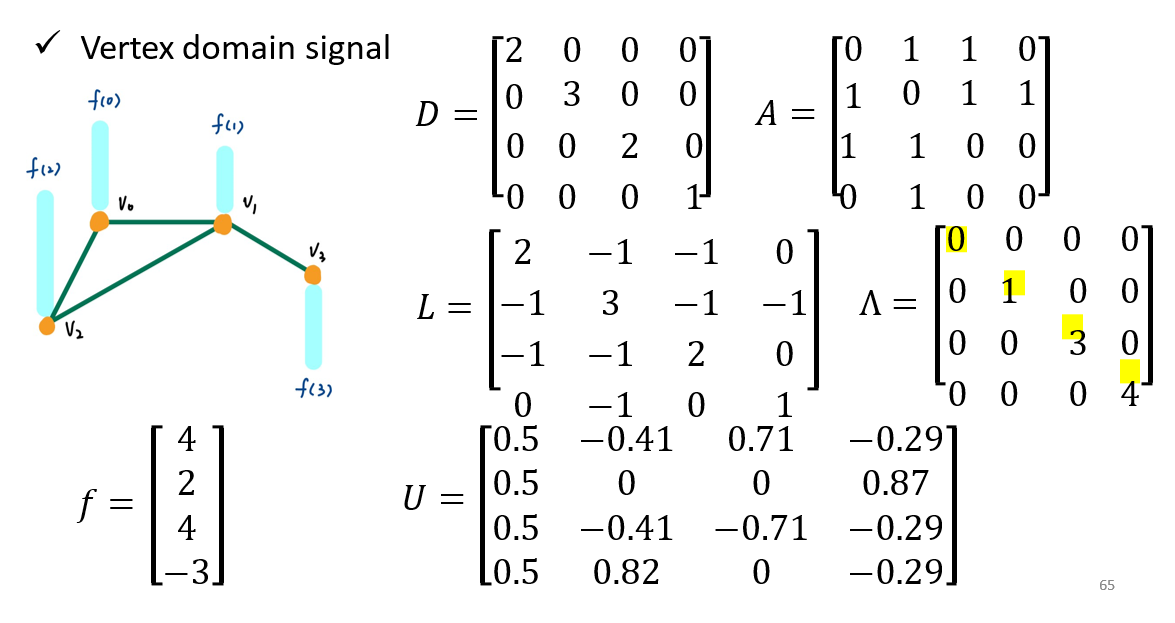
- \(D\):degree matrix,表示每个点的邻居个数
- \(A\):邻接矩阵
- \(L=D-A\):拉普拉斯矩阵
- 对\(L\)进行分解,\(L=UΛU^T\)
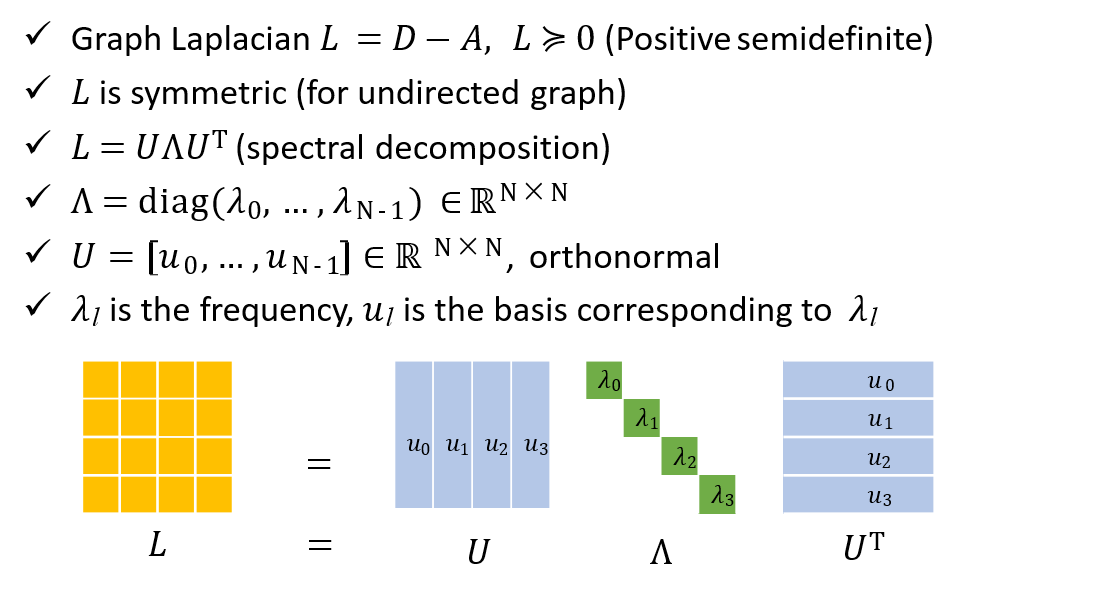
12.5 GCN的缺点
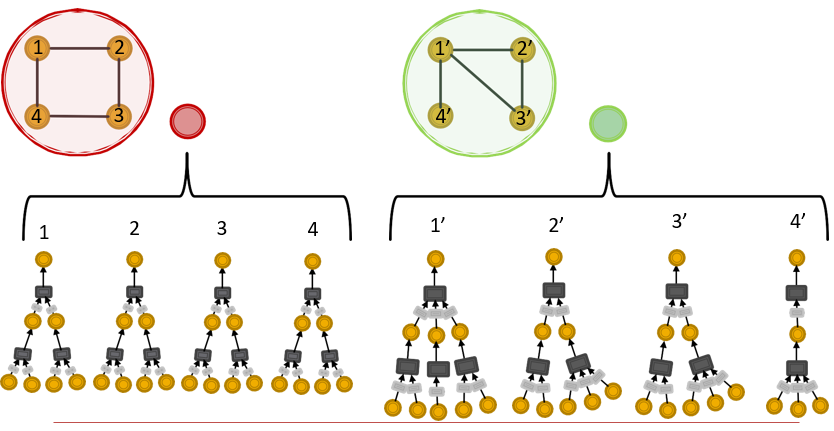
12.5.1 图的同构问题
图结构 => 特征向量 的投影不是一一对应的
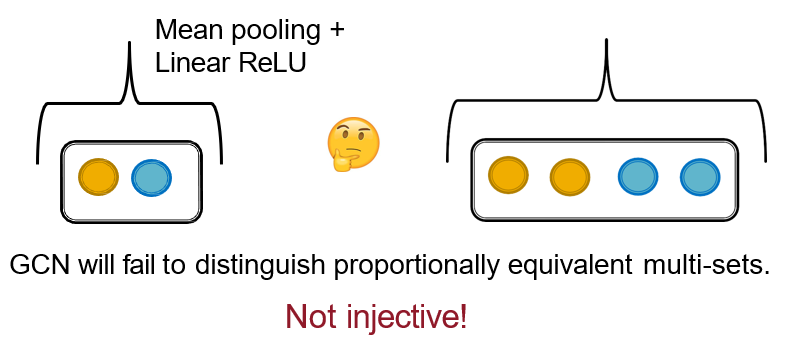
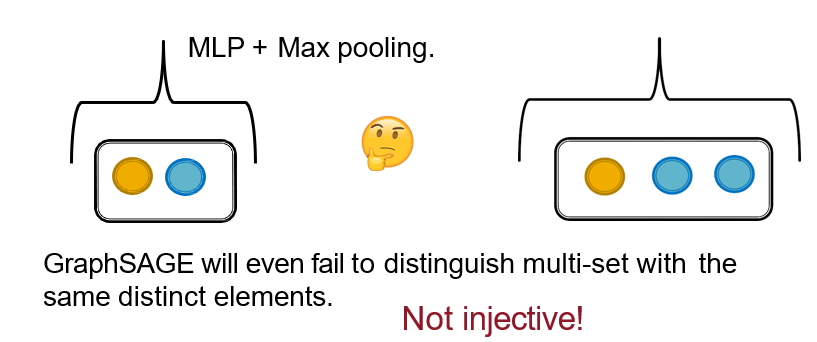
12.5.2 GIN:做邻居节点的aggregation
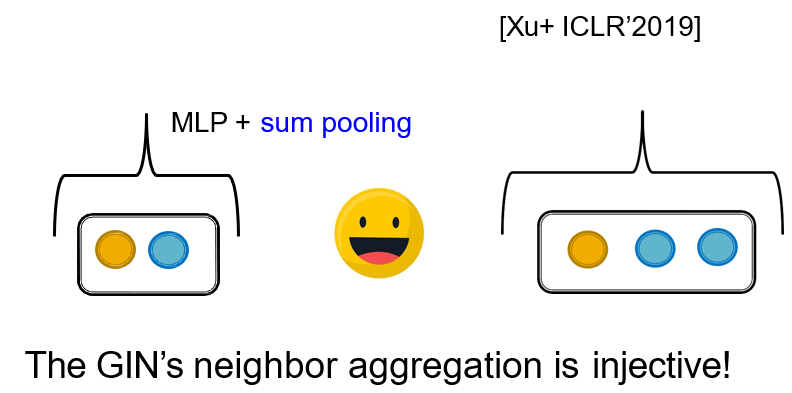
12.5.3 图的同构判断 <=> 图着色问题
K-WL算法:
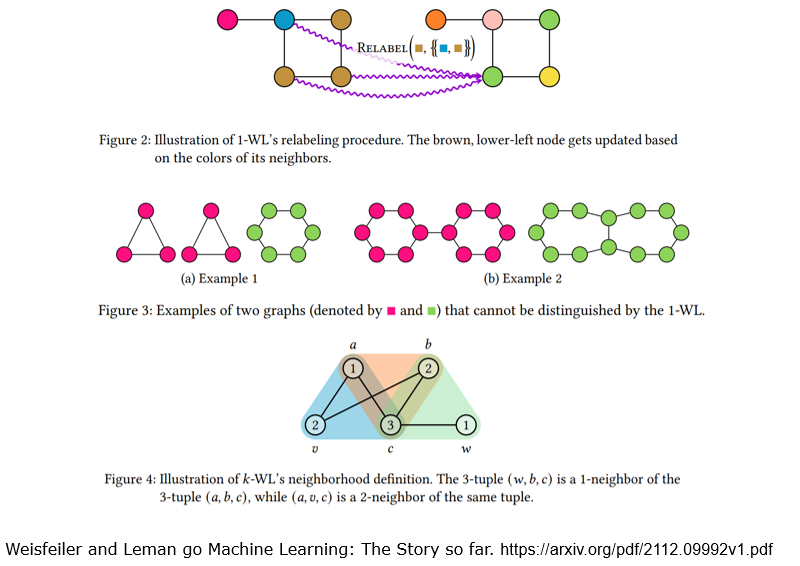
CW网络
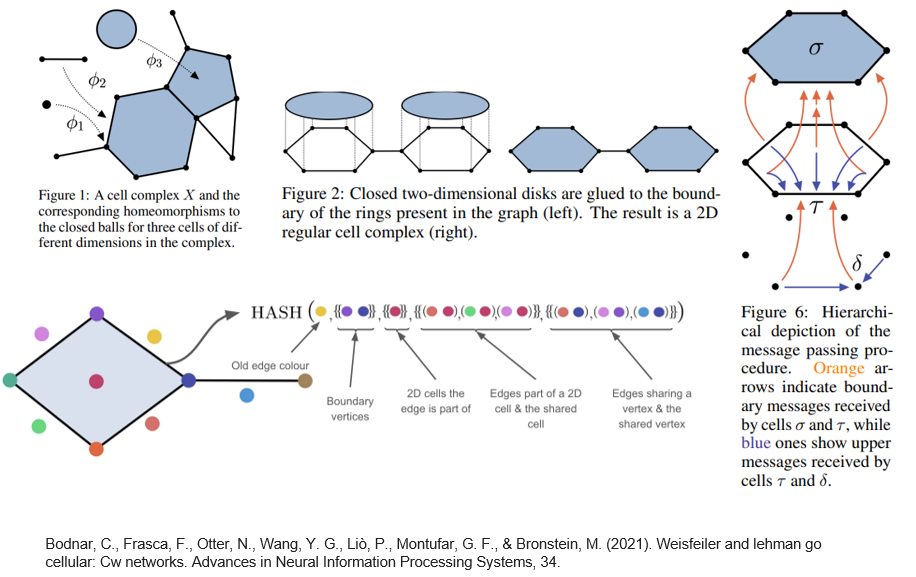
十三、知识图谱
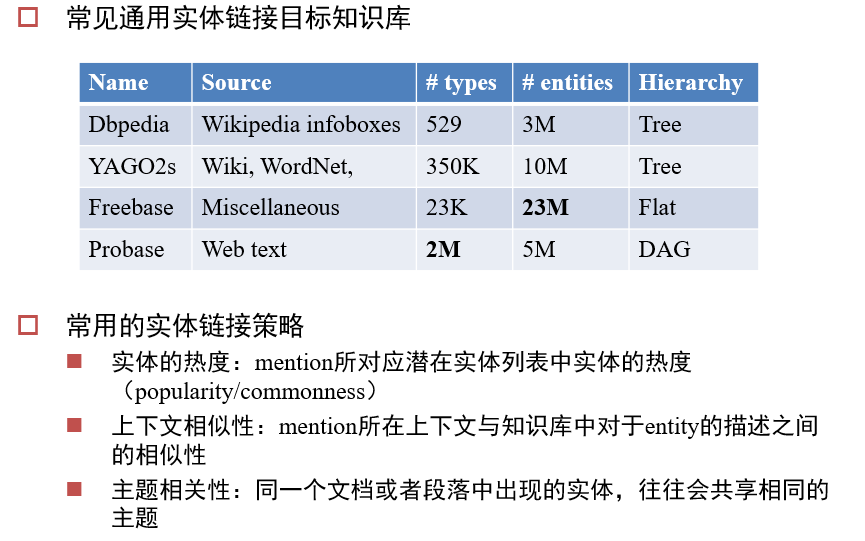
衡量一个知识图谱的好坏:
- 正确性 correctness
- 覆盖性 coverage
- 新鲜度 freshness & usage
13.1 什么是知识图谱
从数据到知识
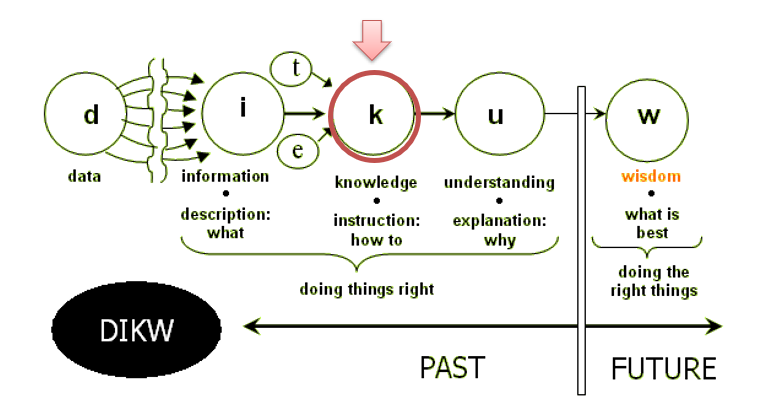
什么是知识图谱:
- 用图来表示知识
- 可以发现邻居之间的关系
- 图是稀疏的,如果用数据库存,则会需要存一个邻接矩阵,有大量的浪费
- 图的节点 => entities,表示当前知识关心的对象
- 图的边 => 表述不同对象之间的联系
- attributes:连接实体、属性
- relationships:连接两个实体
- Ontology(本体):表述图的定义域,如节点都有哪些取值、关系有哪些类型
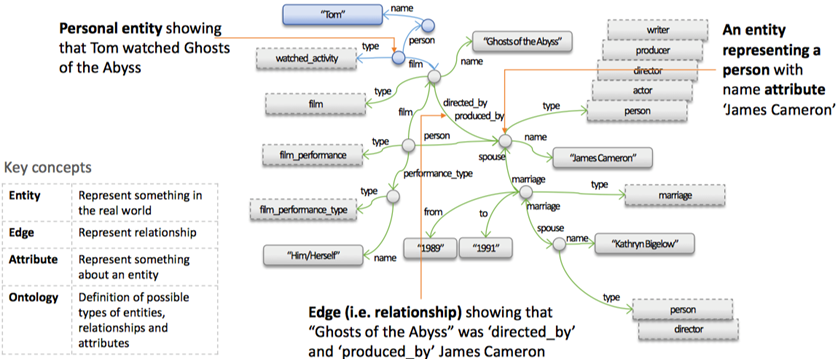
知识图谱与数据库类似,是一个架构,具体存什么东西,由定义决定
13.2 如何构建一个知识图谱

13.2.1 人工构建
- 更新成本高
- 越到后期越难更新,因为需要检查与之前知识之间的关系
13.2.1.1 WordNet

13.2.1.2 BabelNet
多语言
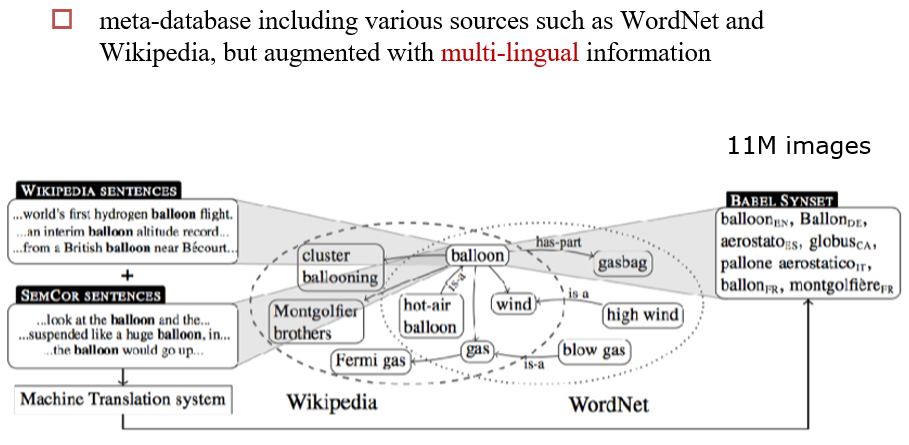
13.2.1.3 Cyc
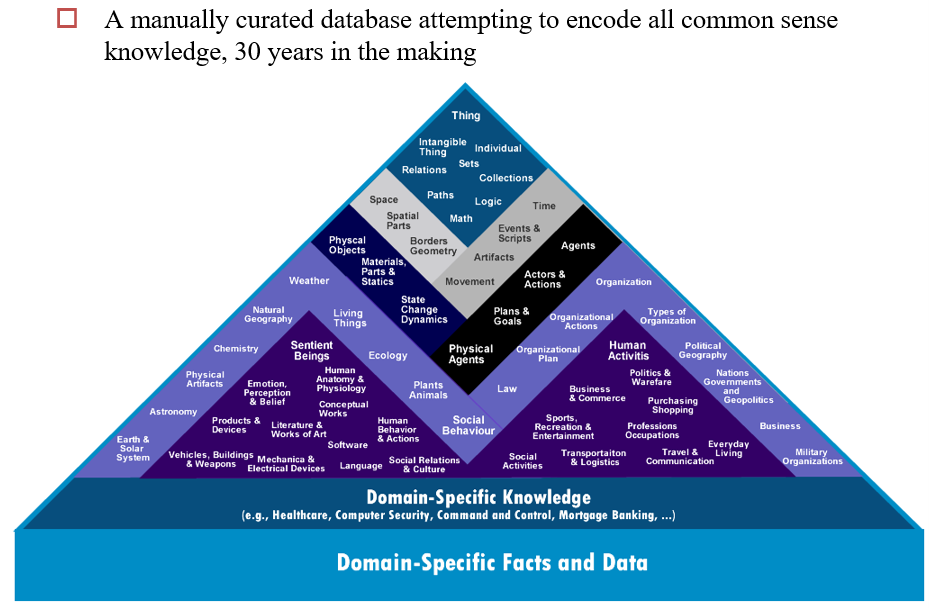
13.2.2 从半结构化数据中抽取信息
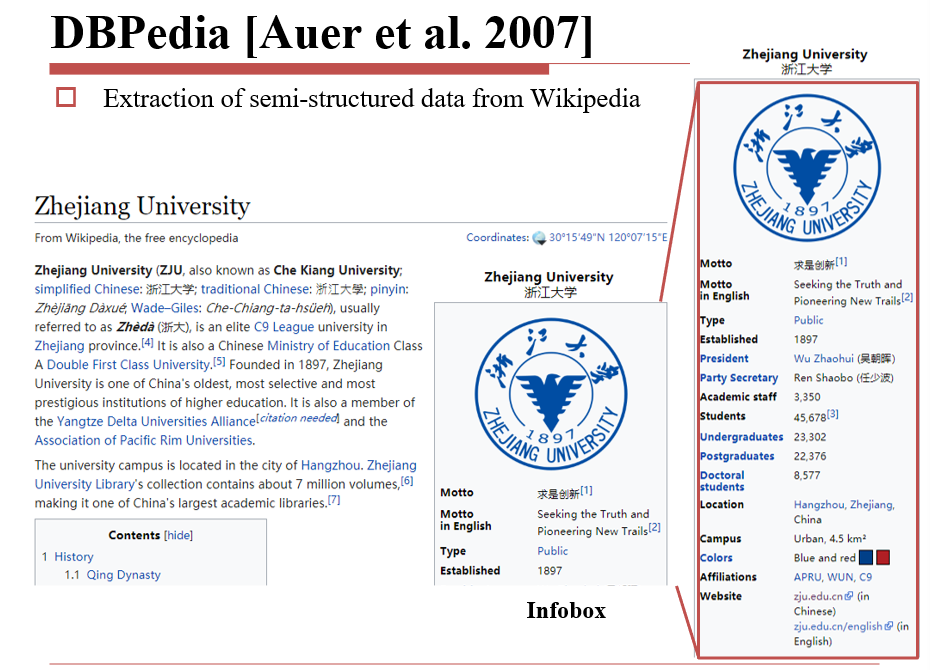
13.2.2.1 DBPedia
直接使用维基百科的info,使用小程序将info的同义标签映射为一种表达
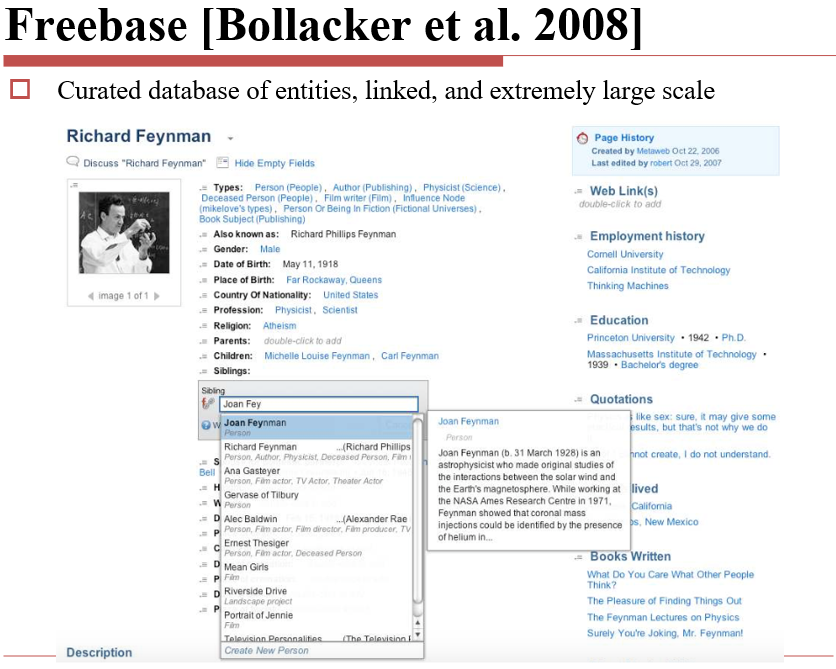
13.2.2.2 Freebase
从Wikipedia中抽取 + 人工标注
13.2.2.3 WikiData
SPARQL:用于查询语义网的Query Language

13.2.3 从非结构化数据中,通过NLP技术,得到结构化的知识图谱
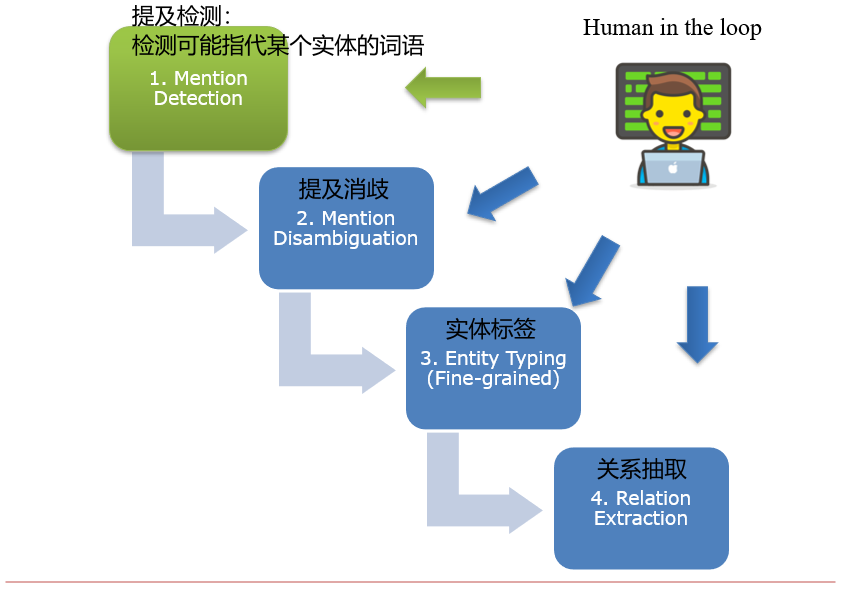
13.2.3.1 Mention Detection:提及检测
NER:命名实体识别,用于识别一些专有名词

几种实现途径:
- 基于规则
- 不需要训练数据
- 但是需要由一些特定的知识
- 非监督&迭代方法
- 先收集一些种子规则,然后标注一些数据,训练一个模型,提炼新的规则
- 然后再标注数据,训练模型,提炼规则......
- 特征工程


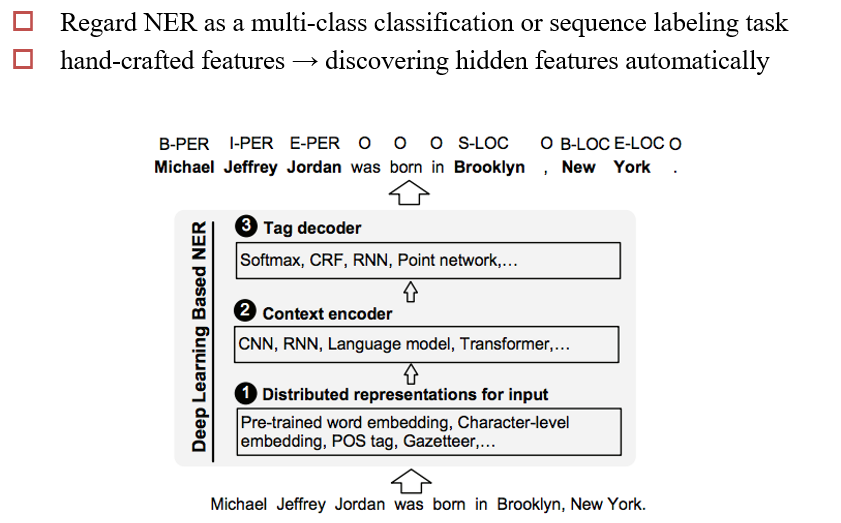
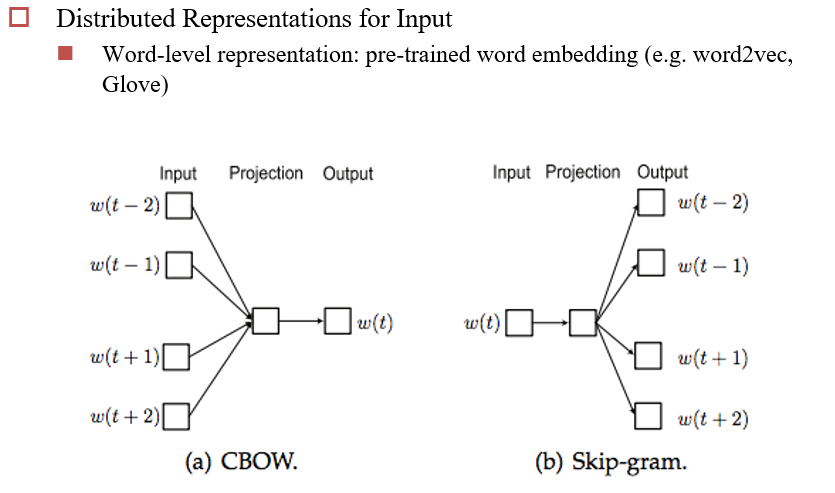
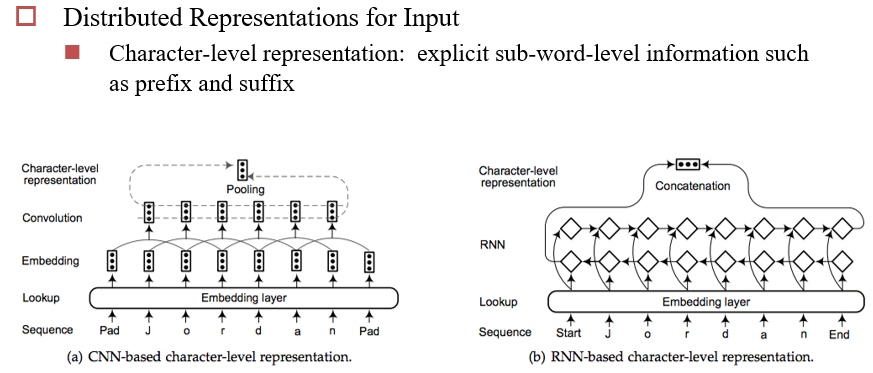
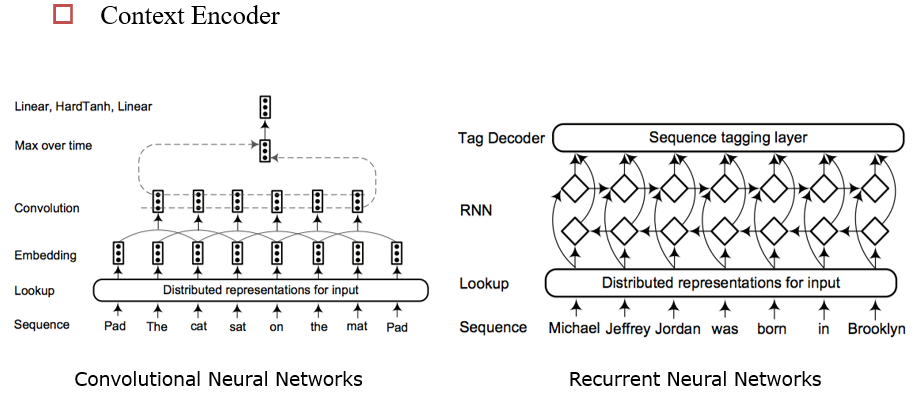
Deep Learning For NER
- 分类数:IBOE×PER/LOC:8类
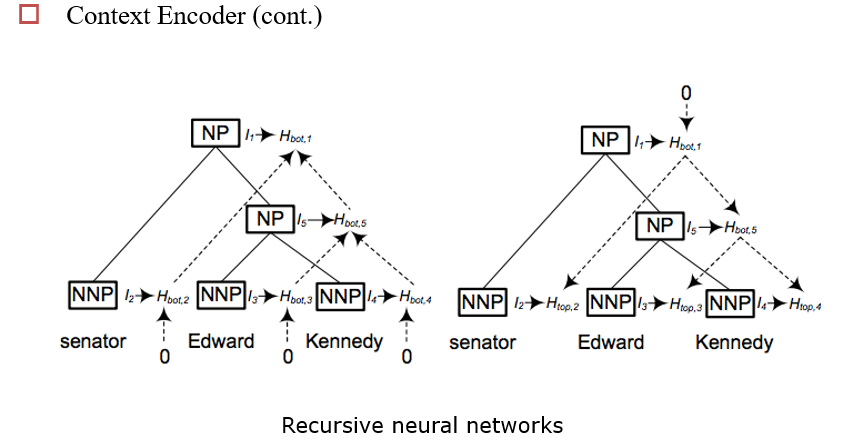
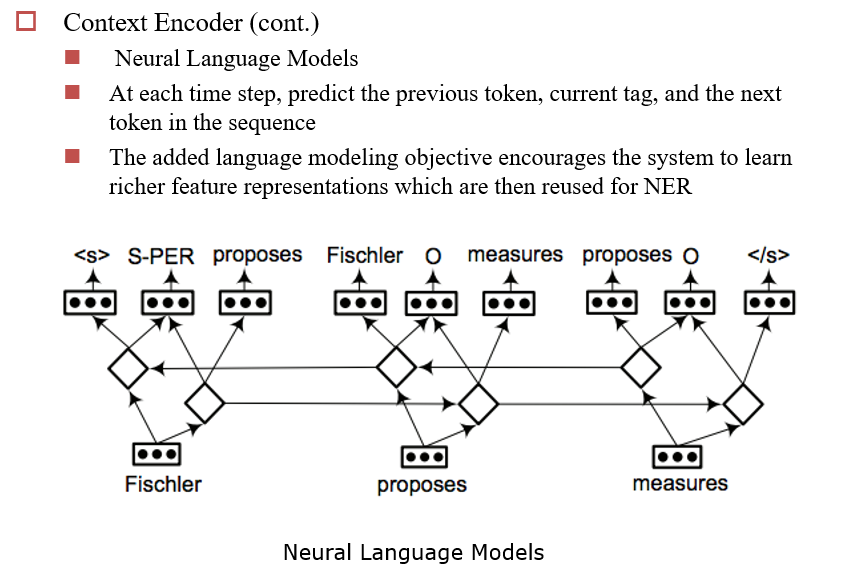
13.2.3.2 Multi-task Learning 多任务学习
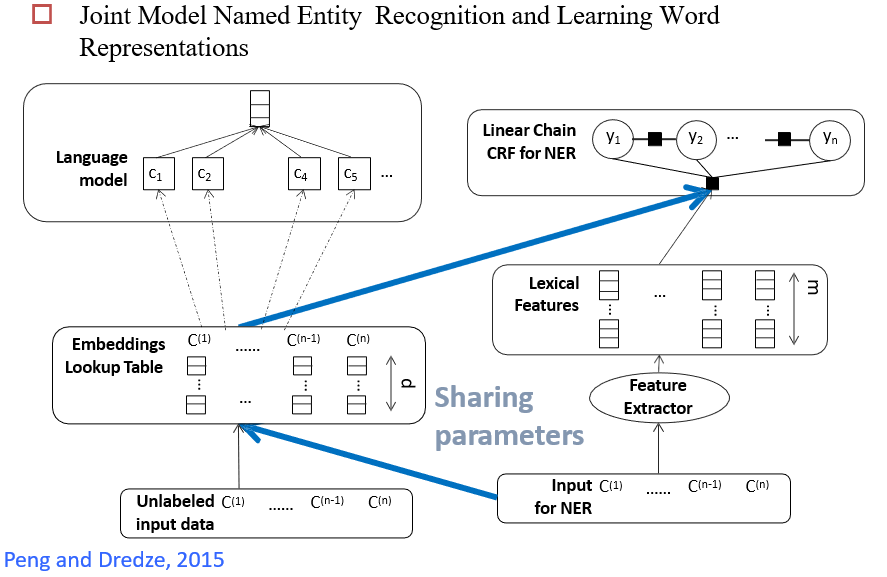
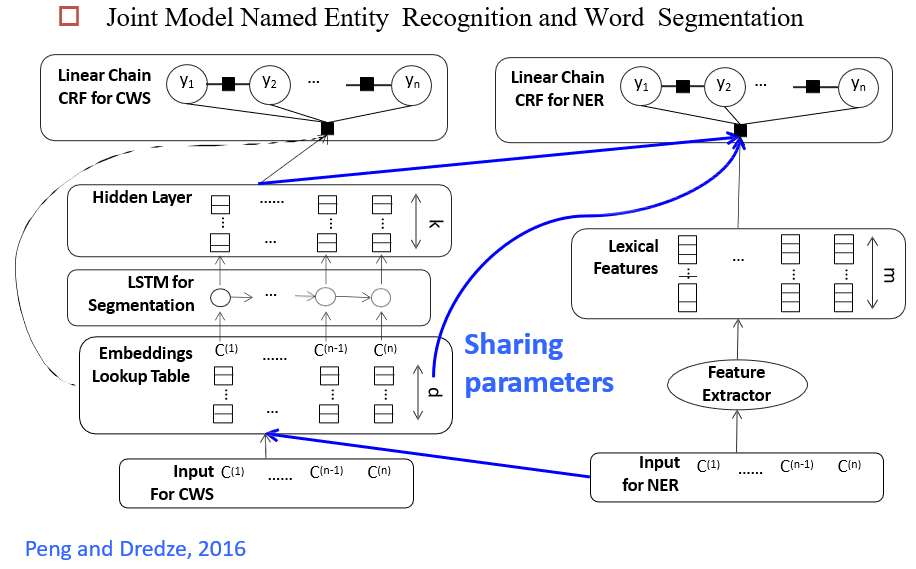
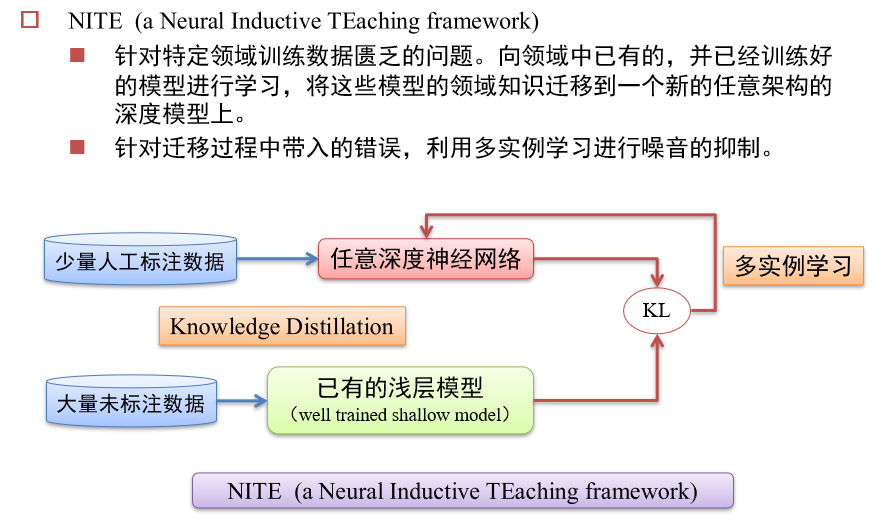
13.2.3.3 Knowledge Distillation 知识蒸馏
将大模型的知识,教给小模型
- 可以收集很多未标注数据,交给大模型生成标签,然后交给小模型训练
- 小模型可以模仿大模型的输出,也可以模仿大模型的中间状态
- 小模型学习的是大模型的logists,即经过softmax之后的结果
- 在蒸馏的时候,要调整温度\(\tau\),温度越大,logist越平缓
多实例学习MIL:抑制噪音
- 假设一种化学式有ABC三种同分异构体,A是有效成分,但是生产的药品都是混合物。数据只能表示某个混合物是否有效,但我们的目标是找出有效成分。
- 假设当前的数据为:AB有效,AC有效,BC无效,在训练时,从包里随机挑选一种成分作为输入,给出对应的标签,让神经网络学习。
- 由于是随机采样,每个成分被选中的概率相同,但是药物是因为含有A而有效,从而模型会微微偏向A有效,然后在下一次采样中,模型会更加倾向于选A。
- 通过多轮迭代,强化这种倾向,最终模型会学习出来A是有效成分
13.2.3.3 Mention Disambiguation:提及消歧
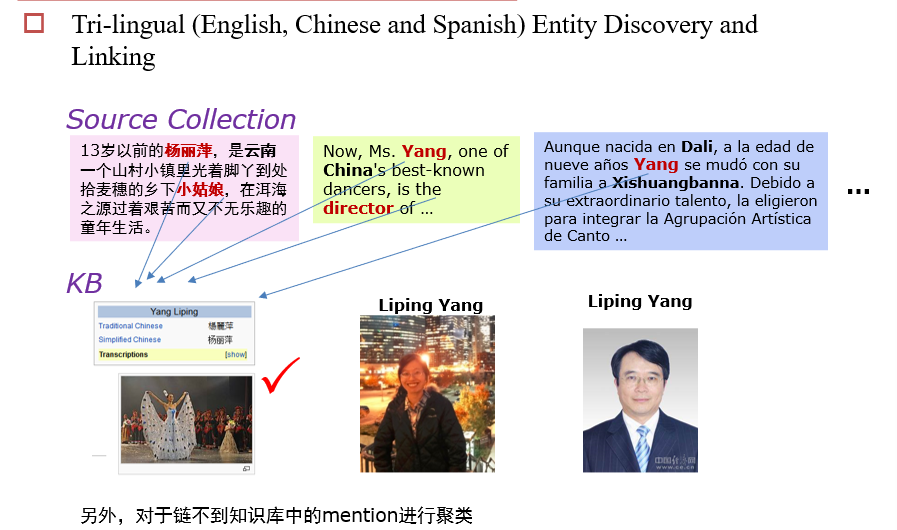
Entity Linking

输入:文档
输出:mention及其对应的title

- 找到文档中的mention
- 每个n元组都是可能的mention
- 基础过滤:删除chunk(固定词组)、stop word
- 基于统计的过滤
- 对mention进行扩展:词根化、将缩写变成全拼/全拼变成缩写
- 尽可能全的找到与mention有关的title
- 基于Name Dictionary:通过维基百科/数据挖掘
- Redirect pages:将不同的词重定向到同一个页面
- Disambiguation pages:一词多义
- Bold phrases from the first paragraphs, hyperlinks:第一段的粗体、超链接
- 基于搜索引擎
- 基于Name Dictionary:通过维基百科/数据挖掘
- 局部Inference
- 全局Inference
- 空聚类
13.2.3.4 实体链接任务