计算机体系结构
Chapter 1:Introduction
1.1 Current computer
什么是CA(Computer Architecture)
计算机架构是:选择和连接硬件组件以创建满足功能、性能、成本和功率目标的计算机的科学和艺术
它是计算机各个部分的需求和设计实现的蓝图和功能描述,主要关注中央处理单元(CPU)内部执行和访问内存地址的方式
Tradeoff取舍
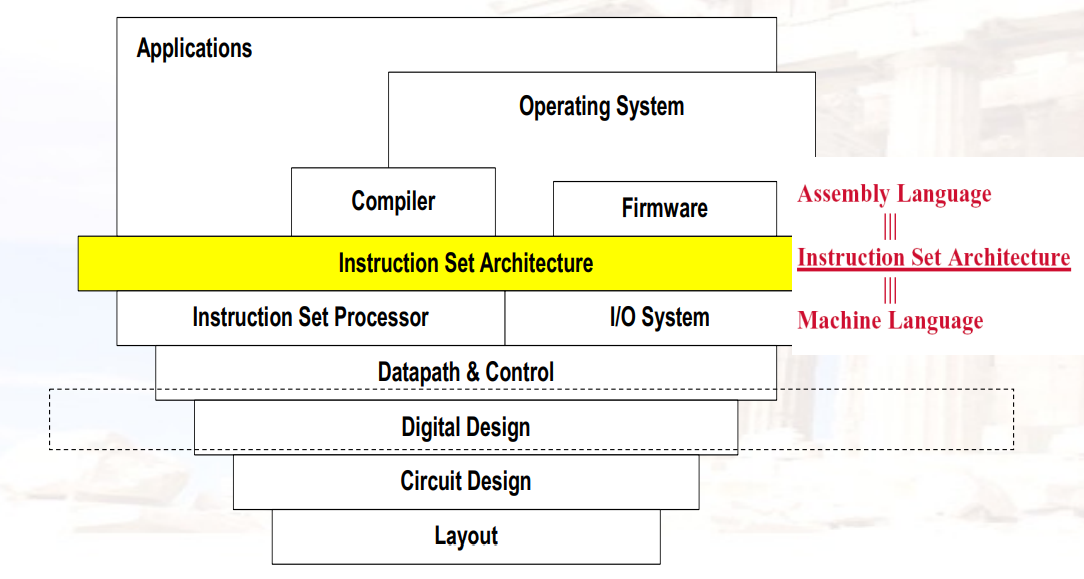
Computer Architecture包含了三个主要的方面
- ISA,七个维度如下:
- Class of ISA
- Memory addressing
- Addressing modes
- Types and sizes of operands
- Operations
- Control flow instructions
- Encoding an ISA
- Microarchitecture:也叫Computer organization,是对系统的较低层次、更具体和更详细的描述,涉及系统的组成部分如何互连以及它们如何互操作以实现ISA
- System Design:包括计算系统中所有其他硬件组件的系统设计,如:逻辑实现
- ISA,七个维度如下:
处理器芯片的发展趋势
- 工艺、主频遇到瓶颈后,开始通过增加核数的方式来提升性能;
- 芯片的物理尺寸有限制,不能无限制的增加;
- ARM的众核横向扩展空间优势明显
SoC:System of Chips,芯片上的系统
CPU发展的三个挑战
- ILP:指令集之间的并行
- Memory:内存到CPU之间的时间开销
- Power:功耗
Bandwidth和Latency
- Bandwidth带宽/throughput吞吐率:单位时间内能够完成的任务
- Latency延迟/response time反应时间:完成单个任务所需的时间
- 有时候不一定Latency降低,Bandwidth就提高了
降低能耗:
- 休眠:在没有core运行时就休眠
- 动态调压:降低电压/频率
- 频率:开关晶体管的次数
- 为典型的情况做设计
- 超频Overlocking
- 尽快将所有的任务完成Race-to-halt
功耗
- 动态功耗Dynamic power:由于开关晶体管导致的功耗
- \(Power_{dynamic}=\frac{1}{2}*电容负载*电压^2\)
- \(Energy_{dynamic}=电容负载*电压^2\)
- 静态功耗Static power:即便不导通,晶体管也会有电压泄露
- \(Power_{dynamic}=静态电流*电压\)
- 一般来说,电压降低10%,功率降低30%
- 动态功耗Dynamic power:由于开关晶体管导致的功耗
1.2 Dependability(需要计算)
Availability:可用性,一定时间内有多长时间是可以正常工作的
- 也是某个时间,不可用的几率
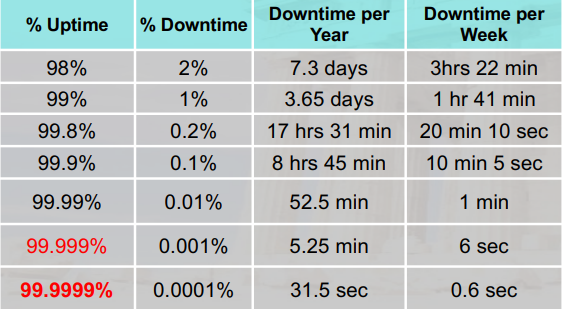
Reliability:可靠性
- 指一个人或系统在日常环境以及敌对或意外环境中执行和维护其功能的能力
- IEEE将其定义为:“某个系统或组件在规定条件下,在规定时间内执行其所需功能的能力。”
Maintainability:可维护性
Dependability:可信性,所提供服务的质量,以便可以合理地依赖此服务
- MTTF:Mean Time To Failure,从开始工作到失效的平均时间
- MTTR:Mean Time To Repair,从失效到再次重新工作的平均时间
- MTBF:Mean Time Between
Failure,两次失效之间的平均时间
- MTBF = MTTF + MTTR
- FIT:Failure In Time,失败出现的机会
- FIT = 1 / MTTF
- Module Availability:模块可用的时间
- \(\frac{MTTF}{MTTF+MTTR}=\frac{MTTF}{MTBF}\)
已知每个部分的MTTF,求整个系统的MTTF:
- 求出各个部分的FITi = 1 / MTTFi
- 求出整个系统的FIT = FIT1+FIT2+…+FITn
- 求出整个系统的MTTF = 1 / FIT

应对failure:Redundancy冗余
- Time Redundancy:重复做一遍
- Resource Redundancy:用另一个部件替换坏掉的部件
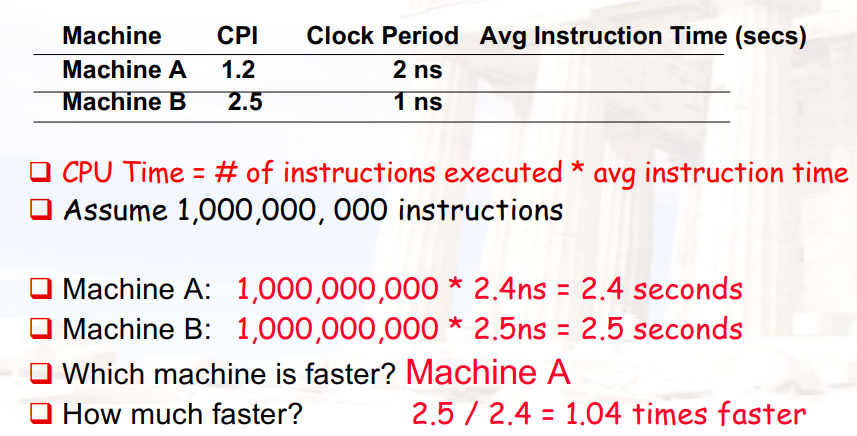
1.3 测量/报告/总结 性能(需要计算)
比较两个计算机的性能
- Execution time:计算的速度
- Throught:吞吐率
- MIPS:millions of instructions per second每秒多少百万条指令
- 使用Benchmark进行测量
Wall-clock Time:一个程序从开始到结束所需时间(包含中间停顿所需的时间)
CPU Time:一个程序实际在CPU上所需的时间
- User Time:在user mode下使用的时间
- System Time:在operating system中使用的时间
MIPS:每秒钟计算的多少百万条指令
- MIPS = benchmark中的指令数 / (benchmark运行的时间 * 1,000,000)
- 指令集中的每条指令,权重不一定一样,且已经包含在了benchmark中
Benchmark的种类
- Real applications:一个真实的程序
- Modified (or scripted) applications:对程序进行一些修改,关注于其中的一些点
- Kernels:程序的最主要的部分
- Toy:只关注一些部分
- Synthetic:创建来表示程序的某些方面
计算A比B快多少:A所需的时间 / B所需的时间,得到一个>1的数字
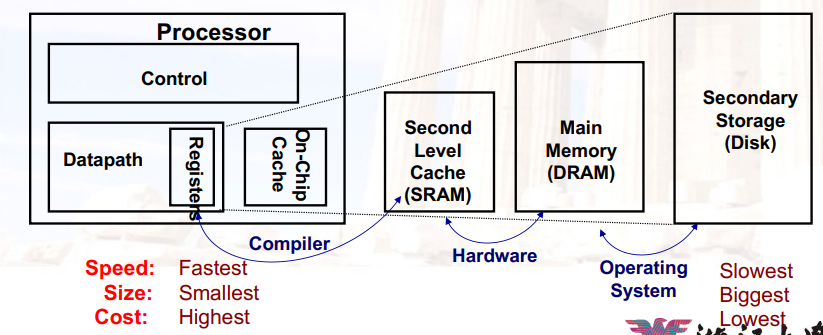
Chapter 3:Memory hierarchy
3.1 Introduction
DRAM:Dynamic Random Access Memory
- 高密度、低功耗、便宜、速度慢
- 不能放在CPU里面,因为有电容,有充放电(交流信号 ),会影响CPU的计算
- Dynamic动态:需要定期“刷新”,刷新时不能进行读写
SRAM:Static Random Access Memory
- 低密度、高功率、昂贵、快速
- 唯一可以放在CPU里面的,因为没有电容
- Static静态:内容将“永远”保存(直到失去动力)
3.2 Cache
3.2.1 组相联计算
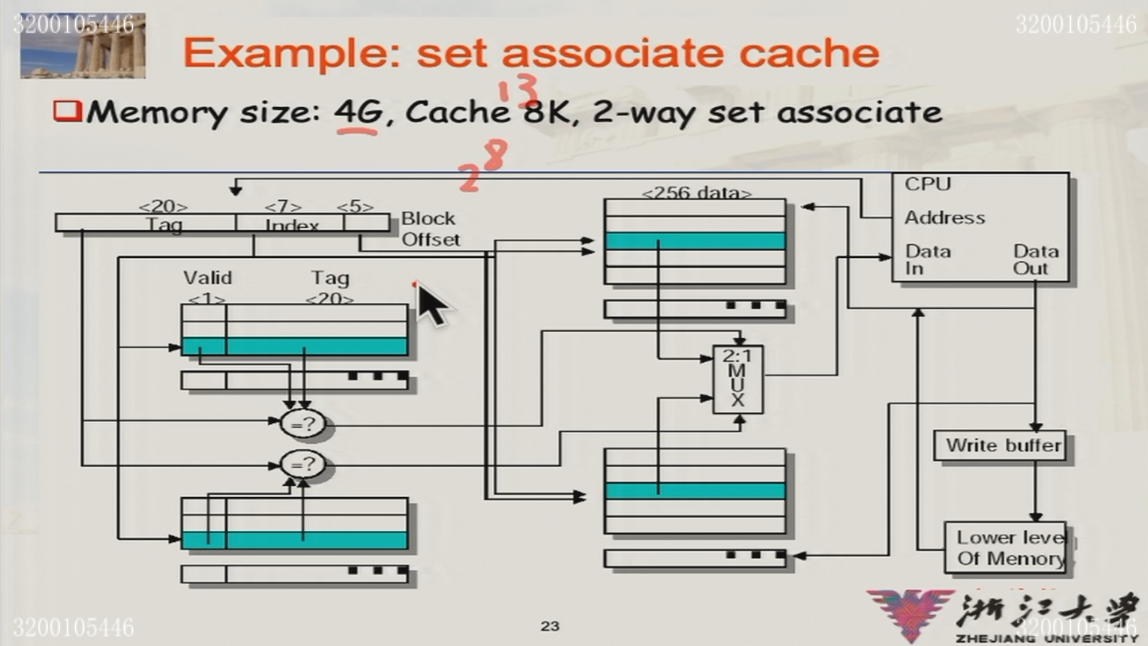
- 4G:地址为32位
- Cache 8K,Block-offset为5位:共28个block
- 2-way组相联:index= 8-1=7位
3.2.2 block的替换策略
只有在全关联/组关联的时候,会有替换策略
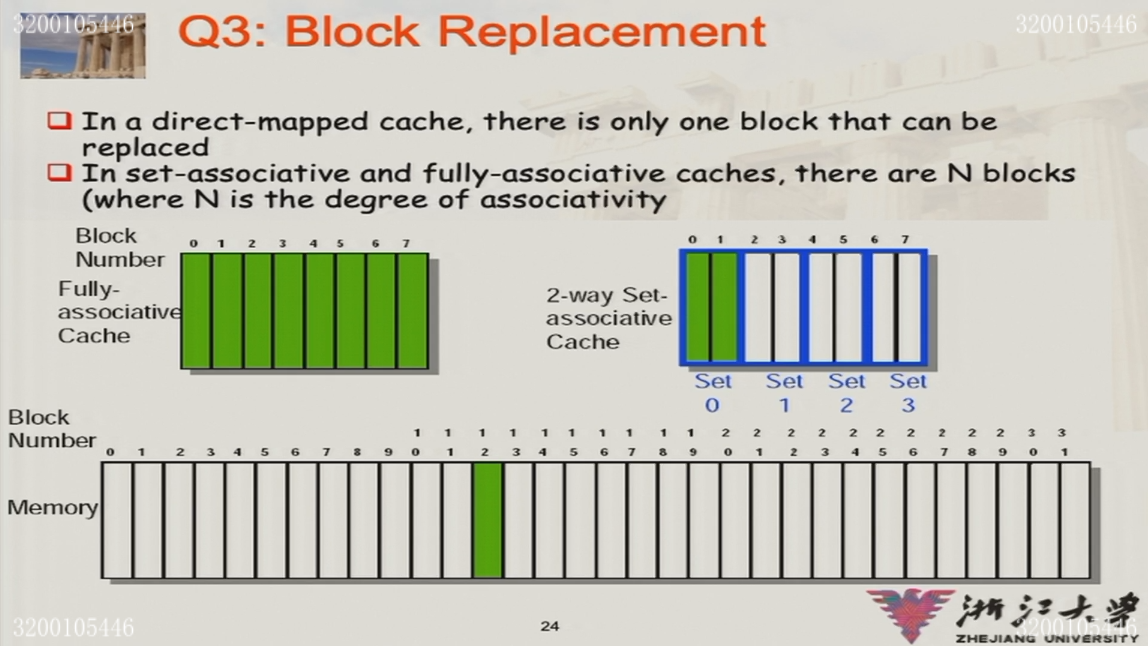
Random replacement:随机选择一个块替换
- 随机数的硬件实现:
- 设计一个专门的组件
- 用一根电线什么也不接,然后读取这个引脚的电压,理论上是白噪声,电压是随机分布的
- 随机数的硬件实现:
LRU:选择最近最少访问的块替换
- 伪LRU算法(体系不考察LRU)

FIFO:选择第一个进入cache的块替换
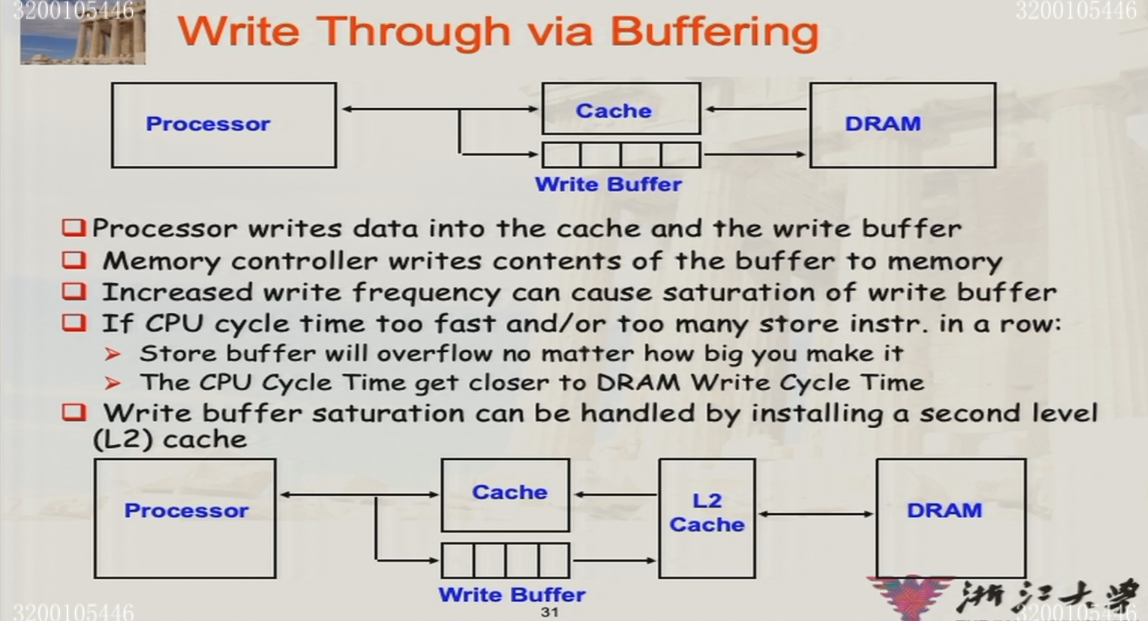
3.2.3 写策略
- write-through:同时修改cache和memory
- cache的控制位:valid bit
- 始终保证memory中的数据是最新的
- 通常会写入buffer,从而让cache不用等待memory
- write-back:只修改cache,block被替换时写入memory
- cache的控制位:valid bit,dirty bit
- 带宽更小,因为重复访问时不需要写memory
选择write-through时,会有两种更新策略
- write-stall:CPU等待write-through完成
- write-buffer:写入buffer,CPU不用等待write-through完成
- buffer的大小不是无限的,buffer满时需要stall
miss时的写策略:(读策略肯定是将block放入cache)
- write-allocate:将对应的block放入cache(通常是write-back对应的策略,write-through也可以用)
- write-around:直接写memory,不取对应的cache(通常是write-through对应的策略)

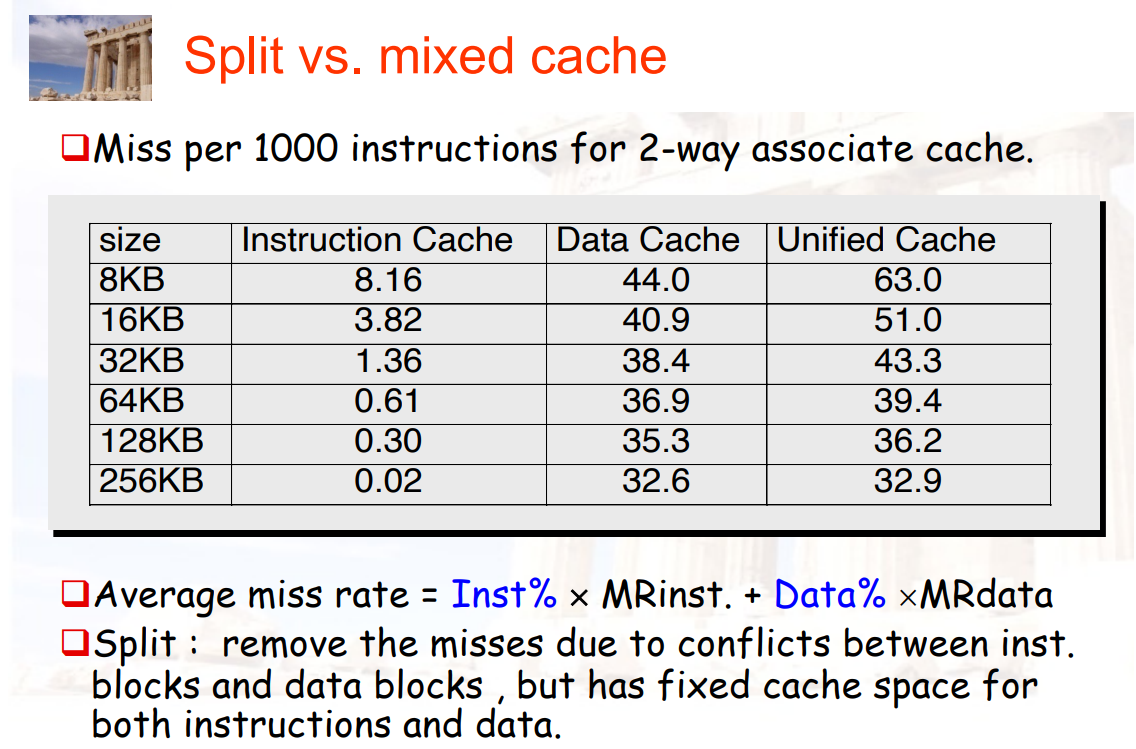
3.2.4 数据和指令的cache是否分离
- average miss rate = 指令占比% × 指令的miss rate + 数据占比% × 数据的miss rate
3.2.5 Supervisor cache / User cache
- Supervisor 和 User 所要访问的空间肯定有很大的区别,可以将它们两个分别赋予一个cache
- 指令cache
- Supervisor / User Space Bit
- 1:Supervisor access only
- 0:Supervisor / User access
3.2.6 Cache Performance (计算)
3.2.6.1 CPU Time
- CPU时间 = (CPU时钟周期 + Memory-Stall周期) × 一个周期的时间
- Memory-Stall周期 = 指令数量IC × 平均每条指令访问内存的次数 × Miss-Rate × Miss惩罚

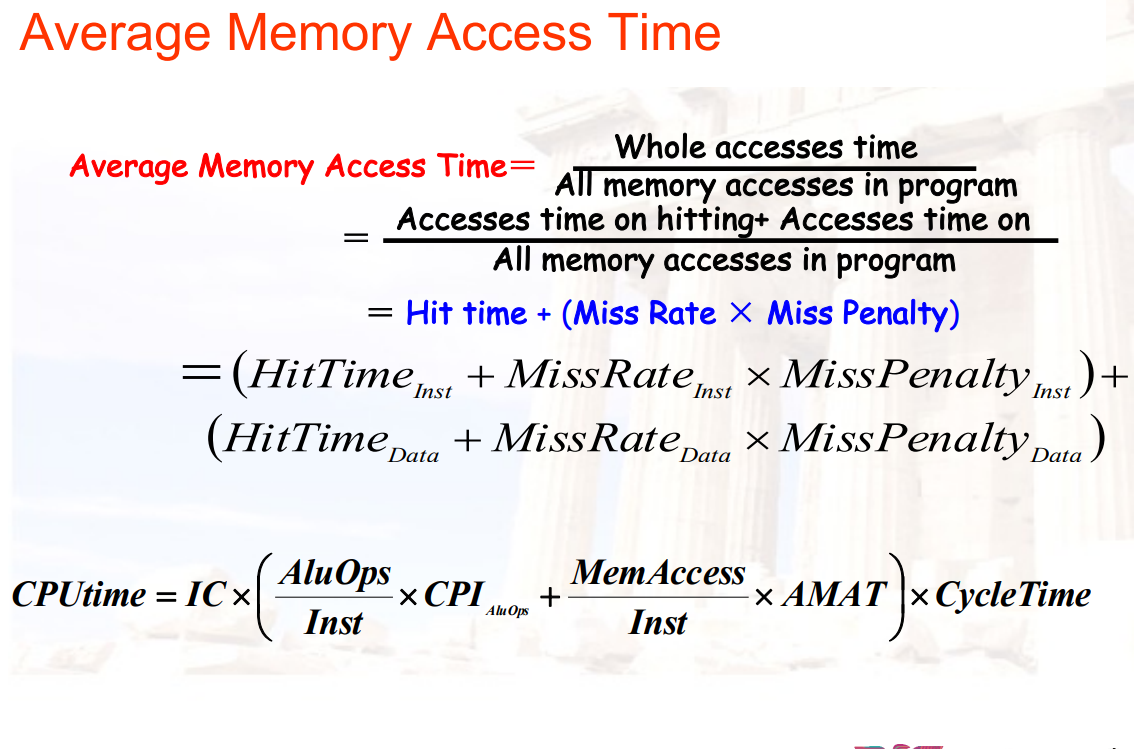
3.2.6.2 AMAT:平均内存访问时间
AMAT = 命中时间 + Miss率 × Miss惩罚
= (命中时间指令 + Miss率指令 × Miss惩罚指令) + 命中时间数据 + Miss率数据 × Miss惩罚数据)
3.2.6.3 Cache性能的测试指标
- Miss Rate
- 与硬件的速度无关
- Average Memory Access Time
- 是性能的间接表现
- CPU time
3.2.6.4 示例
例1:

例2:
- 1 + 0.5:每条指令在取指令的时候都可能miss(1) + 这些指令中的50%是访问数据,也会miss(0.5)


例3:

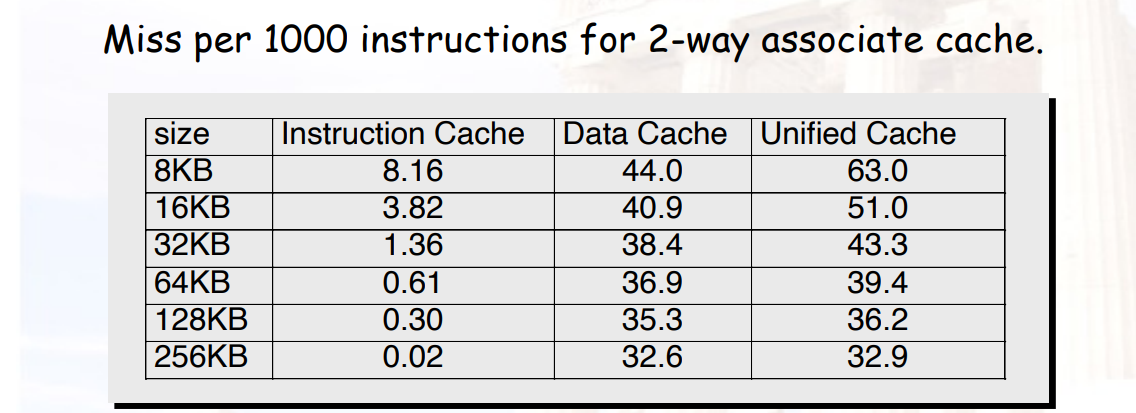



例4:



例5:




Chapter 4:How to improve memory performance
\[ AMAT = hit\_time + miss\_rate × miss\_penalty \]
- 降低hit time
- 更小的一级cache,路径预测
- 避免地址转换,Trace cache
- 增加bandwidth
- 流水线cache,multibanked cache,non-blocking caches
- 降低miss penalty
- 多级cache
- 读miss优先于写miss
- Critical word first,merging write buffers,victim caches
- 降低miss rate
- 更大的block size,更大的cache size,更高的关联度(2路组相联 => 4路组相联)
- 编译器优化
- 通过并行,降低miss_penalty 或 miss_rate
- 硬件/编译器预取
4.1 降低hit time
4.1.1 小而简单的cache
使用小型,直接映射cache
- 实现缓存所需的硬件越少,通过硬件的关键路径就越短
- 无论是读还是写,直接映射都比组关联快
- 将cache安装进CPU芯片上,也可以提高访问速度
一级cache和关联度对性能的影响
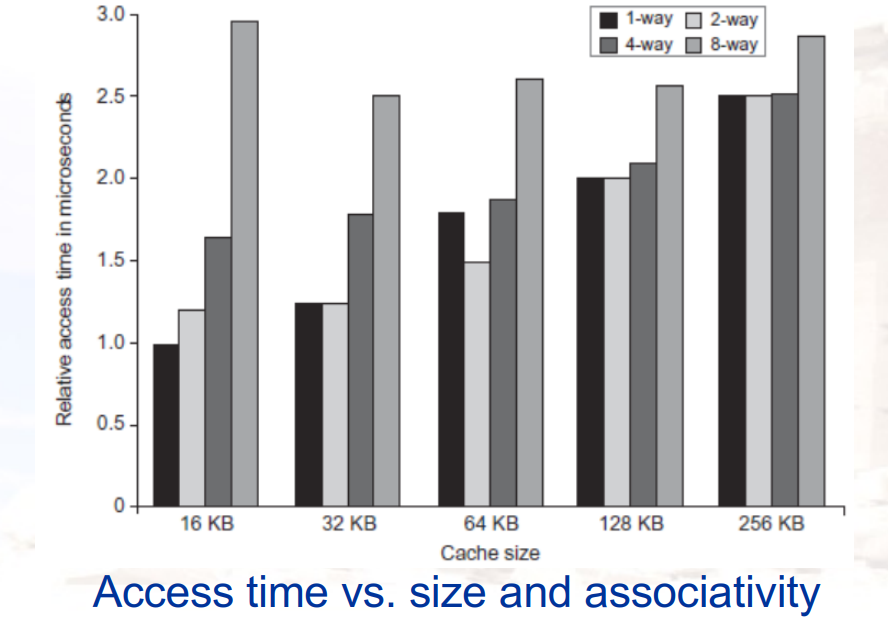
4.1.2 Way Prediction
- 额外的位保存在缓存中以预测下一次缓存访问的方式或块
- 如果预测是正确的,指令缓存延迟是1个时钟周期
- 如果不是,它尝试另一个块,改变方式预测,并有一个额外的1个时钟周期的延迟
- 使用SPEC95进行仿真表明,集预测精度超过85%,因此预测方式节省了流水线阶段85%以上的指令读取
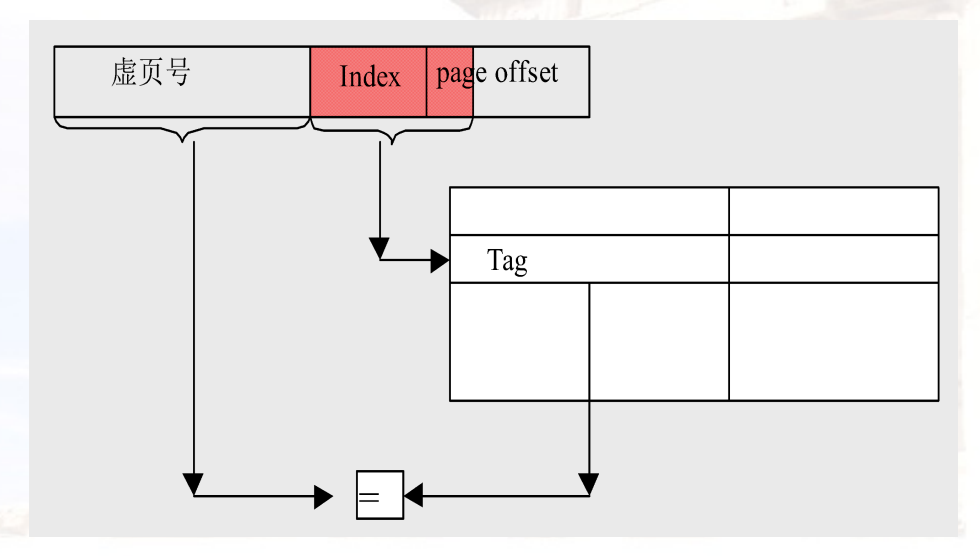
4.1.3 在cache上做索引时避免Address Translation
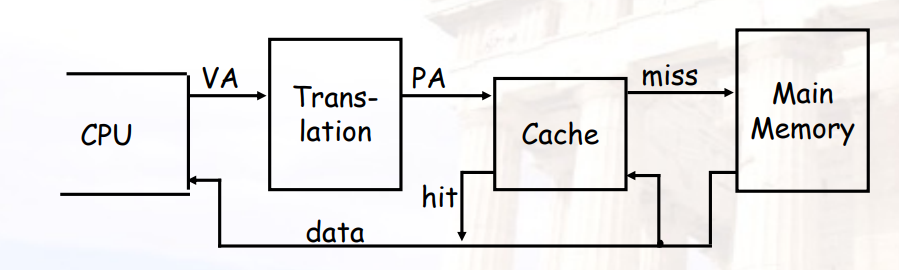
- 每个进程都有一个页表
- 页表是内存中的一个巨大的数据结构
- 每次load/store/instruction_fetch都需要2次内存访问
- 解决方法:
- 方法1:如果cache中的index+offset均在页表中的page-offset中,那么可以先将页表中的page-offset送入cache进行搜索,然后再将MMU翻译出的tag送入cache进行比对
- 方法2:cache中的内容可以是虚地址,但是换进程/进内核的时候需要清空cache
- 方法3:对页表建立一个cache
4.1.3.1 TLB:Translation Lookat Buffer

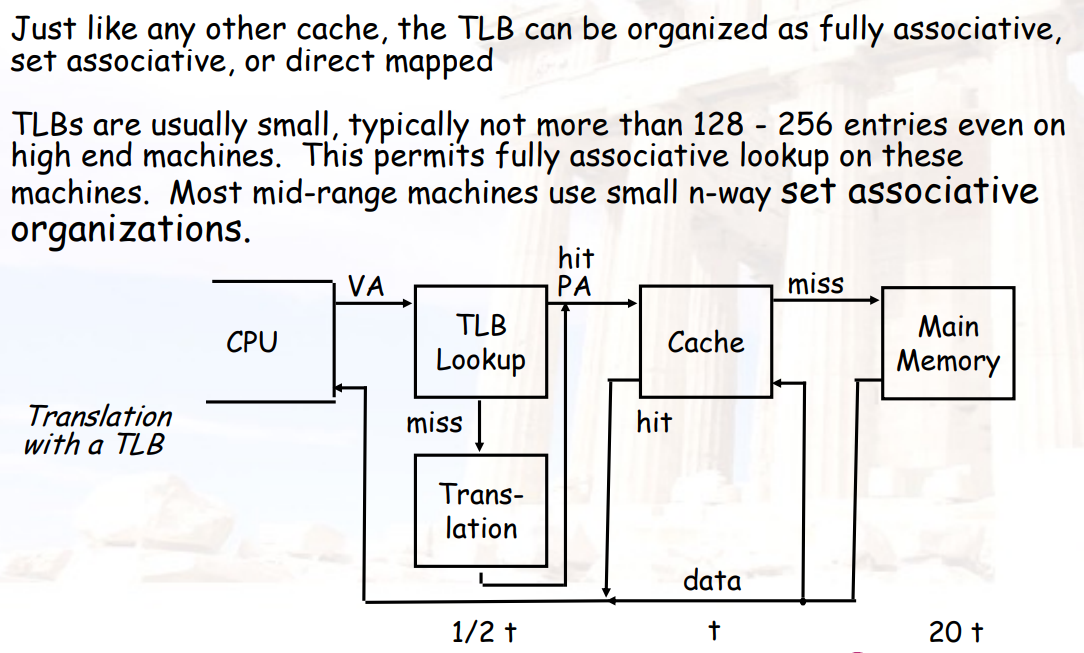
- 实际上就是将页表放入cache
- TLB的大小通常是128~256个entry,通常使用全相联
Fast hits by Avoiding Address Translation
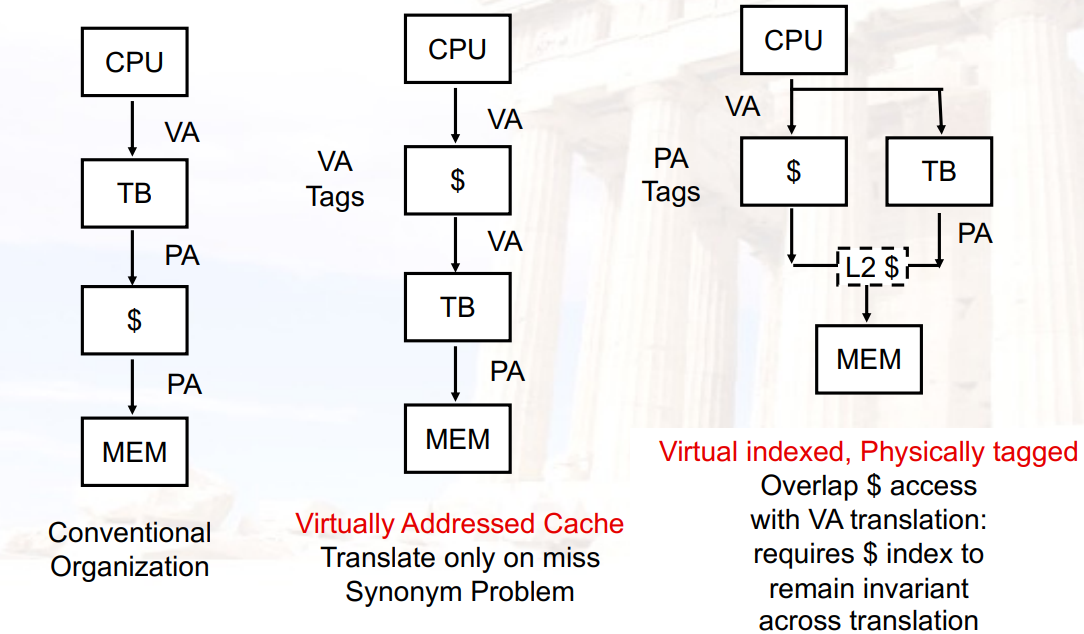
4.1.3.2 Virtual Cache
- cache中的内容可以是虚地址
- 但是换进程/进内核的时候需要清空cache,因为不同的进程使用的虚页号可能相同,但对应的物理地址是不同的地址
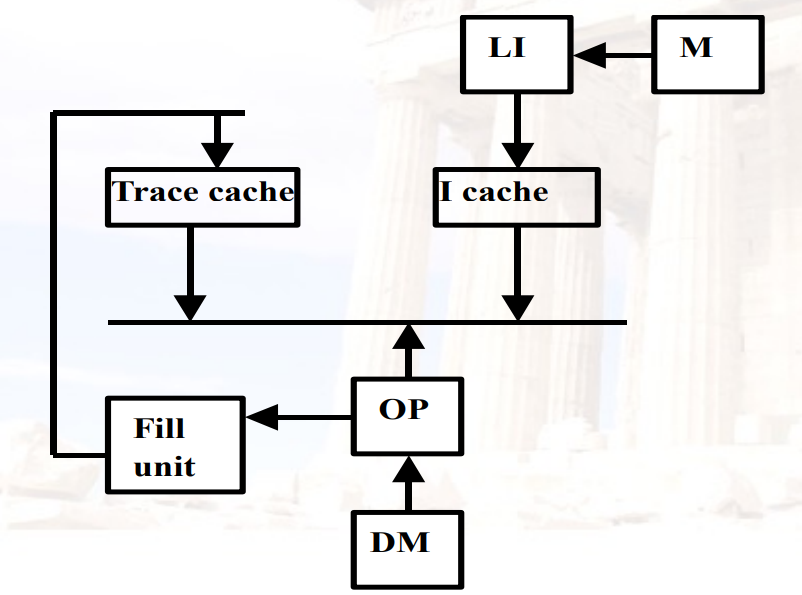
4.1.4 Trace Caches
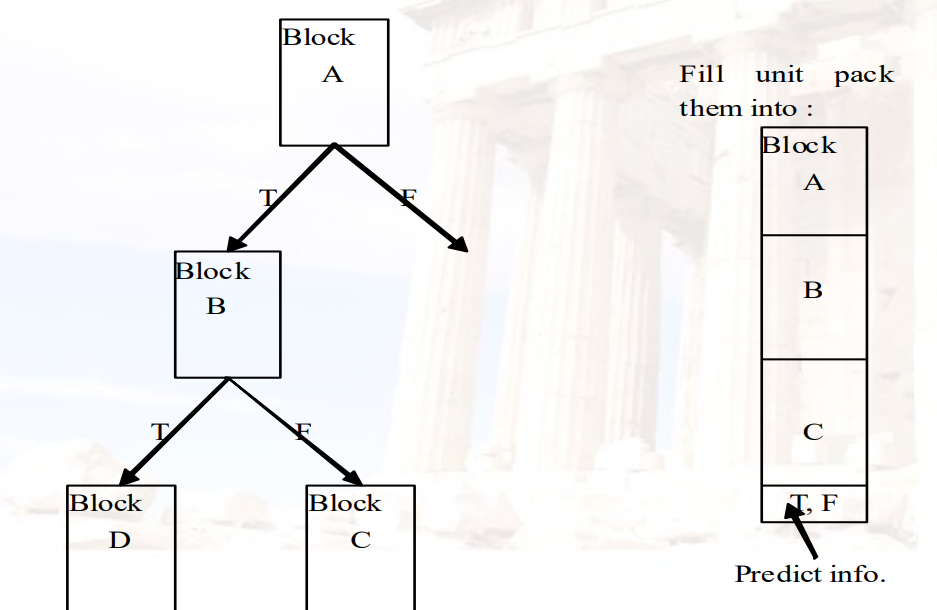
找到一个动态序列的指令,序列包含采取分支加载到缓存块
由CPU而不是内存布局决定block的边界
- 例如有一个循环跨越了两个block,可以将这个循环访问到的数据放到trace cache中的一个block
需要复杂的地址映射机制
使用trace cache后,如果每个循环有N个指令
- 没有 I-cache miss
- 没有 prediction miss
- 没有 packet breaks
Trace:dynamic instruction sequence
- 当指令(操作)退出管道时,将指令段打包到trace中,并将它们存储在trace cache中,包括分支指令
- 虽然分支指令可能会去不同的目标,但大多数情况下,下一个操作顺序将与上一个顺序相同(locality)
优点:引入一个额外的cache,可以突破block的边界
Trace in CPU:
Instruction segment:
4.2 增加bandwidth
4.2.1 Pipelined Cache
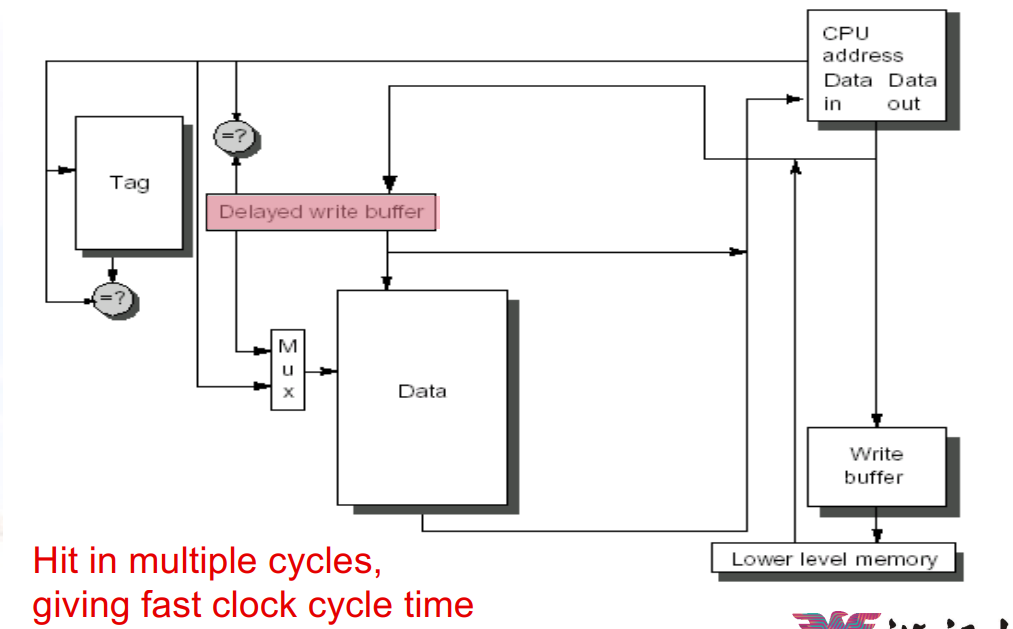
4.2.2 Nonblocking Caches
- 一个Nonblocking(Lookup-free) Caches,允许cache在处理read
miss时继续提供hit
- “Hit under miss” , “Hit under multiple miss”
- 复杂的cache甚至可能有多个未执行的miss(miss under miss)
- Nonblocking与乱序执行相结合,可以让CPU在数据cache
miss后继续执行之后的指令
- 之后的指令与当前指令不能有依赖关系

4.2.3 Multibanked Caches
- 将cache分成几个独立的bank,它们可以同时被访问
- 可以让多条指令同时进cache,但是WB阶段还是要排队
- 需要编译器的支持,实现对内存的交错访问
4.3 降低miss penalty
4.3.1 Multilevel Caches
- 一级cache较小,二级cache较大
- 如果一级cache miss,二级cache hit,此时会降低miss penalty
- AMAT = Hit_TimeL1 + Miss_RateL1 × (Hit_TimeL2 + Miss_RateL2 × Miss_PenaltyL2)
- 两个概念:
- Local miss rate:当前cache miss的次数 / 访问当前cache的指令数
- Global miss rate:当前cache miss的次数 / 总指令数

4.3.2 Critical Word First & Early Restart
不要等到加载满块后才重新启动CPU:
- Critical Word First:一旦发生miss,立即将请求的word从内存中取出并发送给CPU,让CPU继续执行,之后再慢慢填充block。也叫wrapped fetch / requested word first
- Early restart:还是从内存中取出一个block,但是一旦当请求的word到达,就把它发送给CPU,让CPU继续执行
通常在block比较大的时候比较有用
示例:

4.3.3 Giving Priority to Read Misses over Writes
读miss优先于写miss执行

4.3.4 Merging write Buffer
- 用 multiword writes 替代 one word writes
- 在write-througe策略中:
- 当写入失败时,如果缓冲区包含其他修改的块,则可以检查地址,以查看这个新数据的地址是否与有效的写入缓冲区项的地址匹配
- 如果是,则将新数据与该条目合并
- 降低了同一个地址被多次写时的开销,也可以降低write buffer full的次数
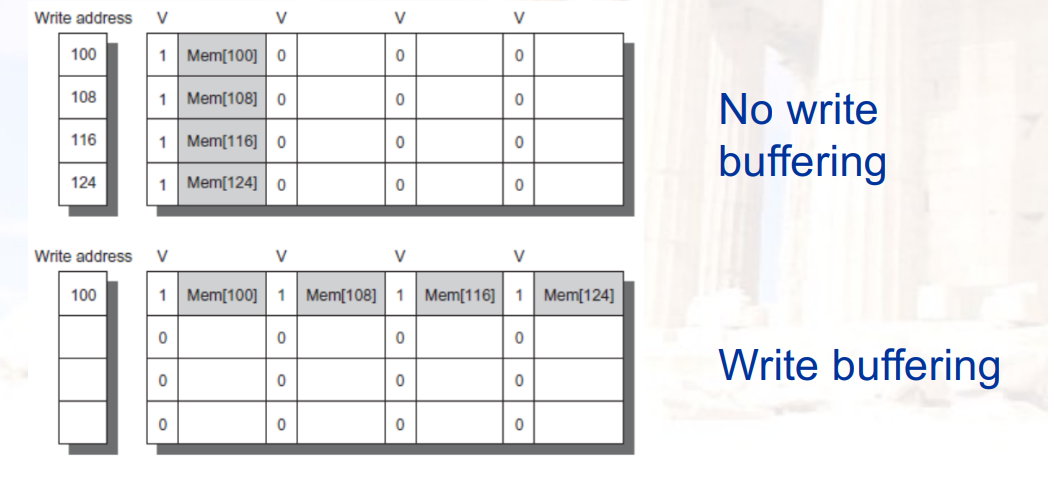
4.3.5 Victim Caches
- Victim Caches:是一个小的、全关联的cache
- 当cache中的块被替换时,可以将其先放入 Victim Caches
- 如果下一次的miss仍在该块中,可以直接将其拿回来 / 直接修改 Victim Caches 中的块
4.4 降低miss rate
miss的来源:
- Compulsory:由于cache为空而导致的miss
- Misses in even an Infinite Cache
- Capacity:由于cache容量已满而导致的miss
- Misses in Fully Associative Size X Cache
- Conflict:由于当前block应当放到的cache中的位置已经有block而导致的miss
- Misses in N-way Associative, Size X Cache
- Coherence:由于cache一致性问题导致的miss
以下策略均在cache size不变的情况下讨论
4.4.1 更大的Block Size
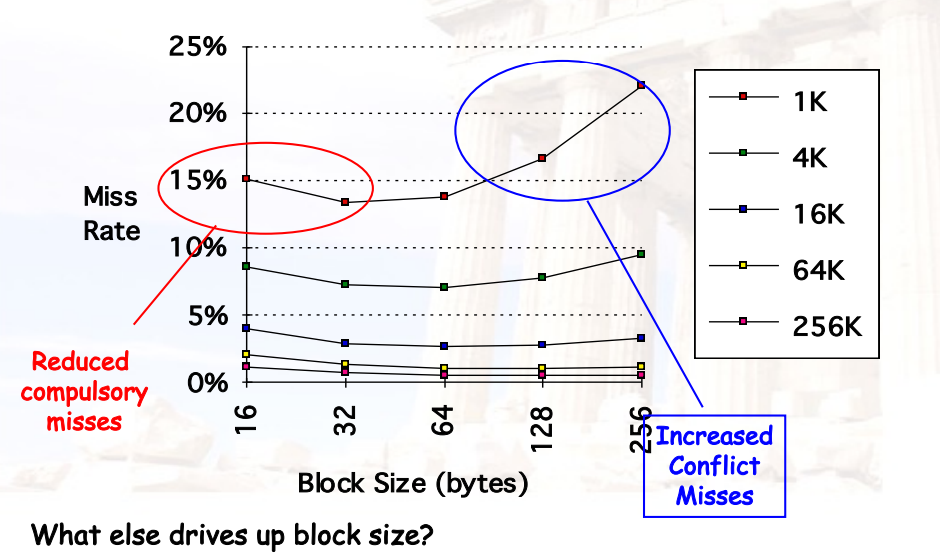
优点:
- 利用空间局部性降低了compulsory miss rate
缺点:
- 会提高miss penalty:因为每次miss需要取更多的数据
- 会提高conflict miss rate:因为cache中的块数降低了
- 会提高capacity miss rate:因为小的cache中包含的块数变少了,就更容易满了
权衡:
- 尽可能最小化 miss rate 和 miss penalty
- block size的选择取决于memory的延迟和带宽
示例:

4.4.2 更大的cache
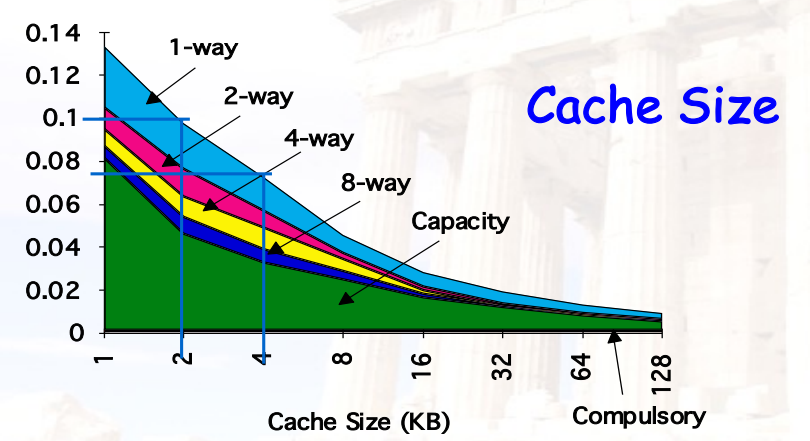
- thumb定律:2倍的size => miss rate降低25%
- 优点:
- 降低了capacity miss rate
- 缺点:
- 会提高hit time
- 会提高cost
- AMAT曲线是U型的
4.4.3 更高的Associativity
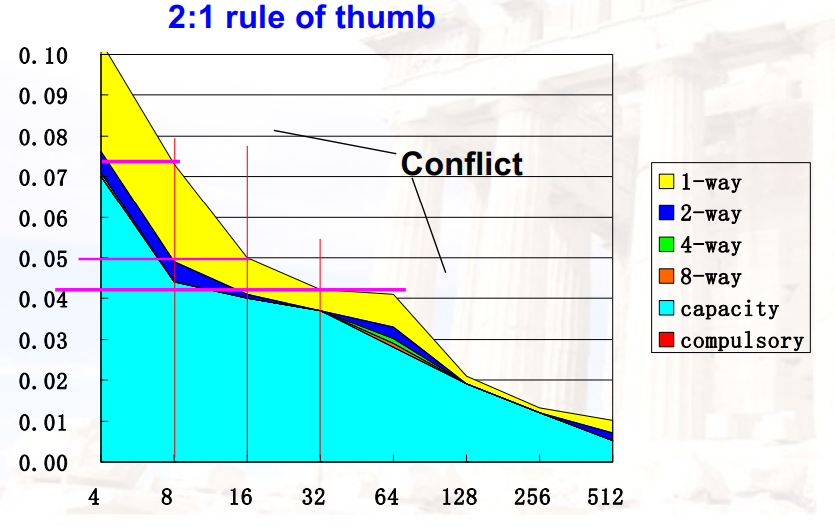
2:1 rule of thumb:
- 大小为N的直接映射的cache 与 大小为N/2的2-way组相联的cache 的miss rate相同
- 8-way组相联在降低miss rate方面,与提高8倍的cache size效果相同
优点:
- 降低了conflict miss rate
缺点:
- 会提高hit time
AMAT vs. Miss Rate
4.4.4 编译器优化
- 指令
- 重新排列内存中的程序,以减少冲突、未命中
- 分析冲突(使用他们开发的工具)
- 数据
- 合并数组Merging Arrays:通过单个数组提高空间局部性
- 循环交换Loop Interchange:修改循环访问数据的嵌套次序
- 循环融合Loop Fusion:将两个有相同循环、类似变量的循环合并为一个
- 阻塞Blocking:重复数据与向下移动整列或整行
4.4.4.1 Merging Arrays
- 将两个独立的数组合并到一起
- 这样使用的时候,可以在一个block中读取到
- 提高空间局部性

4.4.4.2 Loop Interchange
- 遍历矩阵时,修改遍历的顺序,保证内层循环在列上

4.4.4.3 Loop fusion
- 将两个独立的循环合并为一个
- 两个循环中使用了相同的变量,合并之后可以减少miss

4.4.4.4 Blocking optimized Matrix Multiplication
- 将大矩阵分为小矩阵,使得小矩阵的每一列可以存进cache中
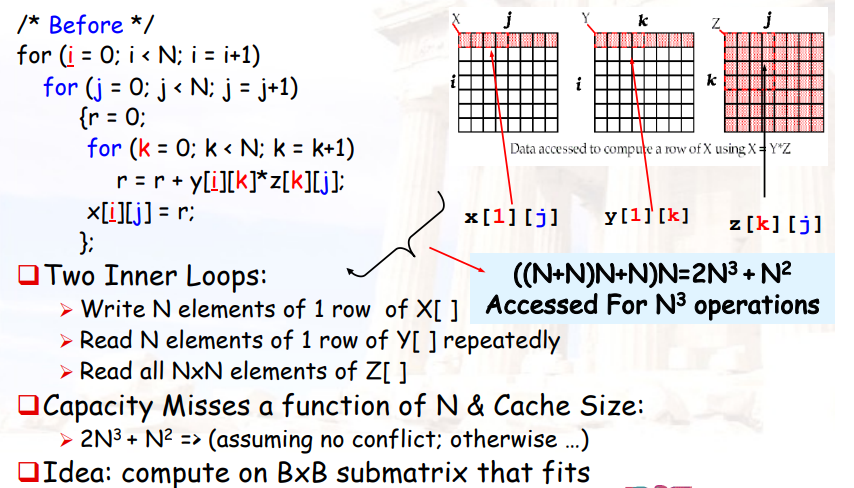
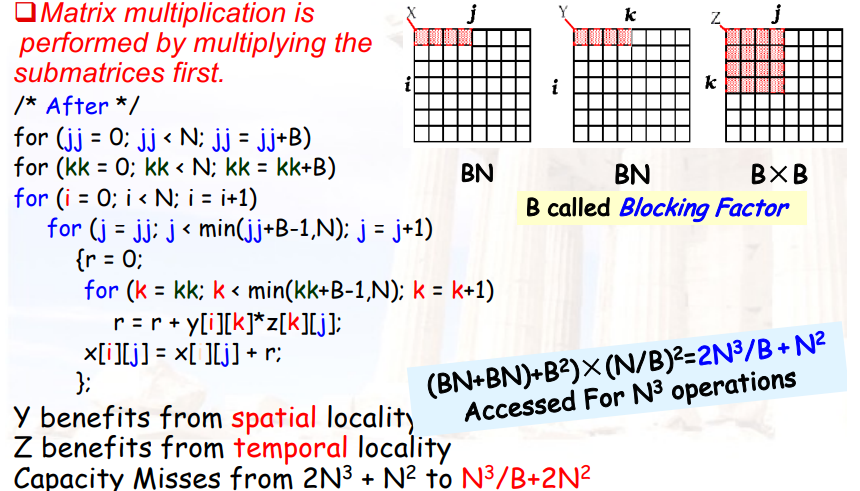
4.4.4.5 示例


4.5 硬件相关知识
4.5.1 DRAM & SRAM
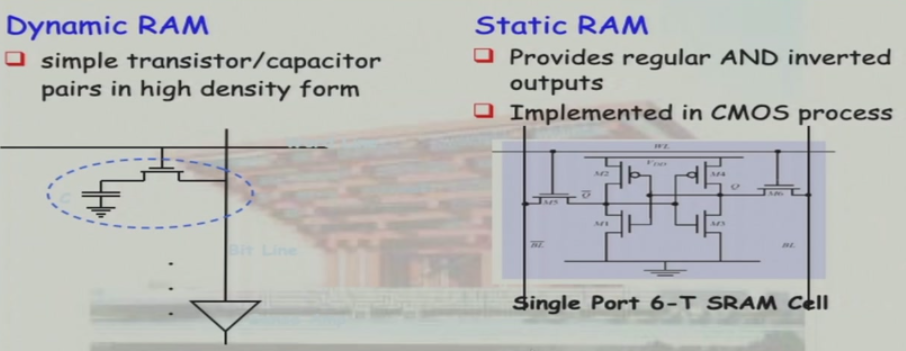
SRAM:
- 6个晶体管,表示1个bit
- 不需要刷新
DRAM:
1个电容,表示1个bit
电容越大,积累的电荷越多,自放电越慢,刷新的频率越低;但每一次写入的时间越长,单位面积存放的电容越少,存储容量越少
DRAM的周期性刷新,会产生一个大的交流信号,导致DRAM不能与CPU做在一起
通常会做成矩阵形式
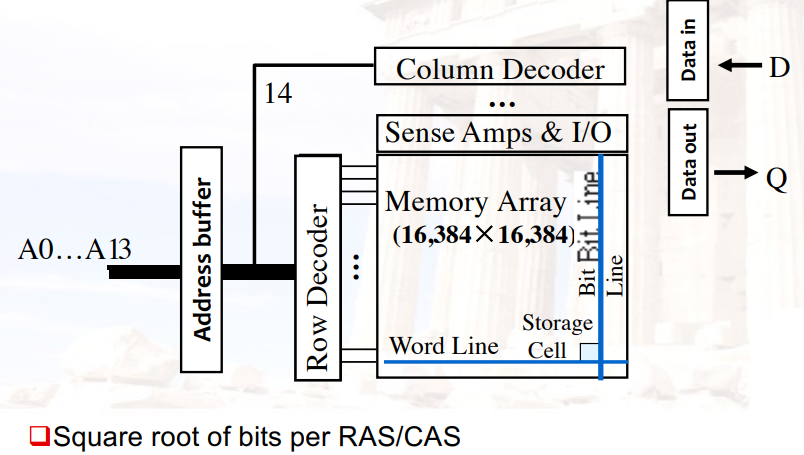
4.5.2 SDRAM:Synchronous DRAM
- 在DRAM的基础上增加了clock,达到同步效果
- 可以有burst mode,让关键字先写
4.5.3 DDR:Double data rate
- 在上升沿和下降沿各做依次写
4.5.4 flash
- flash在读上比DRAM慢
习题
选A:cost尽可能便宜,speed尽可能快

选B:两级cache时,一级cache不需要很大

选A
- B:I/O不仅指与人的交互,还有CPU与内存的交互
- C:I/O性能很重要

选C:直接映射时block conflict的概率最高

选D:当进程工作时,并不是程序访问的所有内容都会被放到主存。如果电脑有虚拟内存,一些内容会仍停留在磁盘。地址空间会被划分成固定大小的block,称为pages。任何时候,每一个page会停留在主存或磁盘中。

选A:
- Write through 与 Write back 对比,对虚拟内存没有影响
- full-associative map 与 其它映射方法 对比
- TLB cache 与 no cache 对比
- LRU replacement 与 其它替换策略 对比

选A

选B:
- 内存为256MB:28bit
- 4KB cache:212
- block size 32B:5bit
- 2-way associative:1bit
- index的长度:12-5-1=6bit

选B:把1个bank替换为多个banks,有哪些好处–提高了带宽

选D:
- AMAT = Hit Time + Miss Rate * Miss Penalty
- IC * CC * IPC
- 改进的程度 = Told / Tnew
- CPU Time = IC * CC * CPI
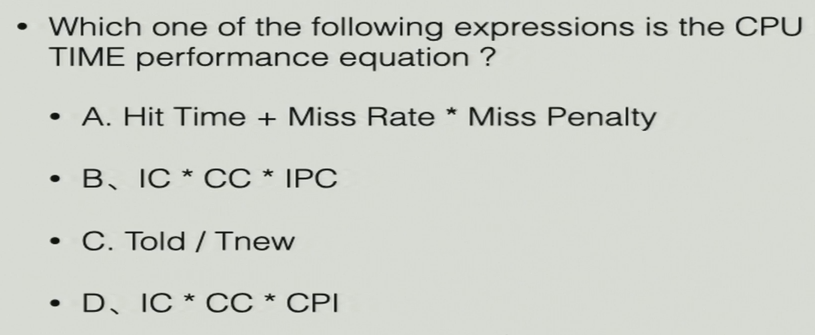
选B:当程序运行的时候,使用的内存地址为逻辑地址

选A:对于全关联来说,组关联的优点在于–tag更小,占用的芯片面积更少

选D:假设cache中有M个block,每K个block分为一个组,则它是一个K-way组关联

选A:增强了空间局部性--访问了x,x的附近也会被访问

- cache大小:64KB--216
- 每一行大小:128B--27
- 4-way组关联:22

选B:如果block size增大了,miss rate可能会降低,正确的表述为:在一定范围内,block size增大,miss rate降低

选D:二级cache的AMAT = Hit timeL1 + Miss rateL1 * (Hit timeL2 + Miss rateL2 * Miss penaltyL2)

在一个2-way组关联的cache中,假设cache有4个block,每个block有1word,每个set有2个block。对于指令
LOAD R1, 0x18,这次访问miss了,不需要replacement,新的block会放在Set 0 Block 0

memory的表现为:
- 送地址:4 clock
- 访问每个word:56 clock
- 传输数据:4 clock
假设一个block有4 word,一个word有8 byte,那么miss penalty为(4 + 56 + 4) × 4 = 256 clock,bandwidth为\(\frac{4 * 8}{256}=\frac{1}{8}\)

- miss rate = 50%
- 每次访问数组时,偶数次miss,然后装入2 word,从而奇数次hit
- AMAT = 8 + 50% * 70 = 43 ns
- CPI计算:
- 先用AMAT与频率换算成clock cycle
- 然后再计算平均每条指令需要的clock cycle

假设cache的其它参数(容量、关联性、block大小)都不变,对于下列三个问题:
- block size翻倍,block数量降低,index变小,tag变大,但不是翻倍的关系
- 直接映射的cache,容量翻倍,block数量翻倍,会降低conflict miss
- 直接映射的cache,容量翻倍,强制miss的次数倍增

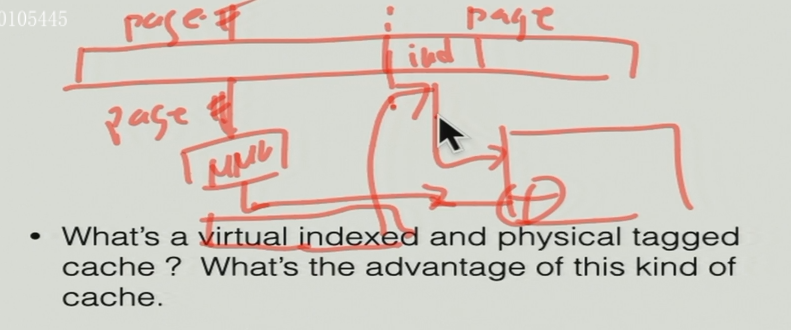
什么是virtual indexed和physical tagged cache?
- virtual indexed:index部分在page-offset中,因此不需要经过MMU翻译
- physical tagged:tag在page number中,需要经过MMU翻译
通过index在cache中找对应的block 与 MMU翻译page number并行进行,降低了时间消耗
假设一个cache使用write-back策略,被交换的block有20%的几率为dirty,cache miss的概率为10%。假设hit time为1 cycle,miss penalty为20 cycle,写回dirty block为20 cycle

第3问需要:图+语言描述


Chapter 5:Extend 2 Supporting M Coperation
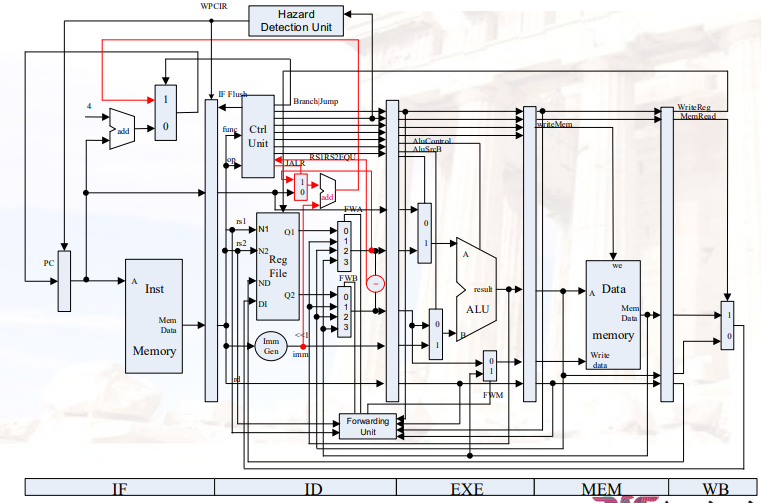
5.1 之前的流水线CPU
- ALU部分是一个门电路,只需要1个cycle就可以完成计算
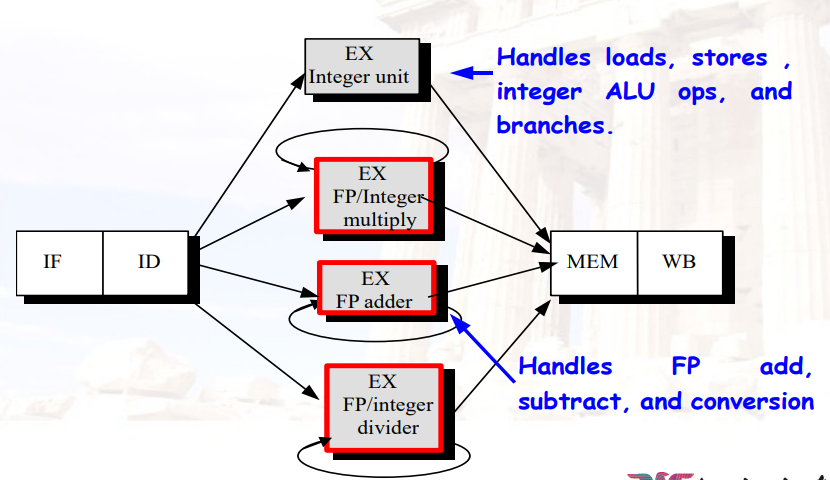
5.2 扩展流水线CPU,支持多周期运算
5.2.1 包含FP运算单元的5阶段流水线
5.2.2 两个指标:Latency和Initiation interval
- Latency:指令开始到结束所需的时间
- Initiation interval:指令开始后,再经过多长时间,可以重新开始

流水级
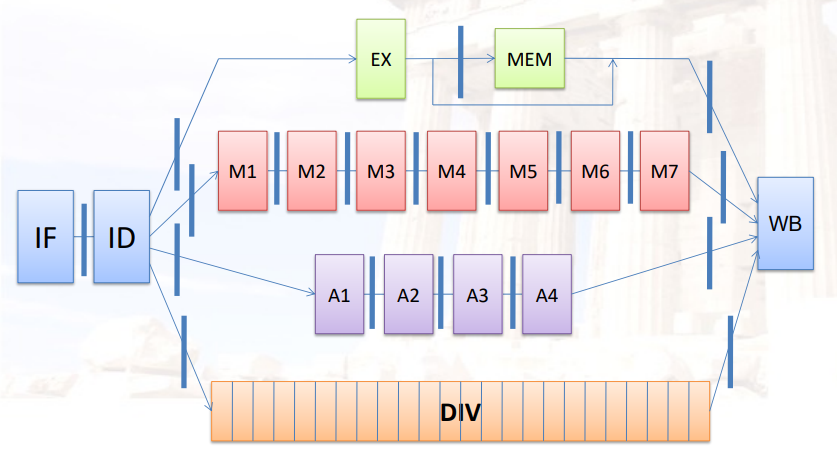
新的情况

5.2.3 按序发射,乱序完成
结构冲突:
WB阶段要写寄存器,ID阶段要读寄存器:double bump,上升沿写,下降沿读
IF和MEM都要访问存储器:将存储器分为指令存储器、数据存储器
同一个周期有多个WB
- 多端口读写,但成本太高
- 阻塞stall
- 在ID阶段stall:多增加一些判断逻辑,但是与原来的CPU是统一的
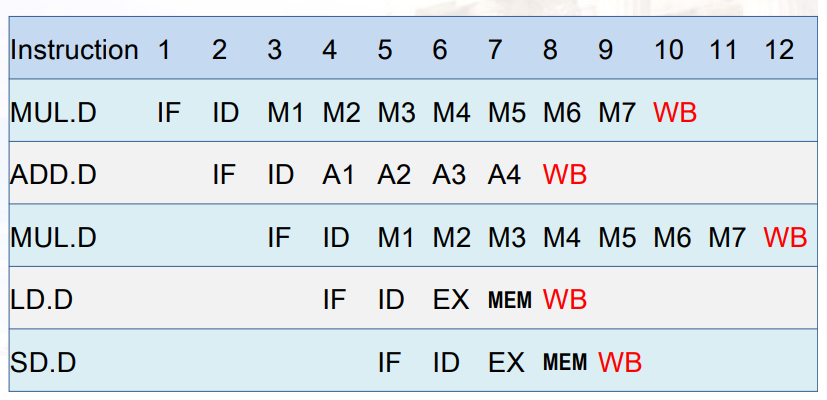
5.2.4 如何解决write port conflict

5.3 data hazard的种类

- RAW true dependence:A写Rx,B读Rx
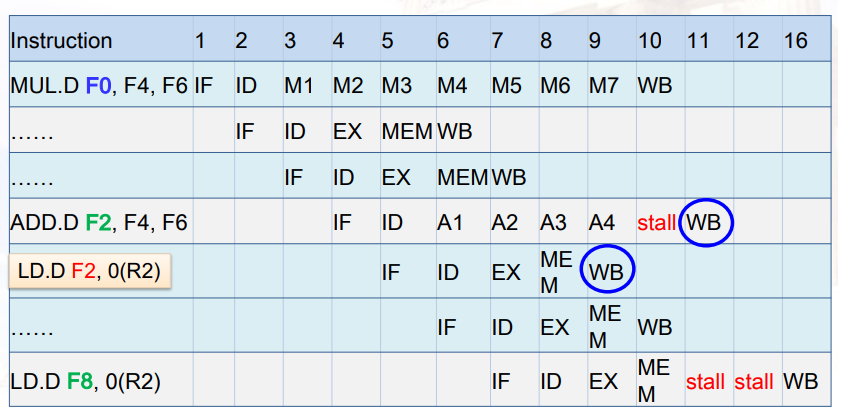
- WAW output dependence:A写Rx,B写Rx
- WAR anti-dependence:A读Rx,B写Rx
5.3.1 RAW依赖
- B在A写寄存器之前,就读了寄存器的值,可能导致B得到了一个旧的value
- 解决方法:forwarding
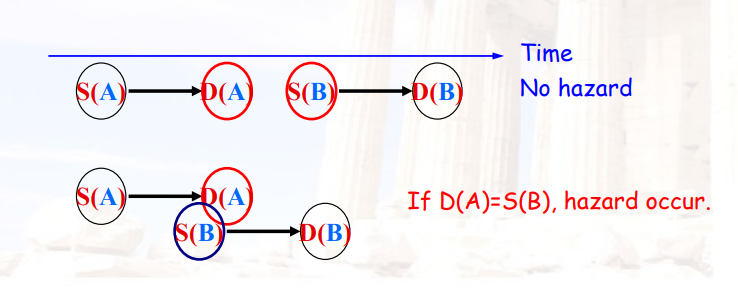
填写技巧:
- 一旦有一行stall,下面都是stall
- stall一定出现在ID的后面
- stall结束时,与上一行的stage之间一定有一个forward
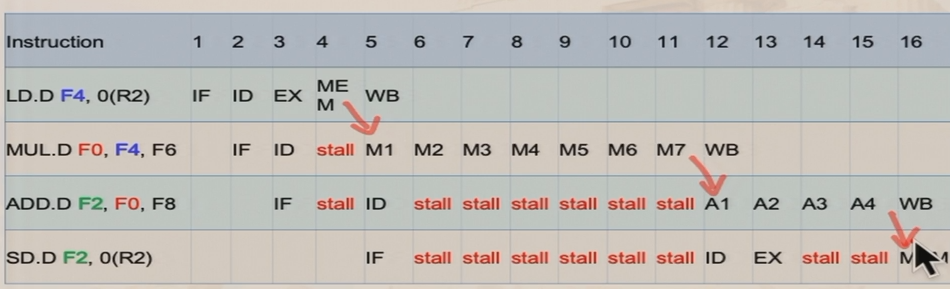
5.3.2 WAW依赖
- B在A写寄存器之前,就写了寄存器的值,可能导致A再次写寄存器,从而使寄存器保存了一个旧的value
- 解决方法:
- 阻塞A
- 直接扔掉A这条指令
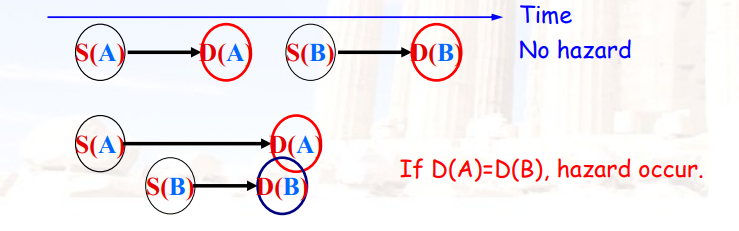
- 在WB之前检测是否需要stall
- 注意:整数指令,MEM=>WB;浮点指令,没有MEM阶段
5.3.3 WAR依赖
- B在A读寄存器之前,就写了寄存器的值,可能导致A读寄存器时,读到了一个新的不正确的value
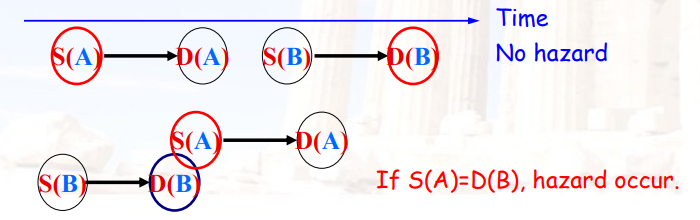
5.3.4 在ID阶段需要检查的内容
- 结构冲突
- 除法、寄存器写端口
- RAW冲突
- 如果有RAW冲突,则直接stall,直到
- 源寄存器不再是其它指令的目标寄存器
- 源寄存器不再是EX/MEM阶段load指令的目标寄存器
- 如果有RAW冲突,则直接stall,直到
- WAW冲突
- 如果有WAW冲突,则直接stall / cancel
Chpater 7:Dynamic Schedule--Scoreboard
统计数据表明,每5条指令,大概率就有一条跳转指令
7.1 指令级并行ILP
7.1.1 指令级并行的目标:最小化CPI
CPI = 理想CPI + 结构冲突导致的stall + 数据冲突导致的stall + 控制冲突导致的stall
- 理想CPI:实现某个算法的最优表现
- 结构冲突:HW不能支持这种指令的组合
- 数据冲突:当前指令依赖于之前指令的结果
- 控制冲突:由获取指令和决定控制流更改(分支和跳转)之间的延迟引起冲突
7.1.2 如何实现ILP
- 基于硬件的动态解决方案
- 基于编译优化的静态解决方案
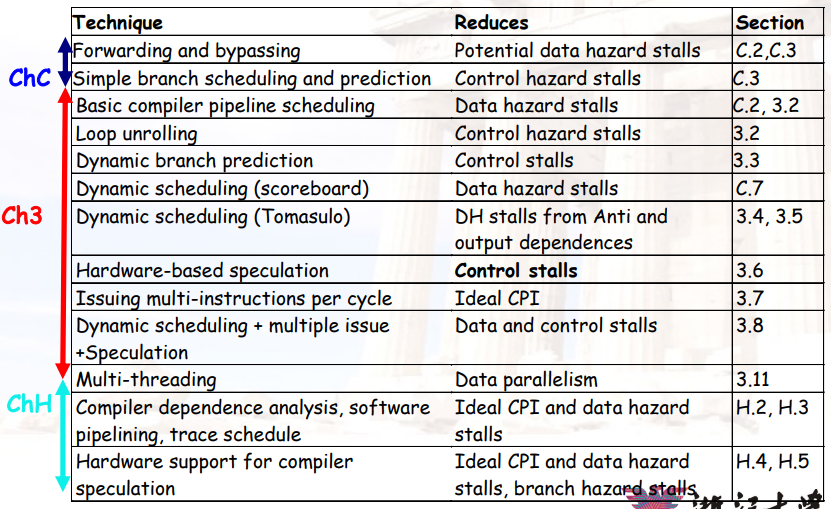
7.1.3 降低stall的方法
7.1.4 Instruction-Level Parallelism ILP
- 为了获得实质性的性能增强,我们必须跨多个基本块利用ILP
- 最简单:循环级并行性,利用循环迭代之间的并行性
- 使用
Vector(SIMD) &GPU Vector:如将多个寄存器与多个寄存器相加,结果保存到多个寄存器中–即同时处理多个寄存器- 如果不是
Vector,则通过分支预测进行动态ILP,或通过编译器展开循环进行静态ILP
- 使用
7.2 数据依赖
7.2.1 真实数据依赖:RAW 写后读

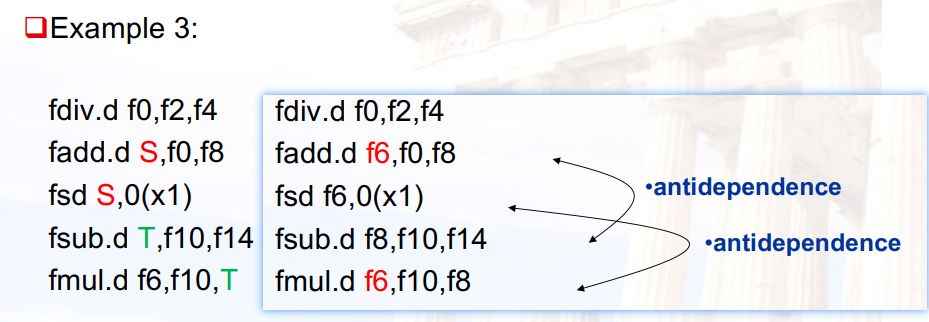
7.2.2 命名依赖
命名依赖:后面要写的寄存器,出现在了前面的源/目的寄存器中
- 可以通过寄存器重命名解决
- 编译器解决:更容易知道重命名到什么时候
- 硬件解决:需要考虑重命名到什么时候、CPU是否支持多个重命名同时存在
- 可以通过寄存器重命名解决
WAR 读后写--anti-dependence

WAW 写后写–output dependence

7.2.3 控制依赖
- 一般情况下,CPU的指令重排只在两个跳转之间进行,不会跨越跳转

Example 1:由于beq的存在,or指令可能与add有依赖,也可能与sub有依赖
Example 2:x4在skip后没有使用,sub指令可能可以被移动到beq之前

7.2.4 异常
- 指令重排不能影响异常的精确性

7.3 ILP:软件方法--静态调度
7.3.1 相关技术
- 实现ILP的基本编译器技术
- 循环展开
- 静态分支预测
- 静态多重问题:VLIW
- 实现ILP的高级编译器支持
- 软件流水线
- 全局代码调度
- 在编译时实现更高ILP的硬件支持
- 硬件为编译器提供更多指令级
- 条件或谓词指令
- 具有硬件支持的编译器推测
7.3.2 示例
指令没有重排:
指令重排后:



7.3.3 跳转指令的delay slot
- 跳转指令后面的一条指令,不论跳转是否成功,都可以执行完成
- 可以把一条指令(不论跳还是不跳都要执行)放在branch的后面,就可以充分利用branch的delay slot
- 一般是从跳转前拿一条指令放在后面,这条指令的执行不影响跳转的结果
7.4 ILP:硬件方法--动态调度
7.4.1 为什么需要动态调度

- 某个被stall的指令,与之前的指令没有依赖关系,但由于之前的指令stall了,它也不得不stall
- 可以通过动态调度,让后面的指令先执行
- 也成为指令重排
7.4.2 基本思路
- 将指令的ID阶段分为两个阶段
- Issue(发射):译码指令,判断是否有结构冲突
- Read Operands:等待,直到没有数据冲突,然后读寄存器,这里要有能够支持等待的存储单元
7.5 Scoreboard 计分板
- 当资源充足且无数据依赖性时,允许指令无序执行
- 顺序issue
- 乱序EXE
- 乱序completion
7.5.1 基本结构
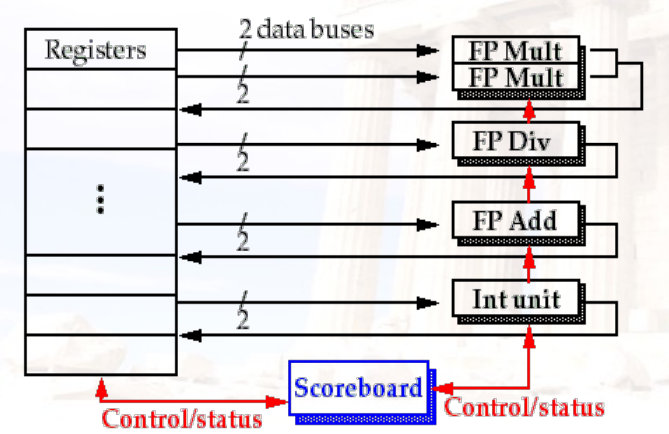
7.5.2 计分板的流水级
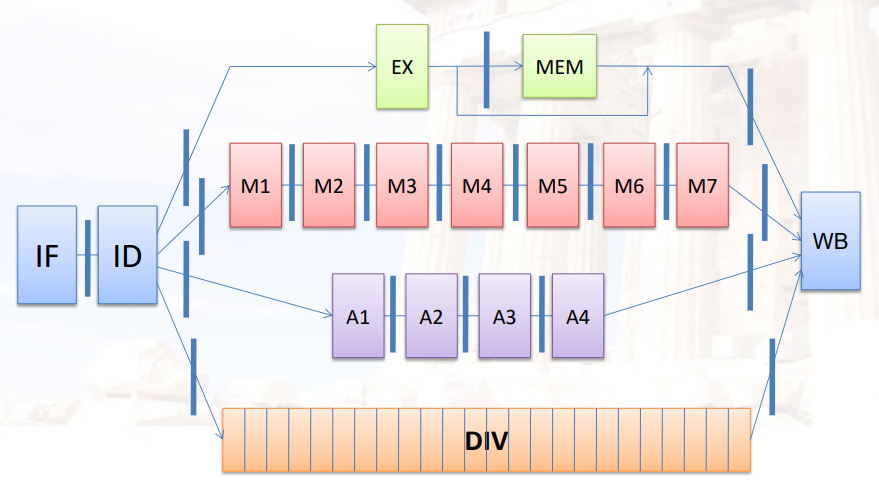
- 发出(Issue):在以下情况下发出指令
- 功能单元可用
- 没有其他活动指令具有相同的目标寄存器。
- 没有structural冲突、WAW冲突
- 读取操作数(RO)
- 两个操作数都可用,才能进入EX阶段,否则一直在RO阶段
- 这意味着以前发出但未完成的指令都没有将操作数作为目标
- 这可动态解决RAW冲突
- 执行(EX)
- 完成后通知记分板,以便重新使用功能单元
- 写入结果(WB)
- 记分板检查WAR冲突,如果有则stall
7.5.3 计分板算法
记分板全权负责指令发布和执行
- 创建相关性记录
- 决定何时获取操作数
- 决定何时开始执行
- 决定何时可以将结果写入寄存器
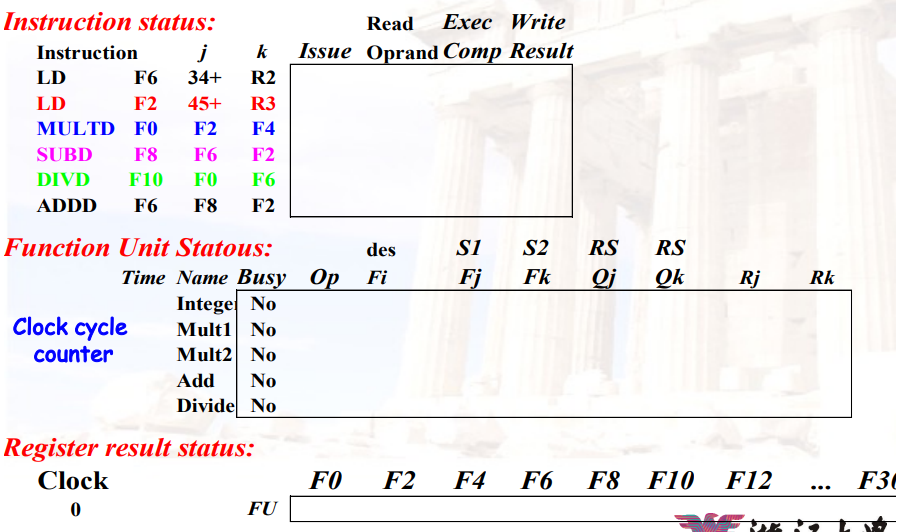
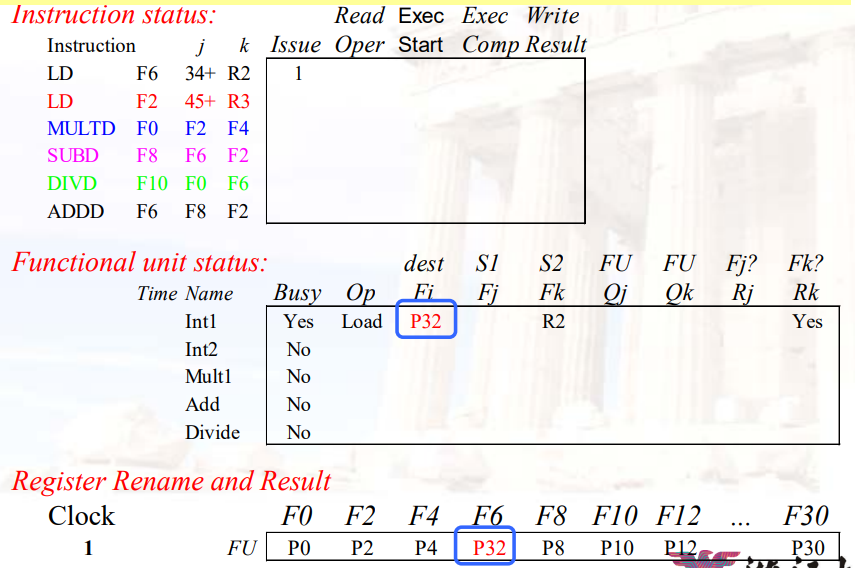
三种数据结构
Instruction status
- 指令在四个步骤中的哪一个
Functional unit status
状态 解释 Busy 表示当前单元是否被占用 Op 当前单元正在执行的指令(如add or subtract) Fi 目标寄存器 Fj, Fk 源寄存器 Qj, Qk 生成源寄存器Fj, Fk的功能单元 Rj, Rk 判断源寄存器Fj, Fk是否已经ready;当操作数被读取之后,设为NO Register result status
- 哪个功能单元将写入该寄存器
7.5.4 记分牌算法的具体运行方式
指令的等待:Function Unit,每个Function Unit最多有1条指令等待执行
- Issue:
- 如果对应功能部件被占用,则stall:防止结构冲突
- 计算完成后,更新记分牌
Function Unit Status:Busy:设置为YesOp:设置为对应的操作Fi:设置为目标寄存器Fj,Fk:设置为源寄存器Qj,Qk:如果源寄存器被占用,则设置为对应的功能部件Rj,Rk:如果源寄存器未被占用,则为Yes;否则为No
Register Result Statue:Fi对应的位置:设置为当前部件
- RO:
- 如果
Rj,Rk不全为Yes,则stall:防止RAW冲突 - 读取源寄存器
- 如果
- EXE:
- 功能部件计算结果
- 计算完成后,更新记分牌
Function Unit Status:Rj,Rk:设置为No,表示释放对应的寄存器
- WB:
- 将计算结果写入目标寄存器
- 计算完成后,更新记分牌:
Function Unit Status:- 清空当前功能部件
- 如果其它功能部件中,
Qj,Qk对应的部件为当前部件,则将其清除,并将Rj,Rk设置为Yes
Register Result Statue:- 清空
Fi对应的位置
- 清空
7.5.5 示例
详见视频讲解
7.5.6 Scoreboard的局限性
- 如果后面的每一条指令都依赖前面的指令,则Scoreboard用处不大
- issue queue的大小问题:
- window:CPU有多少指令可以处于等待状态,一般不能超出一个branch的范围
- 放弃了功能部件的流水性
- 存在WAR和WAW冲突,但Scoreboard选择stall解决
7.6 寄存器重命名
- 任何指令的写,都不写入寄存器,而是写入换名寄存器中
- 之后对该寄存器的读,直接读取换名寄存器
7.7 Scoreboard vs. Tomasulo

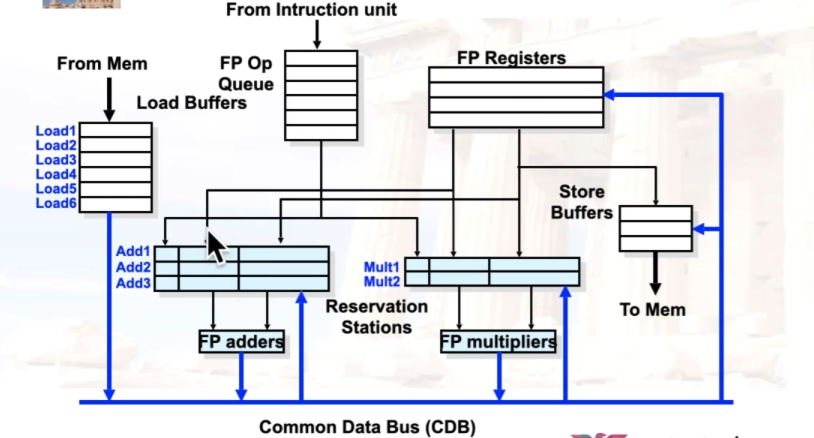
Chapter 8:Dynamic Schedule--Tomasulo
8.1 Tomasulo算法
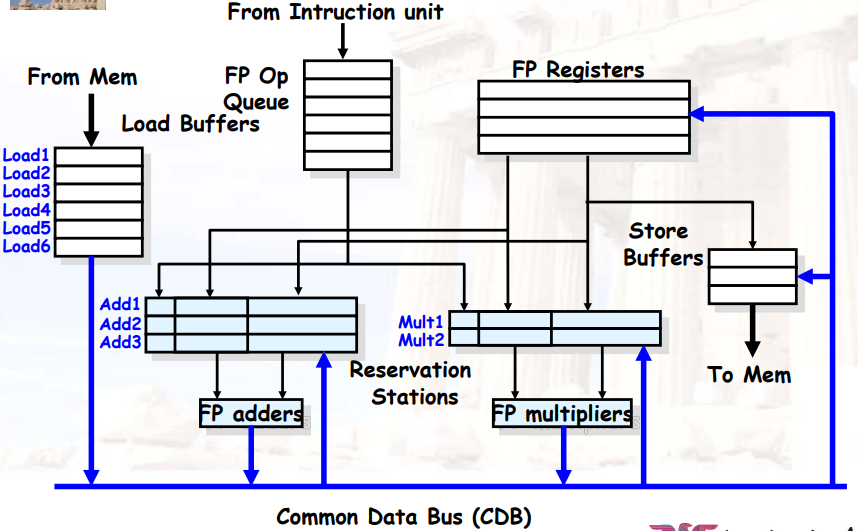
8.1.1 基础思想
- 指令&缓存 被分布在每个功能单元(FU,Function Units)中
- FU buffer被称作保留站(RS,reservation stations),具有挂起的操作数
- 指令中的寄存器被替换为 具体的值 /
指向保留站的指针,被称为
register renaming- 避免了WAR、WAW冲突
- 保留站比寄存器多,因此可以进行一些编译器不能进行的优化
- 当指令要进行计算时,操作数 从保留站中通过CDB(Common Data
Bus)广播获取,而不是寄存器
- 寄存器进保留站只有一个时刻:指令进入保留站的时候
- Load、Store也被视为FU,也拥有RS
- 整数指令可以穿过branch使用,如循环中下一次的指令可以直接使用上一次计算出来的值
8.1.2 保留站的内容
| 状态 | 解释 |
|---|---|
| Busy | 表示当前行是否有指令 |
| Op | 当前行的指令(如add or subtract) |
| Vj, Vk | 源寄存器能读取到的数据 |
| Qj, Qk | 尚不能读取到的数据将由哪条指令算出 |
| A | 指令的地址,用于存放立即数和计算得到的地址数据 |
8.1.3 三个阶段
Tomasulo算法的调度分为三个步骤:发射、执行、写回
- 发射Issue:
- Tomasulo算法是顺序发射的,即指令按照程序中的顺序一条接一条被发射到保留站
- 判断能否发射的唯一标准是指令对应通路的保留站是否有空余位置,只要保留站有空余,就可以把指令发射到保留站中
- 周期结束时会更新保留站和寄存器结果状态表,如果指令有可以读取的数据,就会立刻拷贝到保留站中
- 寄存器结果状态表中总是存有最新的值,即如果后序指令的目的寄存器和前序指令的目的寄存器重合,那就只保留后序指令的写信息
- 执行EXE:
- 指令通过拷贝数据和监听CDB获得源数据,然后开始执行
- 执行可能是多周期的,在执行过程中不改变处理器状态
- 写回WB:
- 指令在写回阶段通过CDB总线将数据直通到寄存器堆和各个保留站
- 周期结束时,根据寄存器结果状态表来更新寄存器堆,并且清除保留站和寄存器结果状态表的信息
8.1.4 Data Path
- Normal Data Bus:数据 + 目标地址
- Common Data Bus:数据 + 源地址
- 64-bit数据 + 4-bit 功能单元的源地址
- 如果与期望的功能单元地址匹配,则写入
8.1.5 具体运行方式
- Issue:
- 如果对应功能部件被占用,则stall:防止结构冲突
- 计算完成后,更新保留站
Reservation Station:Busy:设置为YesOp:设置为对应的操作Vj,Vk:设置为读取到的源寄存器的值Qj,Qk:如果源寄存器被占用,则设置为对应的功能部件A:如果指令为LD/ST,则设置为计算出的目标地址
Register Result Statue:- 目标寄存器对应的位置:设置为当前部件
- EXE:
- 如果
Vj,Vk没有都被填入,则stall:防止RAW冲突 - 功能部件计算结果
- 如果
- WB:
- 将计算出的结果放入
CDB中进行广播,并写入寄存器堆 - 计算完成后,更新保留站
Reservation Station:- 清空当前功能部件
- 如果其它功能部件中,
Qj,Qk对应的部件为当前部件,则读取CDB中的值,放入对应的Vj,Vk中
Register Result Statue:- 清空
Fi对应的位置
- 清空
- 将计算出的结果放入
8.1.6 示例
具体见视频
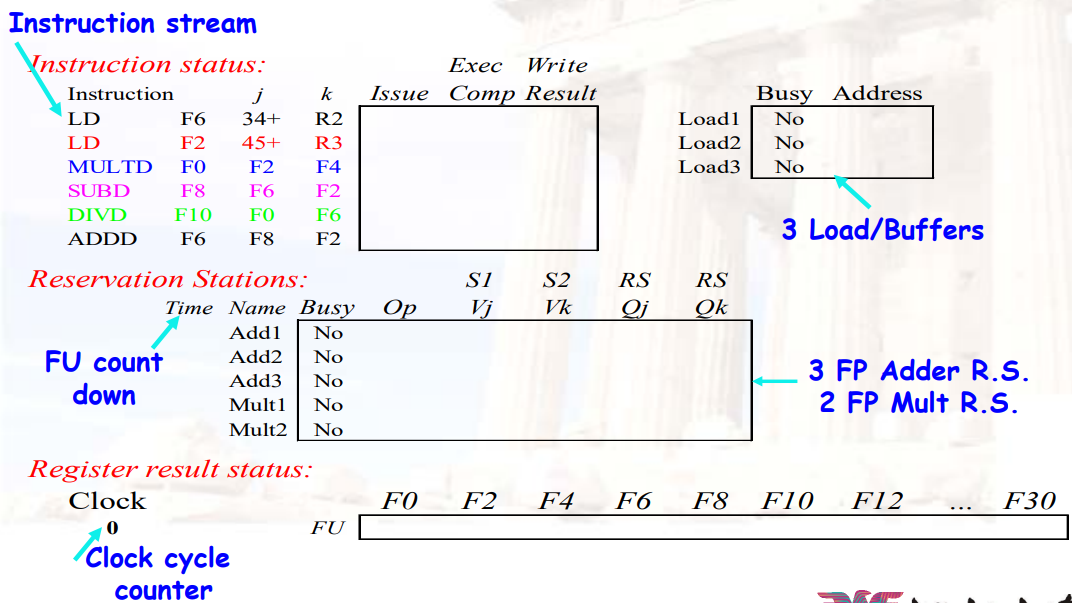
8.1.7 优缺点
Tomasulo算法记录寄存器的值,Scoreboard算法只记录寄存器的编号
优点:
- 将hazard detection logic分散开
- 每个功能单元都有一个保留站,使用CDB进行广播
- 如果多条指令等待同一个结果,并且每条指令都有其它的操作数,当目标结果在CDB中被广播时,这些指令可以同时释放
- 可以消除WAW、WAR冲突
缺点:
- 需要实现一个高速CDB
- 每一个cycle只能有一个功能部件完成,因为CDB上同时只有一个数据
8.1.8 Tomasolo算法的指令可以跨越循环的前后轮
- Tomasolo算法可以实现事实上的动态展开循环,每一轮都可以正常进行
- 要求branch为预测跳转
- 寄存器重命名
- 多次迭代使用不同的物理目标
- 寄存器重命名
- 多次迭代使用不同的寄存器物理目的地(动态循环展开)
- 保留站
- 允许发出指令以推进过去的整数控制流操作
- 还缓冲寄存器的旧值—完全避免了我们在记分板上看到的WAR暂停
- 其他观点:Tomasulo动态构建数据流依赖图
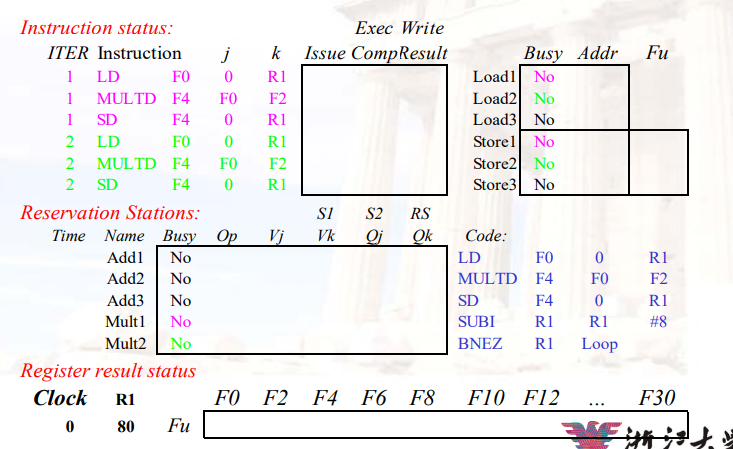
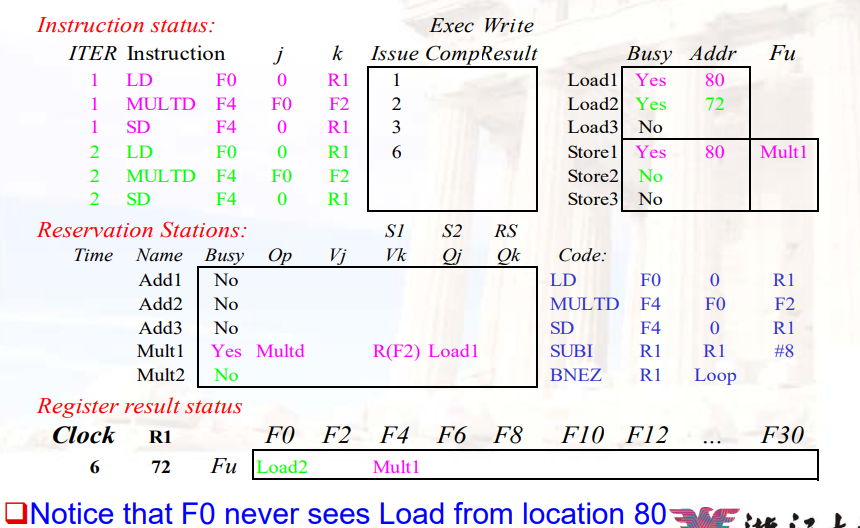
示例:
- 注意,这里直接将Load2写入了F0对应的位置
- 因为需要Load1结果的指令MULTD此时等待的是Load1的值,而不是F0的值
8.1.9 精确中断
- Tomasulo算法的特点:
- 顺序issue
- 乱序execution
- 乱序completion
- 需要修复乱序完成的操作,从而能在指令流中找到精确的断点
- Speculation
- Reorder buffer
8.2 Scoreboard算法:通过寄存器重命名避免WAR、WAW等待
8.2.1 Scoreboard的流水级
- Issue:在以下情况下发出指令
- 功能单元可用
- 没有其他活动指令具有相同的目标寄存器。
- 解决了:structural冲突、WAW冲突
- Read Operands(RD)
- 两个操作数都可用,才能进入EX阶段,否则一直在RO阶段
- 这意味着以前发出但未完成的指令都没有将操作数作为目标
- 解决了:RAW冲突
- Execution(EX)
- 完成后通知记分板,以便重新使用功能单元
- Write Result(WB)
- 记分板检查WAR冲突,如果有则stall
8.2.2 Scoreboard算法
记分板全权负责指令发布和执行
- 创建相关性记录
- 决定何时获取操作数
- 决定何时开始执行
- 决定何时可以将结果写入寄存器
三种数据结构
Instruction status
- 指令在四个步骤中的哪一个
Functional unit status
- buzy,op,Fi,Fj,Fk,Qj,Qk,Rj,Rk
Register result status
- 哪个功能单元将写入该寄存器
8.2.3 Explicit Renaming 显式寄存器重命名
8.2.3.1 前提
- 物理寄存器 > 逻辑寄存器
8.2.3.2 核心思路
对每一条需要写寄存器的指令,分配一个新的物理目标寄存器
- 与编译器优化方式(SSA, Static Single Assignment)类似,但是是硬件实现
- 消除了WAR和WAW冲突
- 与Tomasulo类似,更加容易支持全乱序完成
- 类似于基于硬件的动态编译
8.2.3.3 实现机制
维护一个translation table
- 映射:ISA寄存器 => 物理寄存器
- 写寄存器时:从freelist中得到一个新的寄存器,替换原有项
- 释放物理寄存器的时机:所有使用该物理寄存器的指令均已执行完成
- 由于第二次写同一个逻辑寄存器时,该逻辑寄存器会被分配另一个物理寄存器
- 因此,只有两次写同一个逻辑寄存器之间的指令,有可能使用同一个物理寄存器
8.2.3.4 优点
- 将renaming与scheduling分离
- 流水线可以更贴近于标准MIPS流水线,只是每个周期可能会发射多条指令
- 否则的话,流水线更类似于Tomasulo或Scoreboard
- 可以使用标准的
forwarding、bypassing
- 允许数据从单个寄存器组中读取
- 不需要从
reservation stations或reorder buffer中获取数据 - 对平衡流水线来说,很重要
- 不需要从
- 是另一种获取精确断点的方式:
- 要获得精确的断点,所有需要“撤消”的操作就是撤消表映射
- 在
reorder buffer和future file之间提供有趣的混合- 结果立即写回寄存器文件
- 寄存器名称按程序顺序“释放”(通过ROB)
8.2.3.5 需要的支持
- 快速访问翻译表
- 一种物理寄存器文件,其寄存器数超过ISA指定的寄存器数
- 能够找出哪些物理寄存器是free的
- 没有free的寄存器 ⇒ issue会被stall
- 寄存器重命名不需要保留站,然而:
- 许多现代体系结构使用
explicit register renaming+Tomasulo-like reservation stations来控制执行流程
- 许多现代体系结构使用
- 两个问题:
- 如何管理
free list? - 显示寄存器重命名 如何与 精确中断相结合?
- 如何管理
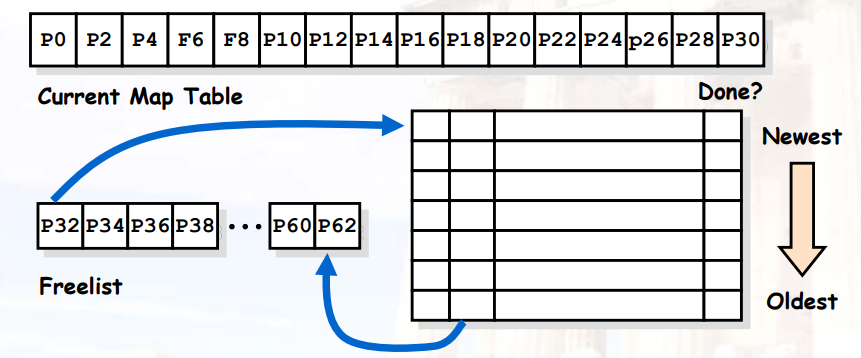
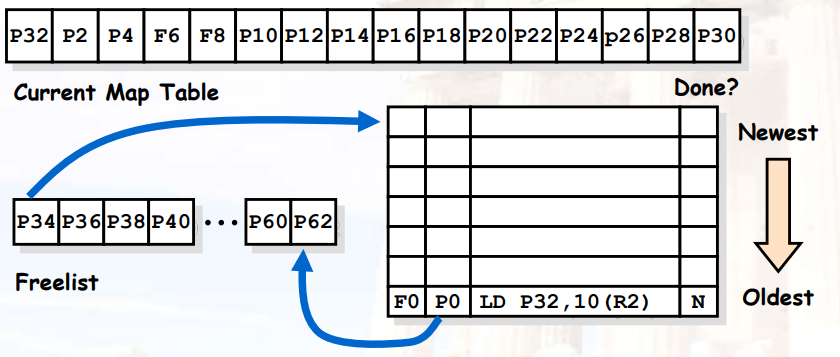
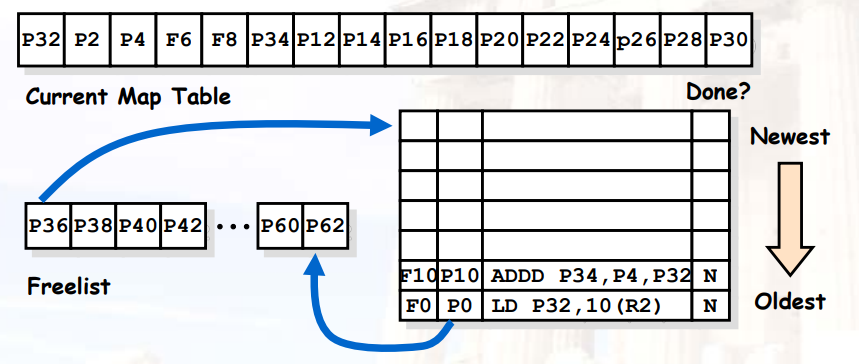
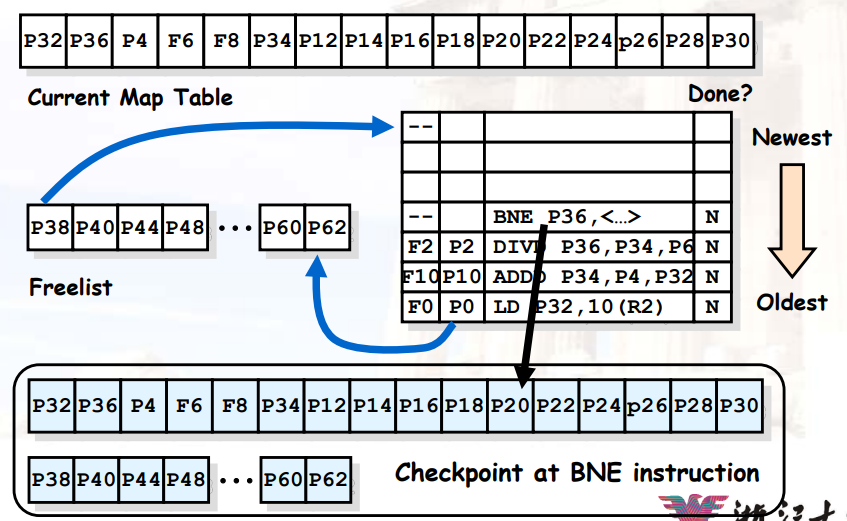
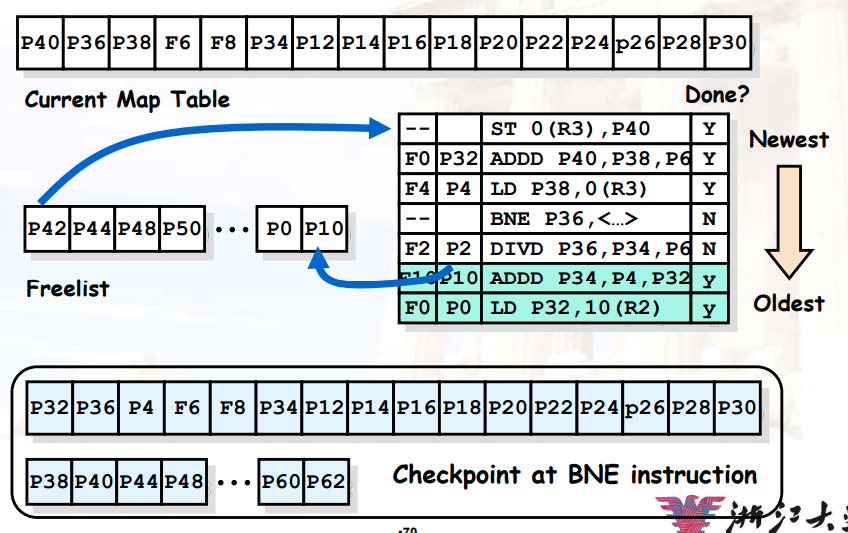
8.2.3.6 示例
- 物理寄存器表 > ISA寄存器表
- 在
issue阶段,每条指令从freelist中申请一个寄存器,作为自己的目的寄存器
- 注意物理寄存器
P0在这次load之后已经dead
- 当我们完成load操作后,我们释放该寄存器
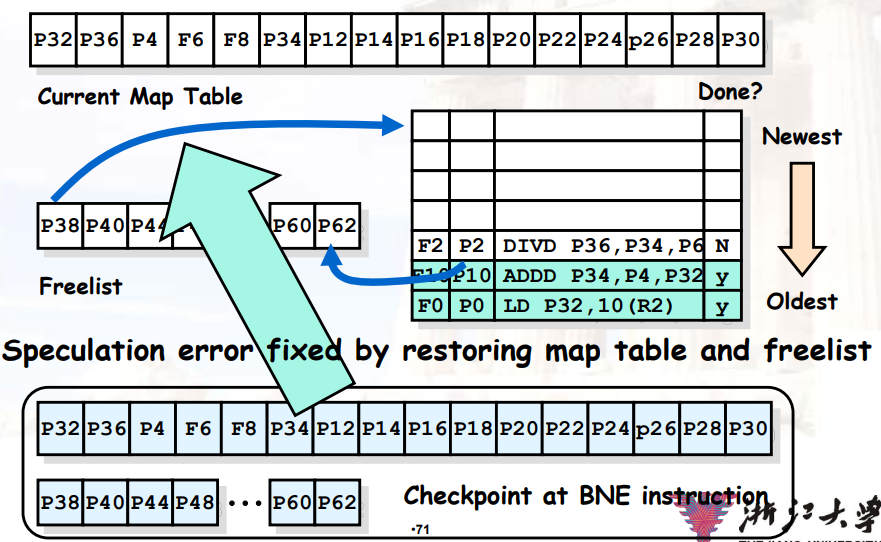
8.2.3.7 在Scoreboard中使用显式重命名
- 实现一个Rename Table:告诉Scoreboard,指令里面的哪个寄存器被换成哪个寄存器了
- Rename Table后面是一个更大的寄存器表,该表不对ISA公开,只能由Rename Table使用
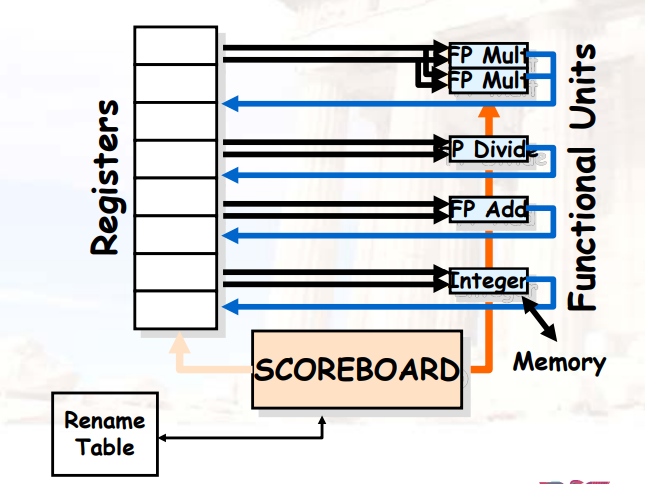
8.2.3.8 显式重命名Scoreboard的四个阶段
- Issue:指令译码、检查是否有结构冲突、为目标寄存器申请新的物理寄存器
- 指令按序issue
- 如果没有物理寄存器,则stall
- 如果有结构冲突,则stall
- Read Operands:直到没有冲突的时候,读取操作数
- 解决了RAW冲突,因为我们等待指令写回数据
- Execution:计算
- Write Result:结束计算
- 在这个过程中,没有检查WAR、WAW冲突
示例见视频
Chapter 9 :Branch Predictor & Speculation
9.1 Control Hazard
- Flushing:
- 每次遇到跳转,直接stall,直到跳转指令完成
- Predict-not-taken:
- 直接读入跳转指令的下一条指令
- 如果发现跳转指令为跳转,则清空流水线,此时浪费了1个周期
- Predict-taken:
- 读入如果跳转时的下一条指令
- 如果发现跳转指令为不跳转,则清空流水线,此时浪费了1个周期
- Delayed Branch
9.2 动态硬件预测
动态硬件预测,只有当前跳转指令被反复执行到的前提下,才有意义
预测是基于数据的预测,因此只能预测下一次遇到当前地址的跳转指令时,是否跳转
9.2.1 1-bit Branch-Prediction Buffer
- Performance = ƒ(accuracy, cost of misprediction)
- BHT,
Branch History Table:index:PC地址的低位value:1位,记录上一次是否跳转
- 问题:
- 在一个循环中,1-bit BHT会导致2次misprediction:进入循环、退出循环
- accurancy:(n-2)/n
9.2.2 2-bit Branch-Prediction Buffer
策略1:初始为Taken,发生2次not-taken后,才预测not-taken
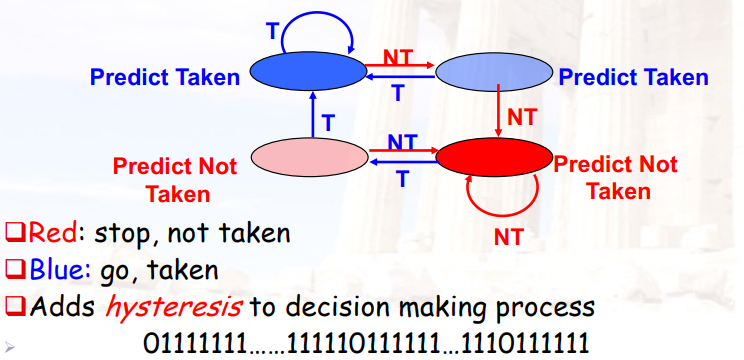
策略2:进入临时状态后,如果是taken,就回到taken了
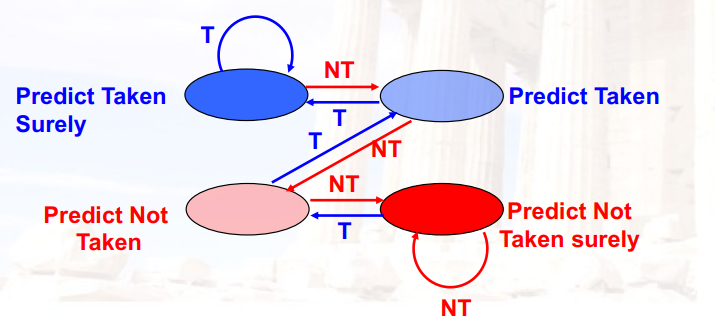
9.2.3 n-bit Branch-Prediction Buffer
与1-bit和2-bit类似,设计更加复杂的状态图

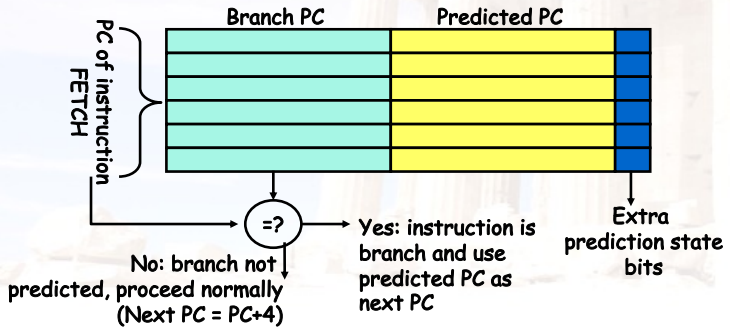
9.2.4 Branch Target Buffer
- 在循环中,每次跳转时,跳转的目的地址都是一样的
- 可以将跳转的目的地址缓存起来,减少一次加法
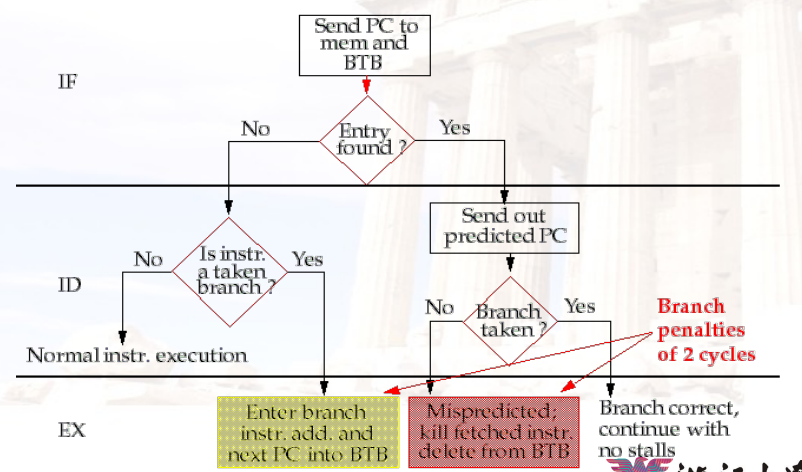
9.2.5 Integrated Instruction Fetch Units 集成指令获取单元
将IF阶段扩展,IF阶段可以实现:
- branch predication
- Instruction prefetch
- Instruction memory access and buffering
9.2.6 Return Address Predictor
- 间接跳转:目的地地址在运行时变化
- 如从函数返回、使用函数指针跳转、对虚函数的访问
- 寄存器的存在,使得难以预测跳转的地址
- SPEC89:程序返回占间接跳转的85%
Branch Target Buffer对return不起作用LR(Link Register)寄存器:用于存储函数的返回地址,在RISCV中是ra寄存器- 进入函数时,通常会先将
LR寄存器保存进堆栈,然后再执行函数的逻辑
- 进入函数时,通常会先将
9.3 Hardware Based Speculation 投机
9.3.1 Tomasulo的缺点
- 无法实现精确中断
- 精确中断:中断发生时,该指令之前的指令均执行完成,后面的指令均没有执行
- WB阶段检测中断
- 外部中断:找到最后面已经完成的指令,这之前的全部完成,之后的全部没有完成
- 内部中断:
- 非法指令、除0异常:直接终止程序
- 缺页异常:仍需要回到产生中断的那条指令,要求必须精确中断。可以通过添加内存栅栏,让CPU强制等待到当前指令
- 会部分overlap
- 整数单元先跑,浮点单元后跑
- 尽管可以issue,但后续基本块在分支解决之前无法开始执行
9.3.2 Hardward-based Speculation
投机:在不知道branch指令是否跳转的情况下,先去做后面的指令
- 对branch的结果做speculation,假装预测是对的来执行程序
- 关键点
- 动态分支预测,选择跳转到哪里
- 由于跳转指令依赖于寄存器,因此跳转指令可能也要等待其它指令的执行完成
- 指令可以先执行,但指令的执行结果必须等待之前的指令均执行完,才能写入内存/寄存器
- 乱序执行、顺序写入
- 算法
- 按照预测的顺序执行,但是不commit
- 只有预测的结果正确时,才将其提交:写寄存器组、写内存
- 如果预测结果不正确,则回滚:清空Reorder Buffer
9.3.3 基于Tomasulo算法的投机执行 Speculative execution
9.3.3.1 基础思想
- 将指令的完成、指令的提交、结果的bypass分开
- 如果当前指令的结果是其它指令所需要的,则仍可以给出去,即使当前指令是推测执行的
- 因为后面的指令也保证不会写入
- 处于推测执行的指令,均可以正常执行,但不会写回,直到当前指令不再是speculative
- 按照顺序commit
- 当branch指令commit的时候
- 如果branch指令预测正确,则后续所有指令按序commit
- 如果branch指令预测错误,则直接舍弃后面的指令
9.3.3.2 结构
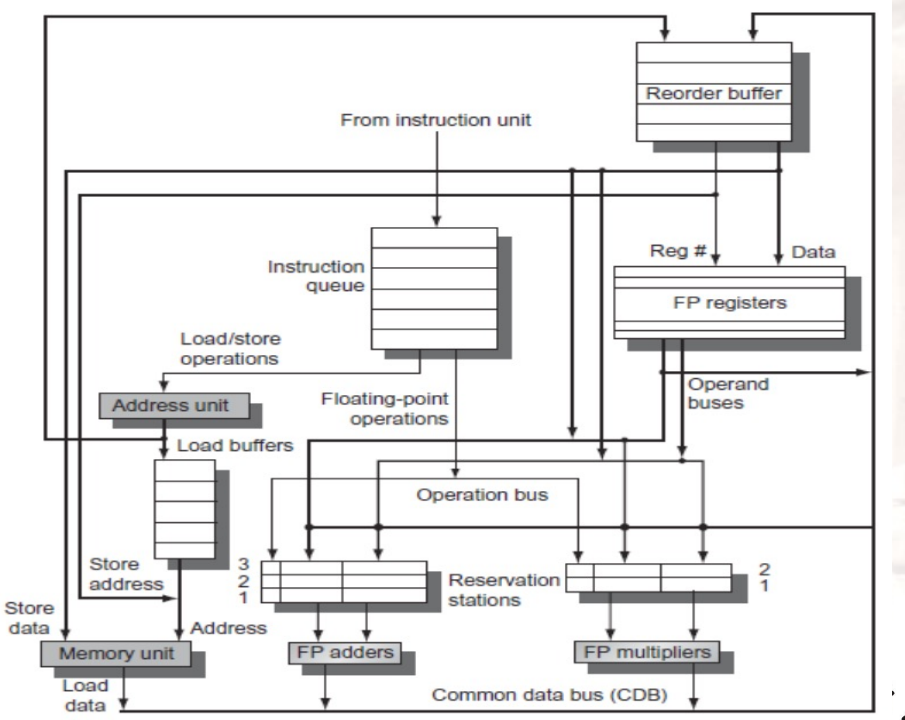
- 指令队列
Instruction queue:用于一次取值取多条指令 Reorder Buffer:- Reorder Buffer的来源是CDB、地址单元,出口是寄存器组、内存单元
- 即原来的
store buffer的拓展,记录哪个地址有哪个值需要写入 - 排序的依据:原来的指令顺序
- 由于要commit的指令,要么写寄存器,要么写内存,因此可以使用该模块实现顺序commit
- 原来CDB广播的数据是直接进寄存器组的,这里添加了一个Reorder Buffer,让其能够顺序commit
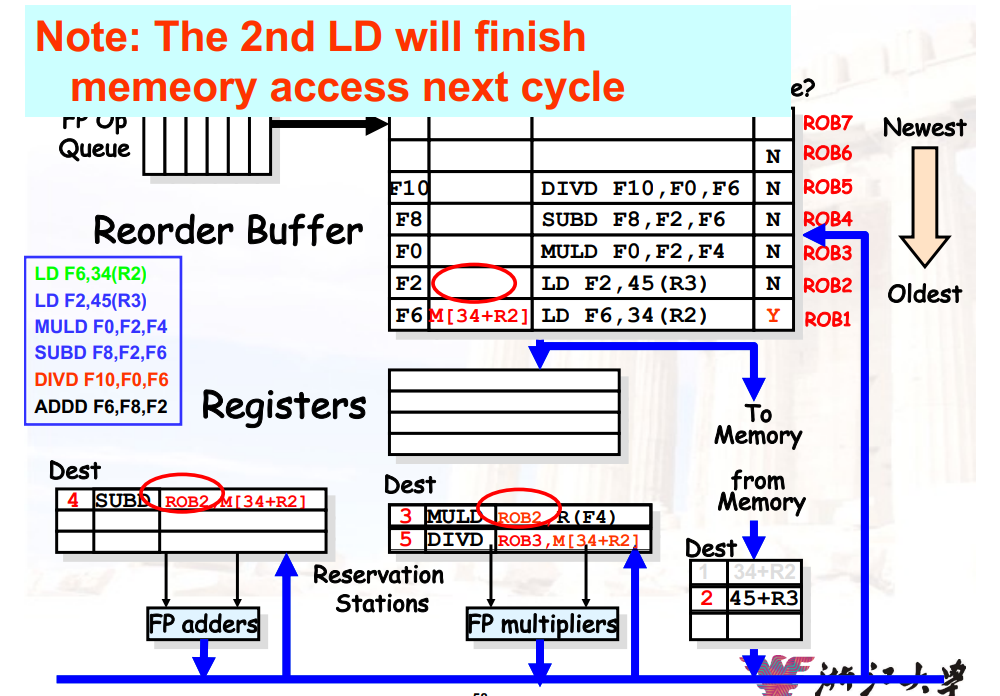
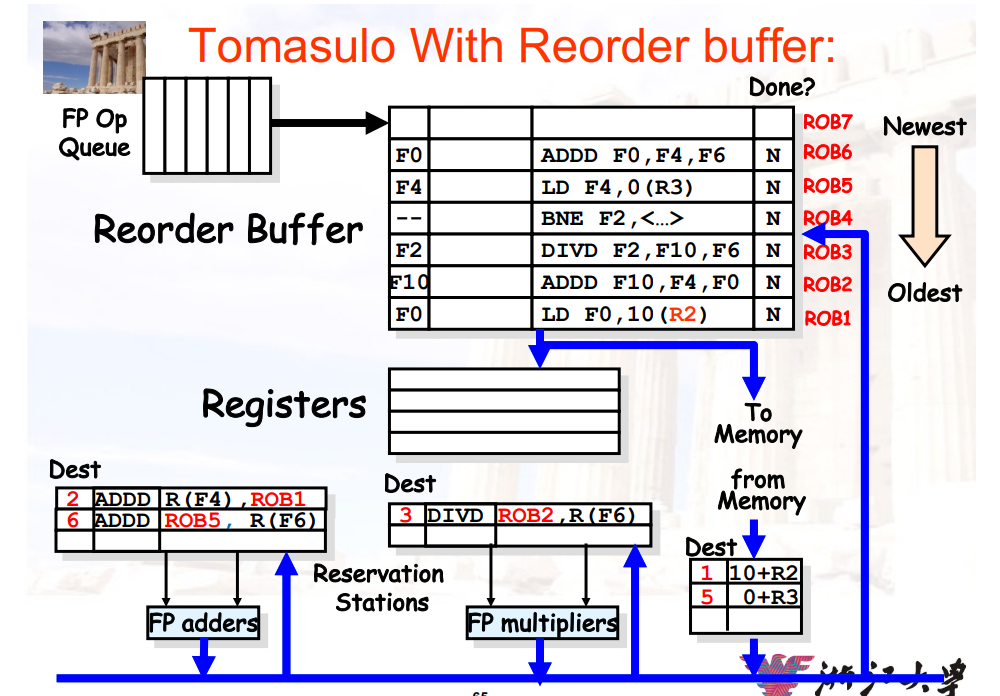
9.3.3.3 和Tomasulo算法的区别
- 增加了
Reorder Buffer,删除了Store Buffer - 寄存器的重命名是通过
Reorder Buffer,而不是通过保留站- 即,通过
Reorder Buffer暂存数据
- 即,通过
- 保留站只用来存放:已经issue,没有execution的指令的opcode、operands
Reorder Buffer会保存指令的结果,并且将操作数bypass给还没有完成的指令
9.3.3.4 Reorder Buffer 的每个实例包含
- 指令的类型
- 目的寄存器
- 计算出的值
- 是否已经就绪
- 异常向量
9.3.3.5 投机Tomasulo算法的四个步骤
- Issue:从FP Op Queue中得到一条指令
- 如果保留站、Reorder Buffer均有空,则发射该指令
- 将该指令存入保留站,并且在Reorder Buffer中为目的寄存器分配一个空间
- 这一步也叫dispatch(分派)
- 更新该实例的控制单元为
in use
- Execution:对操作数进行计算
- 如果两个操作数均ready,则进行计算
- 否则,等待
CDB广播两个操作数,直到两个操作数均在保留站中 - 解决RAW冲突
- Write Result:完成计算
- 写入
CDB进行广播 - 写入
Reorder Buffer - 标记保留站中对应的位置为
free
- 写入
- Commit:使用
Reorder的结果更新寄存器- 当
Reorder Buffer头部的指令已经有结果了,更新寄存器/写入内存,并将其从Reorder Buffer中移除 - 如果跳转指令预测错误,则清空
Reorder Buffer- 这一步也叫graduation(毕业)
- 当
9.3.3.6 commit时的操作
当一条指令变为Reorder Buffer的头部指令,并且已经计算出结果时
- 如果当前指令不是跳转指令
- 更新寄存器
- 从
ROB中删除该寄存器 - 如果是
store指令,则更新内存
- 如果是跳转指令,但是预测错误
- 清空
ROB - 流水线从branch的正确分支那里重新开始执行
- 清空
- 如果是跳转指令,并且预测正确
- branch的执行就结束了
9.3.3.7 示例
- 使用
ROB实现重命名:保留站中等待的,是ROB中的项,而不是之前的保留站的项 ROB保证了提交的顺序与原始指令的顺序是一样的
详细见视频
- 跳转指令依旧需要进入
ROB - 当后面的指令需要读寄存器时,要选择离它最近的
ROB项
9.3.3.8 新问题:memory disambiguation
问题:给定一个指令序列,先store后load,它们两个访问的地址是否时相同的
- 或者说,两条指令是否有RWA冲突
- 如下面的例子中,R2可能与R3的值相同,导致访问同一个地址

我们是否能够先执行LD指令,后执行ST指令?
- 如果存储的是寄存器的值,可能会由于一些对于R2的操作指令,使得ST指令被delay很长时间
- 我们可能想要在同一个周期里,开始执行这两条指令(ST和LD可以通过double bump在同一个周期内完成)
解决方法:
- 在进行内存操作时,要保证
ROB中所有内存操作的地址均已得到,才能进行内存操作 ROB需要跟踪所有修改内存的指令,按照源码的顺序- 当地址已经获得的时候,记录地址、值,而不是寄存器的地址
- 保存先进先出的顺序:保证
load和store的执行顺序没有被打乱- 如下图中,LD指令必须在ST指令之后执行
- 硬件支持:
- 当我们有一个
load的地址的时候,检查store队列- 如果在
load之前有store指令的地址于其相同,则暂停load指令 - 如果
load指令的地址与之前的store指令的地址相同时,会有一个memory-induced RAW hazard- 如果
store的值已经可用,则返回该值 - 如果
store的值不可用,则将对应ROB的序号放入load指令的source中
- 如果
- 否则,执行
load指令
- 如果在
- 当我们有一个
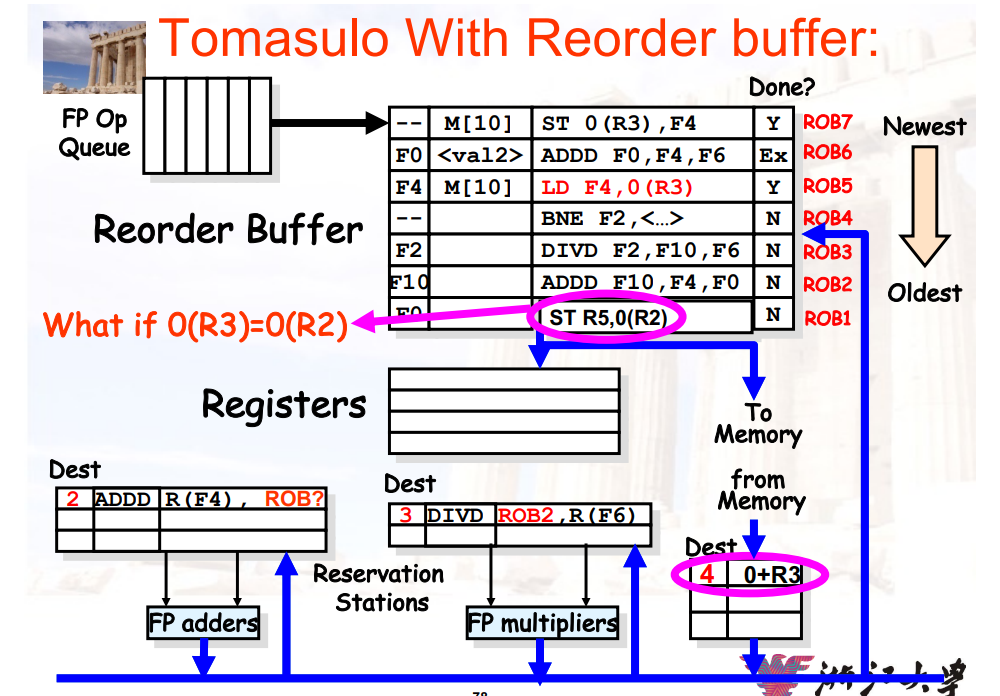
- 在进行内存操作时,要保证
9.3.3.9 对精确中断的硬件支持
- 如果在某一条指令产生了中断,则将
ROB中对应指令的- 后面的指令全部清空
- 前面的指令正常运行
9.4 记分牌、Tomasulo、带投机的Tomasulo三种算法对比
三者按顺序,依次解决了更多的问题
- 记分牌:RAW问题
- Tomasulo:WAW、WAR问题;RAW问题
- 带投机的Tomasulo:精确中断;WAW、WAR问题;RAW问题
Chapter 10:SuperScalar & VLIW
10.1 获取CPI<1:Multiple Issue Processor 多发处理器
CPI<1:单位时间内能够处理多条指令
- Vector
Processing:向量计算(把数据拼在一起、数据并行)
- 将多个数据拼成一个向量,指令对向量进行计算
- 在RISCV中,该指令称为vector指令
- 在其它处理器中,该指令称为SIMD指令
- Superscalar:超标量
- 每个周期可以执行的指令数量是变化的(1~8)
- 可以由编译器或硬件调度(Tomasulo)
- 如:IBM PowerPC、Sun UltraSparc
- Very Long Instruction
Words(VLIW):超长指令字(把指令拼在一起、指令并行)
- 在一个指令中,放固定数量的指令
- 该指令由编译器产生,将操作放到wide templates(TBD)中
- 编译器要保证放在一起的这几条指令之间,没有依赖关系
- 新的性能指标:Instruction Per Clock cycle,IPC
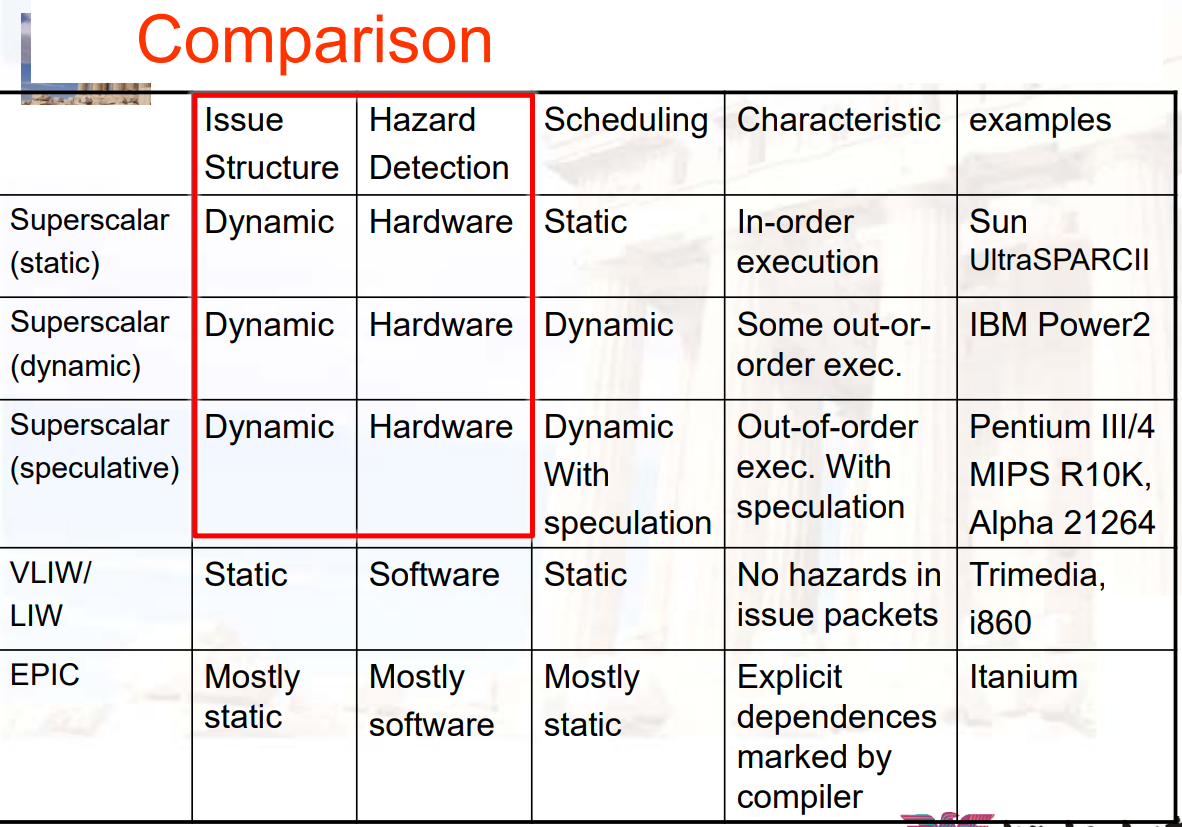
10.2 SuperScalar
- 每个周期尽可能发射足够多的指令,让每个功能单元均处于busy状态
- 静态调度:编译器优化,按序执行
- 动态调度:使用基于Tomasulo算法的技术,乱序执行
10.2.1 静态调度SuperScalar
指令按序发射
在issue的时候,会检查所有流水线冲突,会在一个周期内发射0~8条指令
Issue packet:fetch unit在取值的时候,会在一个周期内取多条指令,这些指令可能会在一个周期内发射
- 如果指令存在结构冲突/数据冲突,则指令就不会issue
- 如果是N-issue,则一个周期内发射0~N条指令
Issue阶段会被分开,并且实现流水
- within packet:确定当前packet中会有多少指令能够同时发射
- between packet:检查选中的指令中,是否与之前的packet有冲突
在一个周期内执行issue check,会限制clock cycle time:需要O(n2-n)次比较
- 因此,将issue阶段分割,并且实现流水
- 第一个阶段:决定由多少指令可以同时发射
- 第二个阶段:检查是否与之前的指令由冲突
- branch penalties会更高,因此预测准确更重要
- 因此,将issue阶段分割,并且实现流水
多发的难点:
译码
issue:难于找到一条FP和一条整数指令,两者完全没有关系
寄存器组:需要在一个周期内完成2 * N个写、 1 * N 个读
Rename的逻辑:必须能够在一个周期内,对同一个寄存器,换名两次,举例如下

Result buses:需要在一个周期内,完成多条指令
- 因此,需要一个multiple buses,对于每一个保留站都有一个匹配逻辑
- 或者,需要multiple forwarding paths
双发流水线:dual-issue pipeline
Scalar MIPS
- 一次两条指令,一条浮点,一条整数
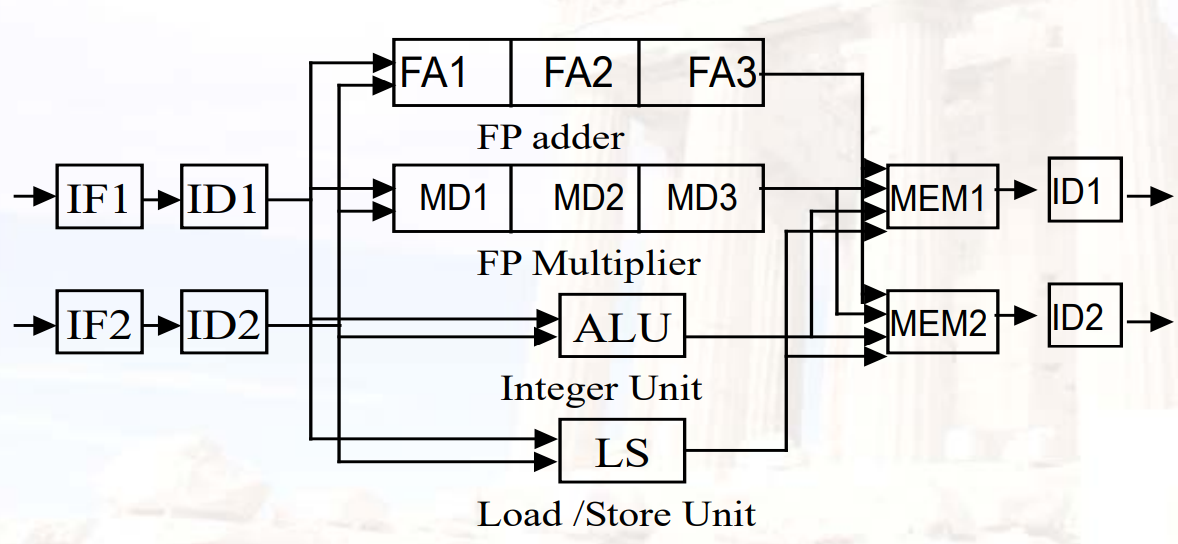

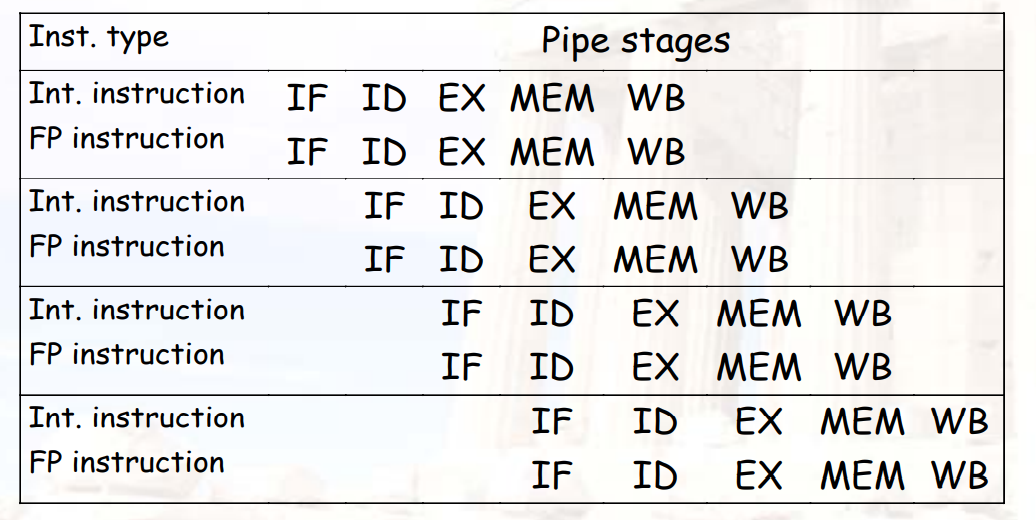
10.2.2 动态调度SuperScalar
- 两种不同的方法用于解决一个周期内issue多条指令:
- pipeline:将两条指令分别在一个周期的上升沿、下降沿执行
- widen issue logic:有一个更宽的逻辑单元,同时可以处理两条指令
- 现在一般两种方法都用
- 双发 ≠ 双执行,只有数据都准备好了,才能执行
- 如果有多个整数单元,则
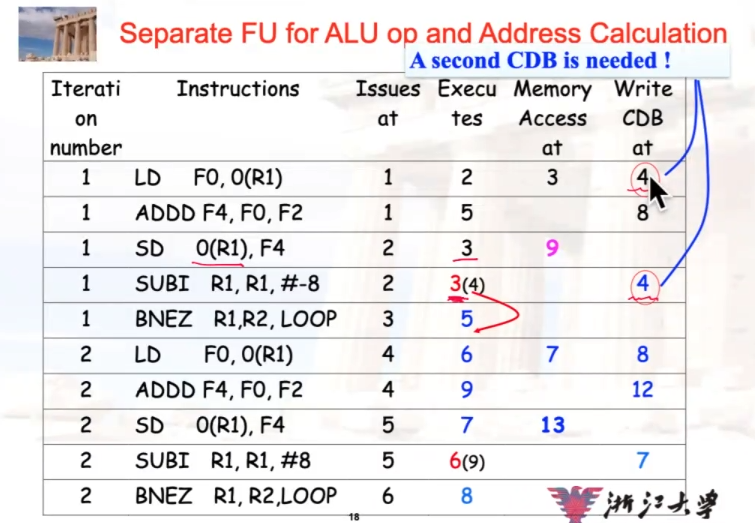
假设整数部分有3个单元:ALU、计算地址(ADD)、比较器(SUB)
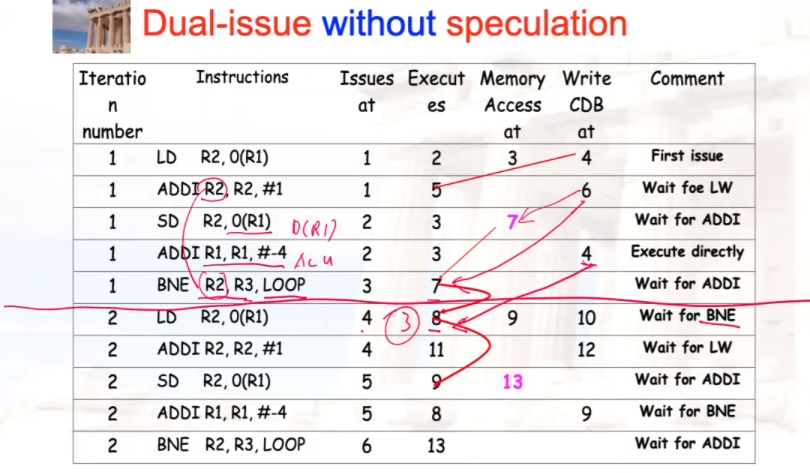
双发,但不使用speculation
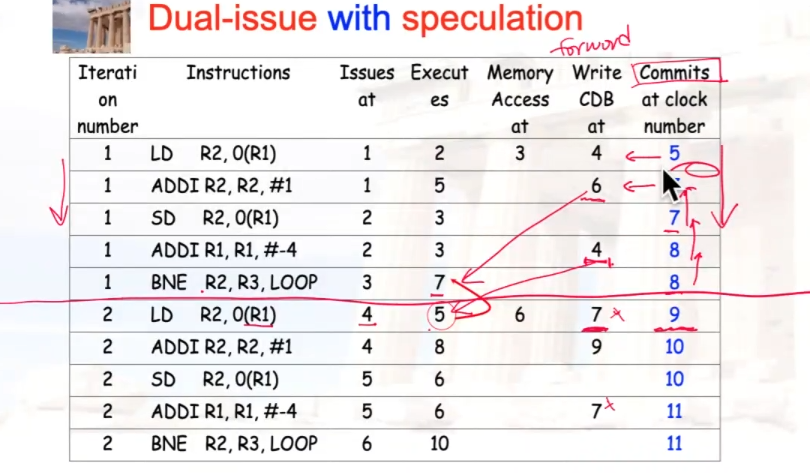
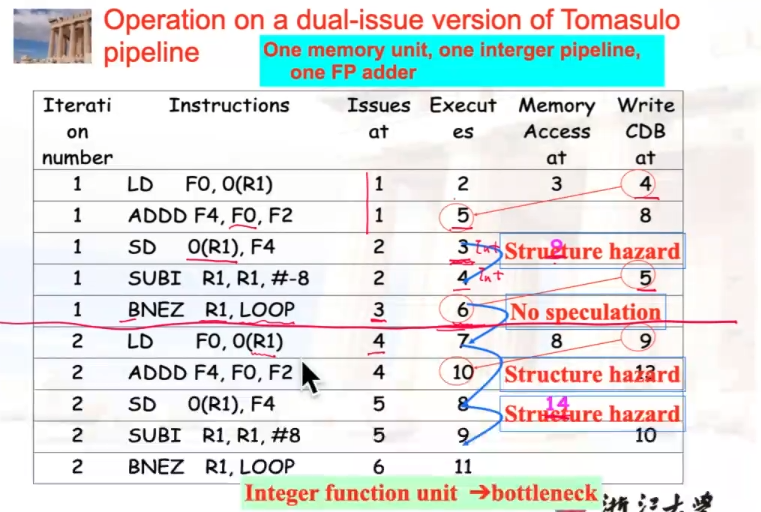
双发,使用speculation

10.2.3 ILP软件方法
- 循环展开
- 静态分支预测
- 静态多发:VLIW(超长指令字)
- 高级编译器支持:
- 软件流水线:software pipeline
- 全局代码调度:global code scheduling
- 硬件对软件的支持
- 条件/预测指令,如ADDHI(前面的比较成功,则执行)、SUBLO(前面的比较s失败,则执行)
- 编译器投机
示例:
C代码:
翻译为MIPS
检查hazard
利用延迟槽减少stall
循环展开:要求循环次数必须是4的整数倍
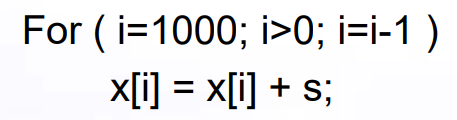




从编译器角度看code movement
- 编译器要考虑程序里面的依赖关系
- 不管流水线是否有硬件冲突
- 编译器要通过指令重排,避免冲突
- 编译器主要考虑RAW(真实依赖),通过寄存器来判断
- 如果有RAW依赖,则不能并行
- 编译器很难判断
memory disambiguation100(R4)与20(R6)是否相等?- 在不同的循环中,
100(R4)与20(R6)是否相等?
循环展开的细节
- 通常不知道循环的具体次数
- 假设有n次,且我们会将循环中的内容展开k遍
- 通常不是简单展开,而是产生一个相邻循环的pair
- 先执行
n % k遍 - 然后再进行
n / k次展开
- 先执行
10.3 静态多发:VLIW
- VLIW:Very Long Instruction Word
- 每个超长指令字中,存储的指令的类型是固定的
- 在指令集的设计中需要进行平衡tradeoff
- 超长指令字可以提供多条指令的空间
- 编译器放入的多条指令,相互之间是没有依赖关系的
- 例如:2个整数指令、2个FP指令、2个Memory访问、1个branch
- 需要编译技术,在多个跳转之间进行调度
- VLIW的问题:
- 技术问题:
- 代码大小增加了
- 会有unused function slots
- 任何功能单元上的stall,会引起多条指令的stall
- 逻辑问题:
- 二进制代码的兼容性
- 多发处理器的主要挑战:
- 如何实现更大的ILP
- 技术问题:
VLIW的循环展开示例:

Chapter 11:Multithreading
11.1 多线程软件
11.1.1 进程&线程
- 进程
- 每个进程有独特的地址空间unique address space
- 可以有多个线程
- 线程:每个线程有它独特的执行上下文unique execution
context
- 独立的PC、registers、stack
- 一个进程的所有线程,共享相同的地址空间
- 可以有私有的堆空间,但一般情况下,一个进程的所有线程共用一个堆
11.1.2 多线程应用:进程被划分成了线程
- 增加并发度concurrency/并行度
- 并发concurrent:外面来了一件事,但手头的事不能停下,因此会被动的同时做两件事
- 并行parallel:主动将任务分为两部分,同时进行
- 部分阻塞
- 集中资源管理
11.1.3 如何保证流水线之间的指令没有依赖关系
- 交替执行不同线程的指令
- 寄存器组是分bank的,每个线程使用不同的bank
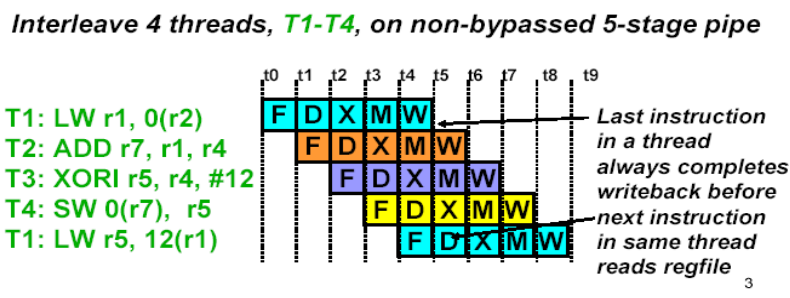
11.1.4 多线程体系结构
- 如果处理器可以执行多个软件线程,则
- 可以同时执行:线程可以由硬件切换(交替执行interleaved),而不是由OS控制
- 共享资源
- 更好的资源利用率、更好的吞吐量
- 可以是同一个进程,也可以不是
- 如果不是,问题主要是页表的切换
- 页表可能会有多份
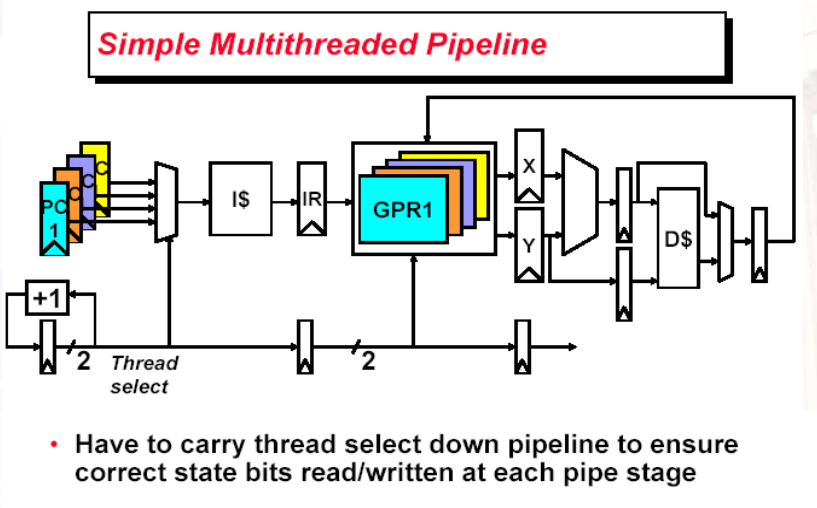
11.1.5 多线程的开销
- 对于每个软件来说,CPU更慢了
- 每个线程需要有各自独立的user state:GPRs、PC
- 也需要独立的OS控制状态:虚拟内存页表、异常处理寄存器
11.1.6 线程调度策略
- Fixed interleave(CDC 6600 PPUs,1965)
- 每N个周期,每N个线程各自执行一条指令
- 如果线程没有ready,就stall
- Software-controlled interleave(TI ASC PPUs,1971)
- OS在N个线程之间,分配S个流水线槽位
- 硬件在S个流水线槽位之间,做固定的interleave
- Hardware-controlled thread scheduling(HEP,1982)
- 硬件跟踪哪个线程ready to go
- 根据硬件优先的模式,选择下一个要执行的线程
Denelcor HEP是一个
uniform shared memory multiprocessor
- 有多个处理器,共享一个内存
uniform shared memory- 是一个细粒度(fine-grain)的多线程
- 可以忍受内存的延迟、同步的延迟、功能单元的延迟
- 每个处理器有120个线程,时钟周期频率为10MHz



11.1.7 Coarse-Grain Multithreading 粗粒度多线程
- Tera MTA为超算应用设计
- 数据特点:数据集很大,局部性较低
- 没有data cache
- 有很多并行的线程,去隐藏一个large memory latency
- 其它应用会更加cache friendly
- 当cache hit时,会有更少的流水线bubble
- 只增加一部分线程,去隐藏偶尔的cache miss latencies
- 当cache miss的时候,交换线程

11.2 多线程设计
- 细粒度多线程
Fine-grained multithreading- 每一个时钟周期,都在不同线程间切换
- 多个线程的指令执行,是交织(interleave)在一起的
- interleave是以轮询的方式进行的:CPU认为指令序列就是交替好的
- 一旦发生停顿,所有线程均中断
- 粗粒度多线程
Coarse-grained multithreading- 一直跑单个线程,只有在成本比较高的停顿发生时,才会进行线程切换
- 如:二级/三级cache miss、功能单元的数据冲突
- 会有线程切换的开销
- 在解决停顿时间较长的情况时,比较划算
- 设计时需要考虑
- 上下文切换的开销
- 需要支持多少线程
- 期望的应用级并行度
11.2.1 Superscalar Machine Efficiency
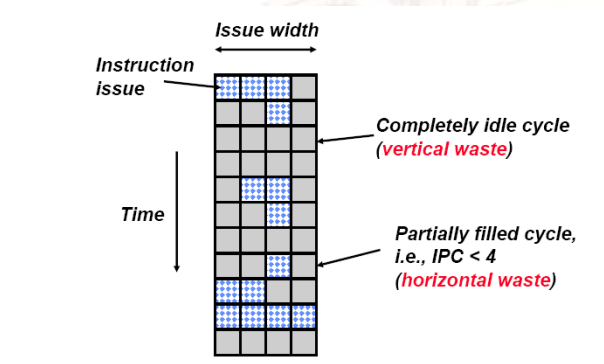
- 垂直waste:通常是cache miss
11.2.2 垂直多线程
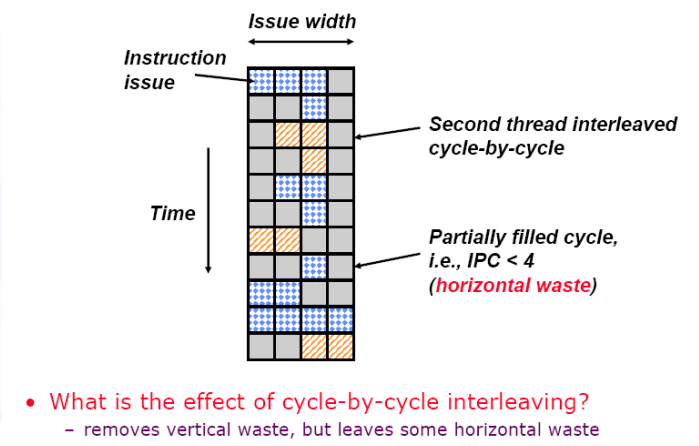
- 消除了垂直waste,但是会没有解决水平waste
11.2.3 芯片多线程
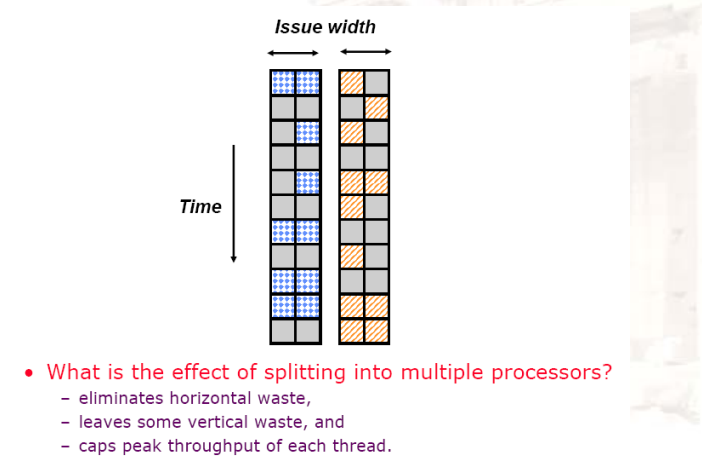
- 消除了水平waste,但是还有一部分垂直waste
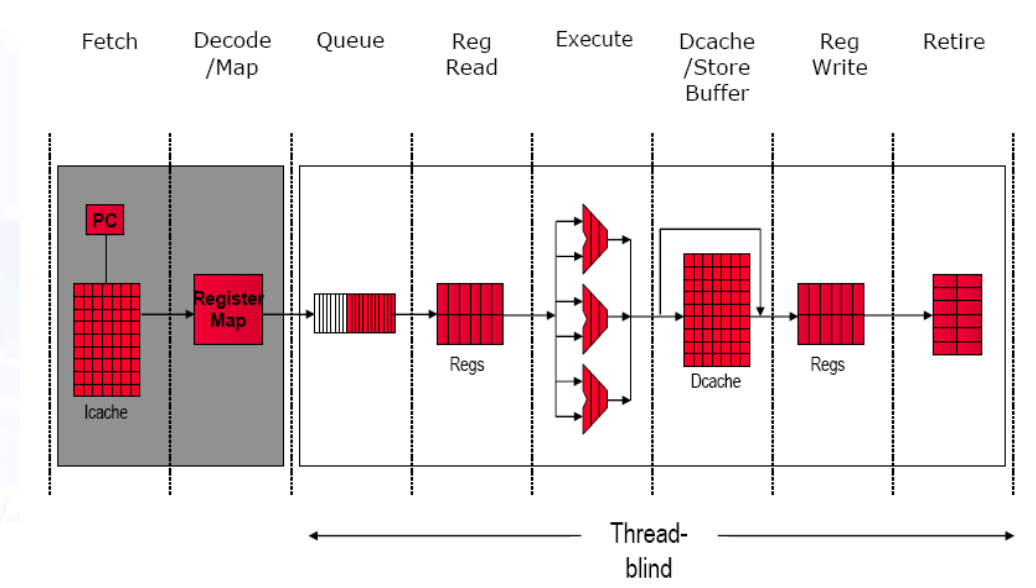
11.2.4 同时多线程 Out-of-Order Simultaneous Multithreading
在细粒度的基础上进行改良

基础Out-of-order流水线
SMT流水线
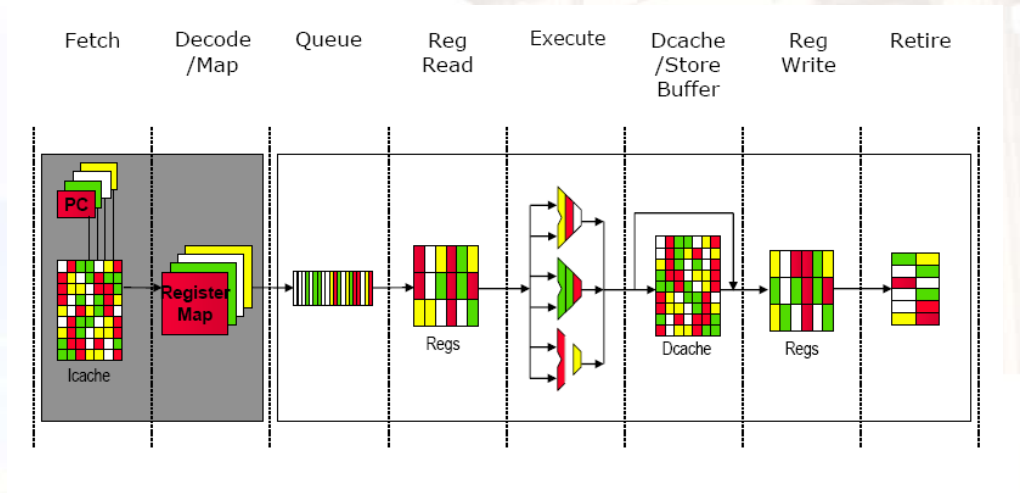
SMT的设计挑战
- 要在细粒度实现的表现与单线程的表现之间进行权衡
- 首选线程:可能会牺牲吞吐量
- 不太可能混合来自多个线程的指令
- 最大限度地提高单线程性能,应尽可能提前提取,并在分支预测失误或预取缓冲区中发生未命中时释放提取单元
- 一个较大的寄存器文件,用于保存多个上下文
- 不影响时钟周期,例如在指令发出时,在指令完成时
- 确保cache和TLB冲突不会导致性能下降
- 要在细粒度实现的表现与单线程的表现之间进行权衡
11.2.5 投机、乱序、超标量的处理器
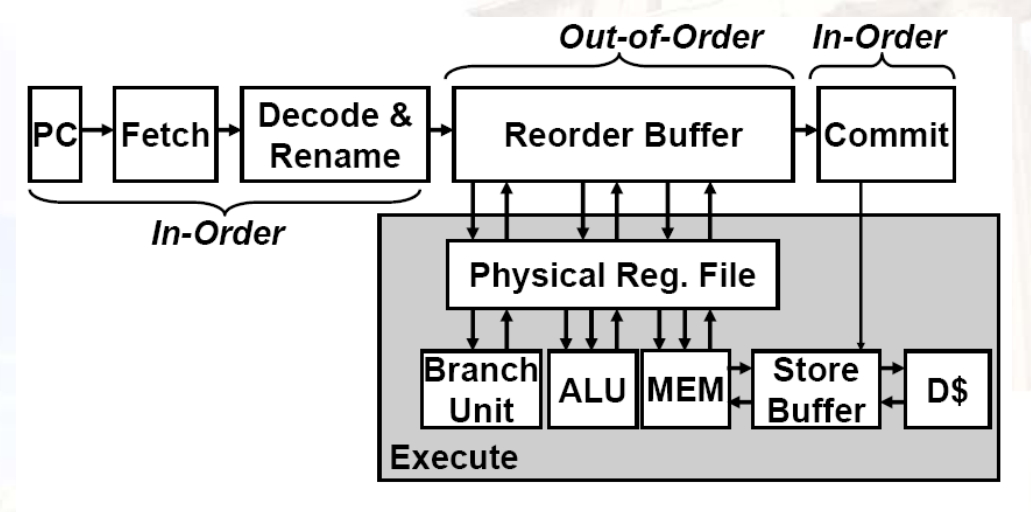
11.2.6 芯片多线程
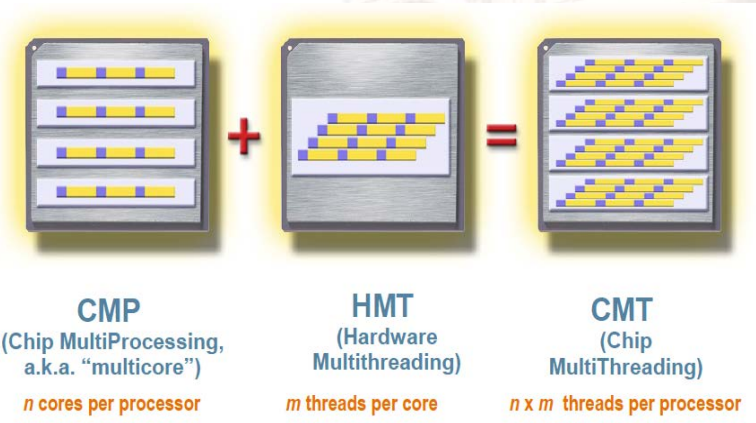
Chapter 12:DLP--Vector & SIMD & GPU
数据级并行
- Vector Processor
- GPU
线程级并行
- SMP/DSM
- Cache coherence
- Synchronization
12.1 程序执行四种模式
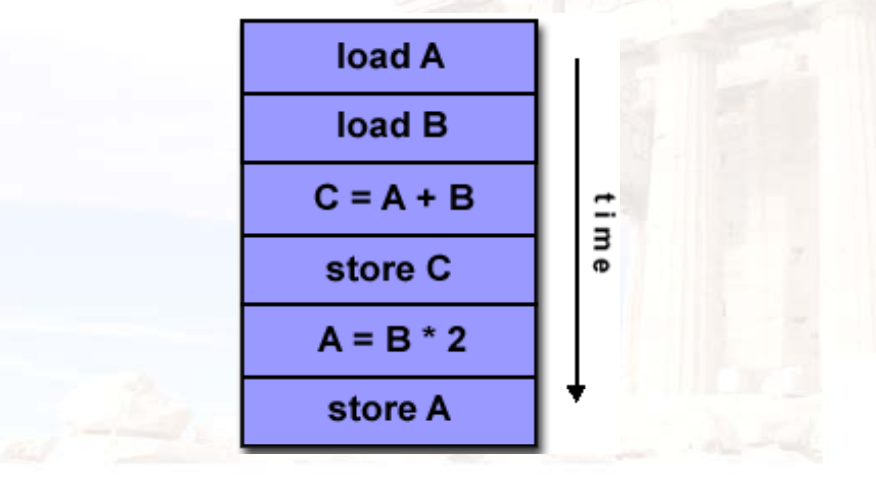
SISD:单一指令、单一数据
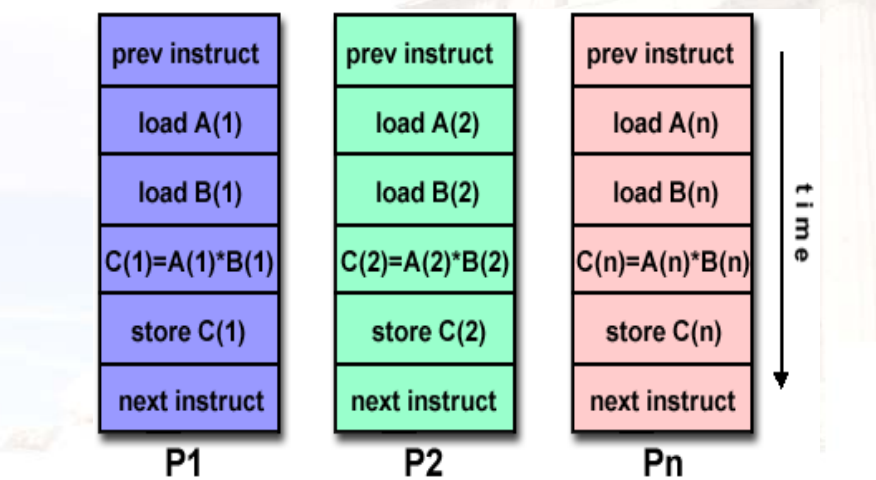
SIMD:单一指令、多个数据
- SIMD必须在最小段里面执行,因为要保证指令是单一的
- 如果跳转的话,指令就不一样了
MIMD:多条指令、多个数据
MISD:多条指令、单一数据
- 比较罕见
12.2 SIMD
- SIMD体系结构可以利用显著的数据级并行性:
- 面向矩阵的科学计算
- 面向媒体的图像和声音处理器
- SIMD比MIMD更节能
- 每个数据操作只需要获取一条指令
- 使SIMD对个人移动设备具有吸引力
- SIMD允许程序员继续按串行的思路思考
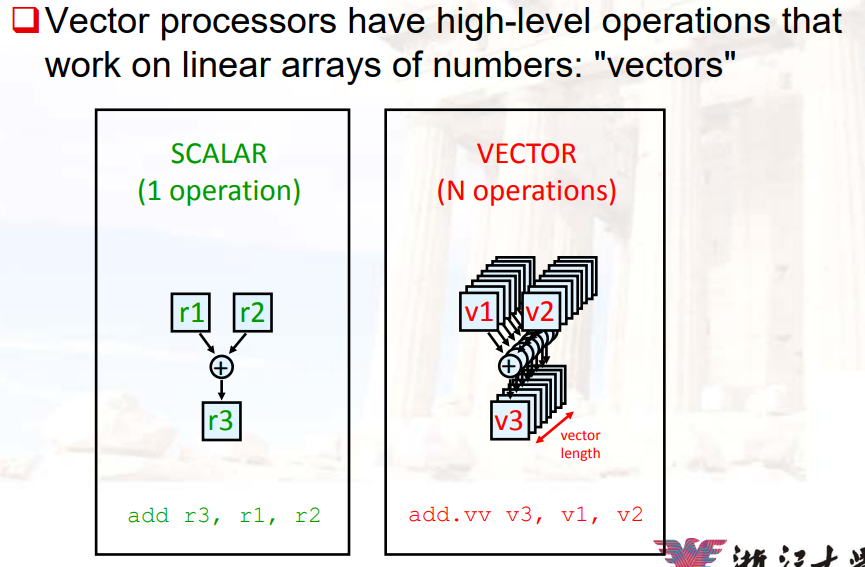
12.3 Vector Processing 向量计算
- 在处理单元的个数不变的时候,相当于做了一次循环展开,节省了branch的开销
12.3.1 向量计算的特点
- 单矢量指令意味着大量的重复工作(循环)
- 可以减少IF的次数
- 每个结果独立于以前的结果
- 长管道,编译器确保无依赖性
- 提高时钟频率,因为基本上都是整数运算,可以很快完成
- 硬件不必检查数据危害
- 访问存储器的向量指令具有已知的访问模式
- 内存是高度交错的
- 内存的读取延迟会被分摊(amortize)到超过64个元素
- 不需要(数据)缓存
- 减少管道中的分支和分支问题
- 通常由回路分支引起的控制危险是不存在的
12.3.2 Vector架构的类型
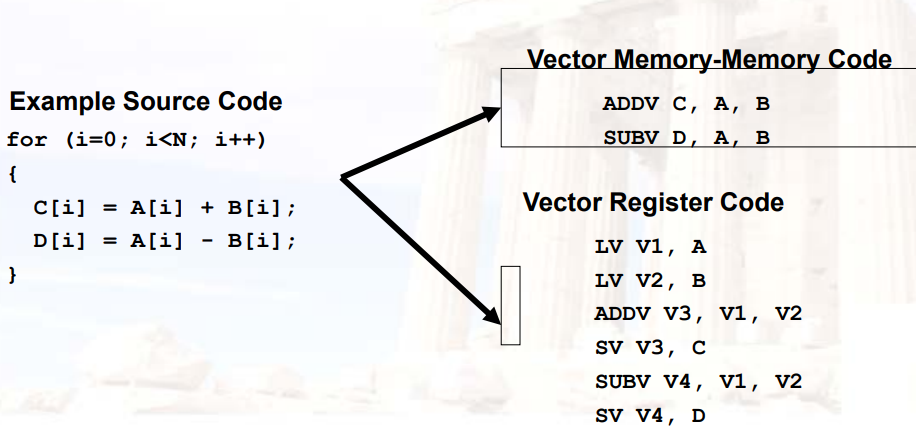
- memory-memory vector processors:
- 所有的向量操作,都在内存之间进行,向量存储在内存中
- 可以给出两个内存地址作为source,一个内存地址作为target
- vector-register processors:
- 所有的向量操作,都在vector寄存器之间进行(处理load和store)
- vector等价于load-store架构
12.3.2.1 vector-register architecture
- 基础想法
- 把一组数据读到
vector register中 - 在寄存器上进行操作
- 将结果写回memory
- 把一组数据读到
- 寄存器由编译器控制
- 用于隐藏memory latency
- 影响内存的带宽
12.3.2.2 Vector Memory-Memory Achitecture
- 矢量内存结构(VMMA)需要更大的主内存带宽,为什么?
- 所有操作数都必须从内存中读取
- VMMA使多个向量操作的执行难以重叠,为什么?
- 必须检查对内存地址的依赖关系
- VMMA导致更大的启动延迟
- 在CDC Star-100上,当矢量<100个元素时,标量代码更快
- 对于Cray-1,向量/标量盈亏平衡点约为2个元素
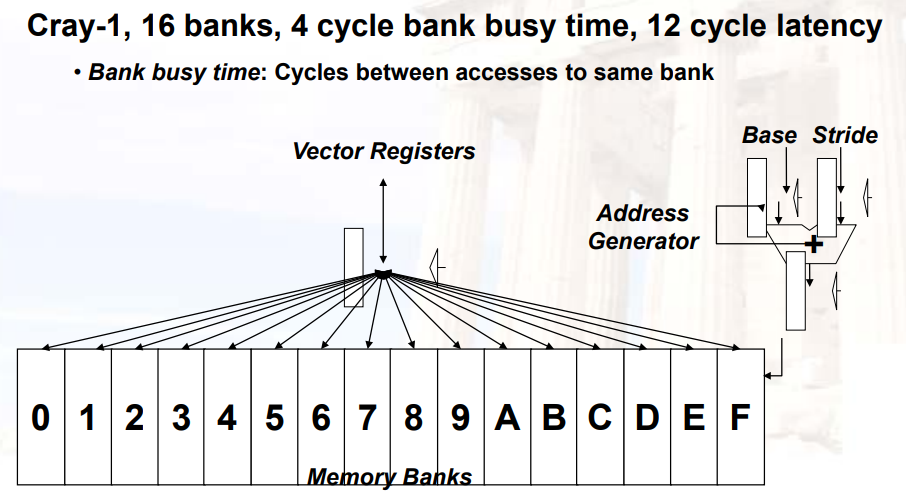
12.3.2.3 Vector Processor的组件
- Vector Register:向量寄存器,固定长度的bank,存储一个vector
- 至少2个读端口,1个写端口
- 通常有8~32个向量寄存器,每个存入64-128个64bit单元
- Vector Functional
Units(FUs):向量功能单元,完全流水,每个周期启动一个新的计算
- 通常有4~8个FUs:FP add,FP mult,FP reciprocal,integer add,logical,shift
- 同一种功能单元可能有多个
- Vector Load-Store Units(LSUs)
- 完全流水
- 每个周期可以读/写多个元素
- 可能有多个LSUs
- Scalar register:标量寄存器,用于浮点标量/地址计算
- Cross-bar:矩阵,将所有部件连起来
12.3.2.4 基础向量指令

12.3.2.5 向量指令的执行时间
- 执行事件取决于三个因素
- 向量的长度
- 是否有结构冲突
- 数据依赖
- RV64V功能单元每个时钟周期消耗一个element
- 流水计算,而不是并行计算
- 执行时间大约为vector的长度
- Convey
- 有可能可以同时执行的向量指令的集合
12.3.2.6 Chimes 节拍
在同一个convey中的指令可能有RAW依赖
Chaining
- 一旦向量操作的源向量均已可用,允许该向量操作尽早执行

Chime
- 执行一次传送的时间单元
- m个convey在m个chimes中执行,向量长度为n
- 对于长度为n的向量,需要m*n个时钟周期
12.3.2.7 Vector内存操作
- load/store操作在寄存器和内存之间移动数据
- 三种类型的寻址
- Unit stride:单位步幅
- 给出每个单元的大小,然后一个单元一个单元的读取
- 最快的
- Non-unit(constant) stride:非单位(恒定)步幅
- Indexed(gather-scatter):索引(聚集-分散)
- 寄存器间接的矢量等效
- 适用于稀疏数据阵列
- 增加矢量化程序的数量
- 压缩/扩展变量
- Unit stride:单位步幅
- 支持内存中各种数据宽度的组合
- {.L、.W、.H、.B}x{64b、32b、16b、8b}
Vector 内存系统
12.3.2.8 DAXPY
- 设X、Y为向量,a为标量,则DAXPY表示的操作为:Y = a * X + Y

12.3.2.9 向量长度
- 一个向量的具体长度是不确定的,但是有一个最大长度(MVL,maximum vector length)
- vector-length
register(VL):控制任何矢量操作的长度,包括矢量加载或存储
- 例如:VL=10时,vadd.vv为
- for(I=0;I<10;I++) V1[I]=V2[I]+V3[I]
- VL可以是从0到MVL的任何值
12.3.2.10 Strip Mining
- 当向量长度 > MVL时,需要进行Strip Mining
- 生成一个循环计算,每个循环计算的向量长度为MVL
- 循环结束后,计算不足MVL的部分
12.3.3 向量操作的优化
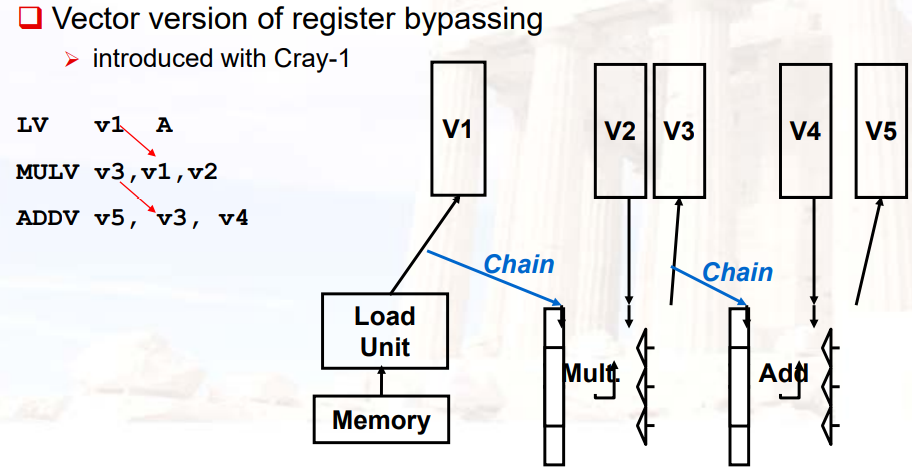
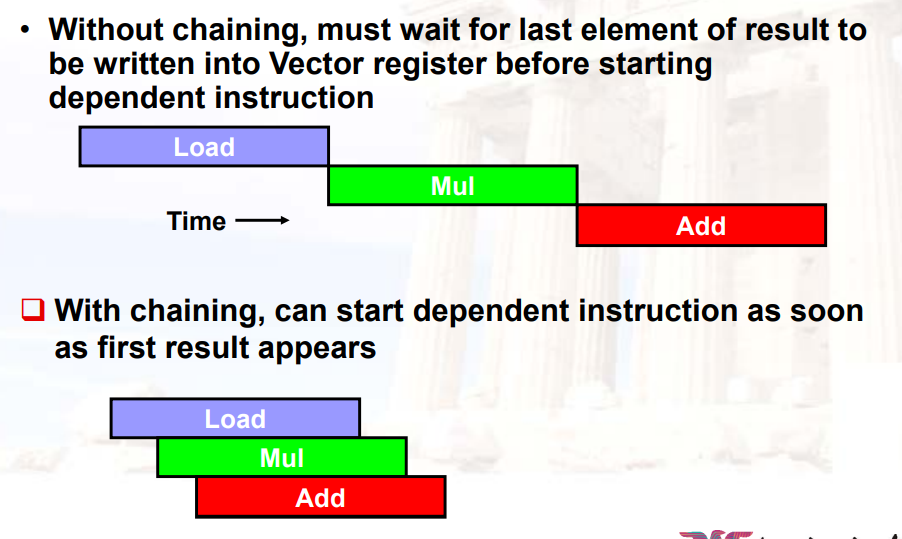
12.3.3.1 Vector Chaining
- 是forward在向量上的延展
12.3.3.2 条件执行
假设源码如下:
- 由于对每个单元的操作不一样,因此需要条件执行
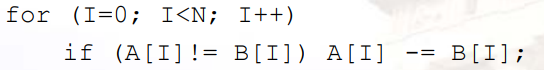
解决方法:条件执行
- 为向量的每个单元添加一个1-bit vector flag register
- 使用vector compare,设置flag register
- 将flag register作为mask,控制向量减法
示例:

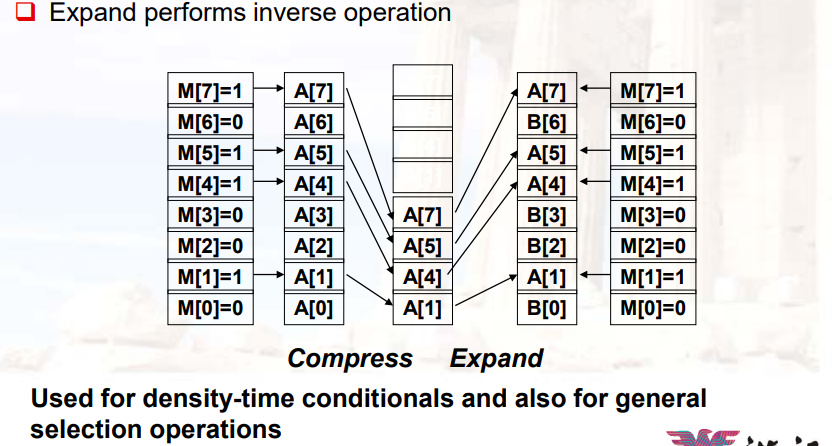
12.3.3.3 压缩/扩展操作
- 如果向量比较稀疏,可以通过mask做压缩
- 然后可以将另一次向量操作,填进当前操作的空余部分
12.3.4 Vector的优点
- 易于获得高性能;N次操作:
- 没有依赖关系
- 使用相同的功能单元
- 存取不相交寄存器
- 按照与前面指令相同的顺序访问寄存器
- 访问连续存储器字或已知模式
- 可以利用大内存带宽
- 隐藏内存延迟(以及任何其他延迟)
- 可扩展:通过添加硬件资源获得更高的性能
- 紧凑型:用一条简短的指令描述N个操作
- 可预测:性能与统计性能(缓存)
- 多媒体就绪:N * 64b、2N * 32b、4N * 16b、8N * 8b
- 需要成熟的编译器技术
12.4 SIMD
- 多媒体应用需要的时比正常word更窄的数据类型
- 如RGBA在做运算时,每个通道要分开计算,即一个计算单元为8-bit
- SIMD与向量计算相比,限制在于:
- 数据的个数被编码进了op code中
- 无复杂的寻址模式(stride、scatter-gather)
- 无mask register
12.4.1 SIMD实现

12.4.2 SIMD代码示例

12.5 GPU:Graphical Processing Units
- 基础思路:
- 异构的计算模型:Heterogeneous execution model
- CPU是主机,GPU是设备
- 为GPU开发一种类似C语言的编程代码
- 编程模型为SIMT:Single Instruction Multiple Thread
- 异构的计算模型:Heterogeneous execution model
- GPU单个指令的计算能力不强,但是并行度非常高,路数很多
- GPU是一个典型的SIMD
12.5.1 Threads and Blocks
- 一个thread与一个data element关联
- thread组成block,block组成grid
- GPU硬件进行thread的管理
12.5.2 NVIDIA GPU 架构
- 与vector machines类似:
- 数据级并行
- 可以进行scatter-gather传输
- 有mask registers
- 有更大的寄存器组
- 区别:
- 没有标量的处理
- 使用多线程去隐藏memory latency
- 有很多的功能单元,不再流水,而是完全的并行
- 4096个线程就是4096个加法器、4096个乘法器…
Chapter 13:Multiprocessors
13.1 为什么要使用多处理器
- 应用的需求
- 单一处理器性能的提升,可以解决latency的问题,但不能解决单位时间内获取更多的产出的问题
- 微处理器已经是最快的CPU了
- 摩尔定律的失效
- 能够使用并行的软件逐渐增多
13.1.1 多处理器的目标
- 性能:
- 突破单一处理器的限制
- 如ILP(branch预测,RAW冲突、内存)
- 更低的成本:
- 使用廉价的部分,构建一个大的系统
- 可扩展性scalability:
- 只要多加处理器,就能获得更好的性能
- 错误容忍:
- 如果有少量处理器失效,仍能继续进行运算
13.1.2 并行计算机
- 定义:并行计算机是一组处理单元,相互协作、通信处理大的问题
- 相关参数:
- 多少个计算机
- 每一个计算单元有多强大
- 如何进行协作、通信
- 数据是怎么发送的
- 通信的类型是什么
- 对程序员来说,硬件和软件的基本单元是什么
- 如何形成性能的
13.1.3 Catalogue the Parallel(MIMD) Processors
- main memory的组成方式
- Shared:所有核共享一个内存UMA
- Distributed:每个核都有一个内存NUMA
- 对硬件来说,memory的性能
- 如memory access latency的表现?
- Shared:每个核访问的不同内存的时间是一致的
- Distributed:每个核访问不同内存的时间是不同的
- 如memory access latency的表现?
- 对软件来说,memory的性能
- 处理器是否能够直接通过内存通信
- Shared(shared memory):可以直接通过load/store进行通信
- Distributed(message passing):通过message进行通信
- 处理器是否能够直接通过内存通信
- 是否正交
- DSM:物理上是分布的,逻辑上是共享的
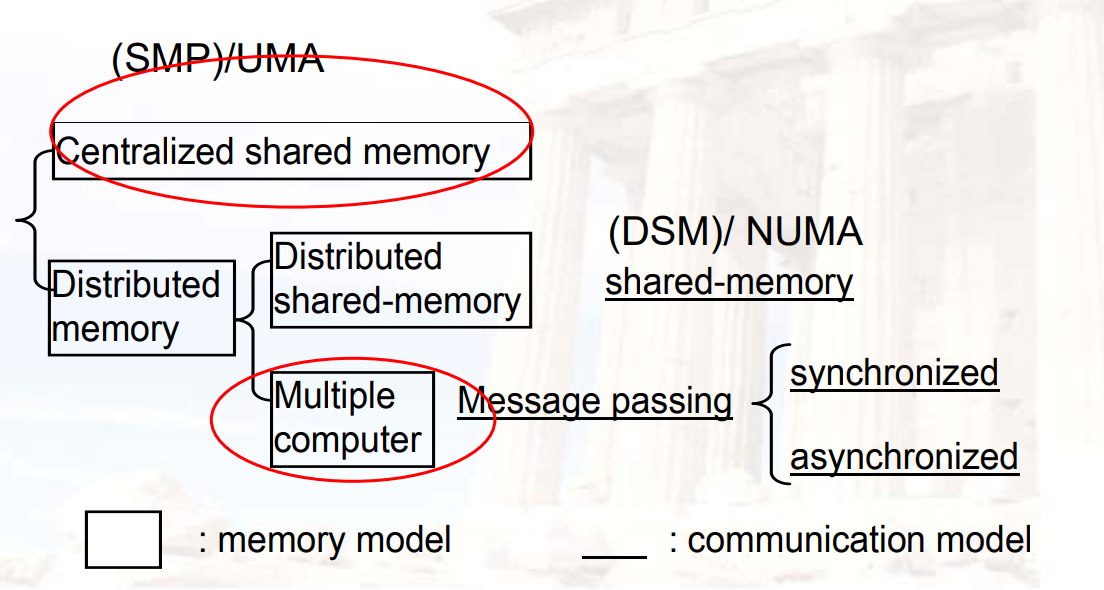
13.1.3.1 UMA
- 理想模型:
- 优秀(single-cycle)的内存访问延迟
- 优秀(infinite)的内存访问带宽
- 实际系统
- 当处理器个数上升时,latency会变长
- bandwidth是有限的
- 添加memory banks,latency也会变大
- 也就是说,UMA做不大
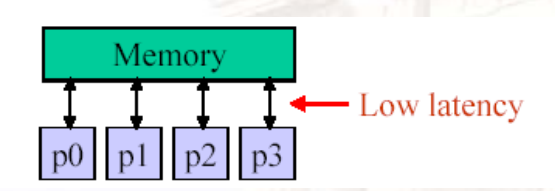
13.1.3.2 UMA vs NUMA
- UMA:uniform memory access
- p0访问m0~m3的延迟都是一样的
- 当系统变大时,延迟会增加
- data放在哪一块是不重要的
- NUMA:non-uniform memory access
- p0访问m0会更快,m1~m3会更慢
- p0发送请求给m0,如果m0发现数据不在当前内存,则向Interconnect发消息,获取其它内存单元的数据
- data放在哪里很重要
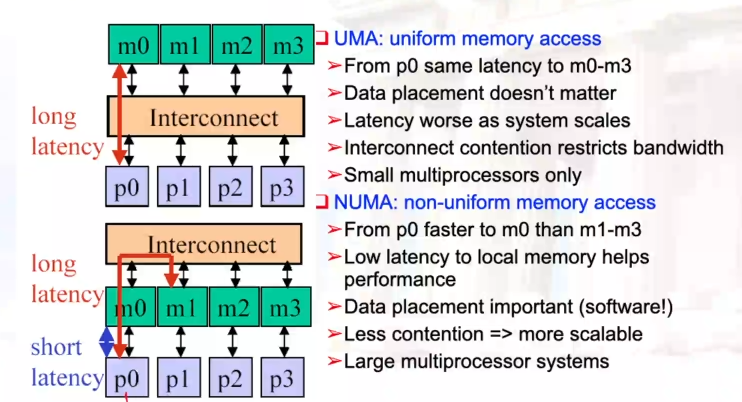
13.1.4 主要的MIMD类型
- 中心化的共享内存
- 去中心化的内存:内存单元跟随CPU
- 内存带宽变大,但是会有更高的通信延迟
- 软件模型更复杂
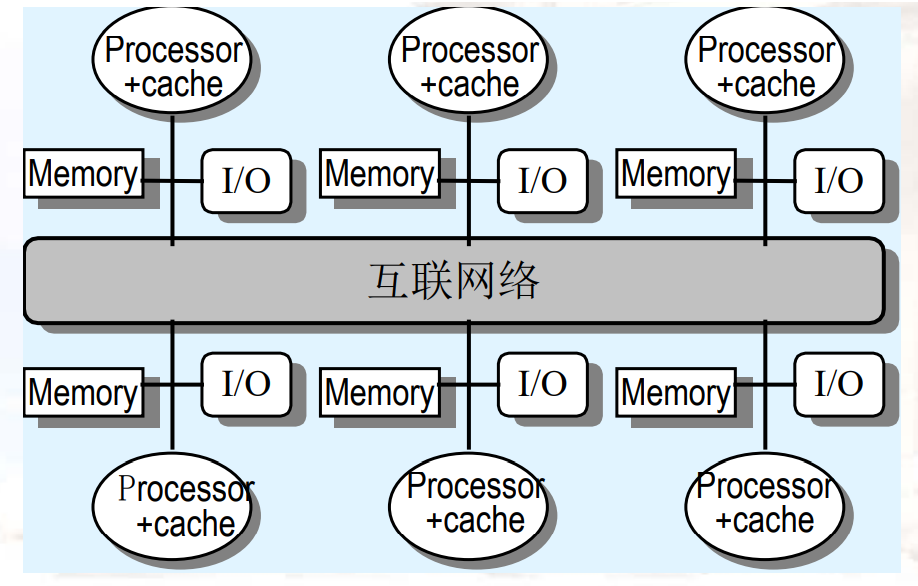
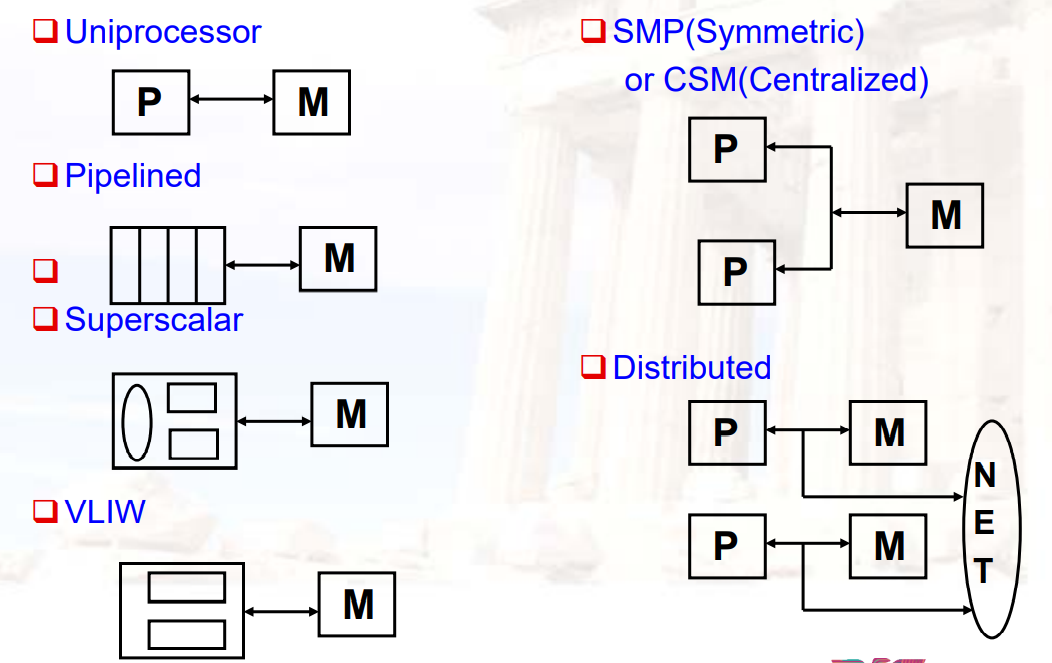
13.1.5 并行架构
- 并行架构拓展了传统的计算机架构,主要通过通信
- 抽象:在硬件和软件上有不同的接口
- 并行的编程模型
- multiprogramming:有很多任务,不考虑通信问题
- shared address space:通过内存进行通信
- message passing:发送/接收消息
- data parallel:由代理(agents)同时操作数据集,然后全局地同时交换信息
- 通信的抽象:
- 共享地址空间:load、store、原子的swap
- 信号传递:send、receive调用库函数
13.1.5.1 Shared Address Model
- 每个处理器都可以访问机器上的任何一个物理地址
- 每个进程都可以访问和别的进程共享的数据
- 数据的传输:load、store
- 数据的大小:byte、word、cache blocks
- 使用虚拟内存,将虚拟空间映射到本地/远程物理空间
- 应用memory层级模型
- 通信会将数据移动到本地的cache
- 对于分布式内存架构,需要一个layer(硬件/软件),做透明的地址映射
- 重点是:数据的一致性、数据保护
- 对于多机系统来说,地址的映射是由软件完成的,通常是OS的一部分
- scalability是有限的,因为通信方式与处理器的地址空间紧密的联系在一起
13.1.5.2 Message Passing Model
- 整个计算机(CPU、内存、I/O设备)作为显式I/O操作进行通信
- 本质上是NUMA,但集成在I/O设备与内存系统之间
- 发送指定远程计算机上的本地缓冲区+接收进程
- 接收指定远程计算机上的发送进程+放置数据的本地缓冲区
- 通常发送的信息包含process tag
- 接收在tag上有规则:match 1,match any
- 同步:当发送完成时,当缓冲区空闲时,当请求被接受时,接收等待发送
- 发送+接收=>memory-memory copy
- 其中每个副本提供本地地址,并且执行成对同步
13.2 Cache coherence 一致性问题
SMP的特性:
- 有限的处理器数量
- 足够大的cache:提供更大的memory bandwidth
- UMA:uniform memory access time
Cache coherence

Synchronization:
- 原子的读/写操作
内存一致性模型:
- 处理器必须以什么样的顺序观察别的处理器写的数据
- 读和写之间的关系是什么样的
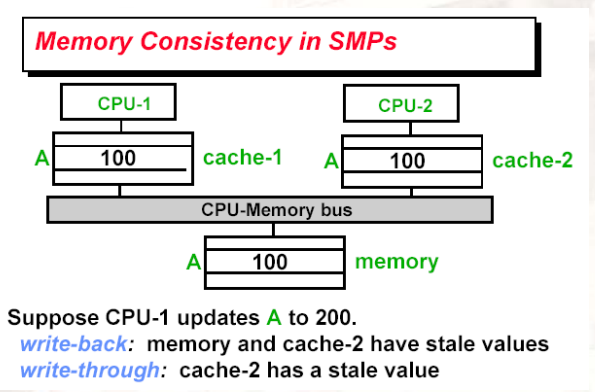
coherency的意义:
- 严格定义:所有的read必须返回最新的write数据
- 更优的定义:所有的write必须最终被read看到,所有的write以一种正确的顺序被看到(串行)
- 两条规则去实现:
- 如果P写了x,P1要读x,只有当read和write分开足够远时,P的write才能被P1的read看到
- 写到同一个地方的数据必须串行起来,以一种相同的顺序被看到
- 只会看到最新的写
cache coherence的定义:

13.2.1 硬件Coherence协议
- Snooping算法:Snoopy Bus
- 所有对数据的请求都要发给所有处理器
- 处理器监听是否有对数据的请求与其相关,如果于其相关,则修改自己的cache中的数据
- 需要广播的机制
- 如果有bus,则work well
- 适用于小规模的机器
- Directoy-Based Scheme:discuss later
- 有一个中央的目录,知道哪一个处理器拥有哪一段地址
- 如果需要修改数据,则向中央目录发送点对点请求
- 中央目录将该请求发送到每个与其相关的处理器
- 只有当处理器不在一个bus上时,才更优
13.2.2 Snoopy协议
- Write Invalidate协议:
- 多个reader,单一writer
- 写到shared data时,会发送一个invalidate的消息,给所有的cache
- 当cache读到invalidate的数据时,就会发生miss
- write-through:内存总是最新的
- write-back:先看别的cache中,是否有当前数据的最新copy
- Write Broadcast协议:
- 写的时候,会将数据发送到bus上,处理器用该数据更新自己的cache
- 不会导致新的miss
- 写的串行化:通过bus访问实现
- 总结:
- 所有的cache会看到所有的bus事件,并进行响应
- 协议依赖于bus事件的全局可见性
- 由于bus上只能有一个数据,因此可以强制串行write
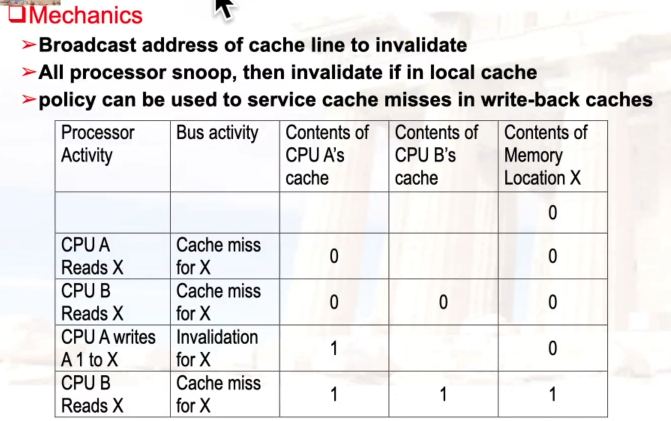
示例:write-back cache、write invalidate
- 最后一次读X时,让其它的cache中进行一次write-back,然后从memory中读取X
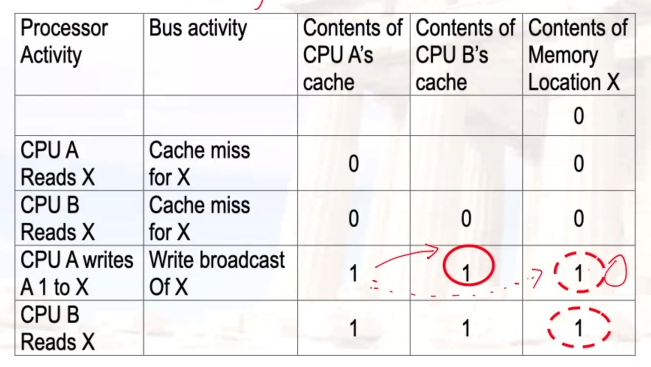
示例:write-back cache、broadcast
- 广播时,会将内存中的数据也修改了(事实上的through)